







StructLM:处理医学数据表格与统一医学术语多样性的桥梁
提出背景
论文:https://arxiv.org/pdf/2402.16671.pdf
代码:https://tiger-ai-lab.github.io/StructLM/
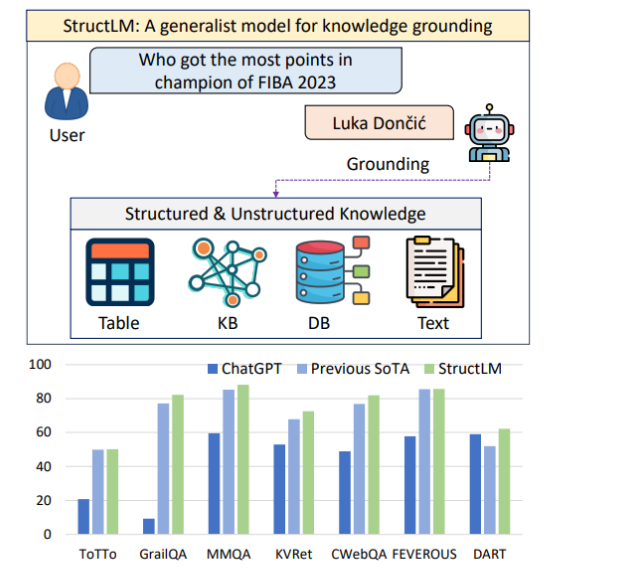
StructLM在各种结构化和非结构化知识任务上的性能。
这个模型可以理解和利用表格、知识图谱、数据库和文本来回应人类查询。
图中显示了StructLM在18个结构化知识定位(SKG)任务上的表现,与ChatGPT和之前的最优模型(SoTA)相比。
在这些任务中,StructLM在7项任务上实现了新的SoTA成就,表现超越了ChatGPT和之前的专业模型。
传统上,用户需要编写程序来与表格、数据库、知识图谱等结构化数据进行交互。
这要求用户掌握SQL、SPARQL等特定领域的语言。
最近,研究人员探索了使用自然语言自动化与结构化数据接口的可能性,以启用问答、摘要、事实验证等潜在用例,所有这些都基于结构化知识源。
这项努力可以降低终端用户访问大量结构化数据的门槛。
尽管大型语言模型(LLMs)在处理纯文本方面已展示出卓越的能力,但它们在解释和利用结构化数据方面的熟练度仍然有限。
我们的调查揭示了LLMs在处理结构化数据方面的显著不足,例如,ChatGPT在与最先进(SoTA)模型的比较中平均落后35%。
为了增强LLMs中的结构化知识定位(SKG)能力,我们开发了一个包含1.1百万示例的综合指令调整数据集。
利用这个数据集,我们训练了一系列基于Code-LLaMA架构的模型,称为StructLM,参数规模从7B到34B不等。
我们的StructLM系列在18个评估数据集中的14个上超过了特定任务的模型,并在7个SKG任务上建立了新的SoTA成就。
此外,StructLM在6个新的SKG任务上展示了出色的泛化能力。
与预期相反,我们观察到模型规模的扩大只提供了边际效益,StructLM-34B相比于StructLM-7B只显示了轻微的改进。
这表明结构化知识定位单纯的叠加规模无意义,需要更多创新的设计才能推向新的水平。
StructLM 框架
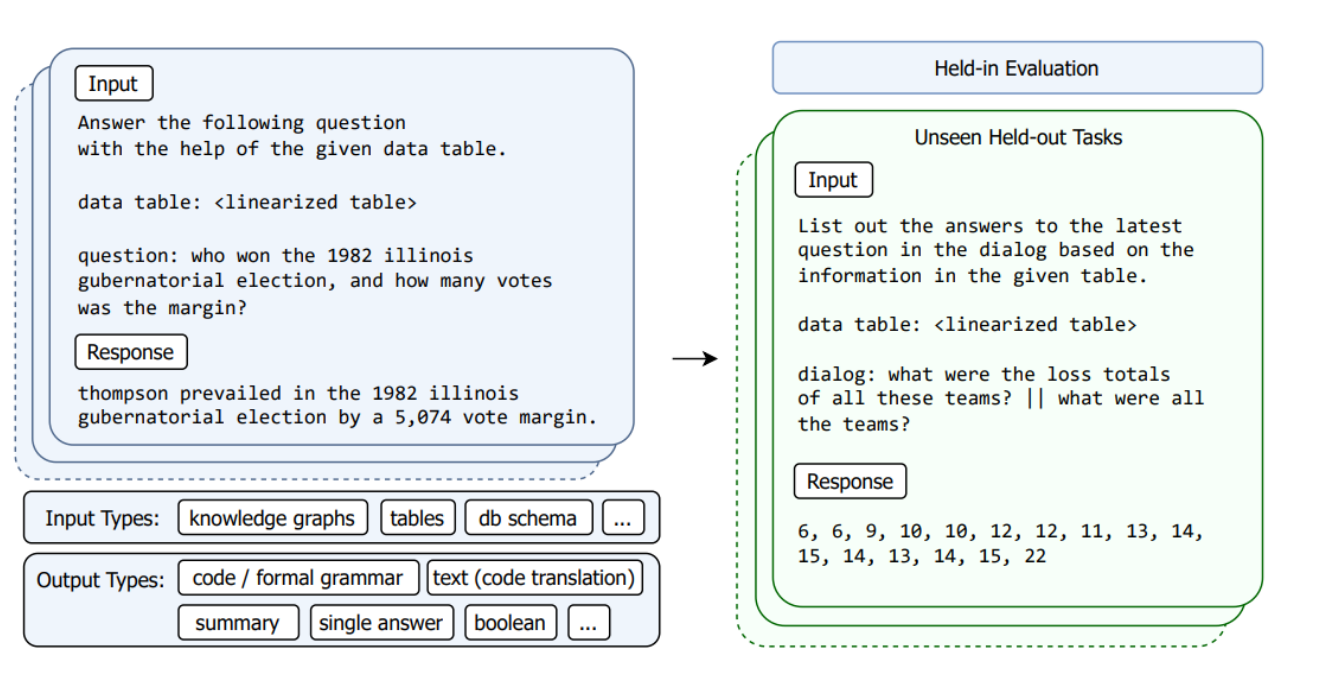
图中展示了两个例子:一个是给定数据表后回答问题的情况,另一个是未见任务的评估,说明了模型如何在没有直接指导的情况下处理新的查询类型。
它不仅在单一任务上表现优秀,而且能够在从未见过的相关任务上展现出强大的推广能力。
这两个例子展示了输入类型可能包括知识图谱、表格、数据库架构等,而输出类型可能是代码、正式语法、文本(代码转换)、摘要、单一答案、布尔值等。
StructLM 组成
- 子解法1:上下文表示学习(训练专属模型):通过特定训练方法学习表格数据的上下文表示,例如PTab和MultiHiertt在学习结构化数据时融合语义信息。
- 子解法2:关系感知机制:RASAT通过与Transformer结合的关系感知自注意力机制,利用不同的关系结构解决SQL查询问题。
- 子解法3:统一序列处理:USKG首次将多个SKG任务统一为序列到序列格式,实现了在相同数据混合中的聚合。
- 子解法4:强化语言模型提示:StructGPT等通过在强大的LLMs上应用提示框架解决SKG任务,提高了任务的鲁棒性和准确性。
- 子解法5:指令调整增强:通过指令和输出对的额外训练,提高了LLMs的可控性和预测性,更接近用户期望。
历史问题及其背景:
- 之所以用上下文表示学习子问题,是因为处理结构化知识时需要能理解和表现数据的上下文背景。
- 之所以用关系感知机制子解法,是因为SQL和其他结构化查询语言需要理解数据之间复杂的关系特征。
- 之所以用统一序列处理子解法,是因为以往的模型在处理多种SKG任务时缺乏统一和高效的方法特征。
- 之所以用强化语言模型提示子解法,是因为现有的LLMs在没有适当提示框架支持时无法准确完成SKG任务特征。
- 之所以用指令调整增强子解法,是因为传统的LLMs在理解用户指令方面存在限制,需要更贴近实际应用需求的训练方法特征。
举个例子:
假设一个用户想从一个数据库中查询1982年伊利诺伊州州长选举的获胜者和票数差距。
- 历史问题:在没有专门针对结构化数据查询训练的模型时,用户需要掌握SQL等查询语言来提取信息。
- 子解法1(上下文表示学习):一个训练有素的模型,如PTab,通过理解表格上下文来识别和提取获胜者和票数差距信息。
- 子解法2(关系感知机制):结合了关系感知自注意力的模型,如RASAT,能够处理和理解选举结果的关系结构,从而回答查询。
- 子解法3(统一序列处理):USKG通过将查询转换为序列到序列的任务,简化了用户的查询过程,不需要用户掌握SQL。
- 子解法4(强化语言模型提示):通过StructGPT这样的提示框架,即使用户的询问非常自然,模型也能理解并提供准确的答案。
- 子解法5(指令调整增强):通过指令调整,模型能够理解“查询1982年伊利诺伊州州长选举获胜者”这样的指令,并给出正确的输出。
怎么训练的专属模型?
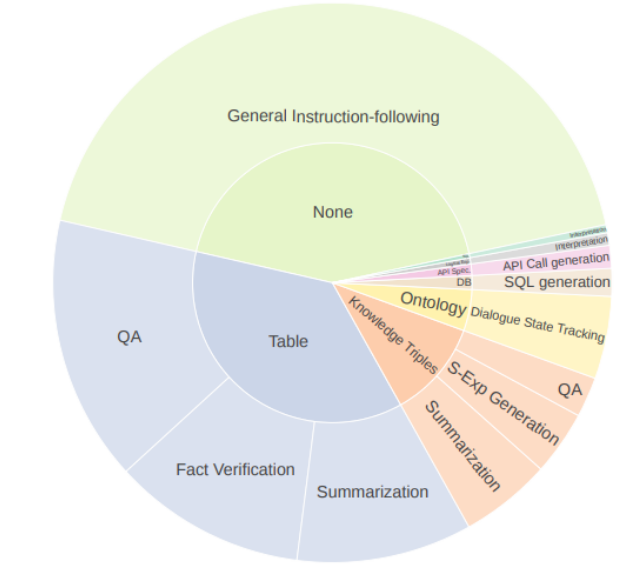
这张图是一个韦恩图,展示了结构化知识类型和任务的分解。
- 在内圈,我们可以看到对数据集中结构化输入的不同类别的粗略分解,包括QA(问答)、表格、知识三元组、本体、SQL/ExO生成(SQL和执行器输出生成)以及对话状态追踪。
- 外圈则展示了代表这些结构化知识类型的任务,例如问答、事实验证、总结以及API调用生成和SQL生成。
此外,这个图还显示了一个较大区域,标记为“General Instruction-following”,表示除了结构化知识任务外,还包括了大量的普通指令跟随数据,这些数据来自SlimOrca。
这表明研究者在构建数据集时不仅考虑了特定的结构化知识类型,还包括了用于训练模型遵循指令能力的通用数据。
方法论,包括数据策展、指令微调方法以及训练和评估。
- 子解法1:数据集选择和分组:选择25个SKG任务,并将它们分为数据到文本生成、基于表格的问答、知识支撑的对话、事实验证、SQL/领域特定语言处理以及数学推理六个组别,以覆盖广泛的结构化数据任务。
- 子解法2:指令微调方法:通过系统提示、指令、输入和输出的组合来构建训练样本,并为每个数据集编写多种指令变体。
- 子解法3:训练和评估:以CodeLlama-Instruct模型家族为基础进行微调,并遵循USKG的结构化数据线性化约定,采用不同的截断方案以优化训练和推理过程。
之所以用这个解法,是因为问题的某个特征:
- 之所以用数据集选择和分组子解法,是因为结构化知识定位任务涉及多种数据类型和处理需求的特征。
- 之所以用指令微调方法子解法,是因为指令微调能提高模型对于各种指令的理解和响应的特征。
- 之所以用训练和评估子解法,是因为基于实际应用需求对模型进行微调和评估能够提高其实际性能的特征。
StructLM 医学应用
StructLM是一个针对结构化知识定位(SKG)的语言模型,能够理解和生成与结构化数据源相关的自然语言响应。
在医学领域,StructLM可以应用于多种任务,例如:
- 从电子健康记录中提取信息:识别病人的诊断记录、治疗过程或药物用量。
- 医学文献检索:基于特定的研究问题,检索并总结相关的医学研究文献。
- 药物相互作用查询:解释特定药物组合的潜在相互作用。
- 临床试验数据分析:从临床试验数据库中回答关于研究结果的问题。
- 诊断支持:通过分析患者数据来辅助医生诊断。
- 治疗方案建议:根据患者病史和当前病情生成治疗建议。
- 患者教育材料自动化生成:根据医学数据库信息创建患者宣教材料。
- 病历摘要自动生成:将病历记录转换为简明的摘要。
- 医疗费用估算:结合医疗服务数据库来估算特定治疗的费用。
- 临床指南自动更新:根据最新研究成果更新临床实践指南。
- 药物剂量计算:基于药物属性和患者特征计算推荐剂量。
- 医疗设备数据解读:解读和总结医疗设备生成的数据。
- 生物标志物分析:从生物信息学数据库中提取特定生物标志物的信息。
- 遗传变异解释:提供对特定遗传变异可能影响的解释。
- 流行病学数据解读:分析公共健康数据库中的疾病爆发和传播模式。
- 营养计划制定:根据食品数据库制定个性化的营养计划。
- 预防保健建议:基于最新的医学研究生成预防性保健的建议。
- 医学影像数据标注:辅助医学影像的解释和标注,如MRI或CT扫描。
- 实验室结果解释:自动解释血液学和生化实验室测试结果。
- 疫苗接种记录管理:管理和查询疫苗接种历史和计划。
StructLM在处理这些任务时,能够利用其对结构化数据的理解能力,从表格、数据库和其他结构化格式中提取和处理信息,然后生成有用的、针对性的自然语言输出。
这在医学领域尤其重要,因为数据往往是高度结构化且复杂的。
我印象最深的是,从病历中提取数据,同一医学概念有多种术语表达,没有统一的医学术语标准,只能人工提取。
StructLM是一个大型语言模型,专门训练以理解和处理结构化数据,如表格和数据库。
在医学领域,这意味着它可以用来从医学数据表格中提取信息,并且能够识别和理解多样化的医学术语。
例如,它能够理解不同的医学术语可能指的是同一种疾病或症状,并帮助统一这些术语以便于更好的数据整合和知识抽取。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









