






论文中的RHLF图解
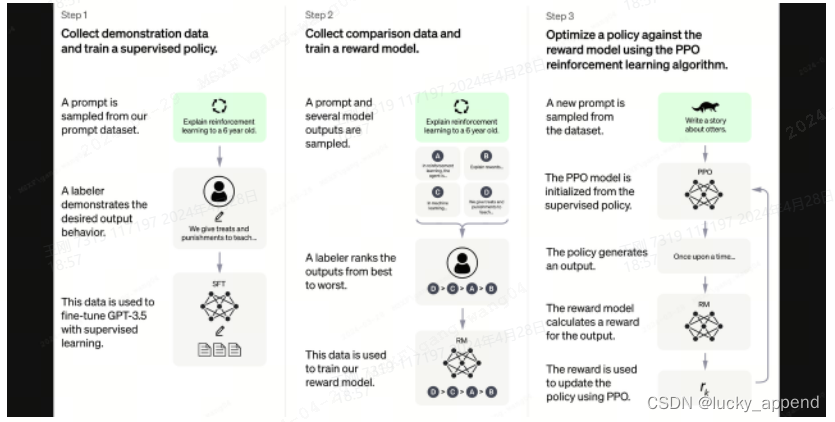
Stage 3 RL的逻辑
-
colossalAI RLHF
-
Stage 1
-
非chat类型的数据,想要学习的领域数据,或者偏好数据,指令数据类型
[ { "instruction": "Provide a list of the top 10 most popular mobile games in Asia", "input": "", "output": "The top 10 most popular mobile games in Asia are:\n1) PUBG Mobile\n2) Pokemon Go\n3) Candy Crush Saga\n4) Free Fire\n5) Clash of Clans\n6) Mario Kart Tour\n7) Arena of Valor\n8) Fantasy Westward Journey\n9) Subway Surfers\n10) ARK Survival Evolved", "id": 0 }, ] -
chat类型的数据,想要学习的对话回复逻辑
[ {"messages": [ { "from": "human", "content": "what are some pranks with a pen i can do?" }, { "from": "assistant", "content": "Are you looking for practical joke ideas?" }, ... ] }, ... ] -
最终转换为数据格式
-
-
Stage 2
-
llama主要在有效果(helpful),安全性(safe)两个方面进行的RLHF调整,所以数据会涉及到这两方面。
-
非chat类型的数据,需要实际看到训练数据格式才能具体了解训练逻辑 。
-
chat类型的数据
[ {"context": [ { "from": "human", "content": "Introduce butterflies species in Oregon." } ] "chosen": [ { "from": "assistant", "content": "About 150 species of butterflies live in Oregon, with about 100 species are moths..." }, ... ], "rejected": [ { "from": "assistant", "content": "Are you interested in just the common butterflies? There are a few common ones which will be easy to find..." }, ... ] }, ... ]
-
-
Stage 3
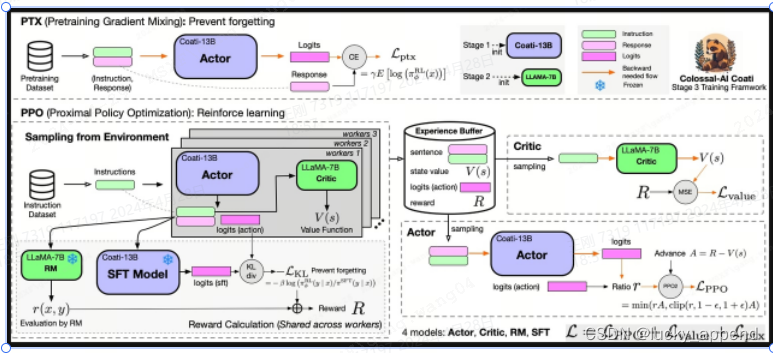
-
从上图中可以看到总共分两步
-
PTX:预训练模型阶梯的混合,PPO于PPO-ptx的重要区别,希望在RLHF的过程中对于公共的,开源的数据集上的表现不降低。
-
PPO
-
-
我个人理解的假设过程,其中RLHF中stage 1的模型已经完成,pretraining和指令微调的模型。
-
训练模型准备步骤:(几个模型加载的模型参数到底是哪个还是需要确认)
-
actor模型对应stage 1中未训练的模型
-
ref|initial模型对应stage 1中未训练的模型
-
reward模型对应stage 2中训练的模型
-
critic模型对应stage 2中未训练的模型
-
(加载模型的方式是先加载模型结构,再加载模型权重。四个模型都会根据输入的参数加载对应的模型参数,给出的实例中只对reward模型进行的模型参数的加载)
-
-
训练数据准备步骤分别加载prompt数据集和pretrain数据集,其中pretrain数据集对应的是去获取预训练模型阶梯的。
-
训练步骤:
-
过程中得出的loss只对actor模型,critic模型进行了参数调整,ref|initial模型和reward模型都没有进行参数调整,只是作为中间变量prompt数据集中exprience的产出。
-
prompt数据先经过actor模型产生结果,计算得到action_log_probs。prompt数据再经过initial模型,产生结果,计算得到base_action_log_probs。prompt数据经过critic模型得到结果value。prompt数据经过reward模型得到结果r。
-
结合上述得到的r,action_log_probs,base_action_log_probs计算reward奖励机制。advantage = reward - value最后得到advantage,就是exprience。
-
(sequences对应的每个prompt数据集中的数据输入,经过上述操作得到advantages)

-
policy loss:prompt数据集中的数据得到的exprience,actor模型,PolicyLoss获取loss,更新actor模型。
-
ptx loss:pretrain数据集中的数据,actor模型,GPTLMLoss获取loss,更新actor模型。
-
value loss:prompt数据集中的数据得到的exprience,critic模型,ValueLoss获取loss,更新critic模型。
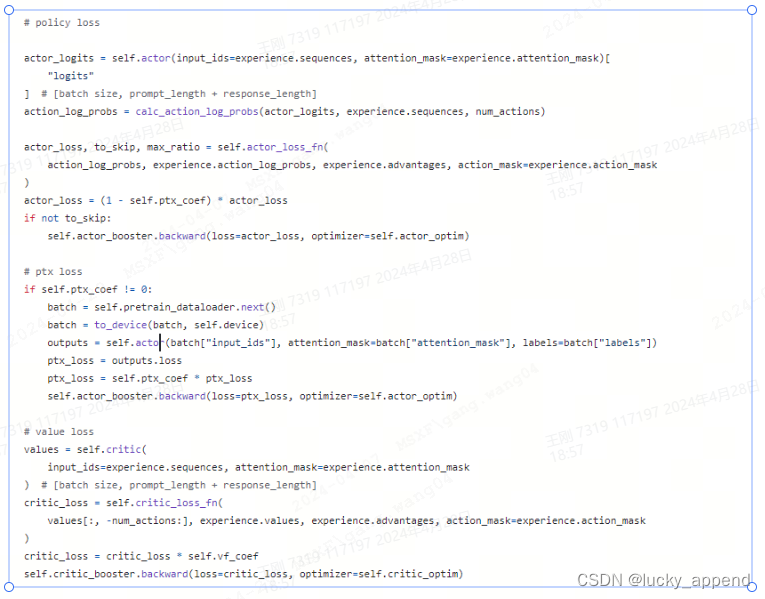
-
-
-
总结
-
Stage 1,Stage 2的目的就是得到一个reward model使其可以自动判断喜好,Stage 1 SFT得到的模型不会在之后的过程中使用,因为其只是一个中间件,我们最终需要得到的是一个经过reward model调教之后的模型。
-
-
-
deepspeed RLHF
-
Stage 3
-
加载模型,应该是将stage 1和stage 2产生的模型参数加载进来了
-
使用exp data生成exprience
-
产生对应actor loss和critic loss,更新调整对应模型参数,基本于collossalAI差不多
-
unsup data作用于actor生成loss,更新actor模型(对应PPO-ptx)
-
-
















 8219
8219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









