







搜索排序算法
一、二分搜索算法
1. 非递归代码实现
#include<iostream>
using namespace std;
int BinarySearch(int arr[], int size, int val)
{
int first = 0;
int last = size - 1;
int mid;
while (first <= last)
{
mid = (first + last) / 2;
if (arr[mid] == val)
{
return mid;
}
else if (arr[mid] > val)
{
last = mid - 1;
}
else
{
first = mid + 1;
}
}
return -1;
}
int main()
{
int arr[] = { 12,23,34,47,65,78,89,90,95,98,105 };
cout << BinarySearch(arr, sizeof(arr) / sizeof(arr[0]), 47) << endl;
cout << BinarySearch(arr, sizeof(arr) / sizeof(arr[0]), 91) << endl;
cout << BinarySearch(arr, sizeof(arr) / sizeof(arr[0]), 89) << endl;
return 0;
}

时间复杂度O(logn)

比如在有序的100w个数据中心查找,那么最多搜索log(100w)大约是20层就可以找到,效率是很高的。
2. 递归代码实现
递归思想的分析:

递归应用的场景:
- 不管是什么数据规模,问题的方式是一样的
- 不同规模的数据,其计算结果是有关系可寻的
写递归函数要清楚:
- 递归函数的意义是什么,返回值和参数列表,完成什么功能
- 递归结束的条件
- 每个数据规模要写好他们之间的计算关系
递归问题的思考是水平方向的,递归代码的执行是垂直方向上的。
二分搜索算法的递归实现
#include<iostream>
using namespace std;
//在arr数组的[i,j]范围内,二分搜索值val,找到的话返回值的下标,找不到返回-1
int BinarySearch(int arr[], int first, int last, int val)
{
//递归结束的条件
if (first > last)
return -1;
int mid = (first + last) / 2;
if (arr[mid] > val)
return BinarySearch(arr, first, mid - 1, val);
else if (arr[mid] < val)
return BinarySearch(arr, mid + 1, last, val);
else
return mid;
}
int BinarySearch(int arr[], int size, int val)
{
return BinarySearch(arr, 0, size - 1, val);
}
int main()
{
int arr[] = { 12,23,34,47,65,78,89,90,95,98,105 };
cout << BinarySearch(arr, sizeof(arr) / sizeof(arr[0]), 47) << endl;
cout << BinarySearch(arr, sizeof(arr) / sizeof(arr[0]), 91) << endl;
cout << BinarySearch(arr, sizeof(arr) / sizeof(arr[0]), 89) << endl;
return 0;
}
二、八大排序算法
1. 冒泡排序算法
特点:相邻元素两两比较,把值大的往下换
缺点:数据交换次数太多了

#include<iostream>
using namespace std;
void BubbleSort(int arr[], int size)
{
for (int i = 0; i < size - 1; ++i)//趟数O(n)
{
bool flag = false;
//一趟的处理O(n)
for (int j = 0; j < size - 1 - i; ++j)
{
if (arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
flag = true;
}
}
if (!flag)
return;
}
}
int main()
{
int arr[] = { 77,9,94,91,48,5,55,4,26,12 };
BubbleSort(arr, sizeof(arr) / sizeof(arr[0]));
for (int v : arr)
{
cout << v << " ";
}
return 0;
}
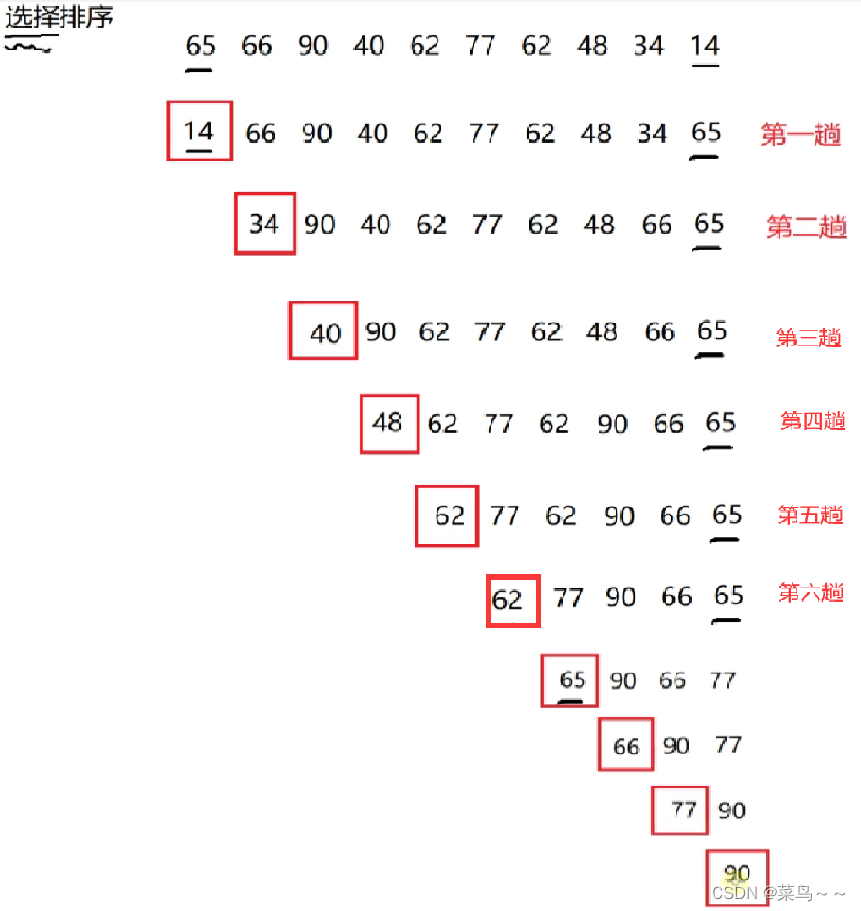
2. 选择排序算法
特点:每次从剩下的元素中选择值最小的元素,和当前元素进行交换
缺点:相比于冒泡排序,交换的次数少了,但是比较的次数依然很多
分析:
#include<iostream>
#include<time.h>
using namespace std;
//时间复杂度:O(n2)
//空间复杂度:O(1)
//稳定性:不稳定。比如5,5,3第一个5和3交换就成了3,5,5
void ChoiceSort(int *arr, int size)
{
for (int i = 0; i < size - 1; i++)
{
int min = arr[i];
int pos = i;
for (int j = i + 1; j < size; j++)
{
if (arr[j] < min)
{
min = arr[j];
pos = j;
}
}
if (pos != i)
{
arr[pos] = arr[i];
arr[i] = min;
}
}
}
int main()
{
int arr[10] = { 0 };
srand(time(0));
for (int i = 0; i < 10; i++)
{
arr[i] = rand() % 100 + 1;
cout << arr[i] << " ";
}
cout << endl;
ChoiceSort(arr, sizeof(arr) / sizeof(arr[0]));
for (int v : arr)
{
cout << v << " ";
}
cout << endl;
return 0;
}
时间复杂度O(n^2),空间复杂度O(1),不稳定,比如5,5,3进行排序,第一个5会放在第二个5后面。
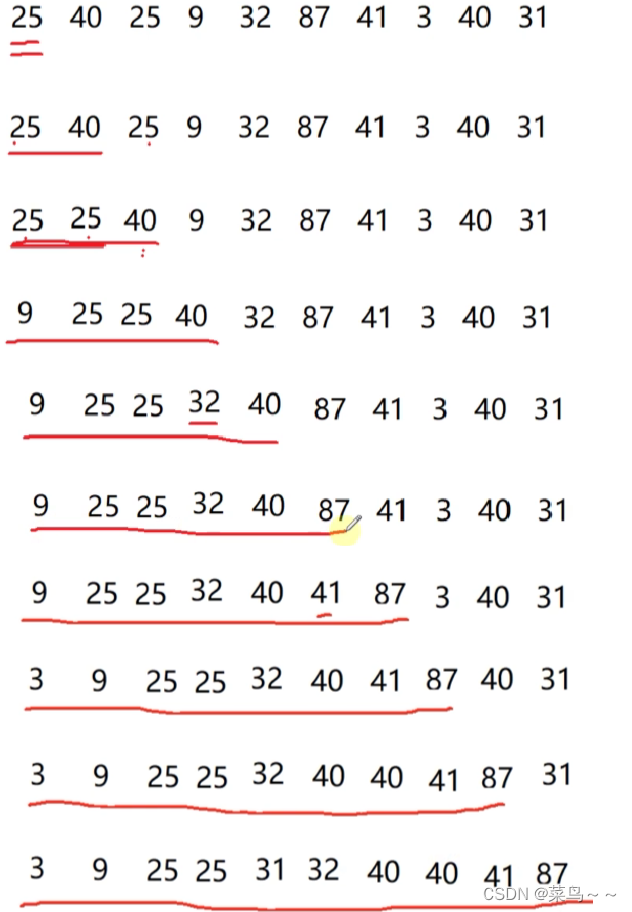
3. 插入排序算法
如果数据趋于有序,那么插入排序算法是所有排序算法中效率最高的!不仅仅没有交换,而且比较的次数也少。
在基础排序算法中,插入排序 > 选择排序和冒泡排序 。
插入排序的算法思想:每次会把前面的一组序列当做已经排序好的序列,然后把当前元素按顺序插入到前面的序列当中。
分析:
#include<iostream>
#include<time.h>
using namespace std;
//时间复杂度:最坏和平均O(n2),最好O(n)
//空间复杂度:O(1)
//稳定性:稳定
void InsertSort(int arr[], int size)
{
for (int i = 1; i < size; i++)
{
int j=i-1;
//要注意把arr[i]的值记录下来,因为后面arr[i]的值可能会被更改
int val = arr[i];
for (; j >= 0; j--)
{
if (arr[j] <= val)
break;
arr[j + 1] = arr[j];
}
arr[j + 1] = val;
}
}
int main()
{
int arr[10] = { 0 };
srand(time(0));
for (int i = 0; i < 10; i++)
{
arr[i] = rand() % 100 + 1;
cout << arr[i] << " ";
}
cout << endl;
InsertSort(arr, sizeof(arr) / sizeof(arr[0]));
for (int v : arr)
{
cout << v << " ";
}
cout << endl;
return 0;
}
时间复杂度:最坏和平均O(n^2),最好O(n)
空间复杂度:O(1)
稳定性:稳定
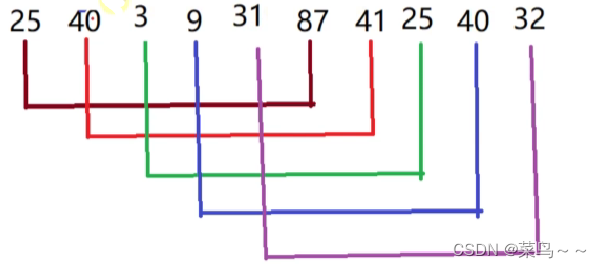
4.希尔排序算法
如果数据趋于有序,插入排序算法是最高的。插入排序的特点是按顺序从左到右依次找合适的位置插入,也就是说随着我们插入排序的进行只是前面一部分是有序的,从整体上表现出来并不是越排越有序,而希尔排序算法是从全局的角度把数据调整的趋于有序,利用插入排序的这一特点,最后进行一次插入排序。
希尔排序:对数据进行分组插入排序
分析:

第一次分组结果(gap=5)
第二次分组结果(gap=2)
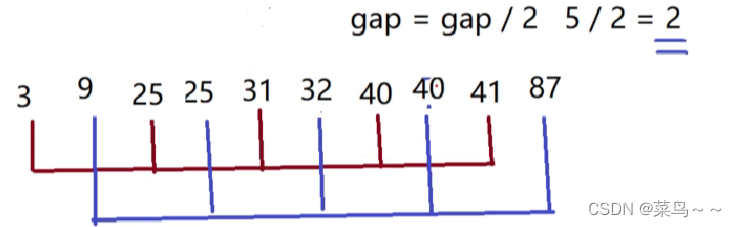
第三次分组结果(gap=1),gap为1的话就是进行最后一次插入排序

最后一次插入排序比较爽的就是因为它是从前往后分组先进行插入排序的,数据可以最快达到趋于有序,这刚好符合插入排序效率比较高的数据序列的特点。
#include<iostream>
#include<time.h>
using namespace std;
//时间复杂度:最坏O(n^2),平均O(n^1.3),最好O(n)
//空间复杂度:O(1)
//稳定性:不稳定
void ShellSort(int arr[], int size)
{
//外面的这层for循环数据量很小可以不关注
for (int gap = size / 2; gap > 0; gap /= 2)
{
//相当于把插入排序的1换成gap
for (int i = gap; i < size; i++)
{
int j = i - gap;
int val = arr[i];
for (; j >= 0; j-=gap)
{
if (arr[j] <= val)
break;
arr[j + gap] = arr[j];
}
arr[j + gap] = val;
}
}
}
int main()
{
int arr[10] = { 0 };
srand(time(0));
for (int i = 0; i < 10; i++)
{
arr[i] = rand() % 100 + 1;
cout << arr[i] << " ";
}
cout << endl;
ShellSort(arr, sizeof(arr) / sizeof(arr[0]));
for (int v : arr)
{
cout << v << " ";
}
cout << endl;
return 0;
}
时间复杂度:最坏O(n^2),平均O(n^1.3),最好O(n)
空间复杂度:O(1)
稳定性:不稳定
插入排序的效率最好,尤其是在数据已经趋于有序的情况下,采用插入排序效率最高。
一般中等数据量的排序都用希尔排序,选择合适的增量序列,效率就已经很不错了,如果数据量比较大,可以选择高级的排序算法,如快速排序。
5. 冒泡、选择、插入和希尔算法性能对比
int main()
{
const int count = 100000;
int* arr = new int[count];
int* brr = new int[count];
int* crr = new int[count];
int* drr = new int[count];
srand(time(0));
for (int i = 0; i < count; i++)
{
int val = rand() % count;
arr[i] = val;
brr[i] = val;
crr[i] = val;
drr[i] = val;
}
clock_t begin, end;
begin = clock();
BubbleSort(arr, count);
end = clock();
cout << "BubbleSort spend:" << (end - begin) * 1.0 / CLOCKS_PER_SEC << "S" << endl;
begin = clock();
ChoiceSort(brr, count);
end = clock();
cout << "ChoiceSort spend:" << (end - begin) * 1.0 / CLOCKS_PER_SEC << "S" << endl;
begin = clock();
InsertSort(crr, count);
end = clock();
cout << "InsertSort spend:" << (end - begin) * 1.0 / CLOCKS_PER_SEC << "S" << endl;
begin = clock();
ShellSort(drr, count);
end = clock();
cout << "ShellSort spend:" << (end - begin) * 1.0 / CLOCKS_PER_SEC << "S" << endl;
return 0;
}

6. 快速排序算法
快速排序的思想:选取一个基准数,把小于基准数的元素都调整到基准数左边,把大于基准数的元素都调整到基准数的右边,然后对基准数左边和右边的序列继续进行这样的操作,直到整个序列变成有序的。
分析:
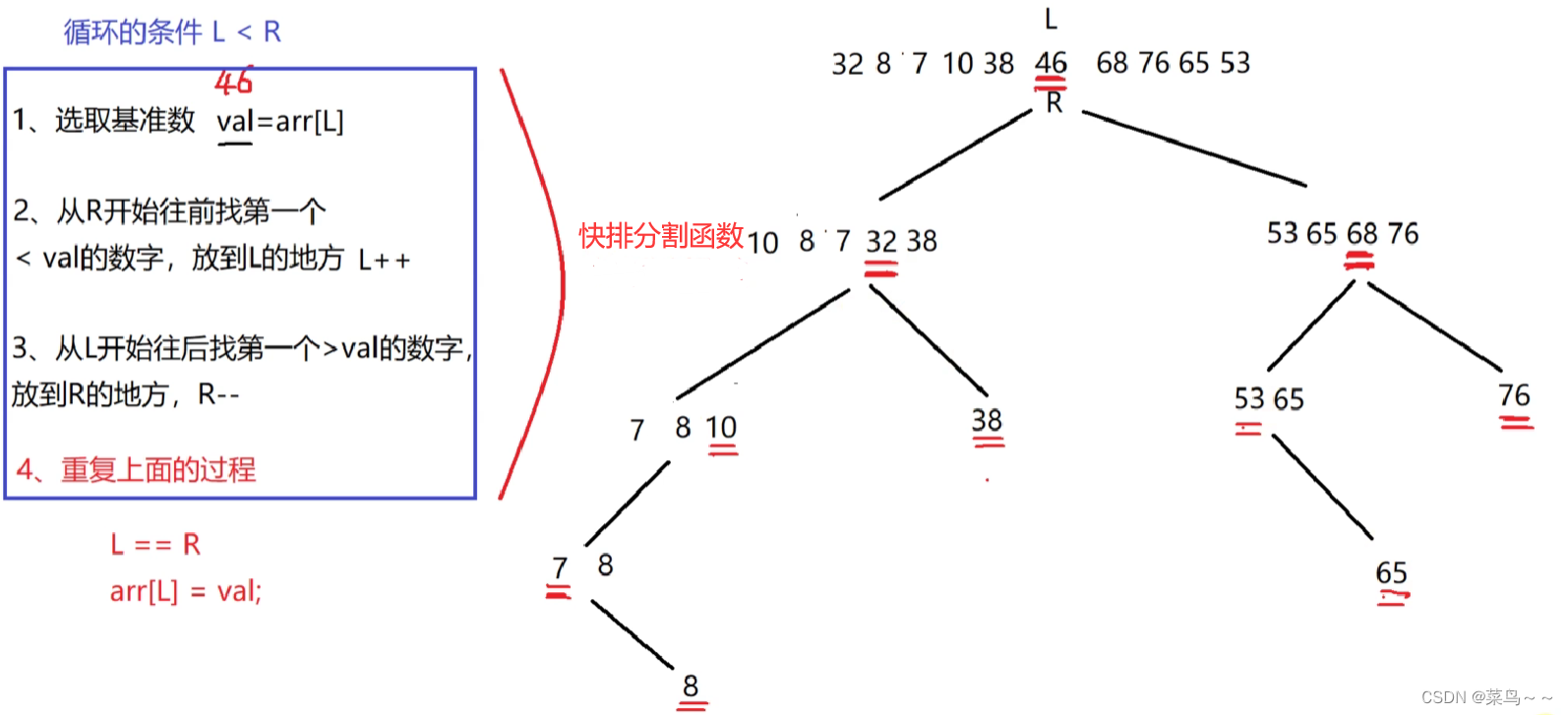
#include<iostream>
using namespace std;
int Partation(int arr[], int l, int r)
{
int val = arr[l];
while (l < r)
{
while (l < r)
{
if (arr[r] < val)
{
break;
}
r--;
}
if (l < r)
{
arr[l] = arr[r];
l++;
}
while (l < r)
{
if (arr[l] > val)
{
break;
}
l++;
}
if (l < r)
{
arr[r] = arr[l];
r--;
}
}
arr[l] = val;
return l;
}
//O(logn)
void QuickSort(int arr[], int l, int r)
{
if (l >= r)
return;
int pos = Partation(arr, l, r);
QuickSort(arr, l, pos - 1);
QuickSort(arr, pos + 1, r);
}
int main()
{
int arr[10] = { 0 };
srand(time(0));
for (int i = 0; i < 10; i++)
{
arr[i] = rand() % 100 + 1;
cout << arr[i] << " ";
}
cout << endl;
QuickSort(arr, 0,9);
for (int v : arr)
{
cout << v << " ";
}
cout << endl;
return 0;
}
最好和平均时间复杂度:O(nlogn)
最坏时间复杂度:O(n^2)
最好和平均空间复杂度:O(logn),递归的深度所占用的栈内存
最坏的空间复杂度:O(n)
稳定性:不稳定,比如5,7,7,3,2。第一个7会放在第二个7的后面。
快排算法优化:
- 随着快排算法的执行,数据越来越趋于有序,在一定范围内,可以采用插入排序代替快速排序;
void InsertSort(int arr[], int l,int r)
{
for (int i = l; i <= r; i++)
{
int j = i - 1;
int val = arr[i];
for (; j >= l; j--)
{
if (arr[j] <= val)
break;
arr[j + 1] = arr[j];
}
arr[j + 1] = val;
}
}
int Partation(int arr[], int l, int r)
{
int val=arr[l];
while (l < r)
{
while (l < r)
{
if (arr[r] < val)
{
break;
}
r--;
}
if (l < r)
{
arr[l] = arr[r];
l++;
}
while (l < r)
{
if (arr[l] > val)
{
break;
}
l++;
}
if (l < r)
{
arr[r] = arr[l];
r--;
}
}
arr[l] = val;
return l;
}
void QuickSort(int arr[], int l, int r)
{
if (l >= r)
return;
if (r - l <= 5)
{
InsertSort(arr, l, r);
return;
}
int pos = Partation(arr, l, r);
QuickSort(arr, l, pos - 1);
QuickSort(arr, pos + 1, r);
}
- 采用“三数取中”法,找合适的基准数
int val=arr[l];
int mid = (l + r) / 2;
if ((arr[l] < arr[mid] && arr[mid] < arr[r])|| arr[r] < arr[mid] && arr[mid] < arr[l])
{
val = arr[mid];
arr[mid] = arr[l];
arr[l] = val;
}
if ((arr[l] < arr[r] && arr[r] < arr[mid]) || arr[mid] < arr[r] && arr[r] < arr[l])
{
val = arr[r];
arr[r] = arr[l];
arr[l] = val;
}
- 随机数法(不靠谱)
7. 归并排序算法
采用“分治思想”,先进行序列划分,再进行元素的有序合并。
递的过程:直到只剩一个元素结束
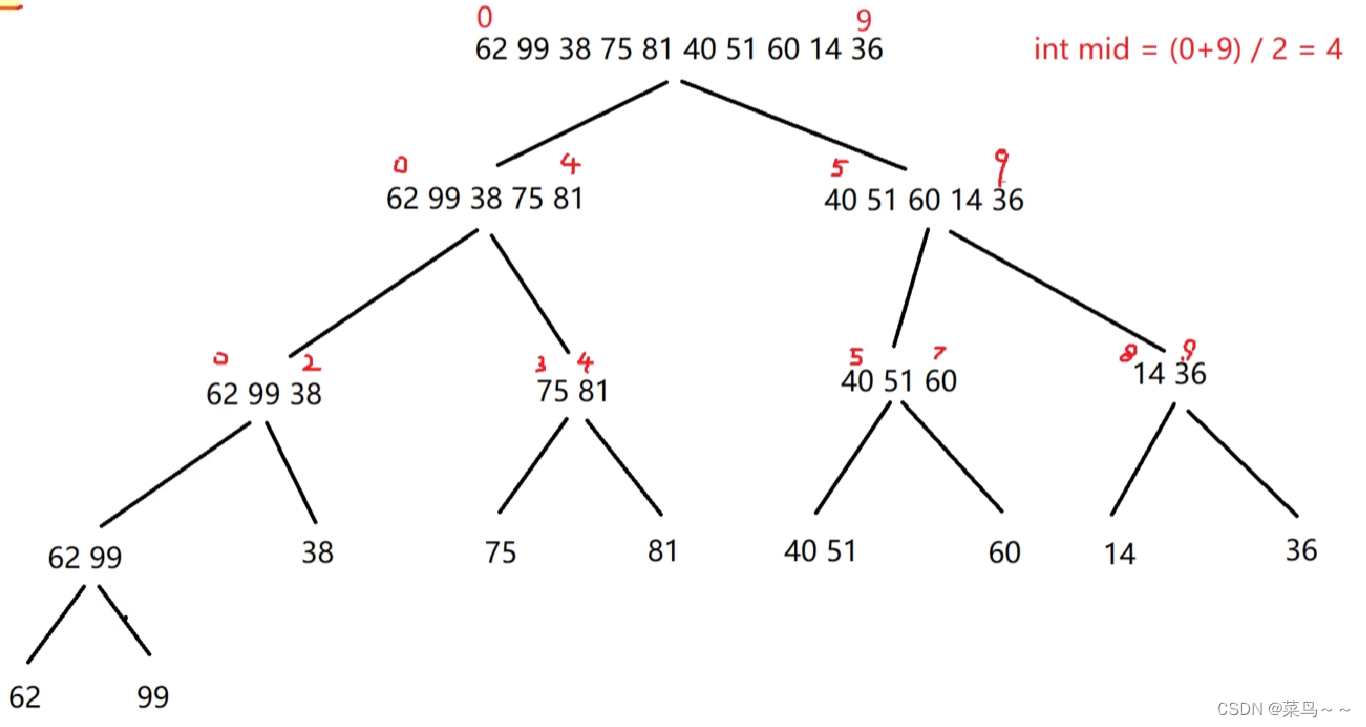
归的过程:需要申请额外的空间
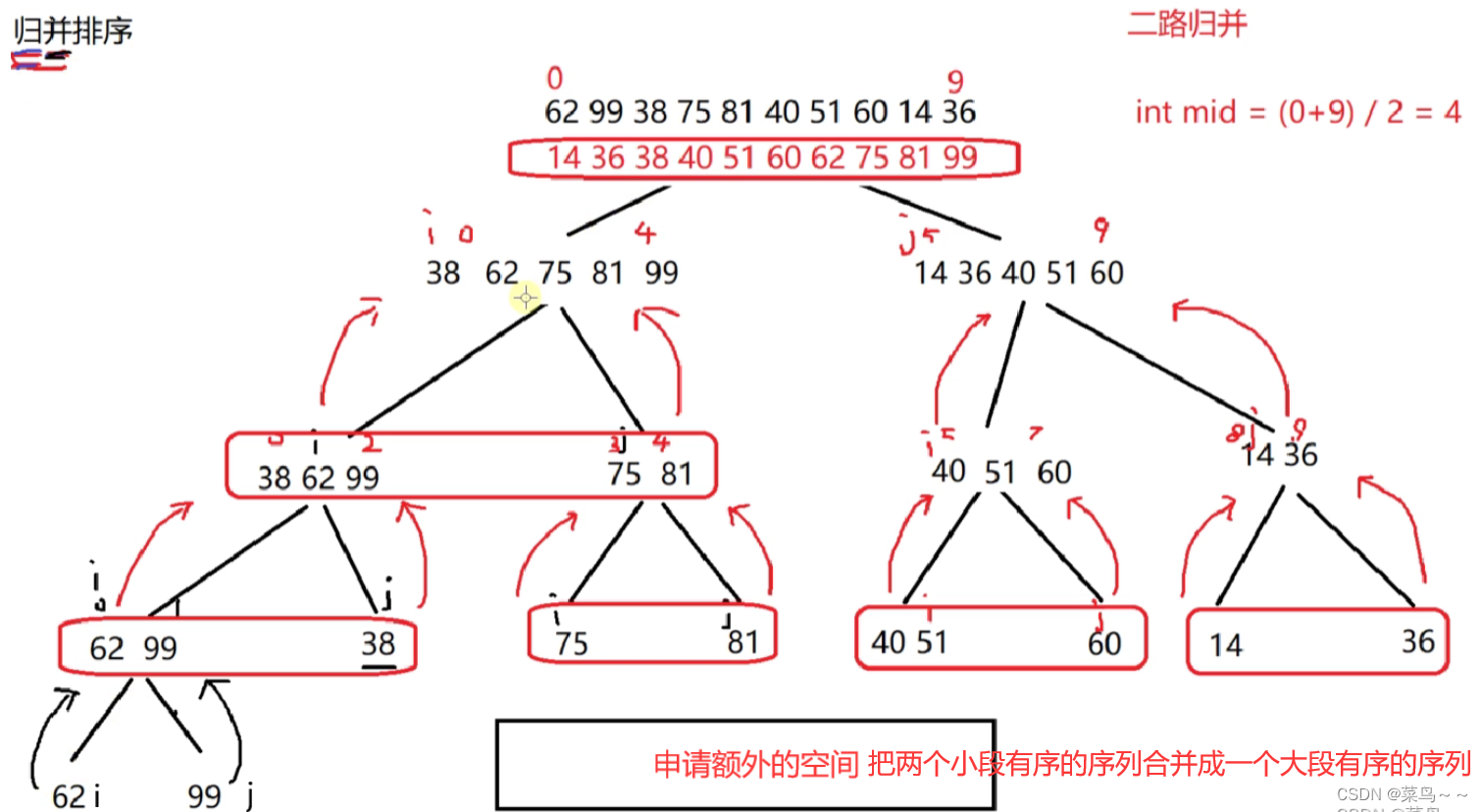
#include<iostream>
#include<time.h>
using namespace std;
void Merge(int arr[], int l, int m, int r)
{
int* p = new int[r - l + 1];
int k = 0;
int i = l, j = m + 1;
while (i <= m && j <= r)
{
if (arr[i] < arr[j])
{
p[k++] = arr[i++];
}
else
{
p[k++] = arr[j++];
}
}
while (i <= m)
{
p[k++] = arr[i++];
}
while (j <= r)
{
p[k++] = arr[j++];
}
for (i = l, j = 0; i <= r; i++, j++)
{
arr[i] = p[j];
}
}
void MergeSort(int arr[], int l, int r)
{
//递归终止条件
if (l >= r)
return;
//先递
int mid = (l + r) / 2;
MergeSort(arr, l, mid);
MergeSort(arr, mid + 1, r);
//再归
Merge(arr, l, mid, r);
}
void MergeSort(int arr[], int size)
{
return MergeSort(arr, 0, size - 1);
}
int main()
{
int arr[10] = { 0 };
srand(time(0));
for (int i = 0; i < 10; i++)
{
arr[i] = rand() % 100;
cout << arr[i] << " ";
}
cout << endl;
MergeSort(arr, 10);
for (int v : arr)
{
cout << v << " ";
}
cout << endl;
return 0;
}
8. 堆排序算法
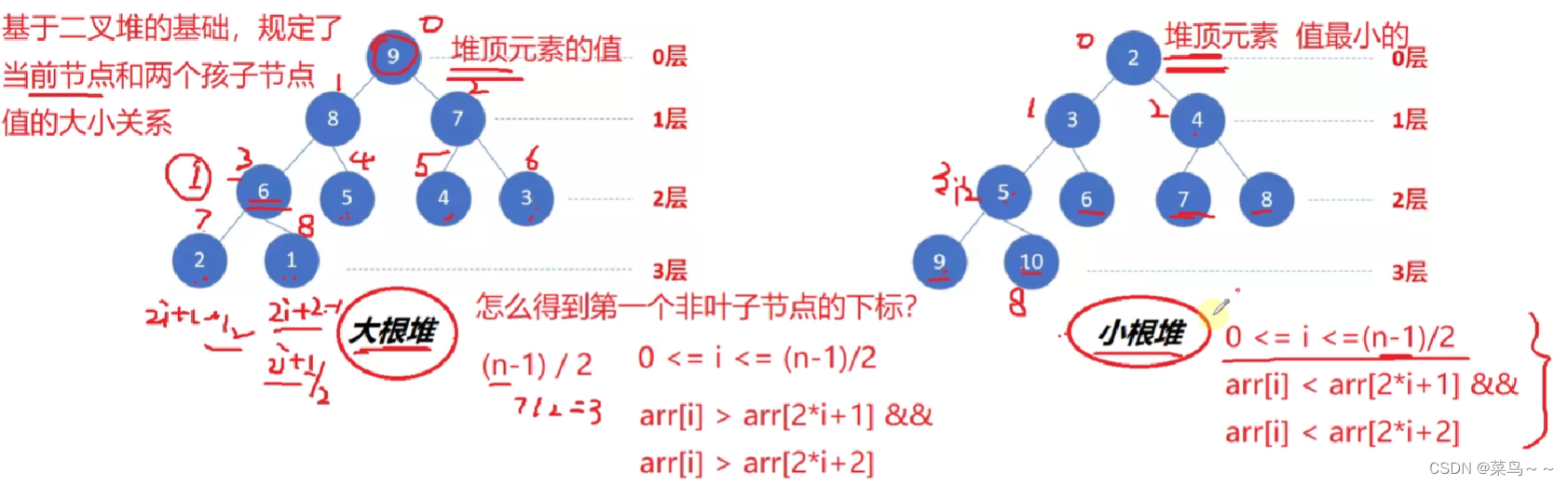
(1)二叉堆&大根堆&小根堆
二叉堆:逻辑上是一颗完全二叉树,存储方式是数组
完全二叉树:每一层的节点都是满的,最后一层的叶子结点都靠左排列
最后一个非叶子结点计算公式:(n-1)/2(n是末尾元素的下标),二叉堆满足0<=i<=(n-1)/2
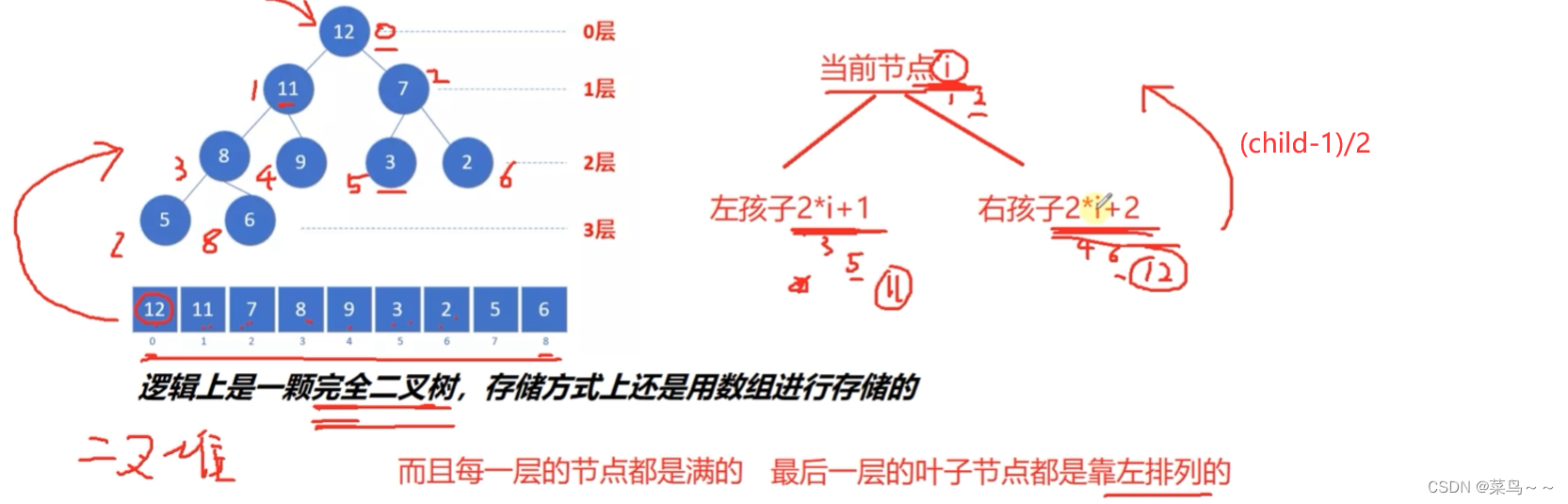
大根堆和小根堆:基于二叉堆的基础,规定了当前节点和两个孩子节点值的大小关系。
- 如果
arrr[i]<=arr[2i+1]&&arr[i]<=arr[2i+2],就是小根堆。 - 如果
arrr[i]>=arr[2i+1]&&arr[i]>=arr[2i+2],就是大根堆。
操作堆只能从堆顶操作
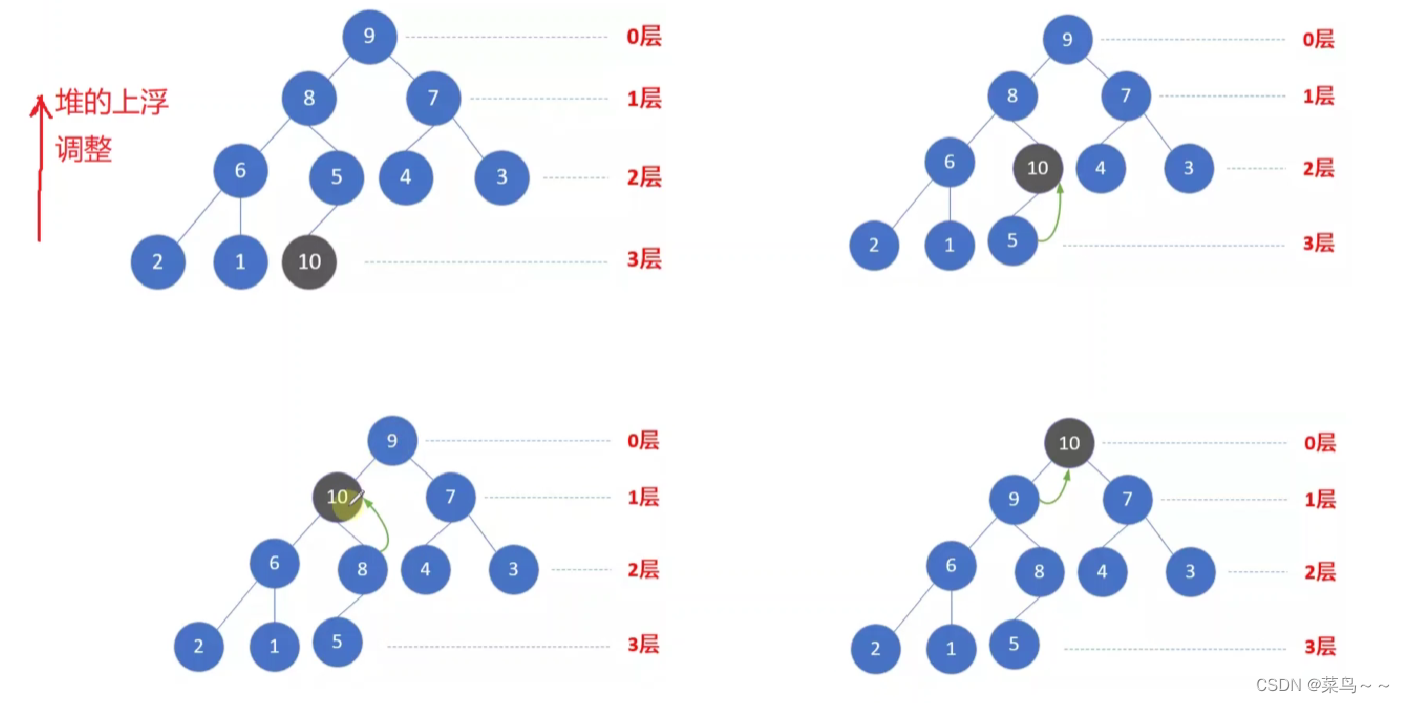
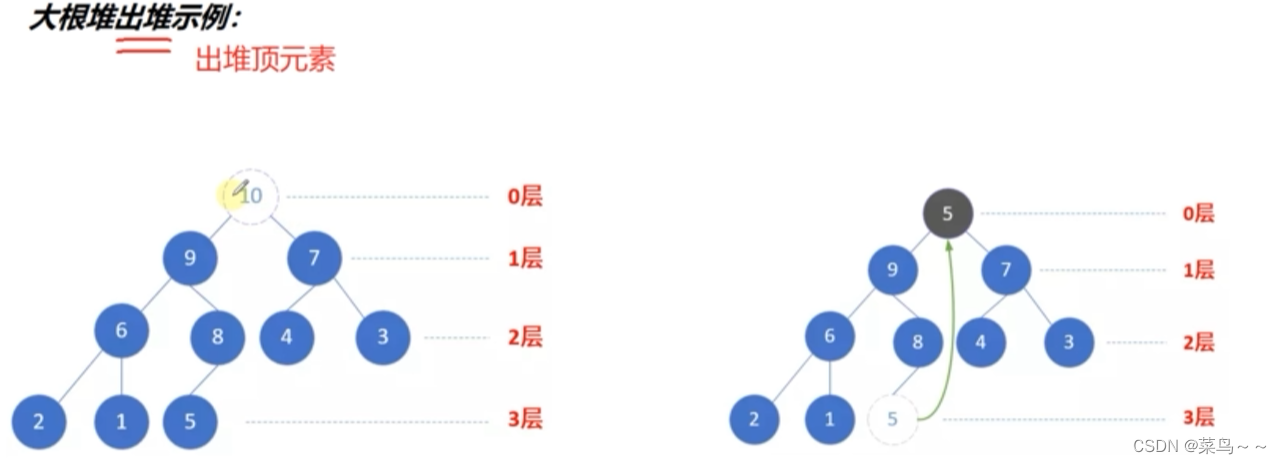
(2) 堆的上浮和下沉调整
入堆:入堆只能从堆底入,然后进行上浮调整
出堆:出堆只能从堆顶出,再将堆底元素放到堆顶,然后进行下沉调整(不断将值大的孩子结点上调,自己下沉,直到没有孩子结点为止,即当前下标大于(n-1)/2)
调堆的时间复杂度和堆的高度:O(logn)
分析:
入堆—堆的上浮调整
出堆—堆的下沉调整
(3)优先级队列的实现
优先级队列,C++的容器适配器,底层是默认实现的大根堆结构。
#include<iostream>
#include<functional>
#include<stdlib.h>
#include<time.h>
using namespace std;
class PriorityQueue
{
public:
//定义堆的函数对象
using Comp = function<bool(int, int)>;
PriorityQueue(int size = 20, Comp comp = greater<int>())
:_size(0), _cap(size), _comp(comp)
{
_ptr = new int[_cap];
}
PriorityQueue(Comp comp)
:_size(0), _cap(20), _comp(comp)
{
_ptr = new int[_cap];
}
~PriorityQueue()
{
delete[]_ptr;
_ptr = nullptr;
}
void push(int val)
{
//判断扩容
if (_size == _cap)
{
int* p = new int[_cap * 2];
memcpy(p, _ptr, _cap * sizeof(_ptr));
delete[]_ptr;
_ptr = p;
_cap *= 2;
}
if (_size == 0)
{
//只有一个元素,不用进行堆的上浮调整
_ptr[_size] = val;
}
else
{
//堆里面有多个元素,需要进行上浮调整
siftUp(_size, val);
}
_size++;
}
void pop()
{
if (_size == 0)
throw "container is empty";
_size--;
if (_size > 0)
{
//删除堆顶元素,还有剩余元素,要进行堆的下沉调整
siftDown(0, _ptr[_size]);
}
}
bool empty()const { return _size == 0; }
int top()const
{
if (_size == 0)
throw "container is empty";
return _ptr[0];
}
int size()const { return _size; }
private:
int* _ptr;
int _size;
int _cap;
Comp _comp;
//堆的上浮调整
void siftUp(int i, int val)
{
while (i > 0)//最多计算到根节点
{
int f = (i - 1) / 2;
if (_comp(val, _ptr[f]))
{
_ptr[i] = _ptr[f];
i = f;
}
else
{
break;
}
}
//把val放到i的位置
_ptr[i] = val;
}
//出堆下沉调整
void siftDown(int i, int val)
{
while (i < _size / 2)//i下沉不能超过最后一个有孩子的节点
{
int child = 2 * i + 1;
if (child + 1 < _size && _comp(_ptr[child + 1], _ptr[child]))
{
child = child + 1;
}
if (_comp(_ptr[child], val))
{
_ptr[i] = _ptr[child];
i = child;
}
else
{
break;
}
}
_ptr[i] = val;
}
};
int main()
{
//生成大根堆
//PriorityQueue que;
//生成小根堆
PriorityQueue que([](int a, int b) {return a < b; });
int arr[10] = { 0 };
srand(time(NULL));
for (int i = 0; i < 10; ++i)
{
que.push(rand() % 100 + 1);
}
while (!que.empty())
{
cout << que.top() << " ";
que.pop();
}
return 0;
}
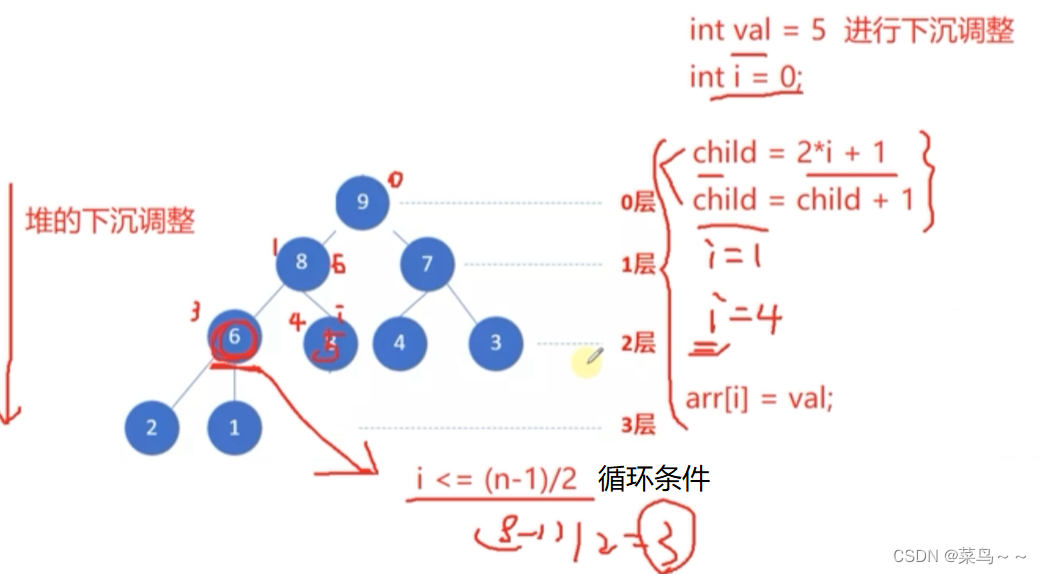
(4)堆排序算法
从小到大排序借助小根堆,从大到小排序借助大根堆。
(1)从最后一个非叶子节点开始调堆,把二叉堆调整成一个大根堆,使得0号节点到最后一个内部节点(n-1)/2全部满足堆性质,n表示最后一个节点的索引。
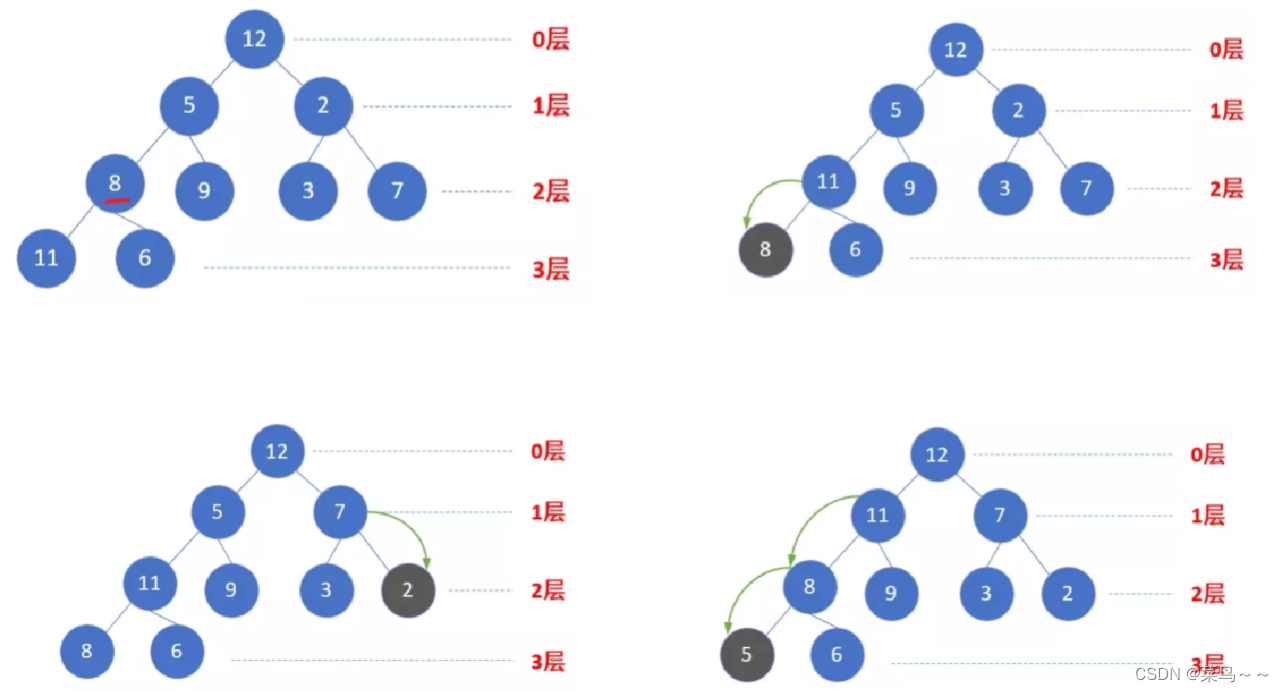
(2)堆顶元素和最后一个元素互换,则完成一个元素的排序任务。
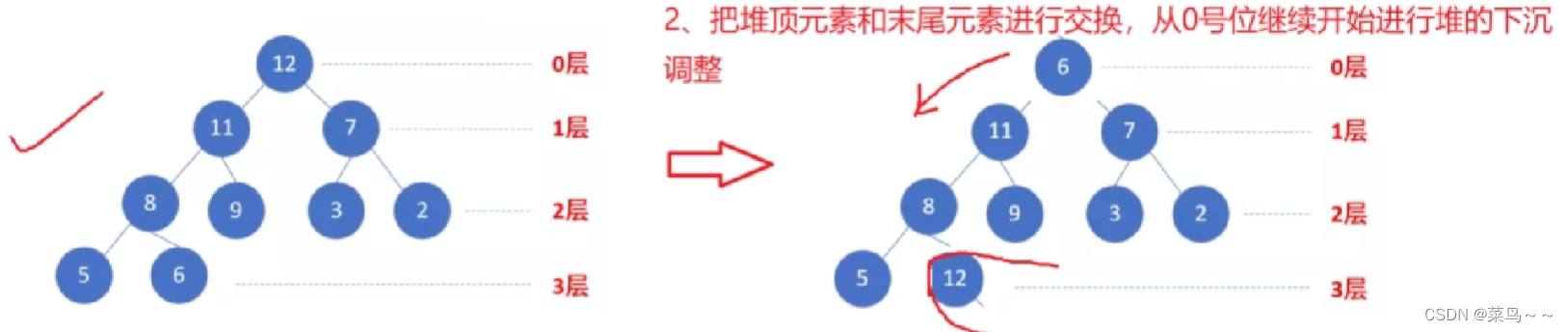
从0号位继续开始进行堆的下沉调整,下次排序少考虑一个元素
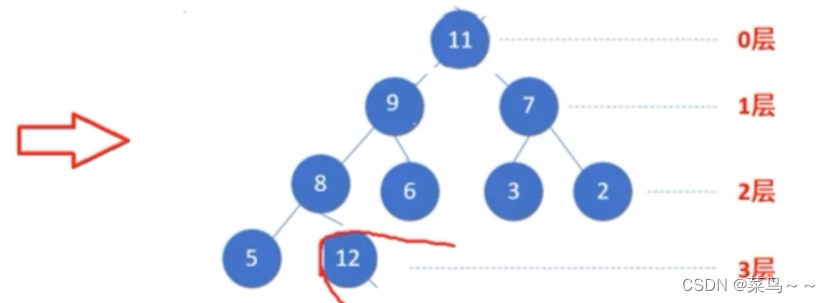
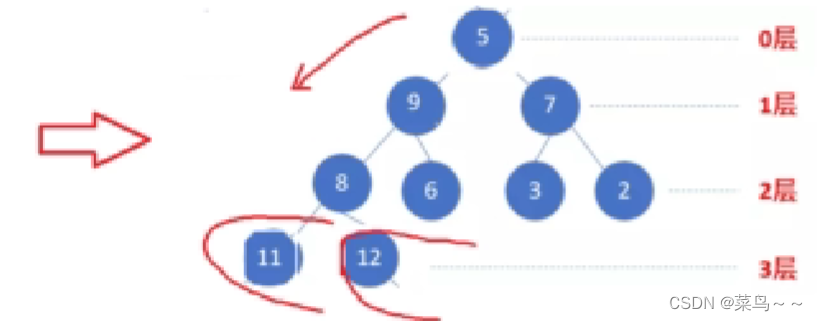
#include<iostream>
#include<time.h>
using namespace std;
//堆的下沉调整
void siftDown(int arr[], int i, int size)
{
int val = arr[i];
while (i < size / 2)
{
int child = 2 * i + 1;
if (child + 1 < size && arr[child + 1] > arr[child])
{
child += 1;
}
if (arr[child] > val)
{
arr[i] = arr[child];
i = child;
}
else
{
break;
}
}
arr[i] = val;
}
void HeapSort(int arr[], int size)
{
int n = size - 1;
//从第一个非叶子节点
for (int i = (n - 1) / 2; i >= 0; i--)
{
siftDown(arr, i, size);
}
for (int i = n; i > 0; i--)
{
int tmp = arr[0];
arr[0] = arr[i];
arr[i] = tmp;
siftDown(arr, 0, i);
}
}
int main()
{
int arr[10] = { 0 };
srand(time(0));
for (int i = 0; i < 10; ++i)
arr[i] = rand() % 100 + 1;
HeapSort(arr, 10);
for (int v : arr)
{
cout << v << " ";
}
cout << endl;
return 0;
}
每一次下沉调整O(logn),每处理完一次都要把堆顶和末尾元素交换,然后继续进行堆的下沉调整,在这里要处理n个元素,把n个元素都要放到堆顶,所以是O(n),所以堆排序的时间复杂度为O(nlogn),空间复杂度为O(1)。
堆排序算法不稳定,只有两个相同元素能建立起比较关系的时候才有机会稳定。在堆排序中,相同值如果处于不同的子树,这两个值就无法比较,不稳定。
9. 快排&归并&堆排

数据量比较大且均匀地时候,快排>归并>希尔>堆排
- 归并排序比快排慢在需要把合并的数据放在临时数组,最后拷贝在原数组;
- 不管是快排还是归并排序,遍历数组的时候都是按顺序访问,这对CPU缓存是友好的(局部性原理),但是堆排序访问元素的时候是按父子节点的关系访问的,并不是按顺序访问,这不符合局部性原理,所以在排序过程中,不管是进行元素上浮还是下沉调整,对CPU缓存不友好,所以排序较慢;
- 每次下沉调整的时候,需要把堆底的元素和堆顶的元素交换,由于堆底的元素是比较小的,所以下沉操作需要进行很多次,才能重新调成一个堆,中间做了很多次比较,无用功太多,这就耗费时间。
10. STL中的sort
C++ STL默认提供以下两个函数接口。第一个函数参数是排序区间,第二个函数参数是排序区间和指定排序方式的函数对象。
void std::sort(const _RanIt _First, const _RanIt _Last)
void std::sort(const _RanIt _First, const _RanIt _Last, _Pr _Pred)
C++ STL默认使用less函数对象,即进行升序排序
template <class _RanIt>
_CONSTEXPR20 void sort(const _RanIt _First, const _RanIt _Last) { // order [_First, _Last)
_STD sort(_First, _Last, less<>{});
}
而实际上,对外提供的两个接口,最后调用的都是三个参数的sort接口,接口源码如下:
template <class _RanIt, class _Pr>
_CONSTEXPR20 void sort(const _RanIt _First, const _RanIt _Last, _Pr _Pred) { // order [_First, _Last)
_Adl_verify_range(_First, _Last); // 检查区间合法性
const auto _UFirst = _Get_unwrapped(_First);
const auto _ULast = _Get_unwrapped(_Last);
_Sort_unchecked(_UFirst, _ULast, _ULast - _UFirst, _Pass_fn(_Pred));
}
主要调用的是_Sort_unchecked函数
void _Sort_unchecked(_RanIt _First, _RanIt _Last, _Iter_diff_t<_RanIt> _Ideal, _Pr _Pred);
_First:首元素的迭代器
_Last:末尾元素后继位置的迭代器
_Ideal:_Sort_unchecked会递归调用,_Ideal的初始值是排序区间元素的个数,每次递归都会减小,用于控制递归层数
_Pred:指定排序方式的函数对象
_Sort_unchecked函数源码:
template <class _RanIt, class _Pr>
_CONSTEXPR20 void _Sort_unchecked(_RanIt _First, _RanIt _Last, _Iter_diff_t<_RanIt> _Ideal, _Pr _Pred) {
// order [_First, _Last)
for (;;) {
// 随着快排的进行,元素会趋于有序
// 快排过程中如果区间不大于 _ISORT_MAX = 32,转入插入排序
if (_Last - _First <= _ISORT_MAX) { // small
_Insertion_sort_unchecked(_First, _Last, _Pred);
return;
}
// _Ideal表示当前区间元素的个数
// 每次递归的时候,都会让_Ideal缩小
// 为了避免递归太深,当_Ideal <= 0的时候,停止递归,采用时间复杂度稳定为O(log2n)的堆排序
if (_Ideal <= 0) { // heap sort if too many divisions
_Make_heap_unchecked(_First, _Last, _Pred);
_Sort_heap_unchecked(_First, _Last, _Pred);
return;
}
// divide and conquer by quicksort
auto _Mid = _Partition_by_median_guess_unchecked(_First, _Last, _Pred);
_Ideal = (_Ideal >> 1) + (_Ideal >> 2); // allow 1.5 log2(N) divisions
if (_Mid.first - _First < _Last - _Mid.second) { // loop on second half
_Sort_unchecked(_First, _Mid.first, _Ideal, _Pred);
_First = _Mid.second;
} else { // loop on first half
_Sort_unchecked(_Mid.second, _Last, _Ideal, _Pred);
_Last = _Mid.first;
}
}
}
总结:

- 主要使用快排,区间元素小于32个时使用插入排序,快排递归次数过多使用堆排序。
- 快速排序不是稳定的O(log2n),最坏的情况会变成O(n^2),可以通过改插入排序或者三数取中的方法改善情况恶化
- 参考STL中sort的源码,可设置变量_Ideal控制递归深度
- 递归太深可能导致函数调用开销过多,甚至栈溢出,程序崩溃
- 快速排序复杂度恶化时,递归会很深,STL的sort中有一个变量_Ideal,每递归一次,_Ideal会减小,当_Ideal变为0是,就会调用稳定的O(nlogn)的堆排序。此外还会判断当前区间的排序元素个数,少于32会转入插入排序,这也能防止递归次数过深导致复杂度恶化。
11. 高级排序常见问题

冒泡会导致比较和交换次数过多,选择排序的比较次数过多,在基本逆序的情况下,插入排序和快排的时间复杂度是O(n^2),不了解数列特征的时候选择稳定的堆排序O(nlogn)

考虑空间复杂度,归并O(n),此时肯定需要使用磁盘IO,效率很低,快速排序递归的空间复杂度为O(log2n)


12. 基数排序(桶排序)


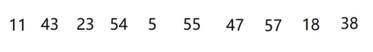

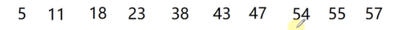
//时间复杂度:O(nd);空间复杂度O(n);稳定
void RadixSort(int arr[], int size)
{
int max = arr[0];
for (int i = 0; i < size; ++i)
{
if (max < arr[i])
{
max = arr[i];
}
}
int len = to_string(max).size();
vector<vector<int>> vecs;
int mod = 10;
int dev = 1;
for (int i = 0; i < len; i++,mod*=10,dev*=10)
{
vecs.resize(10);
for (int j = 0; j < size; j++)
{
//得到当前元素第i个位置的数字
int index = arr[j] % mod / dev;
vecs[index].push_back(arr[j]);
}
//一次遍历所有的桶,把元素拷贝回原来的数组
int k = 0;
for (auto vec : vecs)
{
for (int v : vec)
{
arr[k++] = v;
}
}
vecs.clear();
}
}
由于按照数值索引,无法处理负数
改进:
void RadixSort(int arr[], int size)
{
int max = arr[0];
for (int i = 0; i < size; ++i)
{
if (max < abs(arr[i]))
{
max = abs(arr[i]);
}
}
int len = to_string(max).size();
vector<vector<int>> vecs;
int mod = 10;
int dev = 1;
for (int i = 0; i < len; i++,mod*=10,dev*=10)//O(d),d是数组长度
{
vecs.resize(20);//20个桶,为了能够处理-9~9
for (int j = 0; j < size; j++)
{
int index = arr[j] % mod / dev + 10;
vecs[index].push_back(arr[j]);
}
//O(n)
int k = 0;
for (auto vec : vecs)//O(20)
{
for (int v : vec)//O(n)
{
arr[k++] = v;
}
}
vecs.clear();
}
}
















 3633
3633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









