






1、order by
order by 是全局排序,只有一个reduce(即使设置了多个,也会只走一个),速度较慢,最好事先完成数据的过滤,支持使用case when 或者表达式,排序的数据是reduce后输出的数据
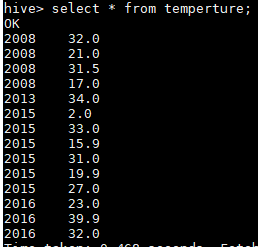
原数据:
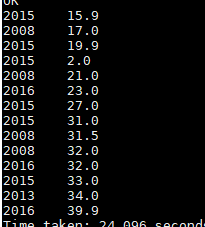
经过order by排序后的数据 ,可以指定升序asc 降序desc
2、sort by
sort by 全局不排序,而是对进入reduce前的每个分区中的数据进行排序。如果设置reduce task 的数量为 多个(一个时等于order by),sort by 只能保证一个reduce中的输入数据按照指定的字段排序,使用sort by你可以指定执行的reduce个数(通过set mapred.reduce.tasks=n来指定),对输出的数据再执行归并排序,即可得到全部结果。
排序列必须出现在SELECT column列表中

可以看到,设置reduce的个数为2 ,每个reduce中的数据都根据year字段使用sort by 排序,每个reduce中的数据都是有序的,但是全局的数据是没有序的。
3、distribute by
首先我们要明白一个概念,distribute by是用来分组的,不是用来排序的。
即在map端如何拆分数据给reduce端,可以控制相应的行到同一个reduce中。
hive会根据distribute by后面的字段名以及reduce的个数进行分发,默认是采用hash算法。sort by为每个reduce产生一个排序文件。distribute by控制某个特定行应该到哪个reducer,这通常是为了进行后续的聚集操作。因此,distribute by经常和sort by配合使用。
使用distribute by后:一个字段值的某个值一定都在这个reduce中,但一个reduce中不一定只包含这一个字段值
语句如下:

结果如下:

4.Cluster by
cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是正序排序,不能指定排序规则。
排序列必须出现在SELECT column列表中。















 1669
1669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









