






算法思想
期望值最大化方法,是宇宙演变、物种进化背后的动力。
如果一个公司在制定年终奖标准时,把每个员工一半的奖金和公司价值观挂钩,人们就会背诵创始人每个语录 — 整个公司都会自动迭代寻找最优解,每个人说话都是公司价值观。
如果一个国家足球不行,把每个孩子的高考分数和足球水平挂钩,人们就会大力投资足球设施,大爷大妈也会把广场让出去给孙子踢足球,谁跟我孙子抢我真的会发疯 — 整个国家都会自动迭代寻找最优解,每个人说话都是公司价值观。
这个思想在算法中就是期望最大化 EM 算法,只要给出一个收益函数, 计算机就会自动的寻找收益最大的那个点。
- 在每一时刻,算出能够最大化收益(期望值)的方向,沿着这个方向走一小步
- 然后再从新的起点重复这个过程,不论从何处起始,最后一定能够达到收益最大的那个终点
EM 算法本质是迭代策略,用于含有隐变量的统计模型中,交替计算期望步骤和最大化步骤,来寻找参数的最优估计。
比如看故事书,但故事中有一些缺失的部分(这些就是隐变量)。
你的目标是填补这些缺失部分,使得整个故事变得连贯和合理。
EM 算法就像一个两步循环过程,帮助你逐渐完善这个故事:
-
期望步骤 (E 步骤): 在这一步,你根据目前所知的信息,对故事中缺失的部分做出最佳猜测。就好比你根据故事的上下文来推测这些缺失部分可能的内容。
-
最大化步骤 (M 步骤): 接下来,你根据这些猜测来重新讲述整个故事,并调整故事中其他已知部分的细节,使得整体故事更加合理。这个过程就像根据新的假设来优化故事的连贯性。(M步骤可以使用 MLE 或 MAP)。
这个循环反复进行:你根据当前的故事版本来改善你对缺失部分的猜测,然后再用这些新猜测来优化整个故事。
随着每次迭代,故事变得越来越连贯,直到最终达到一个点,你觉得再怎么调整也无法使故事更好了。
这时,你就找到了最合适的版本来填补缺失部分,你找到了模型参数的最优估计。
再如 市场营销策略:
-
公司在设计营销策略时,通常会试图理解消费者的隐藏需求和偏好(隐藏变量),并据此调整其产品或服务(参数)。
-
通过市场反馈,公司不断调整其策略以最大化销售或品牌影响力,这类似于EM算法的期望步骤和最大化步骤的迭代过程。
算法推导
概率图模型再复杂都可以简化成俩个变量:观测变量x、隐变量z
比如你正在看一部电影:
- 电影中你能直接看到的场景和角色对话等就像是“观测变量”,这些是你直接获得的信息,不需要猜测或推理。
- 然而,电影也有许多你看不到的部分,比如角色的内心想法、未展示的背景故事,或者导演留下的悬念。这些就像是“隐变量”,你无法直接观察它们,但它们对整个故事的剧情发展(趋势就是人心所向)至关重要。
p ( x ∣ θ ) = ∏ i = 1 n p ( x i ∣ θ ) L ( θ ) = log p ( x ∣ θ ) = ∑ i = 1 n log p ( x i ∣ θ ) = ∑ i = 1 n log ∑ z p ( x i , z i ∣ θ ) \begin{aligned} &p(\mathbf{x}|\theta) \begin{aligned}=\prod_{i=1}^np(x_i|\theta)\end{aligned} \\ &{ L ( \theta )} =\operatorname{log}p(\mathbf{x}|\theta) \\ &=\sum_{i=1}^n\log p(x_i|\theta) \\ &=\sum_{i=1}^n\log\sum_zp(x_i,z_i|\theta) \end{aligned} p(x∣θ)=i=1∏np(xi∣θ)L(θ)=logp(x∣θ)=i=1∑nlogp(xi∣θ)=i=1∑nlogz∑p(xi,zi∣θ)
那我们逐步拆解公式原意:
-
联合概率分布:
- 第一行公式表示,观测数据集 x 在给定参数 θ 的条件下的联合概率分布
- 比如你有 3 张卡片,每张卡片上都有一个秘密数字,这个数字可以是 1、2、3 中的任何一个,我们现在要猜每张卡片上的数字是什么。每张卡片上数字的猜测都是独立的,不会影响其他卡片上的猜测。
- 在数学中,这就是我们说的“联合概率分布”,即我们想知道,所有卡片上每一种可能的数字组合出现的整体概率是多少。
- 如所有卡片上都是1的概率是多少(111)、如所有卡片上是123的概率是多少(123)、(222)、(321)、…、(333) 所有可能的数字组合及其相应的概率。
-
对数似然函数:
- 第二行公式,为了不忘记我们的猜测,我们决定把每次猜的结果写在一个日记本上。因为数字可能很大,所以我们用一种特别的数学“捷径”来记日记,这种捷径就是对数。这样,即使我们猜的数字很大,日记本上的数字也不会太长,更容易计算。
- 在数学中,写在日记本上的这种方法叫做“对数似然函数”,一个帮助我们处理大数字的数学工具。
-
对数似然的求和:
- 第三行公式,现在我们决定把日记本上所有的数字加起来,因为我们用了对数,所以加起来很容易。这就像是玩一个加法游戏,把所有的小数字加起来,得到一个总分。
-
边缘概率:
- 第四行公式,第1张是1、第2张是2,第 3 张卡片藏在盒子里(只有第 3 张未知),我们只知道盒子里可能藏着什么数字(1、2、3)。那先专注于部分已知信息,而忽略未知部分的具体细节,猜对所有看得见的卡片的概率是多少。
- 就是计算 第1张是1、第2张是2 的概率,忽略第三张卡片可能的值。
- 这就是数学中的“边缘概率” —— 它允许我们在部分信息未知的情况下,仍对已知部分进行概率计算。
在概率分布上,就是先猜一个 z 的分布(记为 q),使用 E、M 步骤,去逼近真实分布
L
(
θ
)
L(\theta)
L(θ):
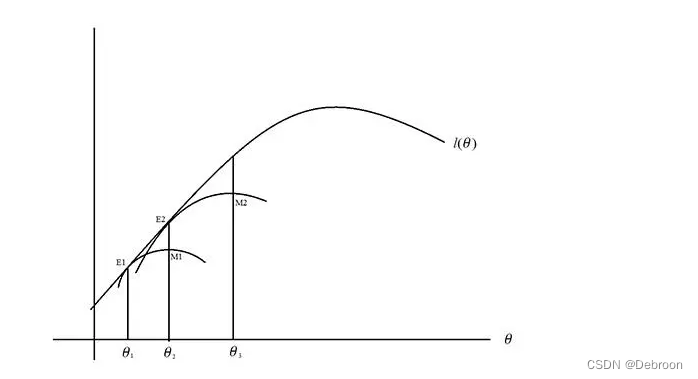
最后让猜的分布像爬楼梯一样,找到真实分布
L
(
θ
)
L(\theta)
L(θ) 的最高点(最优解)。
用数学公式描述这个过程:
L ( θ ) = ∑ i = 1 n log ∑ z p ( x i , z i ∣ θ ) = ∑ i = 1 n log ∑ z ∞ q i ( z ) p ( x i , z i ∣ θ ) q i ( z ) ≥ ∑ i = 1 n ∑ z q i ( z ) log p ( x i , z i ∣ θ ) q i ( z ) \begin{aligned} L(\theta)& \begin{aligned}=&\sum_{i=1}^n\log\sum_zp(x_i,z_i|\theta)\end{aligned} \\ &\begin{aligned}=&\sum_{i=1}^n\log\sum_z^\infty q_i(z)\frac{p(x_i,z_i|\theta)}{q_i(z)}\end{aligned} \\ &\geq\sum_{i=1}^n\sum_zq_i(z)\log\frac{p(x_i,z_i|\theta)}{q_i(z)} \\ \end{aligned} L(θ)=i=1∑nlogz∑p(xi,zi∣θ)=i=1∑nlogz∑∞qi(z)qi(z)p(xi,zi∣θ)≥i=1∑nz∑qi(z)logqi(z)p(xi,zi∣θ)
-
第一行: L ( θ ) = ∑ i = 1 n log ∑ z p ( x i , z i ∣ θ ) L(\theta) = \sum_{i=1}^n \log \sum_z p(x_i, z_i|\theta) L(θ)=∑i=1nlog∑zp(xi,zi∣θ)
- 比如你正在玩一个寻宝游戏,你有一张地图( θ \theta θ),地图上标记了很多可能藏宝的地方(这里的藏宝地方就是 x i x_i xi 和 z i z_i zi)。
- x i x_i xi 是你可以看到的地方,而 z i z_i zi 是地图上标记的,但实际上可能藏宝也可能没藏宝的秘密地方。这一行的意思是,你在尝试弄清楚,根据地图,每个地方藏宝的可能性有多大。
-
第二行: = ∑ i = 1 n log ∑ z ∞ q i ( z ) p ( x i , z i ∣ θ ) q i ( z ) = \sum_{i=1}^n \log \sum_z^\infty q_i(z) \frac{p(x_i, z_i|\theta)}{q_i(z)} =∑i=1nlog∑z∞qi(z)qi(z)p(xi,zi∣θ)
- 这一步就像你在用一种特别的放大镜 q i ( z ) q_i(z) qi(z) 来看地图( θ \theta θ)。
- 这个放大镜可以告诉你,每个秘密地方真的藏宝的机会有多大。
- 你用这个放大镜和地图一起,来计算每个地方可能藏宝的几率。
-
第三行: ≥ ∑ i = 1 n ∑ z q i ( z ) log p ( x i , z i ∣ θ ) q i ( z ) \geq \sum_{i=1}^n \sum_z q_i(z) \log \frac{p(x_i, z_i|\theta)}{q_i(z)} ≥∑i=1n∑zqi(z)logqi(z)p(xi,zi∣θ)
- 最后,这一步就像你在记录你的发现。
- 对于地图上的每一个地方,你都写下了:根据我的放大镜和地图,我认为这里藏宝的机会有多大。”
- 这样,你就得到了一个完整的藏宝地图,上面标记了所有可能藏宝的地方和它们的可能性。
然后根据 Jeasen 不等式,得到公式的下界。
最终的公式是: J ( z , q ) J(z,q) J(z,q)。
- 不断的改变 z,就能不断搜索 θ \theta θ 最大值(概率分布图中的最高点)
于是,EM 算法可分为 E 步骤、M 步骤。
算法流程
E步骤:期望
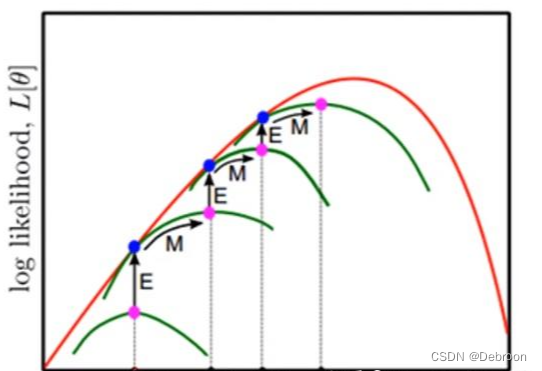
E 步骤:猜的分布 q 不变,最大化 z。
在图中,q 沿着 x 轴上升,碰到真实分布z 就停止,开始 M 步骤。
M步骤:最大化

M 步骤:猜的分布 q 寻优,z 不变。
在图中,q 沿着 y 轴水平移动,碰不到真实分布z 就停止,开始 E 步骤。
陷入局部最优的原因
EM 算法可能会陷入局部最优。
-
非凸目标函数:EM算法通常用于优化非凸(non-convex)的目标函数。在非凸函数中,可能存在多个局部最优解,这意味着算法可能会在达到一个局部最优点后停止,而这个点不一定是全局最优的。
-
初始值依赖性:EM算法的结果往往依赖于初始参数的选择。如果初始参数选得不好,算法可能会被引导到一个局部最优解而不是全局最优解。
-
迭代方式:EM算法通过交替执行其两个步骤(E步和M步)来逐渐改进参数估计。这种迭代方式可能会导致算法“陷入”某个局部区域的最优解,特别是在目标函数有多个峰值的情况下。
-
模型复杂性和数据的局限性:在一些复杂模型或者数据不足的情况下,EM算法可能无法准确估计出全局最优参数,从而陷入局部最优。
解决这些问题的一种方法是通过多次运行算法,每次使用不同的初始参数,然后从中选择最好的结果。
此外,还可以使用全局优化技术,如模拟退火或遗传算法,来辅助找到更接近全局最优的解。
算法应用
高斯混合模型(Gaussian Mixture Model, GMM)
问题描述
假设我们有一组观测数据点,我们认为这些数据点是由两个不同的高斯分布生成的,但我们不知道每个数据点来自哪个高斯分布。
我们的目标是估计这两个高斯分布的参数(均值和方差)以及每个分布对应的混合系数。
输入输出
- 输入:一组观测数据点。
- 输出:两个高斯分布的参数(均值和方差)和混合系数。
Python代码实现
import numpy as np
from sklearn.mixture import GaussianMixture
# 模拟数据生成
np.random.seed(0)
data = np.concatenate([np.random.normal(0, 1, 300), np.random.normal(5, 1.5, 700)]).reshape(-1, 1)
# 应用EM算法
gmm = GaussianMixture(n_components=2, random_state=0)
gmm.fit(data)
# 输出结果
print(f'均值: {gmm.means_.ravel()}')
print(f'方差: {gmm.covariances_.ravel()}')
print(f'混合系数: {gmm.weights_.ravel()}')
这段代码首先生成了一些模拟数据,数据是由两个不同的高斯分布合成的。
然后使用sklearn库中的GaussianMixture模型来应用EM算法。最后,打印出两个高斯分布的均值、方差以及混合系数。
应用到缺失值填充的案例
假设你手上有一组数据,其中部分数据因为某些原因遗失了,你想通过EM算法来估计这些缺失值,从而完善整个数据集。
输入
- 原始数据:一组部分观测到的数据点(例如,人群中的身高数据),其中包含一些缺失值(用
np.nan表示)。
过程
- 初始化:首先,我们使用可观测数据的均值来初步填充这些缺失值。
- EM迭代:通过EM算法的迭代过程(E步骤和M步骤),我们不断更新缺失值的估计,同时也更新整个数据集的均值和方差的估计。
- 收敛检查:在每次迭代后,我们检查均值的变化是否小于一个很小的阈值(如
1e-4),如果是,我们认为算法已经收敛,并停止迭代。
输出
- 填充后的数据集:所有缺失值都被我们估计的值填充,从而得到一个完整的数据集。
- 数据集的统计信息:估计的均值和方差,这些信息可以帮助我们了解填充后数据集的分布情况。
下面的代码实现了上述过程:
import numpy as np
# 模拟数据生成,包含缺失值
np.random.seed(0)
data_complete = np.random.normal(loc=0, scale=1, size=1000) # 完整数据集
missing_indices = np.random.choice(1000, 200, replace=False) # 随机选择200个数据点作为缺失值
data_with_missing = data_complete.copy()
data_with_missing[missing_indices] = np.nan # 将选中的点设为缺失
# 初始估计:用非缺失值的均值填充缺失值
mean_estimate = np.nanmean(data_with_missing)
data_filled = np.where(np.isnan(data_with_missing), mean_estimate, data_with_missing)
# 收敛判定参数
tolerance = 1e-4 # 容忍的最小参数变化
max_iterations = 100 # 最大迭代次数
prev_mean = np.nan # 上一次的均值
# EM算法
for iteration in range(max_iterations):
# E步骤:基于当前填充值计算均值和方差的期望
current_mean = np.mean(data_filled)
current_var = np.var(data_filled)
# 检查收敛
if np.abs(current_mean - prev_mean) < tolerance:
print("EM算法已收敛")
break # 结束循环
prev_mean = current_mean # 更新前一次的均值为当前均值
# M步骤:使用完整数据的期望来更新缺失值的估计
data_filled[missing_indices] = current_mean # 这里简化处理,直接用当前均值填充缺失值
# 打印当前迭代次数和估计的均值,方便观察
print(f"迭代次数: {iteration+1}, 估计的均值: {current_mean}, 估计的方差: {current_var}")
# 输出处理后的数据
print(f"最终估计的均值: {np.mean(data_filled)}")
print(f"最终估计的方差: {np.var(data_filled)}")
假设我们有1000个身高数据点,其中200个是缺失的。
我们的目标是估计这些缺失值,使得我们能够更好地了解这个人群的身高分布。
- 输入:1000个身高数据点,200个缺失。
- 处理:通过EM算法迭代填充缺失值。
- 输出:填充后的完整数据集及其均值和方差的估计。
提问:不是说q不变的吗?为啥q又沿着X轴上升了呢?
嗯嗯,从字面上“q沿着x轴上升”与“q不变”冲突。
-
希望明确“q不变”的含义,以及如何与隐变量的推测过程(E步骤)结合。
-
特别是如何理解q在保持不变的情况下依然可以推测隐变量。
q代表隐变量(无法直接观测到的部分)的后验分布,是我们基于当前模型和已知数据所做的对隐变量的估计。
假设你正在做一个拼图游戏,拼图中有一些部分是缺失的。
你已经根据已拼好的部分做出了一个初步的猜测,认为缺失部分的形状大致是怎样的。
缺失的拼图块应该是什么样的,就是q。
先假设:q 已经由当前的模型参数“推断”出来了,所以在本轮 E 步骤中,“q 的形式”不会再被修改。
我们不改变拼图块的猜测,而是基于这个猜测填补缺失的部分,来计算整体拼图的可能样子。
你不会直接修改猜测的方法,而是用当前的猜测推断这些缺失部分。
q不变是,在E步骤中我们假设当前对隐变量的估计是合理的,意味着我们暂时不去改变隐变量的后验分布q,而是基于它来推断隐变量的具体值。
q沿着x轴上升是更新猜测过程的描述,基于已有的观测数据,不断调整隐变量的估计值(q)。
尽管q的整体形式不变,但在推测隐变量时,q会随着每一个新数据点的加入进行调整,以逐步逼近真实的隐变量分布。
总结:
在 E 步骤,我们先用现有参数(以及上一轮对隐变量的估计)来得到一个新的 q;然后在这一小步内,q 就被“锁定”了(这就是“q 不变”)。
整个 EM 算法会重复执行 E 步骤和 M 步骤,随着不断地迭代(多轮 E 步骤 + M 步骤),q 的分布也会逐渐改变并逼近真实隐变量分布(这看起来就像“q 沿着 x 轴上升”)。
在单次 E 步骤里,你拿着“固定的 q”去填补隐变量;
在迭代的过程中,q 又是在一点点地变化,逐步“爬升”到更符合数据、也让整体似然更高的位置。
提问:我现在需要对一些地面观测站点的PM2.5观测数据进行补缺,有的站点一天24小时只有个别小时缺失;有的站点24个小时全部缺失,由于站点间有经纬度,这种情况可需要考虑空间的临近点来补缺,想问下这两种情况适用于EM算法吗?
空:背景与问题提出
在地面观测的 PM2.5 数据中,经常会出现缺测情况。有的站点一天 24 小时里只缺少几小时数据;有的站点则可能整天的数据全部缺失。由于各站点具有明确的经纬度分布,如果要精确补全缺失数据,就需要同时考虑时间维度(一天内的小时分布、长期趋势)和空间维度(临近站点之间的空气污染物浓度往往存在相关性)。在此背景下,很多人会想到使用 EM 算法等统计方法,结合时空建模,对缺失值进行合理的估计和补全。
雨:核心分析与主要思路
-
EM 算法的适用性:
- 概念:EM(Expectation-Maximization)算法本质上是一种在存在隐藏变量或缺失数据情况下,用于估计模型参数及缺失值的迭代算法。它会在 E 步根据当前模型参数对缺失数据进行期望填补,在 M 步根据填补后的完整数据重新估计模型参数。
- 关键前提:是否可以使用 EM,主要取决于所建立的「概率模型/统计模型」是否合理且能够将“缺失值”纳入到整体的数据生成过程当中。如果在模型里能够体现时空相关性,那么对于部分缺失和全部缺失都可以进行合理估计。
-
缺失类型对模型的影响:
- 部分缺失(只缺少少数小时):
- 如果一天 24 小时里大部分都有观测数据,则站点自身的时间序列信息可以提供较为充分的线索,剩下少量缺失值往往能通过“该站点其他小时 + 空间邻近站点”来补足。
- EM 算法在这种情况下会根据同站点已有观测值和邻近站点的数据,在 E 步时对缺失时段做出最佳估计。
- 全部缺失(整天 24 小时都缺):
- 当某一整天都缺失时,单纯依赖该站点当天的观测规律已经没有任何信息源;需要更多地依靠空间邻近站点的数据以及该站点其他日期的历史信息。
- 如果在模型中对空间和时间相关性做了充分建模,那么 E 步依旧可以借助“相似时间段或周边站点的观测值”对缺失进行推断。但如果模型没有时空相关结构,就会面临估计不稳定甚至无法收敛的问题。
- 部分缺失(只缺少少数小时):
-
时空建模的思路:
- 空间相关性:真实的 PM2.5 分布往往存在空间相关;可以使用空间自回归模型 (SAR)、空间误差模型 (SEM) 或更灵活的地统计学方法(如克里格插值)来刻画站点之间的依赖。
- 时间相关性:大气污染物浓度常随时间呈周期性或趋势性,可用时间序列模型(ARIMA、SARIMA、State-Space Model)、或者结合深度学习模型(LSTM、GCN-LSTM 等)。
- 时空联合:将空间和时间共同纳入模型,才能在遇到“整天缺失”时也可以借助附近站点和过去历史来迭代估计。
-
其他可选方案:
- 地统计插值(Kriging):当注重空间插值时,克里格插值是一种传统且在大气环境领域常用的方法,能直接利用周边站点的空间信息来估计缺失点。
- 机器学习/深度学习方法:例如时空图卷积网络(GCN)+ 时序网络(LSTM/GRU),在拥有足够训练数据时,往往也能取得不错的补缺精度;但实现复杂度和对数据要求也较高。
伞:结论与建议
-
EM 算法对“两种缺失情形”都具备可行性:
只要确保所构建的模型能显式反映时空相关性,EM 算法就能在 E 步环节,用其他时空点的已知信息对缺失数据进行最大似然意义下的估计。无论是只缺少个别小时,还是整天都缺失,只要有足够的关联信息,都可以得到相对合理的填补结果。
-
整天缺失需要更依赖空间邻近与历史信息:
当某一天整天缺失时,如果缺乏时空模型的支持,EM 算法很难仅靠单站点信息来补齐该天数据。因此,在实践中最好建立一个能够显式刻画“站点与站点之间关联”的时空统计或机器学习模型。
当某个站点整天都缺数据时,要确保你的模型在 E 步时可以依赖「其他站点 + 该站点其他时段」所提供的信息来估计完全缺失天的数据。
-
实际工程建议:
- 根据研究和数据需求,先评估选用何种时空模型(空间自回归、克里格、深度学习等)来最好地捕捉空间与时间的关联。
- 在此基础上,用 EM 算法或其他插值方法迭代更新缺失值与模型参数;或者采用专门的时空插值算法来实现缺失值填补。
- 对于高维、全缺失的数据段,要在模型中使用更多先验或额外的限制信息,以提高估计的稳定性和准确度。
总之,这两种缺失情形都可以使用 EM 算法来补缺,但要保证模型能够刻画真实的时空相关性,才能获得准确、稳定的估计结果。这样就能兼顾「只缺少少量小时的数据」与「整天缺失」这两种情形。

















 1073
1073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









