






NLP词向量处理方法
借鉴链接附上,如有侵权请联系我:
链接:
https://blog.csdn.net/weixin_55073640/article/details/123465943
https://zhuanlan.zhihu.com/p/114538417
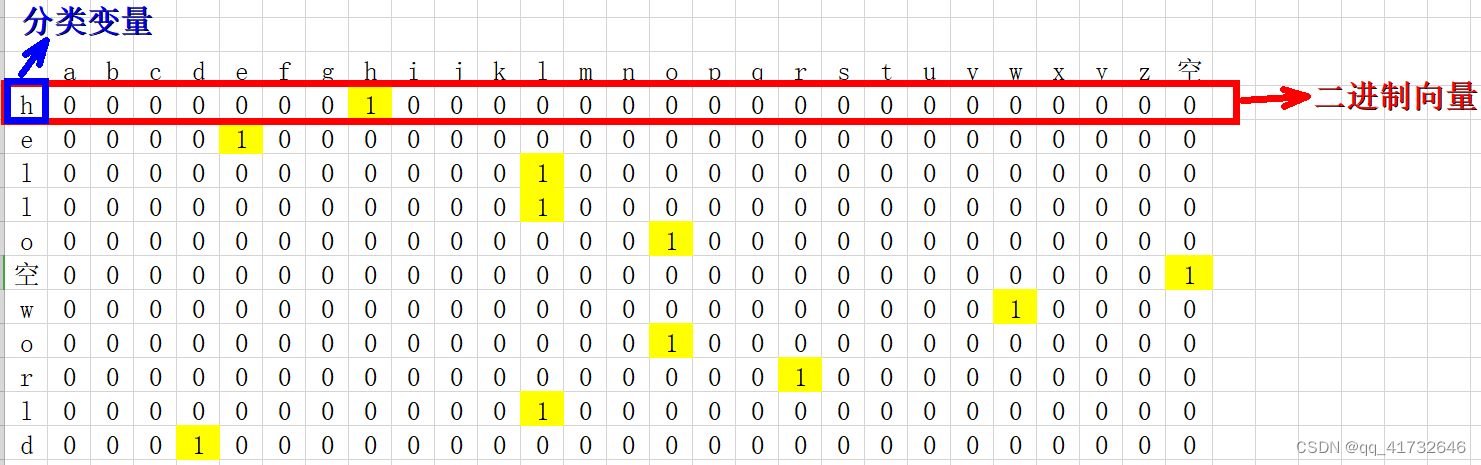
onehot编码
NLP 中最直观,也是到目前为止最常用的词表示方法是 One-hot Representation,这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词。
优点
独热编码解决了分类器不好处理属性数据的问题,在一定程度上也起到了扩充特征的作用。它的值只有0和1,不同的类型存储在垂直的空间。
缺点
1.当类别的数量很多时,特征空间会变得非常大。在这种情况下,一般可以用PCA来减少维度。而且one hot encoding+PCA这种组合在实际中也非常有用。
2.在文本特征表示上有些缺点就非常突出了。首先,它是一个词袋模型,不考虑词与词之间的顺序(文本中词的顺序信息也是很重要的);其次,它假设词与词相互独立(在大多数情况下,词与词是相互影响的);最后,它得到的特征是离散稀疏的。
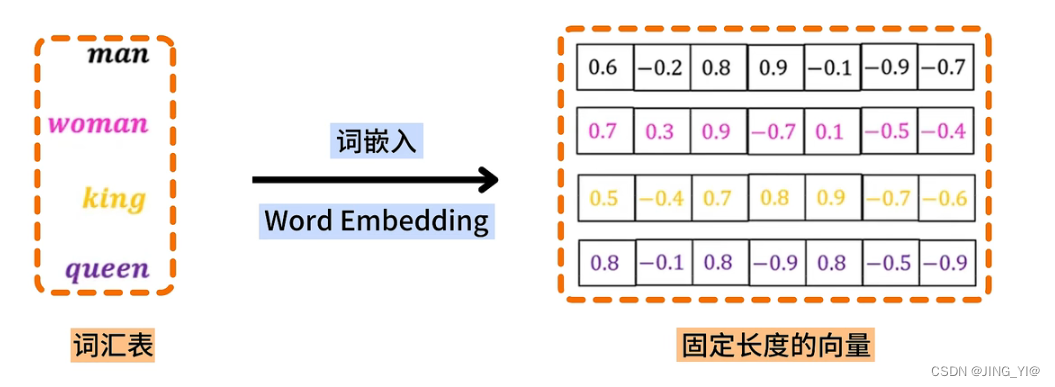
Word Embedding
- 通过一定的方式将词汇映射到指定维度(一般是更高维度)的空间.
- 广义的word embedding包括所有密集词汇向量的表示方法,如后面要学习的word2vec,即可认为是word embedding的一种.
- 狭义的word embedding是指在神经网络中加入的embedding层,对整个网络进行训练的同时产生的embedding矩阵(embedding层的参数),这个embedding矩阵就是训练过程中所有输入词汇的向量表示组成的矩阵.
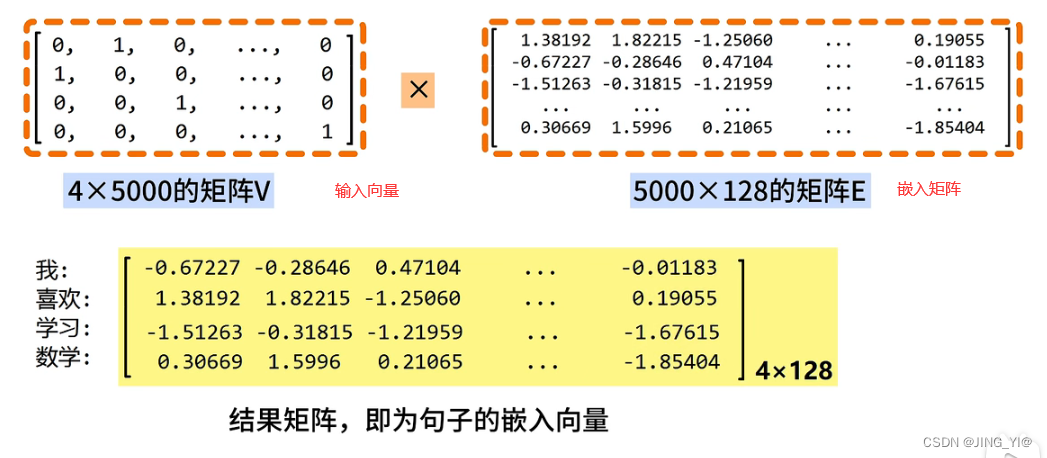
word embedding API
torch.nn.Embedding(num_embeddings , embedding_dim)参数介绍:
- num_embeddings:词典的大小
- embedding_dim : embedding的维度
使用方法:
embedding = nn.Embedding(vocab_size , 128)#实例化,对应下图词表为5000,嵌入维度为128。若使用onehot编码则初始输入向量为4*5000矩阵,经由变换成为了4*128的嵌入向量。
input_embeded = embedding(input)#进行embedding的操作
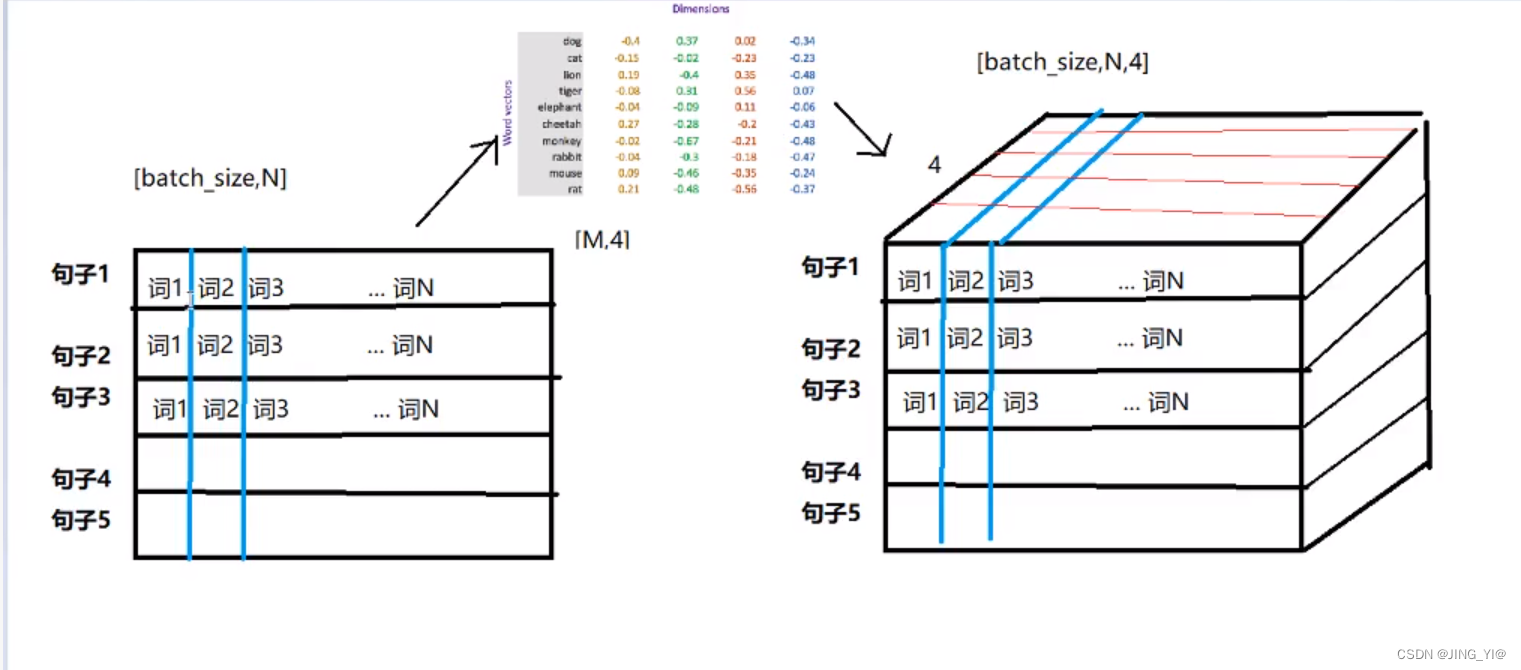
数据的形状变化
思考:每个batch中的每个句子有10个词语,经过形状为[20,4]的Word emebedding之后,原来的句子会变成什么形状?
每个词语用长度为4的向量表示,20是指词表大小,与后续变换无关。所以,最终句子会变为[batch_size,10,4]的形状。增加了一个维度,这个维度是embedding的dim。
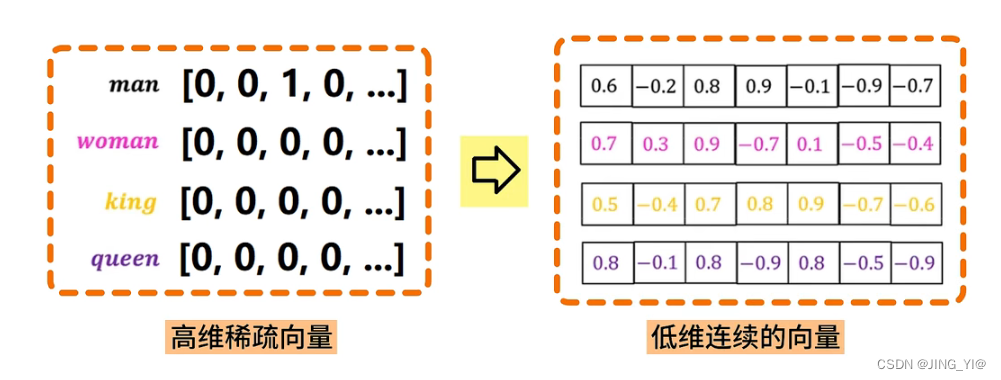
相比One-Hot编码词嵌入具有如下优势:
词嵌入将文本中的词通过一个低维向量来表达,例如128维相比上万维的One-Hot编码,效率上有了质的提升.
word2Vec方法
word2vec是谷歌提出一种word embedding 的工具或者算法集合。Word2Vec是轻量级的神经网络,其模型仅仅包括输入层、隐藏层和输出层,模型框架根据输入输出的不同,主要包括CBOW和Skip-gram模型。CBOW主要是利用上下文来预测当前词。而Skip-gram就是用当前词来预测上下文。
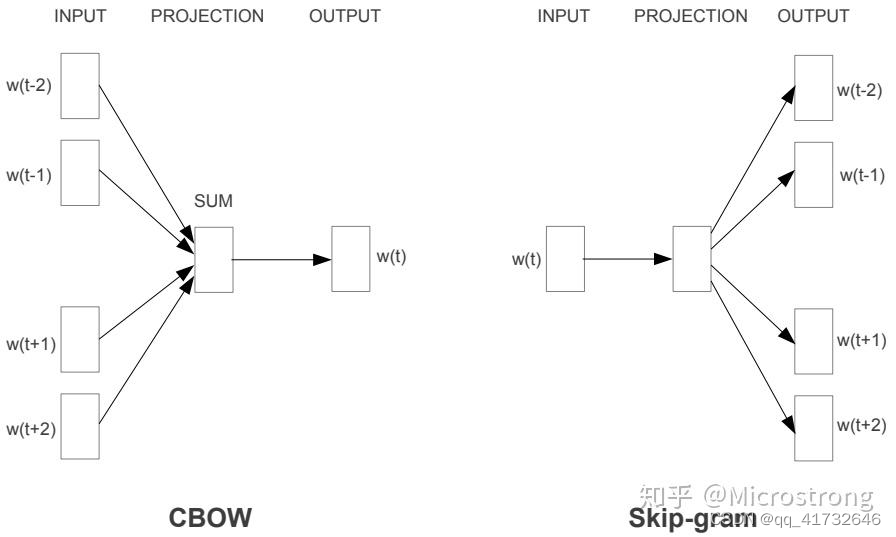
CBOW(连续词袋模型)
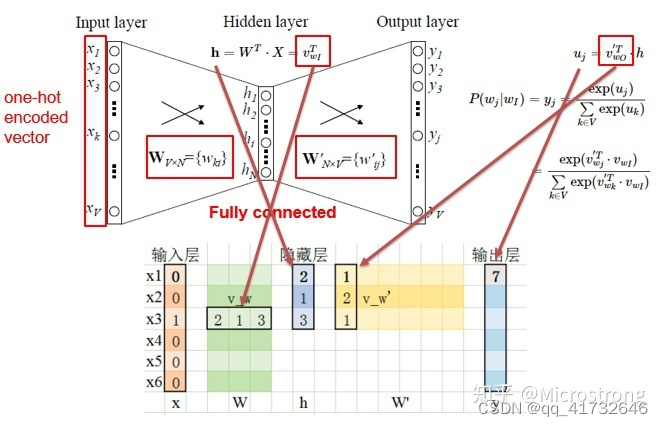
上图展现的是simple CBOW模型,即单输入单输出。
- Input Layer 是指单个词的词向量one-hot表示。考虑一个词表 V V V,里面每一个词 ω i \omega_i ωi,都有一个编号 i ∈ { 1 , . . . ∣ V ∣ } i\isin\{1,...|V|\} i∈{1,...∣V∣},那么此 ω i \omega_i ωi的one-hot表示一个维度为 ∣ V ∣ |V| ∣V∣的向量,其中第 i i i个元素值非零,其余元素均为0。例如: ω 2 = [ 0 , 1 , 0.... , 0 ] T \omega_2=[0,1,0....,0]^T ω2=[0,1,0....,0]T;
- 输入层到隐藏层之间有一个权重矩阵 W W W,隐藏层得到的值是由输入X乘上权重矩阵得到的(细心的人会发现,0-1向量乘上一个矩阵,就相当于选择了权重矩阵的某一行,如图:输入的向量X是[0,0,1,0,0,0], W W W的转置乘上X就相当于从矩阵中选择第3行[2,1,3]作为隐藏层的值)。
- 隐藏层到输出层也有一个权重矩阵 W ′ W' W′,因此,输出层向量y的每一个值,其实就是隐藏层的向量点乘权重向量 W ′ W' W′的每一列,比如输出层的第一个数7,就是向量[2,1,3]和列向量[1,2,1]点乘之后的结果;
- 最终的输出需要经过softmax函数,将输出向量中的每一个元素归一化到0-1之间的概率,概率最大的,就是预测的词。
CBOW Multi-Word Context Model
了解了Simple CBOW model之后,扩展到CBOW就很容易了,只是把单个输入换成多个输入罢了(划红线部分)。
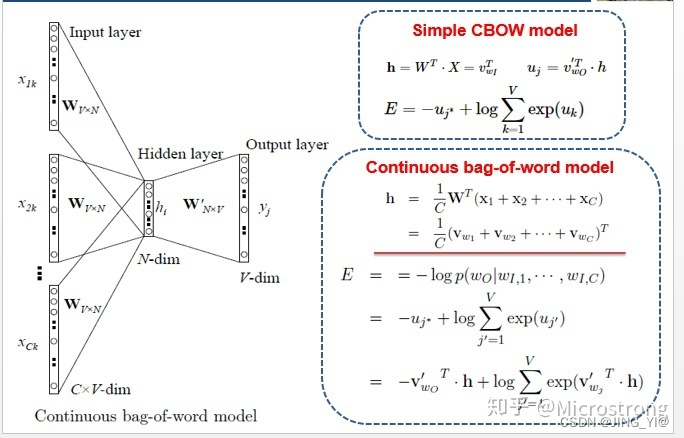
对比可以发现,和simple CBOW不同之处在于,输入由1个词变成了C个词,每个输入
X
i
k
X_{ik}
Xik
到达隐藏层都会经过相同的权重矩阵
W
W
W,隐藏层h的值变成了多个词乘上权重矩阵之后加和求平均值。下列是对网络每一层的分析:
- INPUT:输入的是上下文单词的one hot编码。假设单词向量空间的维度为V,即整个词库大小为V,上下文单词窗口的大小为C。所以输入大小 C * V。
- Hidden:假设hidden layer最终得到的词向量的维度大小为N,INPUT到Hidden的权值共享矩阵(“共享”即每个词乘的W一样)为W。W的大小为 V ∗ N,并且初始化。
我们将C个1 * V大小的向量分别同一个上述所说的V ∗ N大小的W相乘,得到的是C个1 ∗ N 大小的向量。再将这C个1 ∗ N大小的向量取平均,得到一个1 ∗ N 大小的向量。 - OUTPUT:初始化输出权重矩阵大小为N ∗ V的W’将Hidden layer1 ∗ N 的向量与W’相乘,并且用softmax处理,得到1 ∗ V的向量,此向量的每一维代表词库中的一个词。概率中最大的index所代表的单词即为预测出的中间词。
代码
1.引入所需要的库
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
2.导入对应预测文本内容,并进行相应处理(创建词汇表,对单词建立索引,设定预测窗口并完成索引标记)
在此1.txt设置为
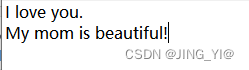 ``
``
path = "1.txt"
f = open(path, 'r', encoding='utf-8', errors='ignore')
text = []
piece = ''
for line in f:
for uchar in line:
if uchar == '\n':
continue
if uchar == '.' or uchar == '?' or uchar == '!':
text.append(piece)
piece = ''
else:
piece = piece + uchar
word_list = " ".join(text).split()
# 将分词后的结果去重
vab = list(set(word_list))
# 对单词建立索引
word_dict = {w: i for i, w in enumerate(vab)} # 单词-索引
data = []
for i in range(2, len(word_list) - 2):
context = [word_list[i - 2], word_list[i - 1],
word_list[i + 1], word_list[i + 2]]
target = word_list[i]
data.append((context, target))
data打印出来是这样的,即前面数组中是上下文,后面的单个单词就是预测的单词。此处预测窗口是5 (4+1),一般还可以选择3。

3.定义CBOW网络模型
class CBOW(nn.Module):
'''''
word_size相当于V;
embedding_dim:嵌入词向量的维度;
context_size相当于一半上下文的大小。CBOW模型中使用的上下文单词数目/2,也可以理解为输入单词的窗口大小。即若为2,则窗口为5.
'''''
def __init__(self, word_size, embedding_dim, context_size):
super(CBOW, self).__init__()
self.embeddings = nn.Embedding(word_size, embedding_dim)
self.linear1 = nn.Linear(2 * context_size * embedding_dim, 128)
# N为128
self.linear2 = nn.Linear(128, word_size)
def forward(self, inputs):
embeds = self.embeddings(inputs).view((1, -1))
out = F.relu(self.linear1(embeds))
out = self.linear2(out)
probs = F.log_softmax(out, dim=1)
return probs
4.定义相关参数以及网络模型训练
EMBEDDING_DIM = 10
CONTEXT_SIZE = 2
losses = []
loss_function = nn.NLLLoss()
model = CBOW(len(vab), EMBEDDING_DIM, CONTEXT_SIZE)
optimizer = optim.SGD(model.parameters(), lr=0.01)
for epoch in range(30):
total_loss = 0
for context, target in data:
# 准备好进入模型的数据
# 这段代码使用PyTorch将输入的上下文列表context中的每个单词转换为对应的整数索引,并将结果存储在列表idxs中。
idxs = [word_dict[w] for w in context]
context_idx = torch.tensor(idxs, dtype=torch.long)
# 梯度置零
model.zero_grad()
# 进入模型训练
log_probs = model(context_idx)
# 计算损失函数
loss = loss_function(log_probs, torch.tensor([word_dict[target]], dtype=torch.long))
# 反向传播并更新梯度
loss.backward()
optimizer.step()
total_loss += loss.item()
print("Epoch:", epoch+1, " Loss:", total_loss)
losses.append(total_loss)
print(losses)
输出结果
Epoch: 1 Loss: 5.777832865715027
Epoch: 2 Loss: 5.395304918289185
Epoch: 3 Loss: 5.041249632835388
Epoch: 4 Loss: 4.7081825733184814
Epoch: 5 Loss: 4.397132158279419
Epoch: 6 Loss: 4.102055191993713
Epoch: 7 Loss: 3.825270652770996
Epoch: 8 Loss: 3.561501145362854
Epoch: 9 Loss: 3.3132278323173523
Epoch: 10 Loss: 3.078549087047577
Epoch: 11 Loss: 2.8582298159599304
Epoch: 12 Loss: 2.651750326156616
Epoch: 13 Loss: 2.457363486289978
Epoch: 14 Loss: 2.2783106565475464
Epoch: 15 Loss: 2.1099923849105835
Epoch: 16 Loss: 1.9543667435646057
Epoch: 17 Loss: 1.8106426000595093
Epoch: 18 Loss: 1.6802804470062256
Epoch: 19 Loss: 1.5579476058483124
Epoch: 20 Loss: 1.4472983479499817
Epoch: 21 Loss: 1.3455210030078888
Epoch: 22 Loss: 1.2528588473796844
Epoch: 23 Loss: 1.1679846048355103
Epoch: 24 Loss: 1.0897139012813568
Epoch: 25 Loss: 1.0190409421920776
Epoch: 26 Loss: 0.9539474844932556
Epoch: 27 Loss: 0.894445538520813
Epoch: 28 Loss: 0.8403486013412476
Epoch: 29 Loss: 0.7909693568944931
Epoch: 30 Loss: 0.7449930906295776
[5.777832865715027, 5.395304918289185, 5.041249632835388, 4.7081825733184814, 4.397132158279419, 4.102055191993713, 3.825270652770996, 3.561501145362854, 3.3132278323173523, 3.078549087047577, 2.8582298159599304, 2.651750326156616, 2.457363486289978, 2.2783106565475464, 2.1099923849105835, 1.9543667435646057, 1.8106426000595093, 1.6802804470062256, 1.5579476058483124, 1.4472983479499817, 1.3455210030078888, 1.2528588473796844, 1.1679846048355103, 1.0897139012813568, 1.0190409421920776, 0.9539474844932556, 0.894445538520813, 0.8403486013412476, 0.7909693568944931, 0.7449930906295776]
Skip-Gram
Skip-gram model是通过输入一个词去预测多个词的概率。输入层到隐藏层的原理和simple CBOW一样,不同的是隐藏层到输出层,损失函数变成C个词损失函数的总和,权重矩阵W’还是共享的。
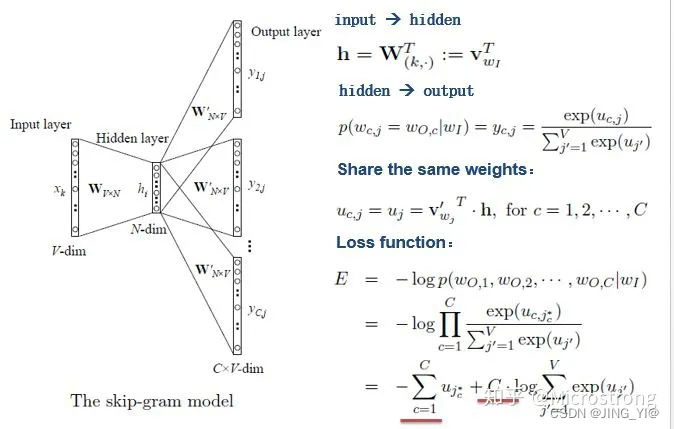
下列是对网络每一层的分析:
- INPUT:输入的是1 * V的one-hot向量x(其中V为词典大小)。
- Hidden:构建一个大小为V * N的嵌入矩阵W(其中N为词向量的维度),所以用这个W和x相乘,得到最终Hidden的输出,大小为1 * N。
- OUTPUT:构建一个大小为N * V的矩阵W’,用W’和Hidden的输出相乘得到最终的输出,大小为1 * V。C个向量就是C*V。
skip-gram的训练过程不是一次性用中心词预测窗口数个词,而是中心词和一个周围词组成一个训练样本。比如当我们指定窗口为2,那么当前词左右的周围词共有4个。有4个周围词的话就有4个样本,即[中心词,周围词1]、[中心词,周围词2]……这也决定了上述朴素skip_gram模型的输出是大小为1 * V。(就是这4个1 * V组成了1个当前词预测出上下文4个词)
代码
1.引入所需要的库
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import torch.utils.data as Data
2.文本预处理(1.txt与前文一样)
# 文本预处理
path = "1.txt"
f = open(path, 'r', encoding= 'utf-8', errors= 'ignore')
text = []
piece = ''
for line in f:
for uchar in line:
if uchar == '\n':
continue
if uchar == '.' or uchar == '?' or uchar == '!':
text.append(piece)
piece = ''
else:
piece = piece + uchar
#print(text)
word_list = " ".join(text).split()
print(word_list) #结果['I', 'love', 'you', 'My', 'mom', 'is', 'beautiful']
#将分词后的结果去重
vab = list(set(word_list))
print(vab) #结果['I', 'is', 'My', 'mom', 'you', 'love', 'beautiful']
#对单词建立索引
word_dict = {w:i for i, w in enumerate(vab)} #单词-索引
print(word_dict) #结果{'I': 0, 'is': 1, 'My': 2, 'mom': 3, 'you': 4, 'love': 5, 'beautiful': 6}
3.相关参数设定与数据预处理
# 相关参数
dtype = torch.FloatTensor
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
batch_size = 8
EMBEDDING_DIM = 4 # 词向量的维度是4
CONTEXT_SIZE = 2 # window size
voc_size = len(vab)
# 数据预处理
data = []
for idx in range(CONTEXT_SIZE, len(word_list) - CONTEXT_SIZE):
center = word_dict[word_list[idx]] # 中心词
# 中心词和每个周围词组成一个训练样本
for j in range(idx - CONTEXT_SIZE, idx + CONTEXT_SIZE + 1):
if j == idx:
continue
data.append([center, word_dict[word_list[j]]])
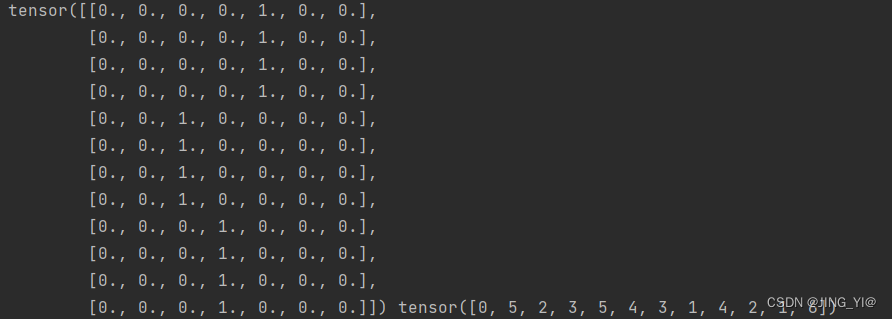
print(data) #结果[[4, 0], [4, 5], [4, 2], [4, 3], [2, 5], [2, 4], [2, 3], [2, 1], [3, 4], [3, 2], [3, 1], [3, 6]]
input_data = []
output_data = []
for i in range(len(data)):
# input_data转换为one-hot形式,output_data合成一个list
input_data.append(np.eye(voc_size)[data[i][0]])
output_data.append(data[i][1])
input_data, output_data = torch.Tensor(input_data), torch.LongTensor(output_data)
dataset = Data.TensorDataset(input_data, output_data)
loader = Data.DataLoader(dataset, batch_size, True)
print(input_data,output_data)的结果是这样的,对照print(data) #结果[[4, 0], [4, 5], [4, 2], [4, 3], [2, 5], [2, 4], [2, 3], [2, 1], [3, 4], [3, 2], [3, 1], [3, 6]],帮助理解
4.构建Skip_gram模型
class Skip_gram(nn.Module):
def __init__(self):
super(Skip_gram, self).__init__()
#self.W是一个形状为(voc_size, EMBEDDING_DIM)的可学习权重矩阵,表示输入词向量与隐藏层之间的转化。
#voc_size代表词汇表的大小,EMBEDDING_DIM代表词向量的维度。
self.W = nn.Parameter(torch.randn(voc_size, EMBEDDING_DIM).type((dtype)))
#self.V是一个形状为(EMBEDDING_DIM, voc_size)的可学习权重矩阵,表示隐藏层与输出词向量之间的转化。
self.V = nn.Parameter(torch.randn(EMBEDDING_DIM, voc_size).type((dtype)))
#forward方法接受一个输入input,它是一个形状为(batch_size, input_size)的张量,其中input_size代表输入的词向量维度。
#在forward方法中,首先将输入词向量与权重矩阵self.W相乘,得到隐藏层的表示hidden。这里使用了torch.matmul函数进行矩阵乘法运算。
#接着,将隐藏层表示与权重矩阵self.V相乘,得到输出的词向量表示output。
def forward(self, input):
hidden = torch.matmul(input, self.W)
output = torch.matmul(hidden, self.V)
return output
5.开始训练啦
model = Skip_gram().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=0.01)
for epoch in range(1000):
total_loss = 0
for i , (x, y) in enumerate(loader):
x = x.to(device)
y = y.to(device)
pred = model(x)
loss = criterion(pred, y)
# i表示当前的索引(即批次数),这里是两批,data=12,batch_size=8,(8+4)
if (epoch + 1) % 50 == 0:
print(epoch + 1, i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
print("Epoch:", epoch+1, " Loss:", total_loss)
输出结果
Epoch: 1 Loss: 8.472830057144165
Epoch: 2 Loss: 7.501566171646118
Epoch: 3 Loss: 8.09452748298645
Epoch: 4 Loss: 7.4987571239471436
Epoch: 5 Loss: 7.117967128753662
Epoch: 6 Loss: 6.324106812477112
Epoch: 7 Loss: 7.214094400405884
Epoch: 8 Loss: 6.785226345062256
Epoch: 9 Loss: 7.5581488609313965
Epoch: 10 Loss: 6.545481443405151
Epoch: 11 Loss: 5.821583271026611
Epoch: 12 Loss: 6.536340236663818
Epoch: 13 Loss: 5.82330584526062
Epoch: 14 Loss: 5.830262660980225
Epoch: 15 Loss: 5.894265174865723
Epoch: 16 Loss: 6.236735105514526
Epoch: 17 Loss: 5.859234809875488
Epoch: 18 Loss: 5.828025817871094
Epoch: 19 Loss: 5.150759935379028
Epoch: 20 Loss: 4.7668105363845825
Epoch: 21 Loss: 5.132047414779663
Epoch: 22 Loss: 4.6761651039123535
Epoch: 23 Loss: 4.985729455947876
Epoch: 24 Loss: 5.049295663833618
Epoch: 25 Loss: 4.684504270553589
Epoch: 26 Loss: 4.623528957366943
Epoch: 27 Loss: 4.766409873962402
Epoch: 28 Loss: 4.5114521980285645
Epoch: 29 Loss: 4.711355209350586
Epoch: 30 Loss: 4.440001010894775
Epoch: 31 Loss: 4.551765203475952
Epoch: 32 Loss: 4.397887468338013
Epoch: 33 Loss: 4.356009483337402
Epoch: 34 Loss: 4.176387310028076
Epoch: 35 Loss: 4.252211570739746
Epoch: 36 Loss: 4.081496477127075
Epoch: 37 Loss: 4.089355945587158
Epoch: 38 Loss: 4.025074005126953
Epoch: 39 Loss: 3.833372473716736
Epoch: 40 Loss: 3.8738949298858643
Epoch: 41 Loss: 3.959350824356079
Epoch: 42 Loss: 4.033707618713379
Epoch: 43 Loss: 3.8661465644836426
Epoch: 44 Loss: 3.8452646732330322
Epoch: 45 Loss: 3.6065515279769897
Epoch: 46 Loss: 3.665121912956238
Epoch: 47 Loss: 3.6360924243927
Epoch: 48 Loss: 3.7820838689804077
Epoch: 49 Loss: 3.993691563606262
50 0 1.8122646808624268
50 1 1.933388590812683
Epoch: 50 Loss: 3.74565327167511 #为一个批次的每个batch相加之和
......















 1063
1063











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









