






拉丁超立方抽样
1.拉丁超立方抽样
拉丁超立方抽样技术最早于1979年由McKay等提出,该方法具有以下优点:
- 具有均匀分层的特性
- 可以在较少抽样的情况下,得到尾部的样本值
以上两点使得拉丁超立方抽样比起普通的抽样方法更加的高效。
2拉丁超立方抽样的步骤
- 首先确定样本数N,既要抽取的样本数目
- 将(0,1)区间均分为N段
- 在这N段中的每一段随机的抽取一个值
- 将抽取的值通过标准正态分布的反函数映射为标准正态分布样本
- 打乱抽样顺序,用matlab中的sort函数
通过以上五步便完成了拉丁超立方抽样
3图解拉丁超立方抽样
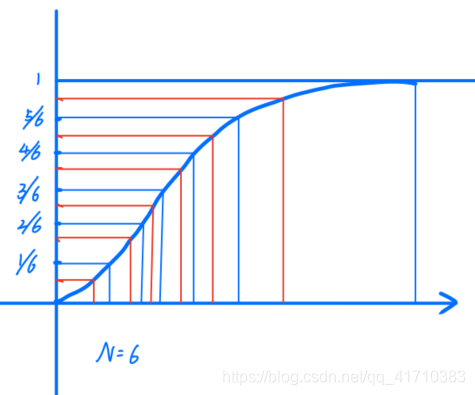
从图中可以看出,假设我们要进行6次抽样,即N=6,则把竖轴均分为六等份(以蓝线为界),在每一等份中随机抽取一个值(红线与纵轴的焦点)进行映射得到标准正态分布值(红线与横轴的焦点)。
下面介绍如何在每一等份中抽取一个值
- 首先在(0,1)均匀分布随机抽取一个值,用matlab中的函数rand(1,1),表示抽取一个一行一列的服从(0,1)均匀分布的随机数。
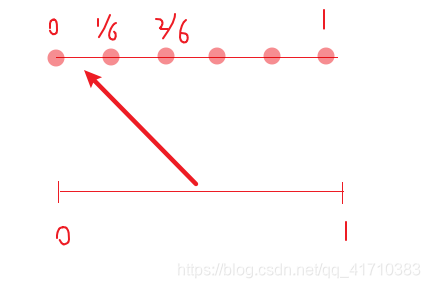
- 假设先在(0,1/6)区间抽取随机数,那么就需要把刚才在(0,1)区间上抽取的随机数映射到(0,1/6)即可,这就需要用到公式
(rand(1,1)/M+(i-1)/M),rand(1,1)/M表示缩小,(i-1)/M表示平移,即(0,1)均匀分布上的随机数经过缩小平移,就映射到了(0,1/6)区域上。。
图解映射过程
通过六次映射就完成了六个样本的拉丁超立方抽样。可见,拉丁超立方抽样首先将抽样区间分层,然后在每一层中抽取样本,这样就保证了尾部层中的样本也会被抽取,而这些样本对于结果也是十分重要的。当然,抽取样本点数越多,分层就越多,极端的尾部值就更容易被抽取。
代码展示
function newz=LHSNoCorr1(M)
for i=1:M
z(1,i)=norminv(rand(1,1)/M+(i-1)/M); %rand(1,1)表示生成一行一列个01均匀分布随机数
end
[temp1,O1]=sort(rand(M,1)); %O1表示一个随机序列,他是对随机生成的M个正态分布进行排序后的数列
newz(1,:)=z(1,O1)'; %利用刚才生成的随机序列来对z进行乱序排列,这样去除了数据之间的相关性
















 1362
1362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











