







Attention Is All You Need

摘要
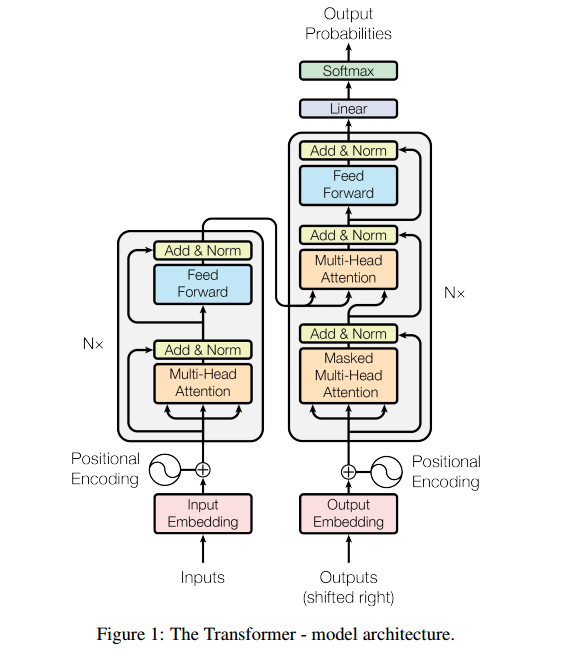
主导序列转导模型基于复杂的递归或卷积神经网络,该神经网络包括编码器和解码器。性能最好的模型还通过注意力机制将编码器和解码器连接起来。我们提出了一种新的简单的网络体系结构Transformer,它完全基于注意力机制,完全不需要重复和卷积。在两个机器翻译任务上的实验表明,这些模型在质量上更优越,同时具有更高的并行化能力,所需的训练时间显著减少。我们的模型在WMT 2014英译德翻译任务中获得了28.4%的BLEU成绩,比现有的最好成绩(包括语料库)提高了2%以上。在WMT 2014英法翻译任务上,我们的模型在8个GPU上进行了3.5天的培训后,建立了一个新的单一模型最先进的BLEU得分41.8%,这只是文献中最好的模型培训成本的一小部分。我们通过将其成功地应用于具有大量和有限训练数据的英语选区分析,表明该转换器对其他任务具有很好的通用性。
self-attention
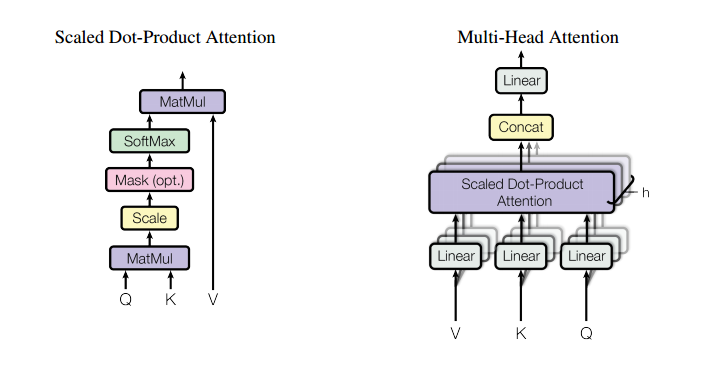

Attention(Q,K,V)
其中公式的计算详细过程如下:
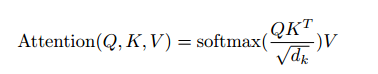
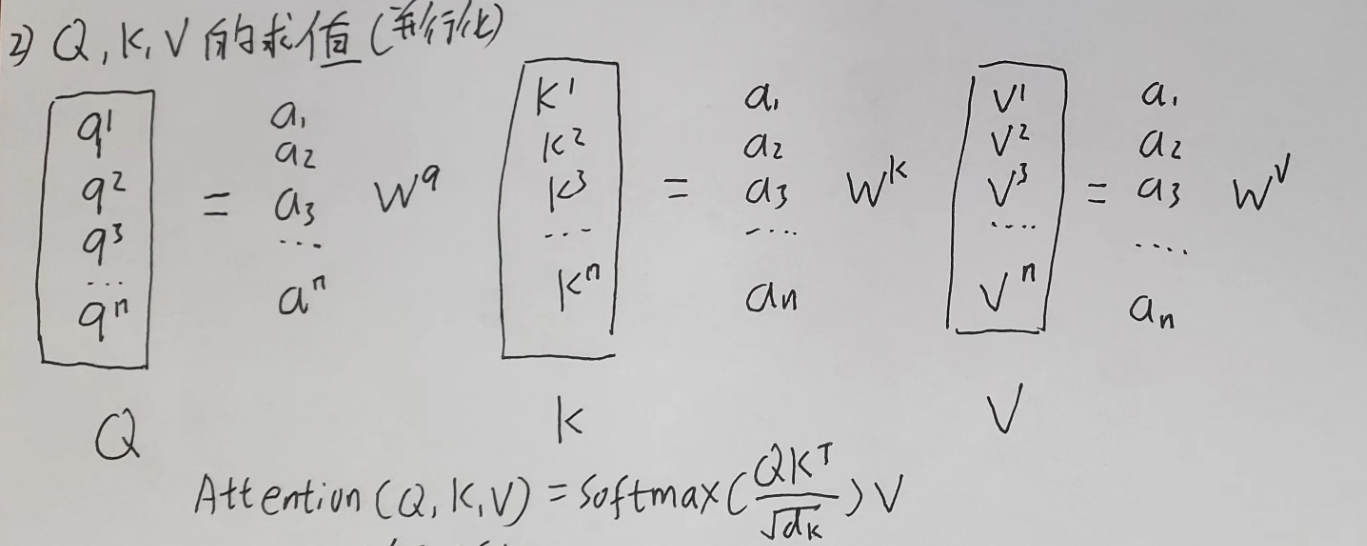
q , k , v的求值
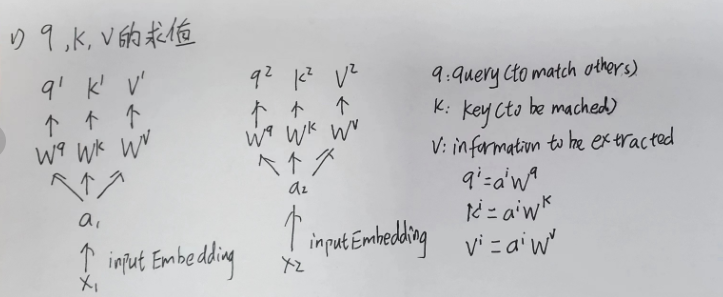
Q , K , V的求值
并行化
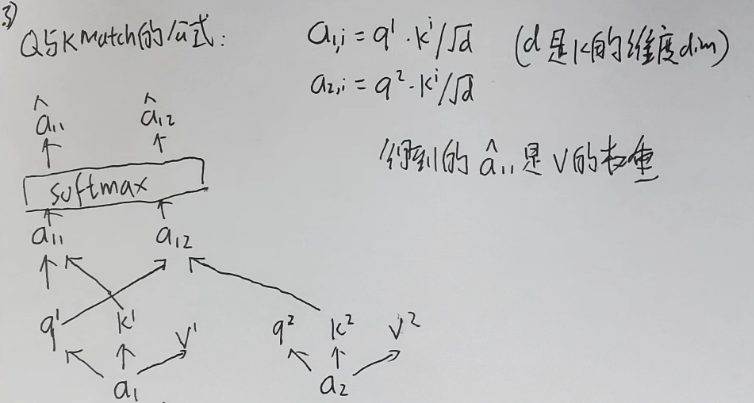
q与k match的过程
Q与K match的过程
并行化
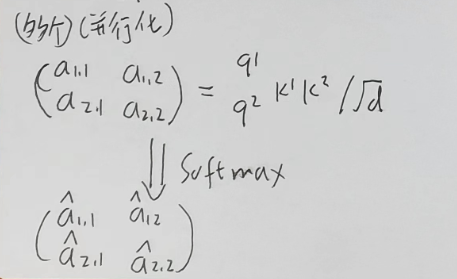
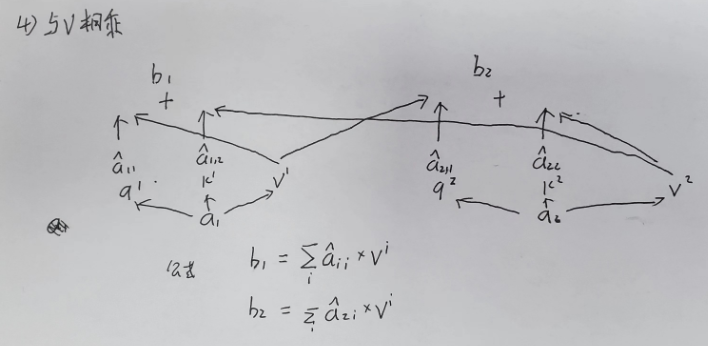
与V相乘
并行化
模块化处理
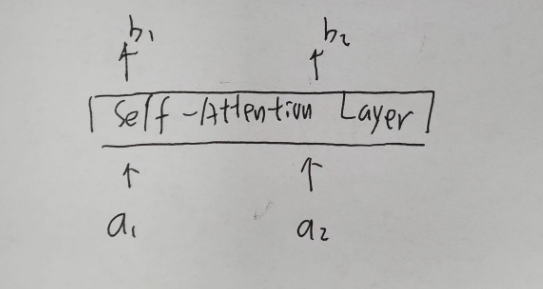
Multi head self-attention

在self-attention的基础上做了均分处理
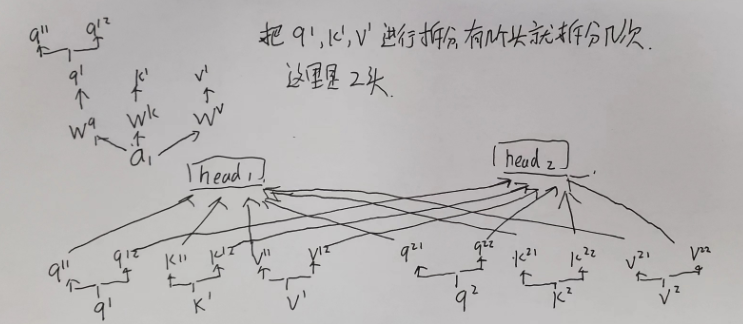
拆分处理

head1,head2,等组成
公式

求单个b的过程
在不同的head中,执行self attention的操作流程
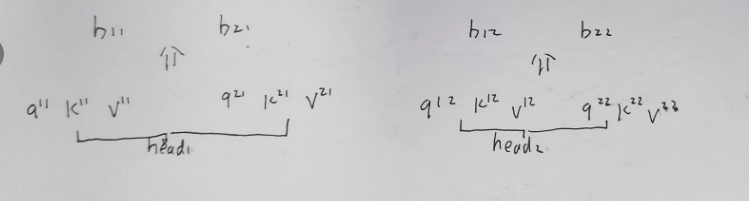
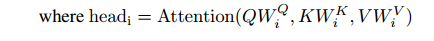
拼接b,并融合
将不同的head执行concat操作:
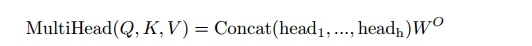
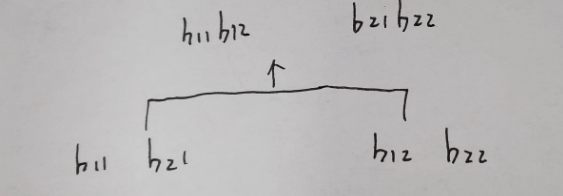
融合

模块化处理
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









