







1.1 统计学习
(1)统计学习分为监督学习、半监督学习、无监督学习和强化学习。*
监督学习的任务是学习一个模型,使得模型能够对任意给定的输入,对其输出做一个好的预测,监督学习的应用最为广泛
(2)输入空间、输出空间、特征空间*
在监督学习中,输入与输出的所有可能取值的集合分别称为输入空间和输出空间。
输入空间与输出空间可能相同,也可能不同,通常输入空间小于输出空间。
每个具体的输入是一个实例,通常由特征向量表示,所有特征向量的空间称为特征空间。
输入空间和特征空间如果相同,不进行区分
如果不同,试讲实例由输入空间映射到特征空间
模型都是定义在特征空间上的
(3)问题分类
输入与输出均为连续变量的问题是回归问题
输出是有限个离散变量的预测问题是分类问题
输入与输出均为变量序列的问题是标注问题
(4)假设空间
监督学习的目的是学习一个由输入到输出的映射,这个映射就由模型来表示
模型可以使概率模型或者是非概率模型,分别表示为条件概率分布
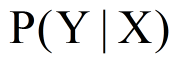
或决策函数
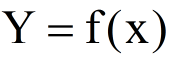
(5)统计学习三要素:模型、策略、算法
模型:
模型就是要学习的条件概率分布或者是决策函数
模型的假设空间**为所有可能的条件概率分布或者决策函数的集合
策略:
有了模型的假设空间,就需要考虑用什么样的准则学习或者选择最优模型。
统计学习的目的就是从假设空间中选取最优模型
因此,引入损失函数的概念:
0-1损失函数
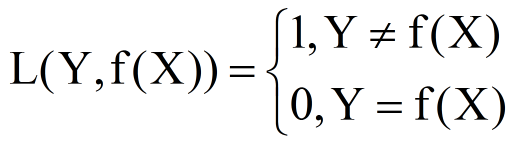
平方损失函数
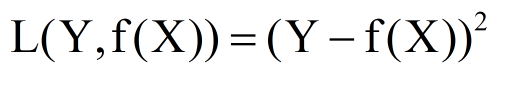
绝对损失函数
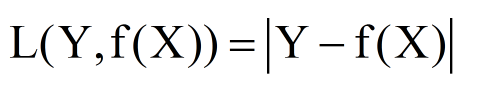
对数损失函数
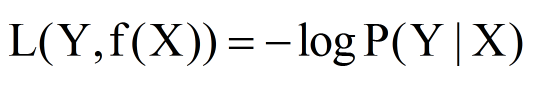
损失函数值越小,模型越好
输入X与输出Y遵循联合概率分布P(X,Y),损失函数的期望:
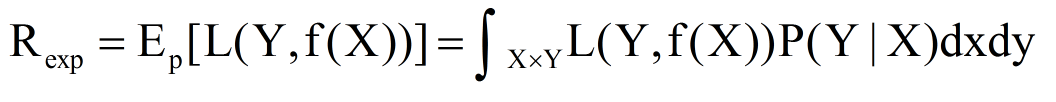
这是模型关于联合分布P(X,Y)的平均意义下的损失,称为风险函数或者期望损失
由于在实际问题中,联合分布P(X,Y)是未知的(PS:如果联合分布P(X,Y)是已知的,那么:就可以直接获得条件概率分布P(Y|X),即直接过得模型,就不需要学习的过程了,所以它是未知的),所以就无法求得Rexp,也就无法求得最小Rexp,因此就不能最小化期望风险的最优模型,所以需要从另一个角度获取最优模型。
此时,引入就引入了经验风险的概念。
假设,存在训练数据集
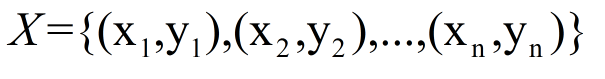
经验风险Remp**表示为
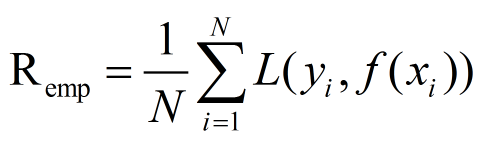
经验风险就是所有训练数据集的平均损失函数
根据大数定律,当样本容量N趋于无穷大时,经验风险Remp(f)趋近于Rexp(f)
但是实际情况是,样本容量是有限的,甚至很小,所以用经验风险去估计期望风险是不合理的。
所以,此时有两种方法对经验风险进行矫正,即经验风险最小化和结构风险最小化
(6)泛化能力
泛化能力就是对未知数据的预测能力,是最重要的性质
所以用泛化误差来衡量泛化能力,泛化误差等价于模型学习得到的期望风险
泛化能力分析是通过分析泛化误差上界来进行的
对比两种学习方法的泛化能力,通常是比较泛化误差上界的大小来确定的
样本容量越大,训练数据就越多,模型效果就越好,泛化误差上界就越小,
假设空间越大,模型的可能性就越多,就越难学习,泛化误差上界就越大;
关于泛化误差上界的推导:
泛化误差上界推导
(7)生成模型与判别模型
统计学习的目的就是从数据中找到****决策函数Y=f(X)或者条件概率分布P(Y|X)
获得的方法可以分为两种,判别方法和生成方法
判别方法:直接面向数据的分类,即直接从大量数据集中学习分类技巧,也就是如何找到最优化方法将不同类别数据进行区分,直接学习得到决策函数Y=f(X)或者条件概率分布P(Y|X),判别方法关心的是给定一个输入X,如何输出一个对应的Y。
生成方法:生成方法通过数据,获取数据内部的信息,即输入X与输出Y的概率分布P(X,Y),之后再通过P(Y|X)=P(X,Y)/P(X)获得条件概率分布,生成方法关心的是输入与输出之间的生成关系。
(8)分类问题
当输出变量取有限个离散值时,预测问题变成分类问题
性能指标是分类准确率(accurucy),其定义为:对于非定的测试训练集,分类器正确分类的样本数与总样本数之比,也就是损失函数为0-1损失函数时测试数据集上的准确率。
对于二分类,常见的评价指标是精确率和召回率
TP----将正类预测为正类数
FN----将正类预测为负类数
FP----将负类预测为正类数
TN----将负类预测为负类数
精确率(precision)
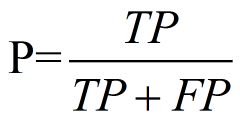
召回率(recall)
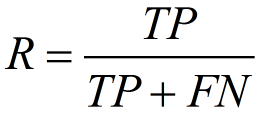
F1值
F1值是精确率和召回率的调和均值
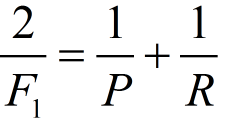
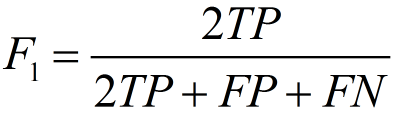
(9)标注问题
标注问题是分类问题的一个推广,其输入是一个观测序列,输出是标记序列或是状态序列,与分类问题的区别是:分类问题输出是离散值,标注问题输出一个向量,向量的每个值属于一种标记类型
(10)回归问题
栗子:
预测明天的天气温度,这是一个回归问题,是一个定向

知乎上回答的挺不错的
https://www.zhihu.com/question/21329754
习题1.1















 451
451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









