







 文章探讨了如何利用高级知识集成和表型信息来提高罕见病诊断的准确性,特别是通过GPT-4在电子健康记录(EHR)中的应用,如表型提取、筛选罕见病和鉴别诊断。文章强调了动态提示策略、知识图谱和IC值在罕见病诊断中的作用,以及在不同医疗领域中的性能差异。
文章探讨了如何利用高级知识集成和表型信息来提高罕见病诊断的准确性,特别是通过GPT-4在电子健康记录(EHR)中的应用,如表型提取、筛选罕见病和鉴别诊断。文章强调了动态提示策略、知识图谱和IC值在罕见病诊断中的作用,以及在不同医疗领域中的性能差异。
提出背景
- 问题:罕见病诊断难度大,因为医生缺乏对这些病症的先前暴露,导致诊断准确性低。此外,罕见病之间和罕见病与常见病之间的表型重叠增加了识别难度。
解法:高级知识集成提示
- 特征1:利用疾病-表型图和表型图的层次结构
- 特征2:开发基于表型信息内容(IC)值的随机行走算法,实现动态的少量示例提示策略
- 原因:为了提高LLMs(除GPT-4外)在鉴别诊断中的性能,需要整合丰富的知识源并创新提示策略。
人类与LLMs比较研究:
- 选择了来自PUMCH数据集的一个子集,包括75个病例和16种疾病,跨越5个医院科室(心脏病学、血液学、肾脏学、神经学和儿科)
- 23家甲级三等医院选出50名医师
- 通过比较分析,GPT-4在所有5个科室的诊断结果上均优于专家医师
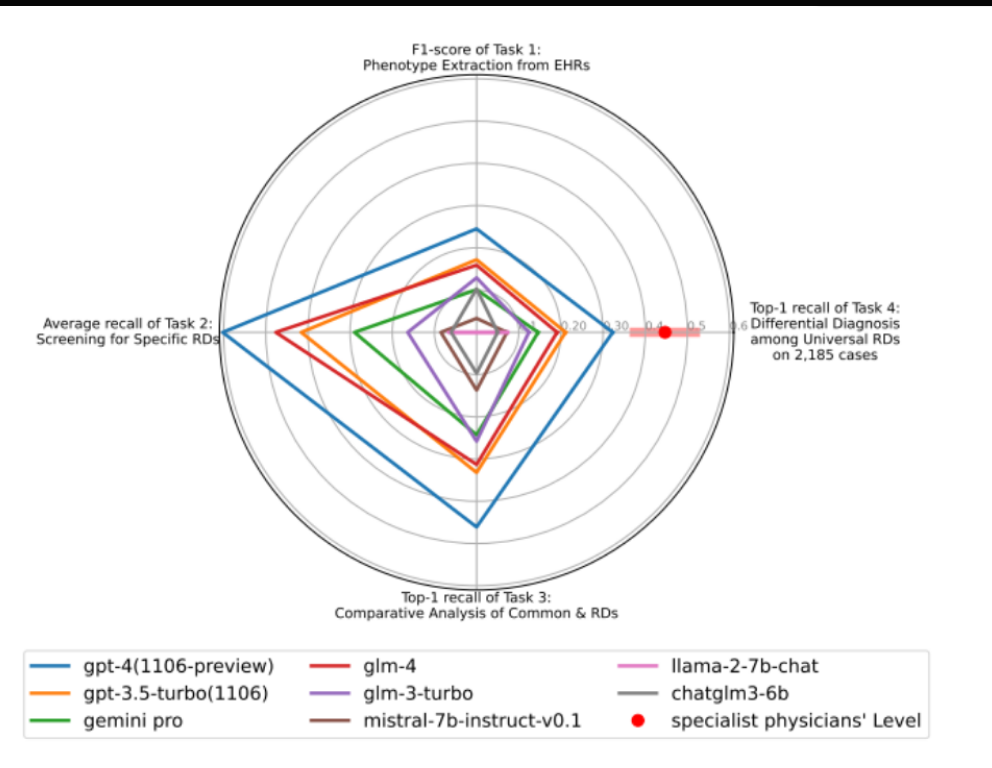
Task 1: 从电子病历EHRs中提取表型的F1分数。
Task 2: 特定罕见病的平均召回率。
Task 3: 常见病与罕见病对比分析的顶级召回率。
Task 4: 在2,185个病例上进行的全球罕见病的鉴别诊断的顶级召回率。
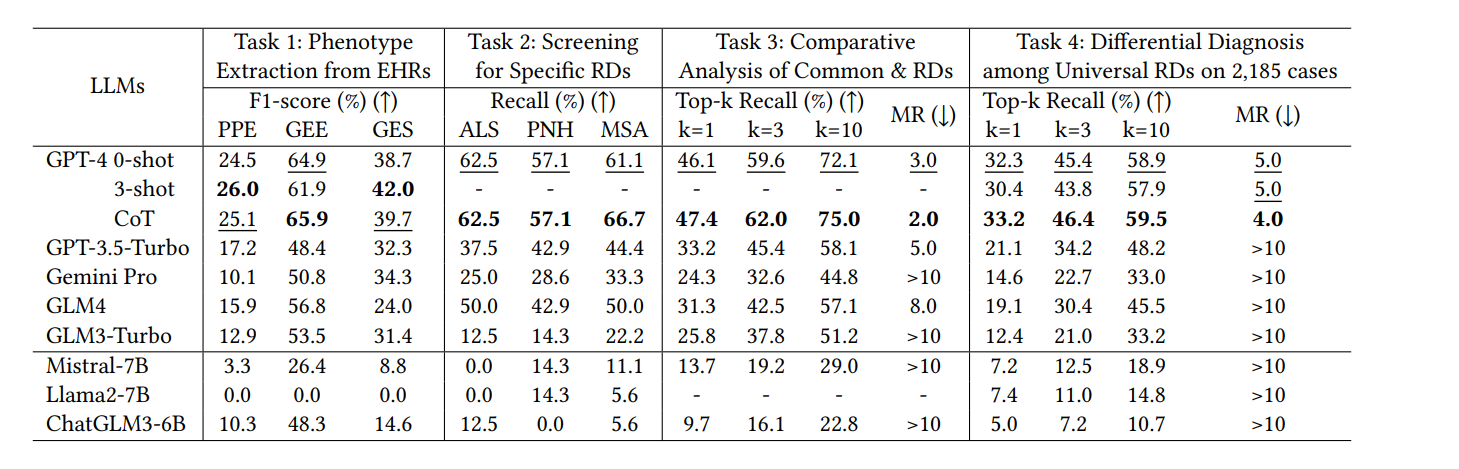
加粗的数字表示最佳结果,下划线的数字表示次佳结果。
实验结果强调了两个关键点:
- 一是使用合适的输入方法(如表型信息输入)可以提高LLMs的诊断性能;
- 二是LLMs的性能在不同的医疗领域和疾病类型上存在差异,这可能与疾病的固有特征及其在(电子病历)EHR文本中的表现方式有关。
此外,实验还展示了在某些情况下,如儿科病例,由于信息的全面性,LLMs能够达到较高的召回率。
然而,在心脏病学等领域,由于症状和体征的相似性和重叠,所有方法的性能都较差,所以在这些领域,客观的辅助检查结果对于鉴别诊断至关重要。
- 在儿科,病例可能会记录详细的生长发育历史和免疫接种记录,这些信息为LLMs提供了全面的背景,使其能够更准确地识别与儿科相关的罕见病。
- 对于心脏病学,由于症状如“胸痛”和“心慌”在多种心脏疾病中都很常见,仅仅依赖文本描述可能难以准确诊断。
- 在这种情况下,LLMs的性能可能不如客观的心电图或心脏超声等辅助检查结果,因为这些检查提供了可以直接用于鉴别诊断的具体生理数据。
解法:高级知识集成提示
-
特征1(知识图构建):创建疾病-表型图和表型图的层次结构,将罕见病的复杂表型信息结构化地表示出来。
-
之所以使用知识图构建,是因为罕见病诊断的一个主要挑战是大量的表型信息和它们之间的复杂关系。
构建疾病-表型图和表型图的层次结构能够清晰地表示这些复杂信息,使LLMs能更有效地理解和处理罕见病的表型数据。
-
-
特征2(动态提示策略):开发一种基于表型信息内容(IC)值的随机行走算法,用于实现动态的少量示例提示策略,以优化LLMs的查询和诊断性能。
-
之所以使用动态提示策略,是因为传统的少量示例提示方法在面对罕见病这种高度专业化和信息稀缺的领域时效果有限。
通过利用表型信息内容(IC)值和随机行走算法,动态提示策略能够根据具体的病例特征,智能地选择最相关和信息丰富的示例,从而显著提高LLMs在罕见病诊断中的性能和准确性。
-
高级知识集成提示这种方法的关键在于,它能够动态地根据每个病例的具体情况调整提示策略,使LLMs能够更有效地利用有限的信息进行高质量的诊断决策。
这不仅提高了诊断的准确性,也减少了对大量训练数据的依赖,对于数据稀缺的罕见病诊断具有重要意义。
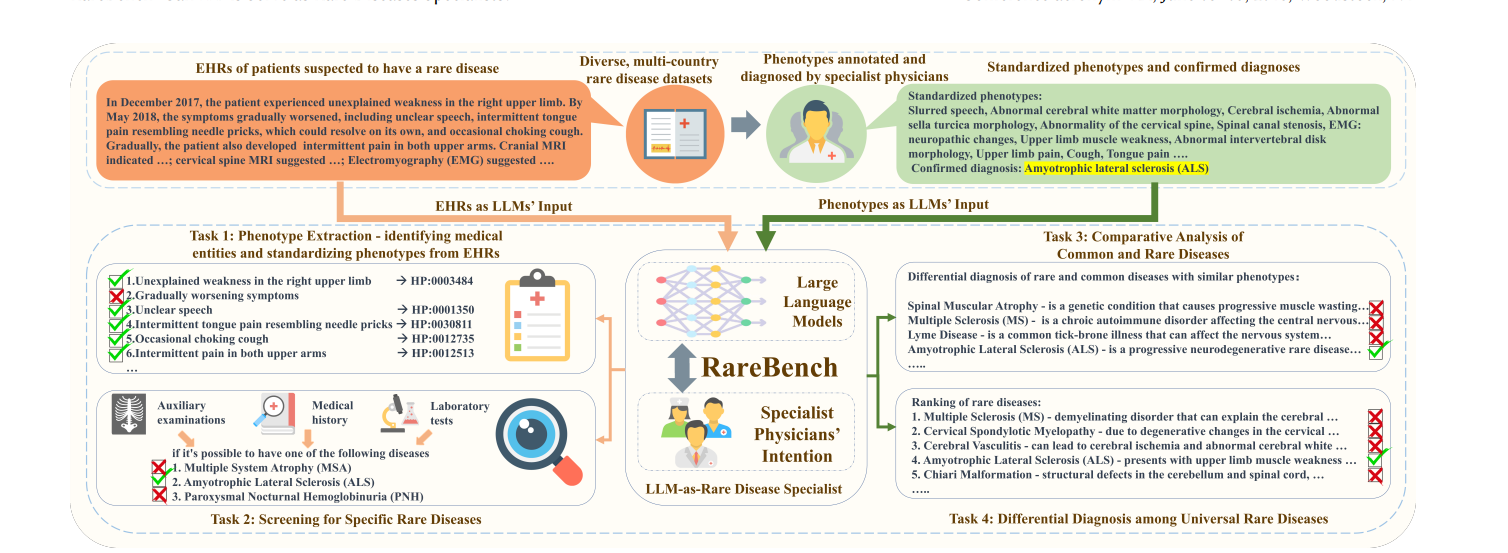
具体任务
任务1:电子健康记录(EHR)中的表型提取
LLMs在从电子健康记录(EHRs)中提取病人表型信息的准确性如何?
对EHRs进行自然语言处理和信息提取,以获取精确的表型数据。
因为EHRs中的数据未经标准化,需要通过NLP技术准确提取病人的表型信息。
- 问题:精确表型提取的能力较弱
- 解决方案:使用两种方法改进表型提取
- 特征1:词汇到表型的匹配(Word-to-phenotype matching)
- 特征2:扩展的语义匹配(Expanded semantic matching)
这种任务关注于通过提高语义理解和精准匹配的方法来克服LLMs在表型提取和标准化方面的挑战,以便更准确地识别和分类疾病的表型。
这种方法均旨在提高表型提取的准确性。
-
第一种方法,通过将输出中的每个词与HPO表型列表中语义最近的词对齐来改进。
-
第二种方法,通过关联输出与HPO表型列表中语义上最近的n个词,然后在重新查询GPT-4之前整合这些匹配作为参考输出范围。
在处理该医疗记录时,需要注意以下几点:
- 表型必须精确地从文本中提取,并使用HPO数据库的标准术语。
- 所提取的表型不应该是原始文本的简单重述,而应该是对症状的精炼描述。
- 必须提取文本中出现的所有表型,包括否定性描述以外的所有表型。
- 对于任何表型,即使在医疗记录中以否定形式出现(例如“没有口干”或“没有关节肿胀和疼痛”),也不应将其包含在提取结果中。
使用表型输入,GPT-4在顶级召回率等指标上略胜一筹。
相比于直接使用医疗记录文本,提取的表型减少了输入令牌的数量,同时去除了不相关的细节,使输入格式对LLMs来说更经济、高效。
假设有一个罕见病患者的EHR包含了症状描述如“间歇性肌肉抽搐”和“行走困难”。
如果直接将这些描述输入LLMs,模型可能需要从大量的文本中提取关键信息,并可能会被不相关的信息干扰。
然而,如果将这些症状转化为标准化的医学术语,如将“间歇性肌肉抽搐”对应到HPO(人类表型本体)中的“肌肉痉挛”(HP:0003394),LLMs就可以更直接地访问与这些标准化术语相关的医学知识,从而提高诊断的准确性。
再通过关联输出与HPO表型列表中语义上最近的n个词,然后在重新查询GPT-4之前整合这些匹配作为参考输出范围。
任务2:筛选特定罕见病
在筛查特定罕见病方面的召回率很低,怎么办?
应用LLMs进行罕见病的预筛查,以评估其对特定疾病的识别能力。
因为需要一种快速筛查工具来识别潜在的罕见病病例,而LLMs可能具备处理大量数据并识别模式的能力。
- 问题:在罕见病筛选中的召回率低
- 解决方案:利用GPT-4进行筛选
- 特征:采用Chain of Thought(CoT)方法
CoT方法通过促使模型进行内部推理来提高筛选的准确性,从而提高了对ALS、PNH、MSA这三种罕见病的召回率。
任务3:常见病与罕见病的比较分析
因为常见病和罕见病的病症重叠,导致普遍误诊为常见病。
使用LLMs对相似表型的疾病进行比较分析,以测试其区分常见病和罕见病的能力。
虽然常见病和罕见病在表型上可能有重叠,但LLMs可以通过大量数据学习来辨识这些细微差别。
- 问题:诊断准确性不足
- 解决方案:使用GPT-4进行比较分析
- 特征:CoT方法与0-shot设置的比较
通过比较0-shot设置和CoT方法的表现,发现CoT方法能够通过促进模型的深层思考和逻辑推理来提高诊断的准确性。
任务2和任务3,通过特定的设置(如零样本和CoT),提升罕见病诊断能力。
任务4:全球罕见病的鉴别诊断
- 问题:鉴别诊断性能不足
- 解决方案:知识集成动态少数示例(Knowledge Integration Dynamic Few-shot)
- 特征1:基于知识图谱的动态少数示例方法
- 特征2:IC值基随机行走算法
知识图谱提供了丰富的背景知识。
IC值基随机行走算法,允许动态选择用于少数示例学习的示例。
LLMs需要更多的上下文信息和知识理解来提高鉴别诊断的准确性,而知识图谱和IC值算法提供了这种上下文。

这张图展示了如何利用知识图谱和基于信息内容(IC)值的随机行走算法来增强LLMs在罕见病鉴别诊断。
图中展示了一个知识图谱的局部示意图,包含了表型节点(P节点)和罕见病节点(RD节点),以及它们之间的边。
使用这个图谱,可以通过IC值加权的随机行走算法来生成罕见病患者的表型嵌入。
这些嵌入随后用于大型语言模型,通过基于余弦相似度的动态少数示例提示,来提高模型的诊断性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









