







 文章介绍了SynFundus-1M数据集,包含11种眼底疾病标注和高质量图像,通过DDPM和VAE生成技术合成大量眼底图像。该数据集对医学图像分析和疾病检测有重要价值,且实验结果显示合成图像与真实图像难以区分。研究者承诺将用于非商业学术研究并遵守CC-BY-NC-SA4.0协议。
文章介绍了SynFundus-1M数据集,包含11种眼底疾病标注和高质量图像,通过DDPM和VAE生成技术合成大量眼底图像。该数据集对医学图像分析和疾病检测有重要价值,且实验结果显示合成图像与真实图像难以区分。研究者承诺将用于非商业学术研究并遵守CC-BY-NC-SA4.0协议。
12 个类别
论文:https://arxiv.org/pdf/2312.00377.pdf
代码:https://github.com/parap1uie-s/SynFundus-1M
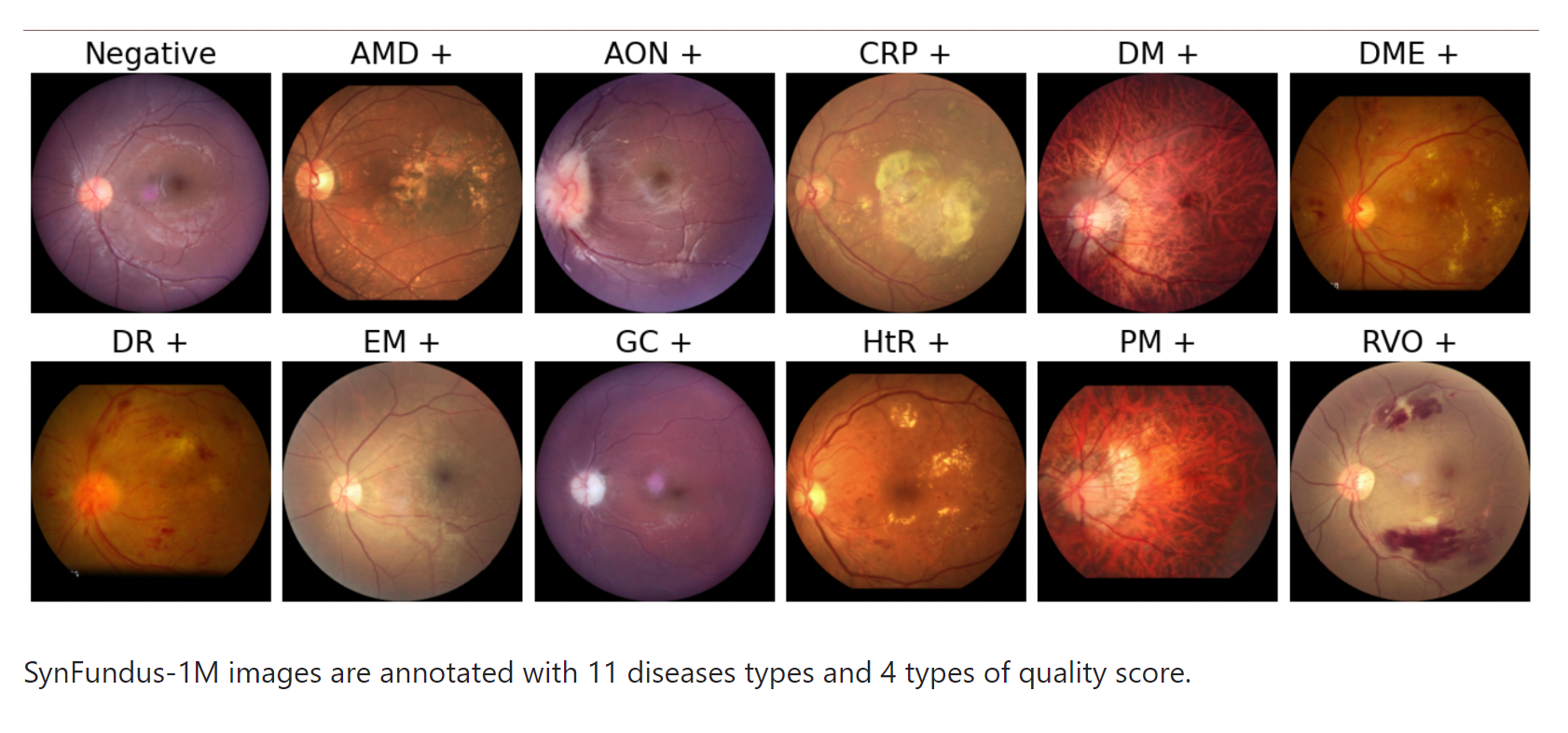
SynFundus-1M数据集中包含了以下11种眼底疾病的标注:
-
糖尿病视网膜病变(Diabetic Retinopathy, DR):这是糖尿病引起的眼病,影响眼底的血管,可能导致视力损失。
-
年龄相关性黄斑变性(Age-related Macular Degeneration, AMD):这是一种影响黄斑(视网膜中心区域)的疾病,通常与年龄增长有关,是老年人失明的主要原因之一。
-
视神经异常(Anomalies of the Optic Nerve, AON):涉及视神经的疾病,可能包括视神经萎缩或视神经炎等。
-
脉络膜视网膜病变(Choroidal Retinal Pathology, CRP):脉络膜是视网膜后的血管层,相关疾病可能包括脉络膜肿瘤或脉络膜炎。
-
变性近视(Degenerative Myopia, DM):一种近视恶化的情况,可能导致视网膜脱落或其他严重的视网膜病变。
-
糖尿病性黄斑水肿(Diabetic Macular Edema, DME):糖尿病的并发症,特点是黄斑区域的液体积聚,影响中央视力。
-
黄斑前膜(Epimacular Membrane, EM):一层透明的组织在黄斑区域上形成,可能导致视力模糊或扭曲。
-
青光眼(Glaucoma, GC):一组疾病,主要特征是眼压升高,可能导致视神经损害和视力丧失。
-
高血压视网膜病变(Hypertensive Retinopathy, HtR):由高血压引起的眼底血管改变。
-
病理性近视(Pathological Myopia, PM):一种严重的近视,可导致新血管生成和视网膜脱离。
-
视网膜静脉阻塞(Retinal Vein Occlusion, RVO):视网膜静脉由于血栓或压迫而发生阻塞,导致视力急剧下降。
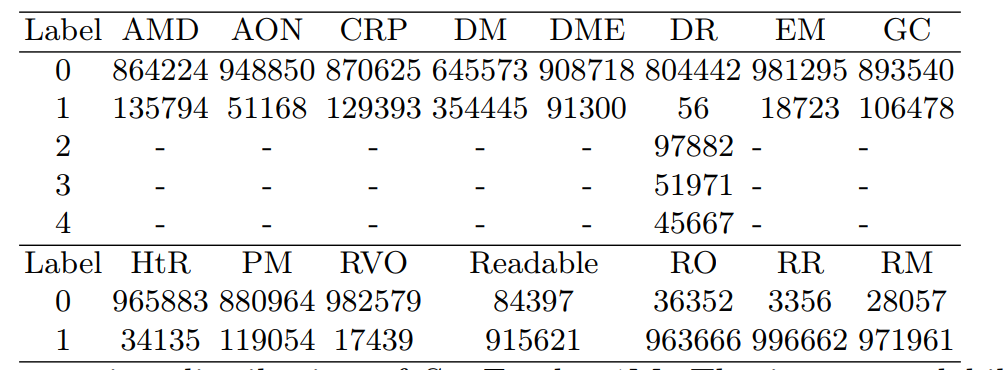
这张表显示了SynFundus-1M数据集的注释分布。
列出了每种疾病标签及其对应的图像数量,还包括了图像可读性的标签数量。
- 标签“0”和“1”代表了每个条件的二元状态,例如在疾病标签中,“0”可能代表没有该疾病,而“1”代表有该疾病。
- 对于可读性标签,数字“1”表示图像或图像的某个区域是可读的,这包括整个眼底(Readable)、光学盘(RO)、视网膜区域(RR)、黄斑区域(RM)。
在这种情况下,较高的数字意味着更好的图像质量和清晰度,这对于诊断和自动图像分析非常重要。
- 例如,“Readable”标签下的“1”表示大多数图像都是可读的,这提供了良好的数据质量。
表3还强调了SynFundus-1M数据集的一个重要特点:所有图像区域的可读性都标为“1”,这意味着数据集中的图像质量普遍良好,适合进行临床判断和计算机视觉分析。这些注释使得数据集对于训练和测试自动化疾病检测算法非常有价值。
提出背景
受到扩散模型的启发,我们训练了一个去噪扩散概率模型(DDPM),命名为SynFundus-Generator,它使用包含130万张真实眼底图像的独特私有数据集。
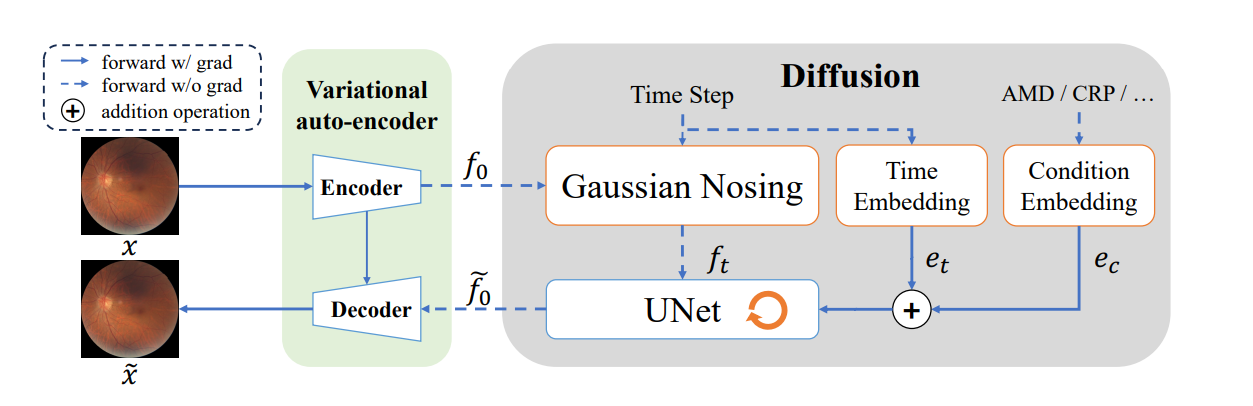
这张图展示了SynFundus-Generator的结构和工作流程。
SynFundus-Generator是一个由变分自编码器(Variational auto-encoder, VAE)和扩散模型(Diffusion model)组成的生成模型,用于生成合成的眼底图像。
-
变分自编码器部分由一个编码器(Encoder)和解码器(Decoder)组成。
编码器将原始眼底图像x转换成一个潜在表示f₀,然后解码器从这个潜在表示重构出一个图像x̃。
-
扩散模型包含高斯噪声加入过程(Gaussian Nosing)和UNet网络。
在这个过程中,潜在表示f₀被逐渐加入高斯噪声生成一系列噪声版本ft,时间步骤的嵌入(Time Embedding)和条件嵌入(Condition Embedding)与噪声版本结合,UNet被用于估计和去除这些噪声,生成清洁的潜在表示。
-
橙色箭头表示噪声估计器在噪声估计和生成过程中的迭代循环。
这个过程使得模型能够在给定的条件(如特定的眼底疾病)下生成新的图像。
条件嵌入(比如AMD/CRP等疾病标签)使得生成的图像可以特定地模拟某些疾病的特征。这种方法支持创建高质量的合成数据集,这些数据集在视觉上与真实眼底图像非常相似,但却是通过计算机生成的。
利用SynFundus-Generator,我们生成了超过一百万张合成眼底图像的集合,称为SynFundus-1M数据集,包含15种类型的注释(11种疾病标签和4种图像可读性标签)。
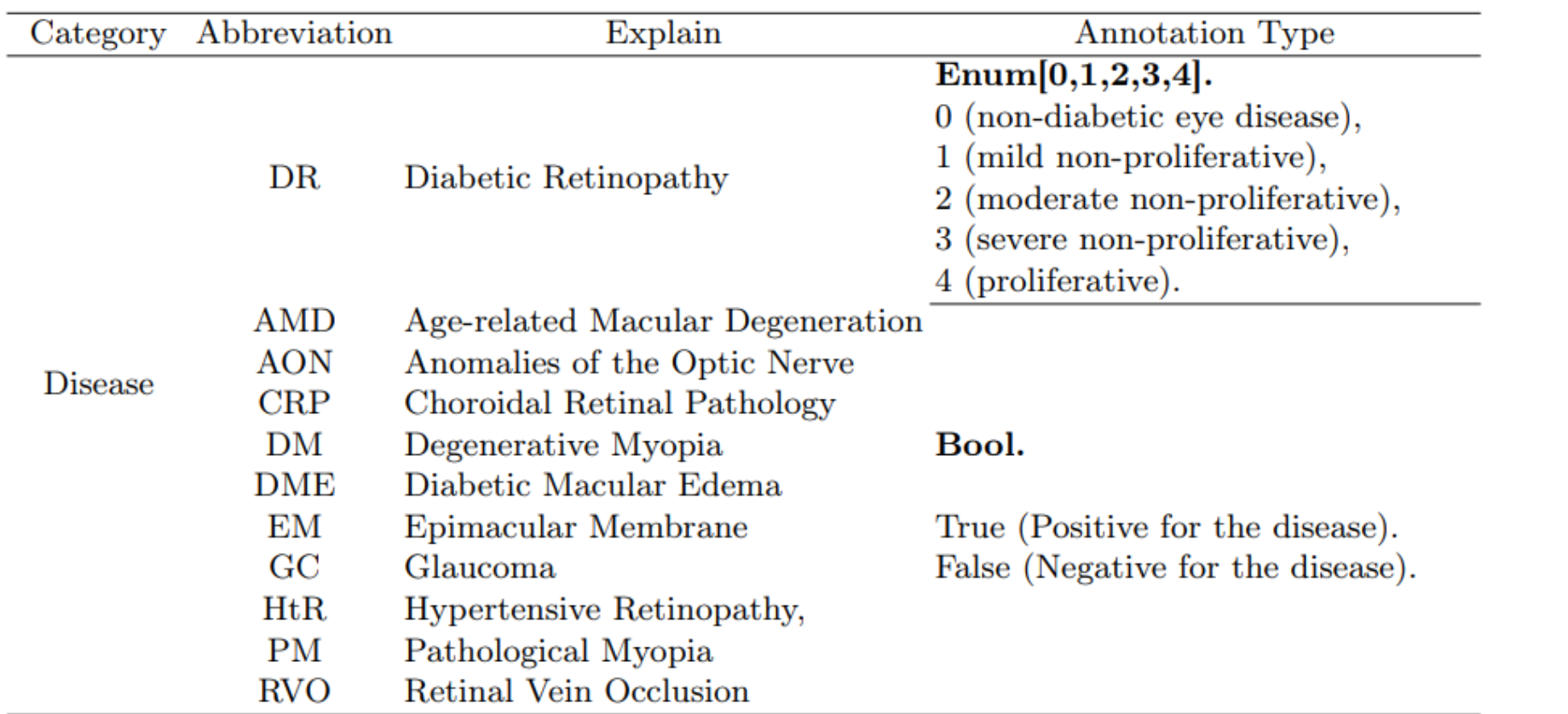
例如,糖尿病视网膜病变(Diabetic Retinopathy, DR)使用一个枚举类型来表示疾病的严重程度,从0(非糖尿病眼病)到4(增生性)。
其他疾病,如年龄相关性黄斑变性(Age-related Macular Degeneration, AMD)和青光眼(Glaucoma, GC),则使用布尔类型的标注,即True或False表示是否有疾病。
与其他开源数据集相比,发布的SynFundus-1M不仅提供了大量的眼底图像,而且还拥有涵盖各种疾病和图像可读性的更广泛的完整注释范围。
图像可读性的更广泛的完整注释范围指的是,SynFundus-1M数据集不仅标注了眼底图像是否包含特定的疾病,还细致地标注了图像中不同区域的清晰度和可用性,这对于自动分析和医学研究来说至关重要。

以SynFundus-1M数据集为例,其图像可读性注释包括:
-
整个眼底图像的可读性:这个标签指示整张图像是否有足够的质量,可以用来进行临床判断。如果图像质量差到无法提供临床上有用的信息,这个标签会被标记为不可读。
-
光学盘的可读性:光学盘是眼底的一个关键区域,与多种疾病(如青光眼)有关。如果图像中光学盘区域清晰,足以进行进一步分析,这一区域就被认为是可读的。
-
视网膜区域的可读性:这涉及眼底图像的主体部分,排除光学盘外的区域。这个区域的可读性标签是根据是否能够识别视网膜的异常来决定的。
-
黄斑区域的可读性:黄斑是负责中央视力的眼底区域。如果黄斑区域由于噪声、人为影响或曝光问题而在很大程度上受到影响,这一区域就被标记为不可读。
通过这样详细的标注,研究人员可以更精确地训练和测试他们的视网膜病变检测算法,以确保算法即使在图像质量较差的情况下也能保持高性能。

这张图是一个表格,展示了不同的眼底图像数据集。
表中列出了每个数据集的名称,可用图像的数量,以及它们是否含有特定类型的注释,包括青光眼、糖尿病视网膜病变、病理性近视以及其他疾病。
此外,还标注了这些数据集中图像的可读性。
在最后一行,SynFundus-1M数据集与其他数据集进行了对比,显示它拥有超过一百万张图片,并且包含有关青光眼、糖尿病视网膜病变、病理性近视的注释。
此外,还有其他8种疾病类型的注释和4种可读性评分。
这表明SynFundus-1M在眼底图像数据集中,因其大量的数据和复杂的注释而被突出显示。
效果评估
广泛的实验表明,即使是经验丰富的标注者也难以将我们的合成图像与真实图像区分开来,合成的疾病相关视觉特征也无法与真实的区分。
通过使用SynFundus-1M数据集进行微调和预训练,眼底图像分析模型的性能得到了提升。
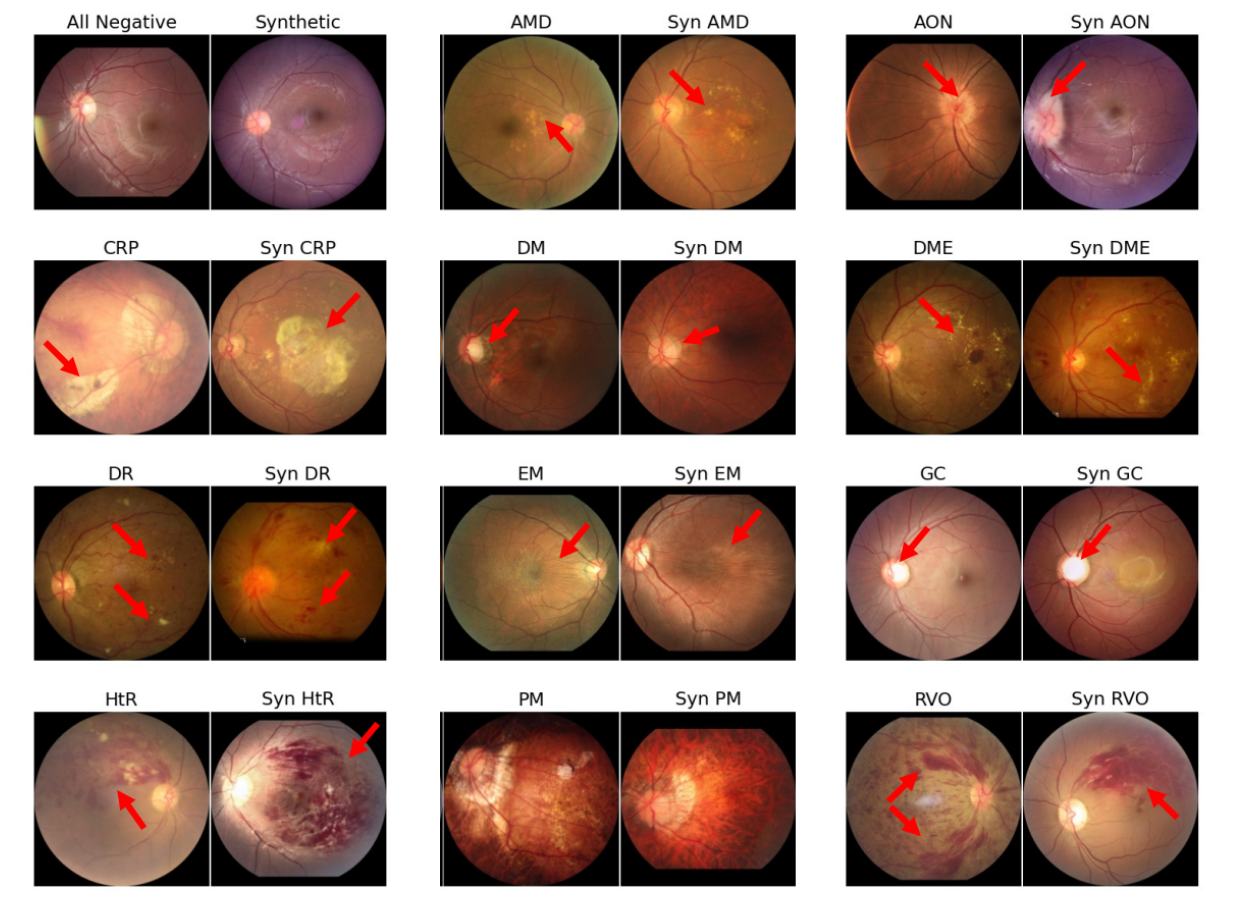
这张图展示了真实眼底图像(奇数列)与合成眼底图像(偶数列)在各种疾病状态下的比较。
每一对图像都代表一种特定的眼底疾病或状况,比如年龄相关性黄斑变性(AMD)、视神经异常(AON)、脉络膜视网膜病变(CRP)等。
红色箭头标注了与疾病相关的视觉特征,如病变或损伤,这些特征在真实图像和合成图像之间非常相似。
图中的对比旨在显示SynFundus-1M数据集中合成图像的质量,证明它们在视觉上与真实图像几乎无法区分,说明这些合成图像在模拟疾病特征方面的高精确度。
通过这种方式,合成图像可用于支持眼底图像分析和疾病诊断模型的训练,而不需依赖仅有的真实图像数据,这对于保护患者隐私和降低标注成本非常有益。
数据获取
I plan to use the SynFundus-1M dataset in my medical imaging research to further investigate and improve the automated detection and classification methods for retinal diseases. This will be a non-profit academic study, and it may be mentioned in future academic papers.
I am aware that SynFundus-1M is protected by the CC-BY-NC-SA 4.0 license and I commit to abiding by this agreement: Yes
I promise not to use SynFundus-1M for commercial purposes: Yes

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









