







 本文探讨了多元相关性,从分布和直观角度理解相关矩阵,并介绍了白化处理。接着,详细阐述了主成分分析(PCA)的原理,指出PCA本质也是一种去相关方法,并讨论了PCA在图像压缩中的应用。最后,讨论了周期性和非周期性宽平稳随机过程的KL展开,展示了其与傅里叶展开的关系。
本文探讨了多元相关性,从分布和直观角度理解相关矩阵,并介绍了白化处理。接着,详细阐述了主成分分析(PCA)的原理,指出PCA本质也是一种去相关方法,并讨论了PCA在图像压缩中的应用。最后,讨论了周期性和非周期性宽平稳随机过程的KL展开,展示了其与傅里叶展开的关系。
多元相关
文章目录
1. 概述
相关是研究随机过程的重要工具。之前,我们研究的都是两个随机变量的相关性。现在我们想扩展到随机矢量的相关性。对多元相关问题研究的角度有两个,一个是从分布的角度来看的,另一个是从直观的角度来看的。
Z , Y ⇒ E ( Z Y ) Z = ( Z 1 , . . . , Z n ) T → Distribution → Intuitive Z,Y \Rightarrow E(ZY) \\ Z = (Z_1,...,Z_n)^T \\ \rightarrow \text{Distribution} \\ \rightarrow \text{Intuitive} Z,Y⇒E(ZY)Z=(Z1,...,Zn)T→Distribution→Intuitive
事实上,从分布的角度来表示相关并不容易,因为相互之间的作用可能会非常复杂。
我们就在二维空间上用等高线的形式,去描述两个随机变量的关系
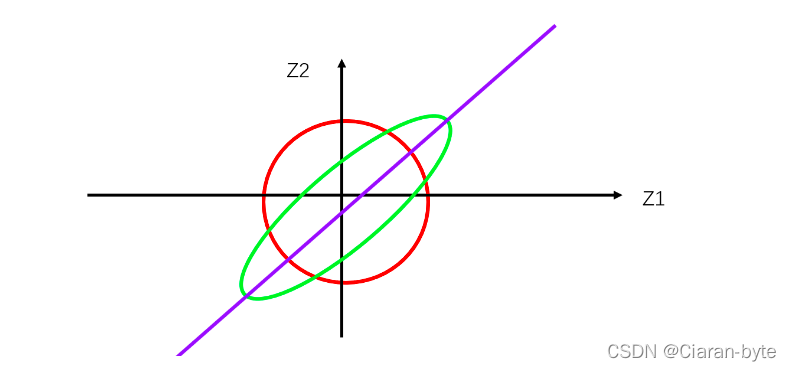
- 如果两个随机变量的等高线是个圆,那么这个两个随机变量不独立,但是没有明显的相关性
- 如果两个随机变量的等高线是个椭圆,那么这个两个随机变量不独立,并且具有明显的相关性
- 如果两个随机变量的等高线是条直线,那么两个随机变量是不独立的,并且二者之间具有强相关性
如果是更高维度的分布函数,就很难统计了。我们希望使用更加直观的方法去描述多元随机变量之间的相关关系。
事实上,我们可以用更加简单的方法,通过相关矩阵的方法去描述多元相关问题
E ( Z i Z j ) E ( Z i 2 ) ( 1 ≤ i < j ≤ n ) ⇒ C n 2 = n ( n − 1 ) 2 E(Z_i Z_j) \quad E(Z_i^2) \\ (1 \leq i <j \leq n) \Rightarrow C_n^2 = \frac{n(n-1)}{2} E(ZiZj)E(Zi2)(1≤i<j≤n)⇒Cn2=2n(n−1)
除了自相关以外,还有n(n-1)/2种的互相关
我们相关矩阵得到的描述是这样的
Correlation Matrix E ( Z Z T ) = ( E ( Z 1 2 ) E ( Z 1 Z 2 ) . . . E ( Z 1 Z n ) E ( Z 2 Z 1 ) E ( Z 2 2 ) . . . E ( Z 2 Z n ) . . . . . . . . . . . . E ( Z n Z 1 ) E ( Z n Z 2 ) . . . E ( Z n 2 ) ) \text{Correlation Matrix} \\ E(ZZ^T) = \begin{pmatrix} E(Z_1^2) & E(Z_1 Z_2) & ... & E(Z_1 Z_n)\\ E(Z_2 Z_1) & E(Z_2^2) &... & E(Z_2 Z_n) \\ ...&...&...&...&\\ E(Z_nZ_1) &E(Z_nZ_2) & ... &E(Z_n^2) \end{pmatrix} Correlation MatrixE(ZZT)= E(Z12)E(Z2Z1)...E(ZnZ1)E(Z1Z2)E(Z22)...E(ZnZ2)............E(Z1Zn)E(Z2Zn)...E(Zn2)
相关矩阵具有这样的性质
- 对称
- 正定
下面,我们将基于相关矩阵,从三个不同的角度去看待相关矩阵
- 白化
- PCA
- KL展开
2. 三个角度看待相关矩阵
2.1 白化
首先第一个角度,是去相关化的角度,我们知道,我们的随机变量之间一般都是有相关性的,但是,如果我们通过某种线性变换,然后随机变量之间的相关性可以被去掉,这个动作就叫白化,也叫做去相关性
Decorrelation (Whiten) \text{Decorrelation } \text{ (Whiten) } Decorrelation (Whiten)
∃ A Y = A Z Z ∈ R n A ∈ R n ∗ n \exists A \quad Y = AZ \\ Z \in \R^n \quad A \in \R^{n*n} ∃AY=AZZ∈RnA∈Rn∗n
经过白化处理得到的相关矩阵Y应该是个对角阵
E ( Y Y H ) = d i a g ( λ 1 , . . . . , λ n ) E(YY^H) = diag(\lambda_1,....,\lambda_n) E(YYH)=diag(λ1,....,λn)
事实上,求解A矩阵是个不适定的问题。因为未知数有n*n个,但是方程只有
n(n-1)/2个。但是我们有一些先验知识。
我们表示一下Y的相关矩阵
R Y = E ( Y Y T ) = E ( A Z Z T A T ) = A E ( Z Z T ) A T = A R Z A T R_Y = E(YY^T) = E(AZZ^TA^T) = AE(ZZ^T)A^T = A R_Z A^T RY=E(YYT)=E(AZZTAT)=AE(ZZT)AT=ARZAT
我们知道相关矩阵RZ是对称的,一定可以做谱分解(特征分解)
R Z = ∑ k = 1 n λ k u k u k T = ( u 1 . . . u n ) ( λ 1 . . . λ n ) ( u 1 T . . . u n T ) = U Λ U T R_Z =\sum_{k=1}^n \lambda_k u_k u_k^T= \begin{pmatrix} u_1 & ...& u_n \\ \end{pmatrix}\begin{pmatrix} \lambda_1 & \\ & ...& \\ && \lambda_n \end{pmatrix}\begin{pmatrix} u_1^T \\ ... \\ u_n^T \end{pmatrix} = U \Lambda U^T RZ=k=1∑nλkukukT=(u1...un) λ1...λn u1T...unT =UΛUT
其中U是RZ的特征向量矩阵,并且也是个正交矩阵
R Y = A R Z A T = ( A U ) Λ ( U T A T ) R_Y = A R_Z A^T = (AU )\Lambda (U^T A^T) RY=ARZAT=(AU)Λ(UTAT)
中间的矩阵就是个对角阵,因此,我们就得到了A
A = U T A = U^T A=UT
2.2 PCA
2.2.1 原理
Principle Component Analysis \text{Principle Component Analysis} Principle Component Analysis
再来看看PCA
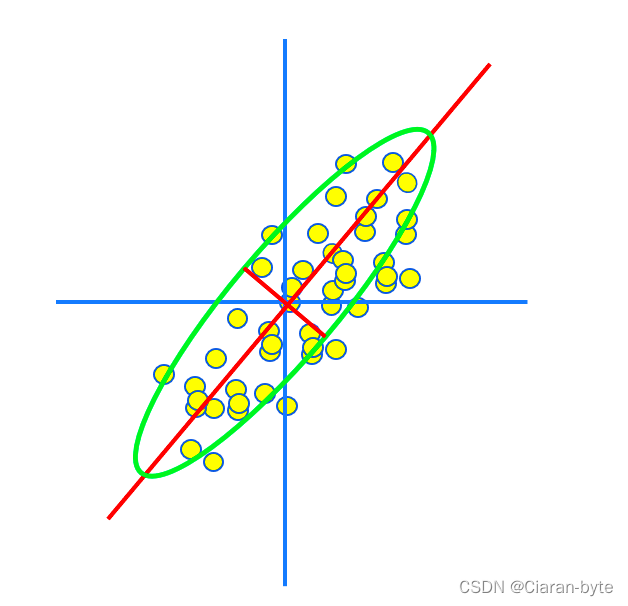
对于PCA来说,最重要的有两个方向
- 能量分布最大的方向
- 损失最小的方向
我们就是要找一个方向,然随机矢量投影在这个方向上,并且具有最大的方差
P r o j α Z = < α , Z > < α , α > α = α T Z α T α α Proj_\alpha Z = \frac{<\alpha,Z>}{<\alpha,\alpha>}\alpha= \frac{\alpha^T Z}{\alpha^T \alpha} \alpha ProjαZ=<α,α><α,Z>α=αTααTZα
方差表达式为
E
∣
∣
P
r
o
j
α
Z
∣
∣
2
=
E
(
∣
∣
α
T
Z
∣
∣
2
∣
∣
α
∣
∣
4
∣
∣
α
∣
∣
2
)
=
E
(
∣
α
T
Z
∣
2
)
∣
∣
α
∣
∣
2
=
E
(
(
α
∣
∣
α
∣
∣
)
T
Z
)
2
E||Proj_\alpha Z||^2 = E(\frac{||\alpha^TZ||^2}{||\alpha||^4}||\alpha||^2) = \frac{E(|\alpha^TZ|^2)}{||\alpha||^2} = E((\frac{\alpha}{||\alpha||})^TZ)^2
E∣∣ProjαZ∣∣2=E(∣∣α∣∣4∣∣αTZ∣∣2∣∣α∣∣2)=∣∣α∣∣2E(∣αTZ∣2)=E((∣∣α∣∣α)TZ)2
即求在方向向量为单位向量条件下的最大方差
m a x α E [ ( α T Z ) 2 ] , s.t. ∣ ∣ α ∣ ∣ 2 = 1 max_\alpha E[(\alpha^T Z)^2],\text{ s.t. } ||\alpha||^2 = 1 \\ maxαE[(αTZ)2], s.t. ∣∣α∣∣2=1
L ( α , λ ) = E [ ( α T Z ) 2 ] + λ ( α T α − 1 ) = α T E ( Z Z T ) α + λ ( α T α − 1 ) = α T R Z α + λ ( α T α − 1 ) L(\alpha,\lambda) = E[(\alpha^T Z)^2] + \lambda(\alpha^T \alpha-1) \\ = \alpha^T E(ZZ^T)\alpha + \lambda(\alpha^T \alpha-1) \\ = \alpha^T R_Z\alpha + \lambda(\alpha^T \alpha-1) L(α,λ)=E[(αTZ)2]+λ(αTα−1)=αTE(ZZT)α+λ(αTα−1)=αTRZα+λ(αTα−1)
求导
∇
α
L
(
α
)
=
2
R
Z
α
−
2
λ
α
=
0
⇒
R
Z
α
=
λ
α
\nabla_\alpha L(\alpha) = 2R_Z\alpha - 2\lambda \alpha = 0 \Rightarrow R_Z\alpha = \lambda \alpha
∇αL(α)=2RZα−2λα=0⇒RZα=λα
可以看出来,这个方向矢量一定是特征矢量。但是是哪个特征矢量呢?我们还要分析一下目标函数
m a x α E [ ( α T Z ) 2 ] = α T R Z α = λ α T α = λ max_\alpha E[(\alpha^T Z)^2] = \alpha^T R_Z \alpha = \lambda \alpha^T \alpha = \lambda maxαE[(αTZ)2]=αTRZα=λαTα=λ
因此,我们要找的,就是最大的特征值对应的特征矢量
2.2.2 PCA与去相关
PCA本质上也是在做去相关。因为经过PCA找到了主成分方向,数据彼此之间就没有相关性了
说到去相关,可以介绍一些图像压缩的问题
图像本质上是个相关性很强的数据,如果我们想把图像数据压缩,如果直接把图像切出来一部分,是肯定不行的,因为会造成极大的信息损失
图像压缩一般有这样的步骤
( 1 ) Transform Coding 变换编码 ( 2 ) Motion Coding 运动编码 ( 3 ) Entropy Coding 熵编码 (1) \text{ Transform Coding 变换编码} \\ (2) \text{ Motion Coding 运动编码} \\ (3) \text{ Entropy Coding 熵编码} (1) Transform Coding 变换编码(2) Motion Coding 运动编码(3) Entropy Coding 熵编码
变换编码首先要把图像切成不同的小块,然后对每个小块做变换,然后实现去相关。一般图像去相关不会使用PCA,因为每次都要计算相关矩阵,计算量太大。一般会使用离散余弦变换DCT或者离散小波变换DWT。因为他们的基的确定的,直接把图片投影到这些基底上即可。能够实现图片的变换编码
第二步是做运动编码,因为图片的逐帧之间可能差异并不大,只需要传递前后图像的差值即可,能够大量节约带宽
第三步是熵编码,也就是无损压缩,比如rar技术。
但是,由于现在通讯带宽很大,用不完,所以,图像压缩技术逐渐没人研究了
2.2.3 PCA几何图形影响因素
下面我们想研究个有趣的问题,主成分与x轴的夹角与随机变量的相关性有关系吗?
我们假设有这样的问题
Z = ( Z 1 , Z 2 ) E ( Z 1 ) = E ( Z 2 ) = 0 E ( Z 1 2 ) = E ( Z 2 2 ) = 1 E ( Z 1 Z 2 ) = ρ Z=(Z_1,Z_2) \quad E(Z_1) = E(Z_2) = 0 \quad E(Z_1^2) = E(Z_2^2) =1 \\ E(Z_1Z_2) = \rho Z=(Z1,Z2)E(Z1)=E(Z2)=0E(Z12)=E(Z22)=1E(Z1Z2)=ρ
假设两个随机变量均值为0,方差为1,相关为ρ,我们计算一下随机矢量Z的特征值和主成分方向
R Z = ( 1 ρ ρ 1 ) R_Z = \begin{pmatrix} 1 & \rho \\ \rho & 1 \end{pmatrix} RZ=(1ρρ1)
{ λ 1 + λ 2 = 2 λ 1 λ 2 = 1 − ρ 2 \begin{cases} \lambda_1 + \lambda_2 = 2 \\ \lambda_1 \lambda_2 = 1- \rho^2 \end{cases} {λ1+λ2=2λ1λ2=1−ρ2
⇒ { λ 1 = 1 + ρ λ 2 = 1 − ρ \Rightarrow \begin{cases} \lambda_1 = 1+ \rho\\ \lambda_2 = 1- \rho \end{cases} ⇒{λ1=1+ρλ2=1−ρ
得到特征向量
λ 1 ⇒ U 1 = ( 1 1 ) 1 2 λ 2 ⇒ U 2 = ( 1 − 1 ) 1 2 \lambda_1 \Rightarrow U_1 = \begin{pmatrix} 1 \\ 1 \end{pmatrix} \frac{1}{\sqrt{2}} \\ \lambda_2 \Rightarrow U_2 = \begin{pmatrix} 1 \\ -1 \end{pmatrix} \frac{1}{\sqrt{2}} λ1⇒U1=(11)21λ2⇒U2=(1−1)21
我们发现,主成分与x轴的夹角相关系数ρ并没有什么关系。那么主成分与x轴的夹角与什么有关?相关系数ρ又决定了什么呢?
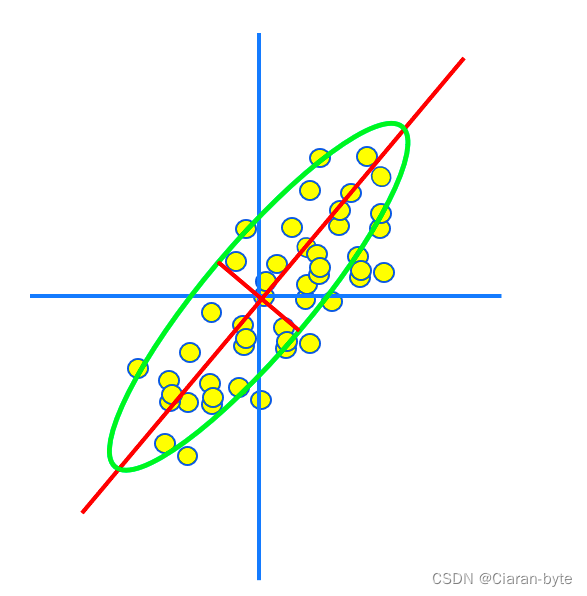
事实上,相关系数ρ决定了两个随机变量组成的纺锤形的胖瘦。ρ越大,纺锤形越瘦,相关度好。ρ=1的时候,就退化成一根线了。ρ=0的时候,就变成了一个圆,没有相关性。
而主成分的方向与两个随机变量的方差有关系。如果两个随机变量方差相等,那么他们投影在x和y轴的方差分量也应该是相等的。夹角就是45度
2.3 展开
2.3.1 随机矢量的KL展开
第三个角度是从展开讲的
我们从去相关的结果来看
Y = A Z = U T Z Z = U Y = ( u 1 . . . u n ) ∗ ( Y 1 . . . Y n ) = ∑ k = 1 n U k Y k Y = AZ = U^T Z \\ Z = UY = \begin{pmatrix} u_1 & ... u_n \\ \end{pmatrix} * \begin{pmatrix} Y_1 \\ ... \\ Y_n \\ \end{pmatrix} = \sum_{k=1}^n U_kY_k Y=AZ=UTZZ=UY=(u1...un)∗ Y1...Yn =k=1∑nUkYk
这个展开非常有特点。把Z展开为多个向量的线性组合。
这个展开中Yk在随机变量的内积角度是正交的,而Uk是标准正交基,在欧式空间上是正交的。
{ U k } Orthonongal U i T U j = 0 ( i = j ) { Y k } Orthonongal E ( Y i Y j ) = 0 ( i = j ) \{U_k \} \text{ Orthonongal }\quad U_i^TU_j = 0 \quad(i \cancel = j) \\ \{ Y_k\} \text{ Orthonongal }\quad E(Y_iY_j) = 0 \quad (i \cancel = j) {Uk} Orthonongal UiTUj=0(i= j){Yk} Orthonongal E(YiYj)=0(i= j)
这是一种双正交展开
Bi-Orthogonal
⇒
Karhunan-Loeve Expansion
\text{Bi-Orthogonal} \Rightarrow \text{Karhunan-Loeve Expansion}
Bi-Orthogonal⇒Karhunan-Loeve Expansion
使用KL展开的时候,并不要求随机过程具有宽平稳的特性
2.3.2 随机过程的KL展开
KL展开也可以推广到连续时间的随机过程上去
Mercer Theorem Z ( t ) = ∑ k = − ∞ + ∞ α k ϕ k ( t ) \text{Mercer Theorem} Z(t) = \sum_{k=-\infty}^{+\infty} \alpha_k \phi_k(t) Mercer TheoremZ(t)=k=−∞∑+∞αkϕk(t)
其中φk在函数空间内积为0,α是随机变量,在随机变量空间上内积为0
∫ I ϕ i ( t ) ϕ j ( t ) d t = 0 E ( α i α j ) = 0 ( i = j ) \int_I \phi_i(t) \phi_j(t)dt = 0 \\ E(\alpha_i \alpha_j) = 0(i \cancel=j) ∫Iϕi(t)ϕj(t)dt=0E(αiαj)=0(i= j)
φ是相关函数的特征函数
∫ I R z ( t , s ) ϕ k ( s ) d s = λ k ϕ k ( t ) \int_I R_z(t,s) \phi_k(s)ds = \lambda_k \phi_k(t) ∫IRz(t,s)ϕk(s)ds=λkϕk(t)
这其实就是离散版本的累加和
∑ j R Z ( i , j ) ϕ k ( j ) = λ k ϕ k ( j ) ⇔ R Z ϕ k = λ ϕ k \sum_j R_Z(i,j) \phi_k(j) = \lambda_k \phi_k(j) \Leftrightarrow R_Z \phi_k = \lambda \phi_k j∑RZ(i,j)ϕk(j)=λkϕk(j)⇔RZϕk=λϕk
2.3.3 周期性宽平稳随机过程的KL展开
Z ( t ) = ∑ k = − ∞ + ∞ α k ϕ k ( t ) Z(t) = \sum_{k=-\infty}^{+\infty} \alpha_k \phi_k(t) Z(t)=k=−∞∑+∞αkϕk(t)
刚才我们介绍的KL展开,都是没有要求宽平稳条件的。如果我们加入宽平稳的条件会怎么样呢?
有了宽平稳的条件之后,特征函数其实就是复指函数。
∫ I R Z ( t − s ) ϕ k ( s ) d s = λ k ϕ k ( t ) ϕ k ( t ) = e x p ( j ω k t ) \int_I R_Z(t-s) \phi_k(s)ds = \lambda_k \phi_k(t) \\ \phi_k(t) = exp(j\omega_k t) ∫IRZ(t−s)ϕk(s)ds=λkϕk(t)ϕk(t)=exp(jωkt)
我们来验证一下
∫ I R Z ( t − s ) e x p ( j ω k s ) d s \int_I R_Z(t-s) exp(j\omega_ks)ds ∫IRZ(t−s)exp(jωks)ds
换元
$$
\text{Let s’ = t-s} \
\int_{I’} R_Z(s’) exp(-j\omega_ks’)ds’ exp(j\omega_kt)
$$
但是这样积分区间会变动,我们现在增加一个均方周期性的条件,让相关函数变成周期性的
E ∣ Z ( t + T ) − Z ( t ) ∣ 2 = 0 ⇒ R Z ( t + T ) = R Z ( t ) E|Z(t+T)- Z(t)|^2 = 0 \Rightarrow R_Z(t + T) = R_Z(t) E∣Z(t+T)−Z(t)∣2=0⇒RZ(t+T)=RZ(t)
我们再来做上面的展开,在一个周期中展开
∫
−
T
2
+
T
2
R
Z
(
t
−
s
)
e
x
p
(
j
ω
k
s
)
d
s
\int_{-\frac{T}{2}}^{+\frac{T}{2}} R_Z(t-s) exp(j\omega_ks)ds
∫−2T+2TRZ(t−s)exp(jωks)ds
换元,由于有周期性,就可以把积分区间中的值给消掉了
Let s’ = t-s ∫ − T 2 + T 2 R Z ( s ′ ) e x p ( − j ω k s ′ ) d s ′ e x p ( j ω k t ) = λ k e x p ( j ω k t ) \text{Let s' = t-s} \\ \int_{-\frac{T}{2}}^{+\frac{T}{2}} R_Z(s') exp(-j\omega_ks')ds' exp(j\omega_kt) = \lambda_k exp(j\omega_k t) Let s’ = t-s∫−2T+2TRZ(s′)exp(−jωks′)ds′exp(jωkt)=λkexp(jωkt)
确实能够得到一个常数乘以特征函数的形式。因此,复指函数就是这个方程的特征函数。
因此,我们可以得到周期性随机过程的KL展开
Fourier ⇔ Karhunan-Loeve Z ( t ) = ∑ k α k e x p ( j 2 k π T t ) α k = 1 T ∫ − T 2 + T 2 Z ( t ) e x p ( − j 2 k π T t ) d t \text{Fourier} \Leftrightarrow \text{Karhunan-Loeve} \\ Z(t) = \sum_k \alpha_k exp(j\frac{2k \pi}{T}t)\\ \alpha_k = \frac{1}{T} \int_{-\frac{T}{2}}^{+\frac{T}{2}} Z(t) exp(-j\frac{2k\pi}{T}t)dt Fourier⇔Karhunan-LoeveZ(t)=k∑αkexp(jT2kπt)αk=T1∫−2T+2TZ(t)exp(−jT2kπt)dt
我们发现,当随机过程具有宽平稳性质和周期性质之后,KL展开和傅里叶展开就是一回事
2.3.4 非周期性宽平稳随机过程的KL展开–谱表示
α k = 1 T ∫ − T 2 + T 2 Z ( t ) e x p ( − j 2 k π T t ) d t \alpha_k = \frac{1}{T} \int_{-\frac{T}{2}}^{+\frac{T}{2}} Z(t) exp(-j\frac{2k\pi}{T}t)dt αk=T1∫−2T+2TZ(t)exp(−jT2kπt)dt
下面我们想令T趋于无穷大。因为本来α是展开的系数,一旦令T趋于无穷大,因为Z是不满足绝对可积的,所以得到的积分是发散的,也就没有办法得到连续的式子。
如果我们能够得到连续的积分
Z ( t ) = ∫ − ∞ + ∞ Z ^ ( ω ) e x p ( j ω t ) d ω Z(t) = \int_{-\infty}^{+\infty} \hat{Z} (\omega) exp(j\omega t) d\omega Z(t)=∫−∞+∞Z^(ω)exp(jωt)dω
这个积分会有奇点,因此,我们才会使用了二阶量的功率谱,来描述频域和时域的关系。
我们可以换一种方法来对付奇点,就是用stieltjes积分表示,奇点就不微分了,保留着即可。这样逻辑就是完全正确的了
Stieltjes Integration ∫ f ( x ) d g ( x ) \text{Stieltjes Integration} \\ \int f(x) dg(x) Stieltjes Integration∫f(x)dg(x)
Z ( t ) = ∫ − ∞ + ∞ e x p ( j ω t ) d F Z ( ω ) Z(t) = \int_{-\infty}^{+\infty} exp(j\omega t) dF_Z(\omega) Z(t)=∫−∞+∞exp(jωt)dFZ(ω)
我们就得到了KL展开在连续时间上的具体形式
因为KL展开是双正交的,所以谱表示是正交的。因此谱过程是个正交增量过程
E ( ( d F Z ( ω 1 ) ) ( d F Z ( ω 2 ) ‾ ) ) = 0 E((dF_Z(\omega_1))( \overline{dF_Z(\omega_2)})) = 0 E((dFZ(ω1))(dFZ(ω2)))=0


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









