






Albérick Euraste Djiré euraste.djire@uni.lu
Earl T. Barr
e.barr@ucl.ac.uk
Abdoul Kader Kaboré
abdoulkader.kabore@uni.lu
Jacques Klein
jacques klein@uni.lu
Tegawendé F. Bissyandé
tegawende.bissyande@uni.lu
摘要
尽管大规模语言模型(LLMs)通过在海量数据集上的训练取得了显著的性能,但它们有时会表现出令人担忧的行为,例如逐字复制训练数据而不是真正的泛化。这种记忆现象引发了对数据隐私、知识产权以及模型评估可靠性的重大关注。本文介绍了PEARL,一种用于检测LLMs记忆的新方法。PEARL评估LLM对输入扰动的敏感性,从而无需访问模型内部即可检测记忆现象。我们研究了输入扰动如何影响输出的一致性,使我们能够区分真正的泛化和记忆。我们的发现基于对Pythia开源模型的广泛实验,提供了一个强大的框架来识别模型何时仅仅重复已学习的信息。应用于GPT 40模型时,PEARL框架不仅识别出圣经经典文本或HumanEval常见代码的记忆案例,还证明它可以提供支持证据,表明某些数据(如纽约时报新闻文章)很可能属于某个模型的训练数据。
1. 引言
LLM的能力在AI社区内一直是一个争论和研究的话题。特别是,虽然各种模型的推理表现表明它们擅长泛化,但大量实证证据显示LLMs偶尔会记忆其训练数据中的特定示例,导致输出逐字复制内容(Carlini等,2021;Hartmann等,2023)。
在LLM的背景下,记忆指的是模型在训练过程中接触到的特定文本部分可以被再现或回忆的现象。让我们将语言模型视为条件概率分布
p
θ
(
y
∣
x
)
p_{\theta}(y \mid x)
pθ(y∣x),其中
θ
\theta
θ 表示模型参数,
x
x
x 是输入上下文,
y
y
y 是输出标记。
对于训练数据集
D
=
(
x
i
,
y
i
)
i
=
1
N
D=\left(x_{i}, y_{i}\right)_{i=1}^{N}
D=(xi,yi)i=1N,可以通过成员优势的概念定义记忆。这衡量了模型在训练数据中出现的输入与未出现的输入上的行为差异。正式地,模型
M
M
M 的成员优势
m
a
m a
ma 可以定义为:
m a ( M , x , y ) = ∣ p θ ( y ∣ x ) − p θ ( y ∣ x ′ ( x ) ) ∣ m a(M, x, y)=\left|p_{\theta}(y \mid x)-p_{\theta}\left(y \mid x^{\prime}(x)\right)\right| ma(M,x,y)=∣pθ(y∣x)−pθ(y∣x′(x))∣
其中
(
x
,
y
)
(x, y)
(x,y) 是训练数据中的序列,
x
′
(
x
)
x^{\prime}(x)
x′(x) 是返回类似但未见过的序列的函数,而
p
θ
(
y
∣
x
)
p_{\theta}(y \mid x)
pθ(y∣x) 是模型生成给定
x
x
x 的
y
y
y 的概率。
较高的成员优势表明模型已经记忆了特定的训练示例,而不是学习可泛化的模式,因为它对已见和未见但类似的示例分配了显著不同的概率。
不幸的是,只有当有关训练数据的信息可用时,这种数学建模的记忆才是可行的。实际上,由于一些战略和实际考虑,大型AI公司(Zewe,2024;eur)缺乏对其训练数据的透明度:保密代表了行业中的关键竞争优势,并与重大法律风险交织在一起。此外,对训练数据的详细了解可能会导致安全漏洞。
然而,在LLM(尤其是商业LLM)中检测记忆至关重要,原因有多个相互关联的原因。
如果没有稳健的记忆检测,组织面临隐私泄露、法律问题和模型性能下降的风险,同时可能侵蚀公众对AI系统的信任。事实上,从隐私和安全的角度来看,记忆检测有助于识别潜在的敏感个人数据泄漏(Yan等,2024;Carlini等,2021;Lukas等,2023;Yao等,2024)。从评估模型质量的角度来看,检测记忆有助于区分真正学习和简单重复训练数据,这对于开发更可靠和更具泛化能力的AI系统至关重要。法律合规也受益于记忆检测,它有助于防止版权侵权并管理知识产权风险(nytimes,2023)。也许最重要的是,记忆识别支持AI系统的透明性和信任,通过促进关于模型能力和局限性的诚实沟通(Zhou等,2023)。
早期的检测方法通过分析模型参数来识别产生高置信度生成的实例(Zhou等,2023)。然而,随着专有LLM对模型参数的访问越来越受到限制,研究人员现在正在调查替代的黑盒方法。这些方法包括分析重复提示下的输出分布模式(Zhou等,2024)和使用精心设计的检测提示评估模型响应(Golchin & Surdeanu,2024)。虽然这些方法看起来很有希望,但仍有一个开放的问题:它们是否成功检测到实际的记忆。确实,记忆检测的一个关键挑战是区分两种情况:(1) 真正的记忆,模型的高置信度答案源于复制训练数据;(2) 成功的插值,模型展示了真正的泛化能力而不依赖于记忆的内容。
本文中,我们在研究中解决了如何识别黑盒LLM中真正的记忆这一研究问题,其训练数据进一步未知。为此,我们提出了以下扰动敏感性假设(PSH):
对于给定的模型、任务和数据点,如果模型记住了该数据点,则其任务性能将对小输入扰动表现出高敏感性。
本文其余部分按照以下贡献进行组织:
- 我们在第2节介绍PSH。在介绍记忆和插值的相关概念以及先前工作通过估计LLM的输出分布来识别记忆实例后,我们在第2节提出我们的假设,并阐述其与记忆的相关性。
-
- 我们在第3节提出了PEARL(PErturbation Analysis for Revealing Language model Memorization),这是一个基于PSH构建的框架,用于预测LLM中的记忆。
-
- 我们在第4节通过在开源模型Pythia及其相关训练数据集Pile上评估其有效性,经验性地展示PSH的力量。
-
- 我们在第4节使用圣经、纽约时报和HumanEval数据集开发GPT-4o中的记忆案例研究。
2. PSH:扰动敏感性假设
LLM作为概率模型运行,旨在从其训练数据中学习和泛化模式。虽然泛化是主要目标,但模型的可靠性本质上与预训练、微调和强化学习期间使用的数据的质量和特性相关。这就造成了固有的紧张关系:模型必须在从所学模式中泛化和保持对训练数据的保真度之间取得平衡,以确保可靠的输出。
文献中对LLM的记忆有多重形式化的定义。一个突出的框架专注于逐字复制,即模型输出其训练数据中确切的序列(Carlini等,2021;Yao等,2024)。这种现象可以在各种任务中表现出来,包括序列完成、问答和推理(Hartmann等,2023)。虽然记忆通常与过度拟合相关联,特别是在模型反复接触相同数据的微调期间(Schwarzschild等,2024;Duan等,2024),最近的工作(Dankers & Titov,2024)表明记忆可能是泛化的必要前奏。他们的研究结果表明,与更常见的数据模式相比,LLM对记忆异常值表现出更高的敏感性。相比之下,插值指的是模型识别和利用训练数据中潜在模式以生成新输出的能力。更正式地说,给定来自输入空间 X \mathcal{X} X 的输入 x x x,插值模型通过计算其学习分布的期望值来生成输出,从而反映所学模式,同时在其预测中保持一定程度的不确定性或置信度。这可以表示为:
f ( x ) = E y ∼ p ( y ∣ x ) [ y ] f(x)=\mathbb{E}_{y \sim p(y \mid x)}[y] f(x)=Ey∼p(y∣x)[y]
其中 f ( x ) f(x) f(x) 是模型的输出,期望值 E [ y ] \mathbb{E}[y] E[y] 是通过对从学习条件概率分布 p ( y ∣ x ) p(y \mid x) p(y∣x) 中采样的输出 y y y 进行取值得到的。
图1展示了我们在使用amazon-nova-lite-v1.0模型时观察到的记忆和插值的实际例子。我们考虑两个文本样本,一个

图1. 在使用amazon-nova-lite-v1.0模型完成任务中的记忆和插值示意图(Intelligence,2024)
来自《哈利·波特》系列,另一个来自维基百科。当样本数据作为带有提示的输入提交给文本完成任务时,模型生成正确的输出。问题是:我们如何知道模型是在很好地插值还是从其训练数据中记住了结果?
基于PSH,我们向输入添加了一些扰动,并再次提示模型完成任务。模型显然未能完成《哈利·波特》文本的任务。相反,对于关于阿尔伯特·爱因斯坦的维基百科文本,模型可以完成任务。
通过这些例子推广,我们推测在记忆的情况下,LLM的输出对训练数据敏感。因此,对记住的输入数据施加一定程度的扰动可能导致模型性能急剧下降。请参阅图2:我们考虑GPT-4o模型在使用莎士比亚诗歌(经GPT-4.0确认为其训练数据的一部分)和GPT-4o发布后提供的新闻文章(附录6)的数据文本样本进行文本完成任务。作为扰动,我们考虑输入的随机位翻转(参见第3节)。通过测量模型在此任务上的性能(以正常压缩距离衡量),我们注意到对于第一个样本文本,当应用超过给定扰动率(2%)时,模型性能突然下降。相比之下,第二个样本文本(我们知道不可能被记住)的性能下降更为规律。这个例子证明了PSH假设用于识别记忆。
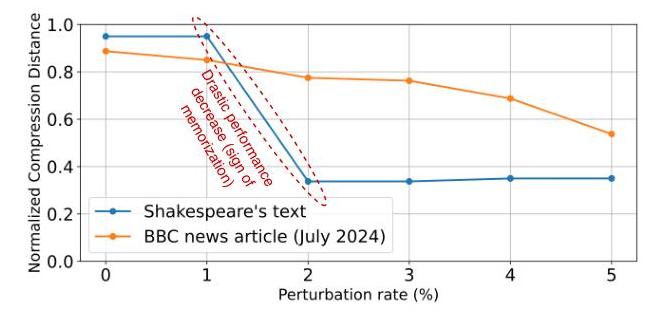
图2. GPT_4o对受扰动的已记忆莎士比亚诗歌和近期文本(非GPT_4o训练集的一部分)的文本完成性能下降对比。
3. PEARL:用于揭示语言模型记忆的扰动分析
我们将PEARL设计为一个新颖的框架,建立在我们的PSH假设之上,该假设认为记忆的数据点在任务性能方面对小输入扰动表现出高敏感性。通过系统地通过控制输入变化实现这一假设,PEARL提供了一种稳健的方法来检测LLMS中的记忆。
如图3所示,该框架开发了一个全面的分析管道,量化与性能下降相关的扰动敏感性模式(基于应用的阈值),从而可靠地区分记忆内容和真正学习的模式。这种方法为研究人员和从业者提供了一种原则性的方式来评估语言模型中的记忆,而无需详细了解模型的内部参数或其训练数据。
给定输入
X
X
X,参考输出
(
Y
)
(Y)
(Y) 可知:在文本完成任务中,输入是一个子序列

图3. 基于PSH假设的PEARL框架概述,用于识别LLM中的记忆
样本文本,因此是参考输出。对于其他任务,如果输出不在样本文本中直接提供,则通过将模型应用于未经任何扰动的输入获得参考输出。然后对输入进行扰动,再将其提交给LLM。PEARL随后计算LLM在参考输出和与扰动输入相关的输出之间实现的性能差异。此过程使用不同强度的扰动重复多次。然后PEARL量化模型对这些扰动的敏感性,以决定是否认为原始输入数据已被记住。我们在本节剩余部分详细介绍PEARL方法的各个步骤。
3.1. 输入扰动生成
PEARL的第一步涉及生成测试输入的受控扰动。我们考虑一个扰动函数
σ
(
k
)
\sigma(k)
σ(k),它系统地修改具有给定强度
k
k
k 的输入数据。在本工作中,我们建议为所有文本输入和所有任务集中于一个单一的扰动函数:图4详细说明了比特翻转扰动生成的过程。该函数因此由在输入文本的二进制版本中翻转
k
k
k 位,然后将其解码回文本以生成扰动后的输入组成。
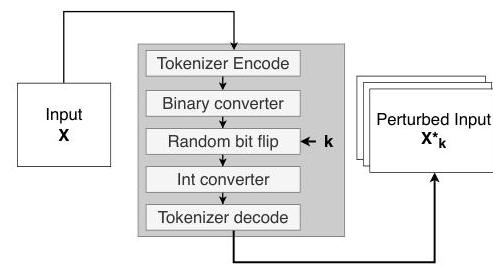
图4. 文本输入中的比特翻转扰动注入,其中 k ∈ N k \in \mathbb{N} k∈N
3.2. 提示LLM执行特定任务
给定任务 T T T、输入 X X X 和生成的扰动输入集 X ∗ = { x 0 ∗ , x 1 ∗ , … x n ∗ } X^{*}=\left\{x_{0}^{*}, x_{1}^{*}, \ldots x_{n}^{*}\right\} X∗={x0∗,x1∗,…xn∗},我们提示LLM并收集输出集 Y ∗ = { Y 0 ∗ , Y 1 ∗ , … Y n ∗ } Y^{*}=\left\{Y_{0}^{*}, Y_{1}^{*}, \ldots Y_{n}^{*}\right\} Y∗={Y0∗,Y1∗,…Yn∗},其中 Y k ∗ = { y ( k , 1 ) ∗ , y ( k , 2 ) ∗ , … y ( k , i ) ∗ } Y_{k}^{*}=\left\{y_{(k, 1)}^{*}, y_{(k, 2)}^{*}, \ldots y_{(k, i)}^{*}\right\} Yk∗={y(k,1)∗,y(k,2)∗,…y(k,i)∗} 是与扰动输入 x k ∗ x_{k}^{*} xk∗ 相关的输出集。确实,对于每个输入,我们提示LLM i i i 次以获得 i i i 个样本输出。这是为了帮助建立结果的统计显著性,因为单次运行可能是异常值,不能代表模型的真实能力。
3.3. 量化LLM对输入扰动的敏感性
对于给定的输出集 Y k ∗ Y_{k}^{*} Yk∗(由提示扰动输入 x k ∗ x_{k}^{*} xk∗ 的LLM生成)和参考输出 Y Y Y,我们按以下方式计算性能变化的度量:
m ( Y k ∗ ) = 1 i ∑ j = 1 i distance ( y ( k , j ) ∗ , Y ) m\left(Y_{k}^{*}\right)=\frac{1}{i} \sum_{j=1}^{i} \operatorname{distance}\left(y_{(k, j)}^{*}, Y\right) m(Yk∗)=i1j=1∑idistance(y(k,j)∗,Y)
其中 distance 实现了一个任务相关的编辑距离函数。
为了量化模型对输入 X X X 的扰动敏感性,我们计算连续扰动强度间的最大性能下降:
sensitivity ( X ) = max j ∈ 1 , . . , k − 1 ( m ( Y j ∗ ) − m ( Y j + 1 ∗ ) ) \text { sensitivity }(X)=\max _{j \in 1, . ., k-1}\left(m\left(Y_{j}^{*}\right)-m\left(Y_{j+1}^{*}\right)\right) sensitivity (X)=j∈1,..,k−1max(m(Yj∗)−m(Yj+1∗))
3.4. 决策记忆
根据以下条件,输入 X X X 被识别为LLM训练数据的已记忆实例:
memo ( X ) = { sensitivity ( X ) > α 记住 otherwise 未记住 \operatorname{memo}(X)= \begin{cases}\text { sensitivity }(X)>\alpha & \text { 记住 } \\ \text { otherwise } & \text { 未记住 }\end{cases} memo(X)={ sensitivity (X)>α otherwise 记住 未记住
其中 α \alpha α 是一个定义任务性能下降显著性的超参数阈值。
3.5. 实验设置
我们通过两组实验验证PEARL以验证PSH。第一组实验考虑具有透明训练数据细节的开源模型。我们甚至在我们的真正阳性测试集上进行微调,经过多个周期,以确保将被测试记忆的数据确实已经被模型考虑过。第二组实验考虑闭源模型,以在野外开发案例研究,展示PEARL在成员推断中的潜在应用。
模型选择。我们考虑Pythia(Biderman等人,2023),一套旨在促进科学研究的开源模型。它包括多样化的模型尺寸范围,从小型配置(如70M参数)到大型配置(数十亿参数),包括6.9B和13B。此外,对于每个模型大小版本,提供了两个变体:一个是在完整预训练数据集The Pile上训练的,另一个是在去重版本的The Pile上训练的。
在这项研究中,我们专注于在去重数据集上训练的Pythia模型变体。确实,从训练数据集中消除重复内容最小化了因重复暴露于相同数据而导致的记忆可能性。因此,这种设置使我们能够在受控条件下系统地评估记忆,确保任何识别出的记忆实例都可以归因于数据的单一出现而非重复模式。
为了在现实场景中验证我们的方法,我们将分析扩展到GPT-4o,检查在无法访问模型内部参数的黑箱情境下记忆检测的情况。选择GPT-4o特别相关,鉴于最近在AI伦理和知识产权方面的进展。值得注意的是,鉴于2024年1月OpenAI与《纽约时报》之间的法律纠纷,涉及涉嫌版权侵权和未经授权使用新闻内容进行训练(nytimes,2023)。因此,我们提议调查GPT_4o中《纽约时报》文章的潜在记忆。
数据集。Pythia模型在The Pile数据集(Gao等人,2020)上进行了预训练,这是一个多样化的语料库,旨在涵盖广泛的文本类型,从文学和科学文章到网络内容和编程代码。从实验角度来看,我们假设该数据集中的任何数据样本都可能被模型记住。我们选择了一个包含1000个文本样本的随机子集,每个样本至少包含300个标记,以构建我们的阳性集(通过多轮微调“强制”记忆以驱动过拟合)。相反,我们可以断言,Pile中不存在的数据不可能被记住,模型在这些数据上的高性能很可能是由于其泛化能力。我们考虑负样本(非记忆数据)的RefinedWeb数据集,其中包括一组与Pile不相交的文本,为评估模型在未见数据上的泛化能力提供了可靠的基准(Penedo等人,2023)。选择标准与Pythia相同:1000个随机样本。
对于野外实验,我们构建了四个不同来源收集的100个数据样本的实验集:
(1) HumanEval 数据集,由 OpenAI 发布,包含
针对164个Python编程问题的样本。每个问题包括函数签名、文档(docstring)、实现主体和多个单元测试。该数据集作为评估语言模型代码生成能力的标准基准(Chen等人,2021)。由于它是公开可用的,因此怀疑已被GPT-4o记住(Matton等人,2024)或者至少是其训练数据的一部分(Dong等人,2024)。
(2) Less Basic Python Programming (LBPP) 是一个编程挑战数据集,于2024年7月11日发布,晚于GPT-4o的发布。类似于HumanEval,它专注于Python编程任务,但更强调复杂的编程概念和算法挑战,并明确提出(Matton等人,2024)以解决现有代码生成测试集(如HumanEval)对模型(如GPT-4o)的污染问题。
(3) 圣经是一本古老、流行且独特的宗教文本集合。由于其开放性质,圣经一直是大多数模型训练数据的关键来源之一,与维基百科并列。由于其与其他更当代文本样本相比独特的写作风格,我们假设圣经经文更有可能被记住。
(4) 纽约时报 (NYT) 是一家每天发表涵盖政治、商业、技术和文化等各种主题文章的报纸。OpenAI 使用 NYT 文章是诉讼的主题(nytimes,2023),涉及版权侵权。OpenAI 的论据主要依据“合理使用”规则
1
{ }^{1}
1。在本文中,我们将认为 NYT 数据是 GPT-4o 训练集的一部分。因此,如果能提供某些样本已被记住的证据,那么合理使用的辩护可以被质疑。
任务与评估指标。我们考虑自然语言处理和软件工程中的四个常见任务:文本补全和文本摘要以及代码补全和代码摘要。我们区分这些任务,因为代码摘要的输入是用编程语言编写的代码,而输出是用自然语言编写的文本。
我们根据任务的不同使用不同的模型性能评估指标。对于代码/文本补全,我们依赖于标准化压缩距离(NCD)。对于代码/文本摘要,我们使用ROUGE-L(Lin,2004)。
超参数。表1总结了我们在实验中使用的不同超参数值。
1 { }^{1} 1 它是美国法律中的一项原则,允许使用受版权保护的材料用于教育、研究或评论目的。为了通过合理使用测试,相关作品必须将受版权保护的作品转化为新的作品,并且新作品不得在同一个市场中与原作竞争,以及其他因素。
| 参数 | 描述 | 值 |
|---|---|---|
| k k k | 允许控制扰动强度的超参数。在比特翻转的情况下,它是指输入中修改的令牌百分比(参见第4.2节) | k ∈ { 0 , 1 , 2 , 3 , 4 , 5 } k \in\{0,1,2,3,4,5\} k∈{0,1,2,3,4,5} |
| i i i | 每个扰动输入生成的输出数量(参见第4.2节) | i = 10 i=10 i=10 |
| α \alpha α | 允许确定实例是否被记住的阈值(参见第4节) | 取决于模型、任务和数据集 |
表1. 超参数值
4. 实验结果
4.1. 研究问题
- [RQ1.] 输入扰动敏感性假设能否为检测和量化LLM中的记忆提供可靠的指标?大多数以前的文献都将记忆评估为成员推断问题。在没有真实数据的情况下,我们提出了一种在受控环境(开放模型和数据)中的两步验证方法:首先,我们评估PEARL在不属于训练数据集的数据集中检测记忆的判别能力,然后评估PEARL识别的记忆实例数量是否随着实现过拟合(因此记忆)的微调努力一致变化。
-
- [RQ2.] 当应用于GPT-4o时,PEARL在哪些特定数据集中发现了记忆实例?我们开发了封闭源模型的案例研究,调查各种数据集的记忆决策——包括已知是训练数据集一部分的数据集、先前研究怀疑已被记住的数据集以及已知不是训练数据集一部分的数据集。
-
- [RQ3.] 在PEARL中,记忆预测在多大程度上取决于任务?在这个研究问题中,我们调查PEARL在分析两个考虑任务的性能下降时的判别能力是否稳定。
4.2. PSH验证
Pythia是一种生成模型,未经训练以遵循指令,因此我们仅将其410m版本应用于文本补全任务。图5说明了如何拆分每个样本文本以得出提示中使用的输入以及参考输出。在生成扰动输入并应用重复提示后,我们收集输出并计算性能指标(即NCD)和模型敏感性指标,如方程2和3所定义。
我们考虑负集(即,RefineWeb,不是训练集的一部分)。图6表示不同的
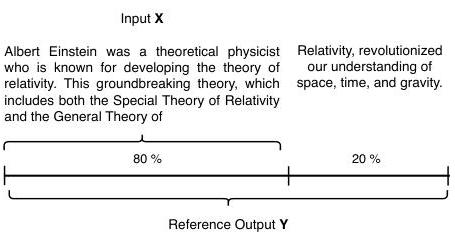
图5. 文本补全任务的示例输入
X
X
X 和参考输出
Y
Y
Y。
当敏感性阈值
α
\alpha
α 变化时,PEARL在该数据集上的假阳性率。鉴于阈值
α
=
0.2
\alpha=0.2
α=0.2 导致较低的假阳性率(0.04),我们将其设为该任务和此模型实验的阈值。
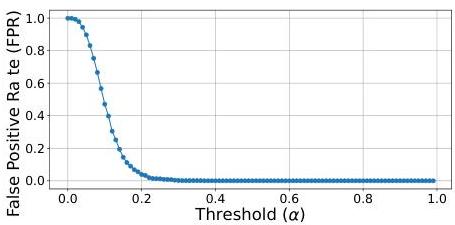
图6. 当尝试识别不属于Pythia模型训练集的数据集中记忆实例时,PEARL随敏感性阈值 α \alpha α 变化的FPR演变
应用PEARL并设置敏感性阈值 α = 0.2 \alpha=0.2 α=0.2,我们比较了PEARL在RefineWeb数据集(不属于训练数据集)和Pile数据集(训练数据集)中识别出的记忆实例比例。在图7中,我们注意到PEARL在第10轮迭代中识别出的Pile样本(>20%)作为记忆的比例远高于RefineWeb样本(≈2%)。对于更高的敏感性阈值(例如图8中的 α = 0.4 \alpha=0.4 α=0.4),我们可以减少RefineWeb的假阳性数,尽管对Pile的识别截止更加严格。
结果进一步表明,随着微调过程的进行,检测到的记忆实例数量在Pile(训练数据)中增加,而在RefineWeb(不属于训练数据)中检测到的实例数量保持稳定且较低。
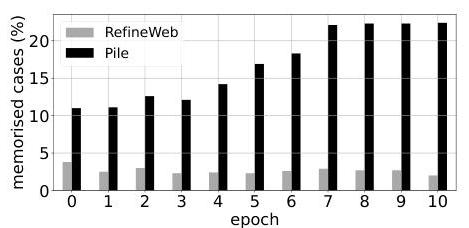
图7. Pythia-410m识别的RefineWeb和Pile数据集中记忆的比例 - α = 0.2 \alpha=0.2 α=0.2
回答RQ1: PSH被证明是一个可靠的框架,用于检测LLM中的记忆,正如Pythia模型中训练数据(Pile)和非训练数据(RefineWeb)之间明显的扰动敏感性区别所证明的那样。可调的检测阈值使误报率得到了精细控制。在微调过程中,训练数据中的检测率增加,而非训练数据中的低率保持稳定,进一步验证了PSH作为一个强大的记忆指示器。这些发现建立了PSH作为LLM记忆检测的原则基础,而PEARL则提供了实用的实施。
最后,我们将我们的检测结果与通过白盒方法(对抗压缩比(Schwarzschild et al., 2024))在FamousQuotes数据集的100个样本上获得的检测结果进行比较。结果显示我们的检测显著重叠:PEARL的优势在于它不需要了解模型内部结构,也不需要了解训练数据。详细结果见附录6。
4.3. 模型规模的影响
谷歌研究院之前的(Carlini et al., 2023)研究表明,较大的模型具有更强的记忆能力。我们在不同规模的Pythia变体上重复了RQ1的实验,并确认了这一发现:在表2中,识别出的记忆实例数量随着模型规模的增加而增加,即使对于高敏感性阈值也是如此。
| 模型 | 识别出的记忆实例数 α = 0.16 \alpha=0.16 α=0.16 | 识别出的记忆实例数 α = 0.2 \alpha=0.2 α=0.2 | 识别出的记忆实例数 α = 0.25 \alpha=0.25 α=0.25 |
|---|---|---|---|
| Pythia 410m | 265 | 110 | 32 |
| Pythia 1-4B | 349 | 171 | 57 |
| Pythia 6.9B | 449 \mathbf{4 4 9} 449 | 259 \mathbf{2 5 9} 259 | 110 \mathbf{1 1 0} 110 |
表2. PEARL在不同规模的Pythia模型中识别的记忆实例数量
4.4. GPT-4o记忆
我们考虑以下来源的样本集,这些样本集具有不同程度的记忆可能性。
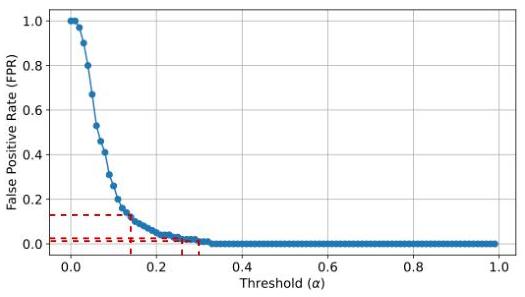
我们根据数据集应用代码或文本补全任务。鉴于LBPP由Matton等人(Matton et al., 2024)认为不太可能是GPT-4o训练集的一部分,我们首先在它上面应用PEARL以选择敏感性阈值。
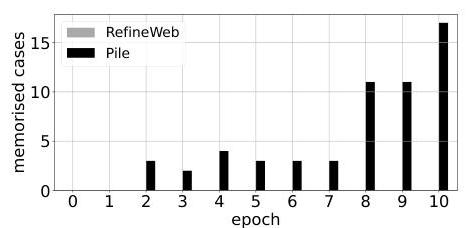
图8. Pythia-410m识别的RefineWeb和Pile数据集中记忆的实例数 -
α
=
0.4
\alpha=0.4
α=0.4
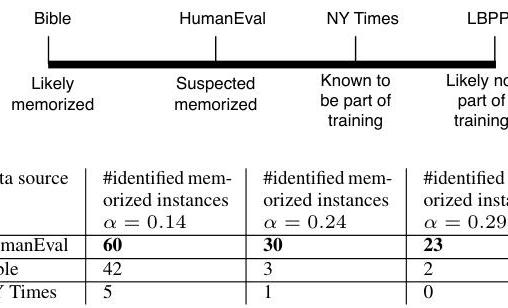
表3. PEARL在GPT-4o模型中识别的记忆实例数量。附录6提供了最小化假阳性的示例案例(参见附录6中关于FPR与敏感性阈值 α \alpha α 变化关系的图表)。
表3报告了PEARL在圣经、HumanEval和纽约时报数据集中每个100个样本子集内识别的记忆实例数量。
回答RQ2: PEARL对GPT-4o的分析揭示了数据集中记忆的非均匀模式,在HumanEval中检测到显著的记忆,在圣经中检测到适度水平的记忆,在纽约时报内容中检测到较少的实例。结果表明,记忆更可能发生在独特或风格独特的内容中,而不是在整个训练数据中均匀发生。
我们在附录6中提供了圣经和纽约时报数据集中计算的敏感性值最低和最高的示例案例,这表明记忆样本是数据集中的异常值(由于风格(例如圣经)和/或内容的独特性(例如纽约时报))。
4.5. PSH的任务依赖性
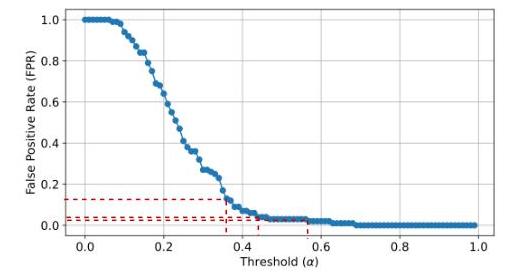
我们调查基于PSH的记忆识别在多大程度上受任务选择的影响。为此,我们在GPT-4o上再次运行所有实验,使用相同的数据库(圣经、HumanEval、纽约时报)进行代码/文本摘要任务。我们回想一下,这项实验无法在Pythia模型上进行,因为它不支持摘要任务。我们再次使用LBPP数据集校准 α \alpha α 的值,以尽量减少PEARL的假阳性率(参见附录6)。
实验结果表明,在之前通过完成任务识别为记忆的所有样本中,只有6个在使用摘要任务时仍然被识别为记忆。图9显示了根据两个任务计算的每个样本的敏感性值分布:通过完成任务,我们可以识别GPT-4o在许多HumanEval代码样本和一些圣经经文中的记忆案例。HumanEval和纽约时报的敏感性值中位数也存在统计学上的显著差异。相比之下,使用摘要任务时,只有少数HumanEval样本被识别为记忆。HumanEval和纽约时报之间的差异进一步不显著。
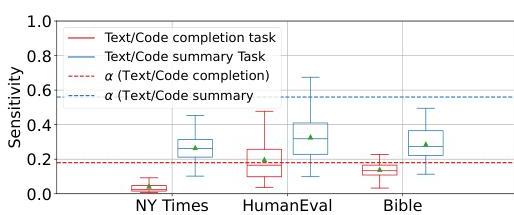
图9. 不同数据源对GPT-4o输入扰动的敏感性测量分布
这种对比可以解释为,在大多数情况下,输入提供的上下文足以让GPT-4o执行摘要任务。因此,输入中的扰动在许多情况下不会导致性能的急剧下降。
回答RQ3: PSH在记忆检测中的有效性随着任务类型显著变化。虽然PEARL在完成任务中揭示了清晰的记忆模式,但在摘要任务中这些模式几乎消失,这表明当模型需要重现精确内容而非基于理解生成新内容时,扰动敏感性更能暴露记忆。
5. 讨论
5.1. 影响
通过PEARL验证PSH为AI社区提供了一个原则性的框架,用于检测LLM中的记忆,以理解和量化模型如何存储和使用训练数据。对于实践者,PEARL提供了一个实用工具来评估记忆风险;而对于研究人员,我们的发现为调查记忆、任务类型和模型性能之间的关系开辟了新的途径。
对于像莎士比亚或圣经经文这样的独特内容,模型缺乏学习一般模式的相似示例,记忆似乎不可避免。通过提供一种可靠的方法来检测此类情况,我们的研究为关于AI训练中数据所有权和同意的持续辩论提供了具体的证据。
5.2. 局限性
PEARL的敏感性阈值 ( α ) (\alpha) (α)校准需要访问已知不在模型训练集中的数据。因此,对于训练数据信息不可用的闭源模型来说,这种校准具有挑战性。
PEARL的有效性在不同类型的任务中有所不同,正如完成任务和摘要任务之间对比结果所示。这种任务依赖性表明,扰动敏感性可能并非在所有模型能力中同样揭示记忆。
5.3. 有效性的威胁
关于外部有效性,我们从GPT-4和Pythia模型得出的结论可能无法推广到其他架构,而且我们选择的数据集可能不代表所有内容类型。对于内部有效性,我们的校准假设LBPP数据确实不在训练集中,而我们的扰动技术可能会引入意外偏差。对于构念有效性,通过依赖距离度量来测量原始输入和扰动输入之间的输出差异,我们可能无法捕捉模型响应的所有语义方面。此外,我们将内容简单地分类为记忆或非记忆,这可能过于简化了LLM中的记忆行为谱系。这种二元分类方法虽然在检测目的上是实用的,但可能无法完全代表模型结合和利用训练数据的细微方式。然而,这些局限性部分被PEARL可配置的敏感性阈值所缓解,这允许实践者根据具体需求调整检测粒度。此外,我们在不同数据集和模型中展示的一致模式表明,尽管存在这些简化,该方法仍成功捕捉到了有意义的记忆信号。
6. 相关工作
关于LLM中的记忆的研究沿着几个方向发展。早期研究集中在通过成员推断攻击提取敏感信息(Duan等,2024)。虽然开创性,但它们需要访问模型内部,如损失函数和架构细节,限制了其在黑盒场景中的适用性。
另一种视角出现在Schwarzschild等人的研究中(Schwarzschild等,2024),他们基于对抗压缩比(ACR)定义了记忆,其中如果内容可以通过显著较短的提示再现,则被认为被记住。这种方法利用GCG(Zou等,2023)找到生成目标输出的最小输入,提供了一种新型的检测记忆指标,当模型生成参数可访问时。
最近的研究加深了我们对记忆机制的理解。Speicher等人(Speicher等,2024)描述了记忆的学习阶段,而Dankers等人(Dankers & Titov,2024)证明了记忆逐渐发生在模型层中,早期层起着更重要的作用。他们的研究还提供了记忆任务依赖性的证据,与我们的发现一致。
结论
本文介绍了PEARL,一个验证和操作化扰动敏感性假设(PSH)以检测LLM中记忆的框架。通过在GPT-4和Pythia模型上跨多种数据集进行实验,我们证明扰动敏感性作为记忆的可靠指标,特别是在需要精确内容再现的任务中。我们的研究结果揭示记忆模式强烈依赖于任务,并在独特或独特内容中更为普遍。随着AI系统继续扩展,PEARL为解决数据隐私问题以及模型评估中的偏见提供了有价值的见解,并为负责任的AI开发和训练数据使用的讨论做出了贡献。
参考文献
EU AI Act: 第一个人工智能法规 - 主题 - 欧洲议会 - europarl.europa.eu. https://www.europarl.europa.eu/topics/en/article/20230601STO93804/eu-ai-act-first-regulation-on-artificial-intelligence#transparency-requirements-1.
Biderman, S., Schoelkopf, H., Anthony, Q., Bradley, H., O’Brien, K., Hallahan, E., Khan, M. A., Purohit, S., Prashanth, U. S., Raff, E., Skowron, A., Sutawika, L., and van der Wal, O. Pythia: 分析大规模语言模型在训练和扩展中的套件,2023年5月。URL http://arxiv.org/abs/2304.01373. arXiv:2304.01373 [cs].
Carlini, N., Tramèr, F., Wallace, E., Jagielski, M., HerbertVoss, A., Lee, K., Roberts, A., Brown, T., Song, D., Erlingsson, U., Oprea, A., and Raffel, C. 从大规模语言模型中提取训练数据。收录于第30届USENIX安全研讨会论文集。USENIX Association,2021年。
Carlini, N., Ippolito, D., Jagielski, M., Lee, K., Tramer, F., and Zhang, C. 跨神经语言模型量化记忆,2023年3月。URL http://arxiv.org/abs/2202.07646. arXiv:2202.07646 [cs].
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. D. O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman,
G., 等人. 评估训练代码的大规模语言模型。arXiv预印本arXiv:2107.03374, 2021.
Dankers, V. 和 Titov, I. 首先泛化,然后记忆?自然语言分类任务的记忆定位,2024年8月。URL http://arxiv.org/abs/2408.04965. arXiv:2408.04965 [cs].
Dong, Y., Jiang, X., Liu, H., Jin, Z., Gu, B., Yang, M., 和 Li, G. 泛化还是记忆:大规模语言模型的数据污染与可信评估,2024年5月。URL http://arxiv.org/abs/2402.15938. arXiv:2402.15938.
Duan, M., Suri, A., Mireshghallah, N., Min, S., Shi, W., Zettlemoyer, L., Tsvetkov, Y., Choi, Y., Evans, D., 和 Hajishirzi, H. 成员推断攻击是否适用于大规模语言模型?2024年2月。URL http: //arxiv.org/abs/2402.07841. arXiv:2402.07841 [cs].
Gao, L., Biderman, S., Black, S., Golding, L., Hoppe, T., Foster, C., Phang, J., He, H., Thite, A., Nabeshima, N., Presser, S., 和 Leahy, C. The Pile: 一个800GB的多样化文本数据集,用于语言建模,2020年12月。URL http://arxiv.org/abs/2101.00027. arXiv:2101.00027 [cs]。
Golchin, S. 和 Surdeanu, M. 时间旅行在LLMs中:追踪大规模语言模型中的数据污染,2024年2月。URL http://arxiv.org/abs/2308.08493. arXiv:2308.08493 [cs]。
Hartmann, V., Suri, A., Bindschaedler, V., Evans, D., Tople, S., 和 West, R. SoK: 通用大规模语言模型中的记忆,2023年10月。URL http://arxiv. org/abs/2310.18362. arXiv:2310.18362 [cs]。
Intelligence, A. A. G. 亚马逊诺瓦系列模型:技术报告和模型卡。2024年。
Lin, C.-Y. ROUGE:自动摘要评估包。在Text Summarization Branches Out,第74-81页,西班牙巴塞罗那,2004年7月。计算语言学协会。URL https://aclanthology. org/W04-1013/。
Lukas, N., Salem, A., Sim, R., Tople, S., Wutschitz, L., 和 Zanella-Béguelin, S. 分析语言模型中个人可识别信息的泄漏。2023年IEEE安全与隐私研讨会(SP),第346-363页。IEEE,2023年。URL https://ieeexplore.ieee. org/abstract/document/10179300/。
Matton, A., Sherborne, T., Aumiller, D., Tommasone, E., Alizadeh, M., He, J., Ma, R., Voisin, M., GilsenanMcMahon, E., 和 Gallé, M. 关于代码生成评估数据集的泄露问题,2024年7月。URL http: //arxiv.org/abs/2407.07565. arXiv:2407.07565 [cs]。
nytimes. 时报起诉OpenAI和微软关于使用受版权保护作品的人工智能。https://www.nytimes.com/2023/12/27/business/media/ new-york-times-open-ai-microsoft-lawsuit.html, 2023. [在线;2025年1月22日访问].
Penedo, G., Malartic, Q., Hesslow, D., Cojocaru, R., Cappelli, A., Alobeidli, H., Pannier, B., Almazrouei, E., 和 Launay, J. Falcon LLM的精炼网络数据集:仅用网络数据超越策划语料库,2023年6月。URL http://arxiv.org/abs/2306. 01116. arXiv:2306.01116 [cs].
Schwarzschild, A., Feng, Z., Maini, P., Lipton, Z. C., 和 Kolter, J. Z. 通过对抗性压缩重新思考LLM记忆,2024年11月。URL http://arxiv.org/abs/2404.15146. arXiv:2404.15146.
Speicher, T., Khan, M. A., Wu, Q., Nanda, V., Das, S., Ghosh, B., Gummadi, K. P., 和 Terzi, E. 理解LLM中的记忆:动态、影响因素及意义,2024年7月。URL http://arxiv.org/abs/ 2407.19262. arXiv:2407.19262 [cs].
Yan, B., Li, K., Xu, M., Dong, Y., Zhang, Y., Ren, Z., 和 Cheng, X. 论保护大规模语言模型(LLMs)的数据隐私:综述,2024年3月。URL http://arxiv.org/abs/2403.05156. arXiv:2403.05156 [cs].
Yao, Y., Duan, J., Xu, K., Cai, Y., Sun, Z., 和
Zhang, Y. 大规模语言模型(LLM)安全与隐私调查:好的、坏的和丑陋的。高可信度计算,第100211页,2024年。URL https://www.sciencedirect.com/science/article/pii/ S266729522400014X。出版商:Elsevier。
Zewe, A. 研究:大型语言模型训练中使用的数据集往往缺乏透明度 - news.mit.edu。https://news.mit.edu/2024/ study-large-language-models-datasets-lack-transparency-0830, 2024.
Zhou, K., Zhu, Y., Chen, Z., Chen, W., Zhao, W. X., Chen, X., Lin, Y., Wen, J.-R., 和 Han, J. 别让你的LLM成为评估基准作弊者,2023年11月。URL http://arxiv.org/abs/2311.01964. arXiv:2311.01964 [cs].
Zhou, Z., Xiang, J., Chen, C., 和 Su, S. 定量分析和研究大规模语言模型中的实体级记忆。收录于AAAI人工智能会议论文集,第38卷,第19741-19749页,2024年。URL https://ojs.aaai.org/index.php/AAAI/article/ view/29948。期号:17。
Zou, A., Wang, Z., Carlini, N., Nasr, M., Kolter, J. Z., 和 Fredrikson, M. 针对对齐语言模型的普遍且可转移的对抗攻击。arXiv预印本arXiv:2307.15043, 2023.
附录
数据可用性
为了开放科学,我们向社区提供了研究中使用的所有人工制品。项目存储库包括所有人工制品(工具、数据集等),可在以下网址获取:
https://github.com/Berickal/PEARL
附录1:对抗压缩比(ACR) vs 扰动敏感性假设(PSH)
我们将白盒方法ACR (Schwarzschild等人,2024)的检测结果与我们的黑盒方法PSH进行比较。两者均应用于Pythia 410m。由于ACR的作者将其应用于FamousQuotes数据集的100个样本子集,我们在该数据集上执行PEARL的文本完成任务。基于RefineWeb的PEARL假阳性率设置相同的敏感性阈值 ( α = 0.2 ) (\alpha=0.2) (α=0.2),我们总体检测到16例记忆案例,而ACR检测到15例。图10显示我们的检测与PSH识别的记忆案例重叠了 50 % 50 \% 50%。
图10. 使用PSH和ACR检测到的记忆案例的重叠
图11展示了通过ACR检测到的样本和通过PSH检测到的样本的敏感性值分布。
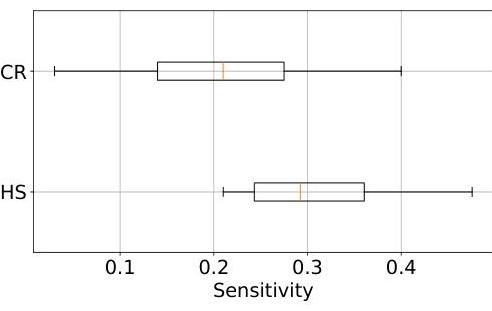
图11. PEARL为使用ACR检测到的样本与使用PSH检测到的样本提供的敏感性值分布
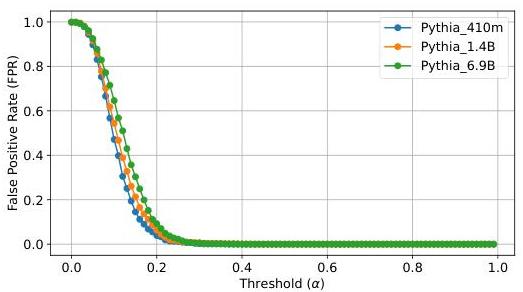
附录2:不同大小的Pythia模型给定敏感性阈值 α \alpha α变化时FPR的演变
为了确定不同尺寸变体Pythia的相关敏感性阈值,我们将其应用于RefineWeb并评估通过改变
α
\alpha
α超参数获得的FPR分数。下图提供了FPR分数的演变情况。
附录3:LBPP数据集给定敏感性阈值
α
\alpha
α变化时GPT_4o模型的FPR演变 - 代码完成任务
附录4:LBPP数据集给定敏感性阈值
α
\alpha
α变化时GPT_4o模型的FPR演变 - 代码摘要任务
附录5:PSH插图示例
本附录展示了第2节中用来说明PSH的示例。
训练集中的数据样本
莎士比亚的文字:《辛白林》(1609)摘录。
输入:我的错误无足轻重——我已多次告诉过你们——只是两个恶棍,他们的虚假誓言在我完美的荣誉之前占了上风,声称我和罗马人串通一气:于是随之而来的是我的流放,这二十年来,这块岩石和这些领地就是我的世界;我在那里以诚实的自由生活,向上帝偿还了更多的虔诚债务,胜过我在以前所有时间里所做的一切。但上山去!这不是猎人的语言:先打到鹿的人将成为宴会的主人;另外两个人将为他服务;我们不会害怕任何毒药,它只存在于更高地位的地方。我会在山谷中与你们会合。[Guiderus和Arviragus退场] 要隐藏天性的火花是多么困难啊!这两个男孩几乎不知道他们是国王的儿子;Cymbeline也梦想不到他们还活着。他们以为是我的孩子;尽管他们在洞穴中被抚养长大,他们的思想却触及宫殿的屋顶,天性促使他们在简单和低微的事物中表现得像王子一样,远超过其他人的技巧。这个Polydore,Cymbeline和英国的继承人,他的父亲国王称他为Guiderius——朱庇特啊!当我坐在三英尺高的凳子上讲述我曾经的英勇事迹时,他的精神就飞入我的故事中:他说“就这样,我的敌人倒下了,我就这样把脚踩在他的脖子上”;就在那时,王子的血在脸颊上涌动,他出汗了,绷紧年轻的肌肉,并把自己摆成姿势,表演我的话语。年轻一点的弟弟Cadwal,从前叫Arviragus,在同样的姿态下,赋予我的话语生命,展现更多自己的构思。——听…… […]
参考输出: […]游戏开始了!哦,辛白林!天堂和我的良心知道你对我是不公正的流放我:当时,当他们三岁和两岁时,我偷走了这些婴儿;我认为这样可以阻止你继承王位,就像你剥夺了我的土地一样。Euriphile, 你是他们的奶妈;他们把你当作母亲,每天都在她的坟墓前致敬:我自己,Belarius,被称为Morgan,他们把我当作亲生父亲。游戏结束了。
不在训练集中的数据样本
BBC文章:摘自BBC(2024年7月3日发布)
输入:一只座头鲸被泽西岛的小学生在从萨克岛一日游返回途中发现。圣劳伦斯小学和奥弗恩中学的教师和学生们在周一旅行时用视频和照片记录了这一发现。来自英国潜水员海洋生物救援组织海峡群岛分会的唐娜·吉奎尔·德·格鲁希表示,这只座头鲸似乎是一只年轻的鲸鱼。她说这是一个“非常幸运和罕见的发现”,她希望这是健康水域的一个迹象。去年7月,还有两只座头鲸在海峡群岛附近被发现。当地野生动物专家丽兹·斯威特形容最近在根西水域发现这些生物“非常罕见”和“非常特别”。斯威特女士说,增加可能是由于鲸鱼迷失方向。她说:“有一条巨大的迁徙路线穿过比斯开湾,然后绕爱尔兰海岸向上,它们正前往北极的觅食地。”“那里非常繁忙,非常嘈杂的水域,这些动物很容易有点困惑,也许有点迷路。” 她的 […]
参考输出 : […]另一种理论认为,上升的海水温度可能正在引诱鲸鱼的食物更靠近海峡群岛。斯威特女士解释说:“鱼类移动得很频繁,所以它可能是跟着食物来的,因此它可能只是在这里短暂停留。”
附录6 :识别的GPT 40记忆实例列表
本附录列出了根据第4.4节描述的完成任务识别为记忆的数据, α = 0.29 \alpha=0.29 α=0.29,汇总在表4中。问题编号栏标识其在原始数据集中的问题。
我们识别为记忆的圣经文本实例如下:
#262:噢,您听到祷告的声音,万有都要归向您。罪孽与我作对:至于我们的过犯,您要赦免他们。蒙您拣选,并使他亲近您,住在您的院中的人是有福的:我们要因您家的美善,甚至因您圣殿的美善而满足。上帝啊,您将以正义回应我们,因为您是我们拯救的保障;您是全地尽头和海上的可靠依靠:祂以力量坚固山脉;腰间束着力量:祂平息海洋的喧嚣,海浪的喧嚣,和人民的骚乱。住在极远处的人因您的记号而战栗:您使早晨和傍晚的出现令人喜悦。您拜访大地,浇灌它:您大大丰富它,充满水的河流:您为它预备粮食,当您如此提供时。您充分浇灌它的脊梁:您设定它的沟壑:您使它柔软于阵雨:您赐福它发芽。您以您的美好冠冕一年:您的道路滴下肥膏。它们滴在旷野的牧场:小山四面欢欣。牧场披着羊群;山谷也盖满了谷物;它们欢呼,它们歌唱。向神欢呼吧,所有土地:唱出祂名的荣耀:让祂的赞美辉煌。
#289:但愿每个人都能证明自己的工作,那么他就会独自感到欢喜,而不是在另一个人身上。因为每个人都必须背负自己的担子。教导他人话语的人应与教导者分享一切美好的事物。不要自欺;上帝是不会被戏弄的: 因为无论一个人种什么,他也会收获什么。因为他播撒肉体的种子,他将从肉体中收获腐朽;但他播撒圣灵的种子,他将从圣灵中收获永恒的生命。让我们不要在行善上疲倦:因为在适当的时候,如果我们不放弃,我们一定会收获。既然我们有机会,让我们向所有人做好事,特别是向信仰之家的人做好事。你看我亲手写给你们的信多么大。那些想要在外表上炫耀的人强迫你们接受割礼;只是因为他们不想因基督的十字架而遭受迫害。因为他们自己受割礼的人也不遵守律法;但他们想让你们受割礼,以便在你们的肉体上夸耀。然而,我绝不愿夸耀,除非夸耀我们的主耶稣基督的十字架,借着他,世界对我已经钉死,我也对世界已经钉死。因为在基督耶稣里,割礼毫无价值,未割礼也毫无价值,只有新造的人才重要。凡按此规则行事的人,愿平安与怜悯降临他们,以及上帝的以色列民。
附录7 :纽约时报与圣经文本之间的敏感性比较
本附录展示了根据第4.4节介绍的完成任务考虑的纽约时报和圣经文本中具有最高敏感性和最低敏感性的实例。结果总结在表5中。
#261:现在,以色列长子吕便的儿子们(他是长子;但由于他玷污了他父亲的床,他的长子权被转给了约瑟的儿子们:并且家谱不能按长子权计算。犹大在他的兄弟中占优势,他的后裔中产生了统治者;但长子权属于约瑟:) 吕便,以色列的长子的儿子们是:哈诺,帕流,赫斯伦,和迦米。约珥的儿子是:示玛雅他的儿子,歌他的儿子,示每他的儿子,米迦他的儿子,利亚雅他的儿子,巴力他的儿子,比拉他的儿子,提革拉毗勒尼色王把他掳走:他是吕便人的领袖。他的兄弟们按家族计算他们的世系,是最重要的,耶以勒,和撒迦利亚,和巴拉的儿子阿撒的儿子示玛的儿子约珥,他们住在亚罗珥,一直到尼波和巴力米安:他在东边一直住到从幼发拉底河进入旷野的入口处:因为他们在基列地的牲畜增多。扫罗的日子,他们与哈基莱人作战,哈基莱人倒在他们手中:他们住在基列全地东部的帐篷里。加得的子孙住在他们对面,从巴珊到沙拉迦:约珥是领袖,其次是沙法姆,雅乃和沙法坦在巴珊。他们的兄弟们,他们父家的家人是:米迦勒,米书兰,示巴,约赖,雅干,洗雅,和希伯,七个。
#262:噢,您听到祷告的声音,万有都要归向您。罪孽与我作对:至于我们的过犯,您要赦免他们。蒙您拣选,并使他亲近您,住在您的院中的人是有福的:我们要因您家的美善,甚至因您圣殿的美善而满足。上帝啊,您将以正义回应我们,因为您是我们拯救的保障;您是全地尽头和海上的可靠依靠:祂以力量坚固山脉;腰间束着力量:祂平息海洋的喧嚣,海浪的喧嚣,和人民的骚乱。住在极远处的人因您的记号而战栗:您使早晨和傍晚的出现令人喜悦。您拜访大地,浇灌它:您大大丰富它,充满水的河流:您为它预备粮食,当您如此提供时。您充分浇灌它的脊梁:您设定它的沟壑:您使它柔软于阵雨:您赐福它发芽。您以您的美好冠冕一年:您的道路滴下肥膏。它们滴在旷野的牧场:小山四面欢欣。牧场披着羊群;山谷也盖满了谷物;它们欢呼,它们歌唱。向神欢呼吧,所有土地:唱出祂名的荣耀:让祂的赞美辉煌。
#301:我认为如果我不向专家请教他们的意见,我的可信度会受到影响,”他说。州长还说,预测和实际统计数据之间的差异是因为纽约人自己的行为。除了某些例外,纽约人已经设法遵守了行动和社交限制。白宫冠状病毒应对协调员黛博拉·伯克斯博士似乎同意,并在周五祝贺科莫先生和他的同行成功减缓了他们各州感染潮的蔓延。“这是因为纽约和新泽西的公民以及康涅狄格州和现在的罗德岛所做的真正改变这场大流行病进程的努力,这种变化极大地改变了。”伯克斯博士说。当然,出于政治和公共卫生原因,当选领导人过度计划而非低估灾难是明智的。例如,在飓风期间,州长更有可能通过提前下令疏散而不是寄希望于风暴减弱来挽救选民的生命和自己的职位。控制疫情爆发曲线的主要目标之一,除了防止人们死亡外,就是减缓传播速度,以保持医院的正常运转。从冠状病毒紧急情况开始,科莫先生就反复采取立场,他表示宁愿为从未发生过的严峻情景做好准备,也不愿盲目相信乐观的预测。讽刺的是,他那种末日态度可能会使他在纽约人开始意识到最糟糕的情况并未发生时,努力保持州内秩序变得复杂。
| #ID | 来源 | m ( Y N ∗ ) m\left(Y_{N}^{*}\right) m(YN∗) | m ( Y I ∗ ) m\left(Y_{I}^{*}\right) m(YI∗) | m ( Y N ∗ ) m\left(Y_{N}^{*}\right) m(YN∗) | m ( Y N ∗ ) m\left(Y_{N}^{*}\right) m(YN∗) | m ( Y I ∗ ) m\left(Y_{I}^{*}\right) m(YI∗) | m ( Y N ∗ ) m\left(Y_{N}^{*}\right) m(YN∗) | 敏感性 | 问题编号 |
|---|---|---|---|---|---|---|---|---|---|
| #17 | LBPP | 0.42 | 0.23 | 0.51 | 0.18 | 0.21 | 0.25 | 0.32 | LBPP/17 |
| #58 | LBPP | 0.32 | 0.62 | 0.37 | 0.35 | 0.34 | 0.45 | 0.29 | LBPP/58 |
| #103 | HumanEval | 0.8 | 0.49 | 0.8 | 0.73 | 0.38 | 0.24 | 0.34 | HumanEval/3 |
| #105 | HumanEval | 0.68 | 0.32 | 0.42 | 0.55 | 0.32 | 0.24 | 0.36 | HumanEval/5 |
| #107 | HumanEval | 0.66 | 0.24 | 0.21 | 0.19 | 0.14 | 0.12 | 0.42 | HumanEval/7 |
| #113 | HumanEval | 0.71 | 0.53 | 0.24 | 0.76 | 0.3 | 0.26 | 0.53 | HumanEval/13 |
| #114 | HumanEval | 0.55 | 0.56 | 0.27 | 0.49 | 0.29 | 0.22 | 0.3 | HumanEval/14 |
| #115 | HumanEval | 0.65 | 0.3 | 0.26 | 0.29 | 0.17 | 0.24 | 0.35 | HumanEval/15 |
| #116 | HumanEval | 0.62 | 0.38 | 0.2 | 0.16 | 0.44 | 0.12 | 0.32 | HumanEval/16 |
| #122 | HumanEval | 0.67 | 0.33 | 0.21 | 0.67 | 0.19 | 0.19 | 0.48 | HumanEval/22 |
| #123 | HumanEval | 0.87 | 0.68 | 0.22 | 0.19 | 0.21 | 0.08 | 0.46 | HumanEval/23 |
| #127 | HumanEval | 0.56 | 0.19 | 0.72 | 0.19 | 0.13 | 0.14 | 0.53 | HumanEval/27 |
| #128 | HumanEval | 0.64 | 0.2 | 0.41 | 0.22 | 0.26 | 0.17 | 0.44 | HumanEval/28 |
| #129 | HumanEval | 0.71 | 0.33 | 0.18 | 0.2 | 0.62 | 0.18 | 0.44 | HumanEval/29 |
| #130 | HumanEval | 0.55 | 0.15 | 0.18 | 0.13 | 0.17 | 0.15 | 0.4 | HumanEval/30 |
| #134 | HumanEval | 0.66 | 0.24 | 0.22 | 0.08 | 0.15 | 0.15 | 0.43 | HumanEval/34 |
| #142 | HumanEval | 0.55 | 0.49 | 0.42 | 0.13 | 0.17 | 0.16 | 0.29 | HumanEval/42 |
| #145 | HumanEval | 0.46 | 0.16 | 0.29 | 0.11 | 0.09 | 0.11 | 0.3 | HumanEval/45 |
| #154 | HumanEval | 0.67 | 0.14 | 0.41 | 0.14 | 0.18 | 0.1 | 0.53 | HumanEval/54 |
| #162 | HumanEval | 0.49 | 0.49 | 0.12 | 0.16 | 0.15 | 0.16 | 0.37 | HumanEval/62 |
| #166 | HumanEval | 0.64 | 0.57 | 0.2 | 0.35 | 0.22 | 0.39 | 0.37 | HumanEval/66 |
| #175 | HumanEval | 0.29 | 0.43 | 0.13 | 0.23 | 0.14 | 0.23 | 0.3 | HumanEval/75 |
| #180 | HumanEval | 0.7 | 0.67 | 0.71 | 0.29 | 0.34 | 0.33 | 0.42 | HumanEval/80 |
| #188 | HumanEval | 0.43 | 0.13 | 0.24 | 0.16 | 0.21 | 0.15 | 0.29 | HumanEval/88 |
| #198 | HumanEval | 0.67 | 0.61 | 0.32 | 0.31 | 0.34 | 0.35 | 0.29 | HumanEval/98 |
| #262 | 圣经 | 0.65 | 0.18 | 0.18 | 0.09 | 0.1 | 0.09 | 0.47 | - |
| #289 | 圣经 | 0.63 | 0.23 | 0.09 | 0.09 | 0.08 | 0.08 | 0.4 | - |
表4. 在文本完成任务中GPT. 4 o识别的记忆案例列表。
| 来源 | 最低敏感性 | 最高敏感性 | ||
|---|---|---|---|---|
| #ID | 敏感性 | #ID | 敏感性 | |
| 圣经 | #261 | 0.019 | #262 | 0.469 |
| 纽约时报 | #301 | 0.007 | #304 | 0.266 |
表5. 最低和最高敏感性在
实现最坏情况尚未发生并最终感到不安想要外出。
#304:-猴子从苏格兰野生动物园逃脱后从鸟食器中取食 - 法国农民封锁巴黎周围的道路,升级抗议活动 - 俄罗斯军用飞机在乌克兰边境附近坠毁 - 冬季风暴导致希思罗机场降落困难 - 美国敦促以色列减少加沙平民的痛苦,布林肯说 近期欧洲历史事件哥本哈根证券交易所部分在火灾中倒塌 - 哥本哈根证券交易所部分在火灾中倒塌一人死亡缆车事故 - 土耳其缆车事故致一人死亡 德国警方阻止亲巴勒斯坦会议 - 德国警方阻止亲巴勒斯坦会议 埃特纳火山喷发烟圈 - 埃特纳火山喷发烟圈 伊斯坦布尔夜总会火灾致29人死亡0:48 伊斯坦布尔夜总会火灾致29人死亡 服务员参加巴黎复兴的咖啡比赛 - 服务员参加巴黎复兴的咖啡比赛 威尔斯公主宣布癌症诊断 - 威尔斯公主宣布癌症诊断 俄罗斯打击切断哈尔科夫的电力供应并扰乱供水 - 俄罗斯打击切断哈尔科夫的电力供应并扰乱供水 俄罗斯东南部乌克兰家园遭袭击摧毁 - 俄罗斯东南部乌克兰家园遭袭击摧毁 导弹袭击基辅 - 导弹袭击基辅 冰岛西南部火山喷发 - 冰岛西南部火山喷发 法国将堕胎权利写入宪法 - 法国将堕胎权利写入宪法。
参考论文:https://arxiv.org/pdf/2505.03019


















 802
802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











