







首先解释一下我们的MOSS版本,目前开源的版本我们称为MOSS 003,二月份公开邀请内测的版本为MOSS 002,一月份我们还有一个内部测试版本叫做OpenChat 001,这里正好简单介绍一下我们的历次迭代过程。
OpenChat 001
在去年ChatGPT问世后,国内NLP从业者受到冲击很大,当时没有llama也没有alpaca,大家普遍认为我们距离ChatGPT有一到两年的技术差距。而要做ChatGPT有两个部分是很昂贵的,一个是数据标注,一个是预训练算力。我们没有算力,但是可以想办法构造一些数据来试试看,毕竟AI都强大到能替代这么多人的工作了,没理由认为它替代不了标注人员的工作。于是我们当时从OpenAI的论文附录里扒了一些它们API收集到的user prompt,然后用类似Self-Instruct的思路用text-davinci-003去扩展出大约40万对话数据。没错,跟今天的alpaca类似,而且我们当时还是多轮对话而不是单轮指令。之后在16B基座(CodeGen)上做了一下fine-tune,发现似乎稍微大点的模型很容易学到指令遵循能力,下面是当时的一些示例。

OpenChat 001 指令遵循能力

OpenChat 001 多轮对话能力
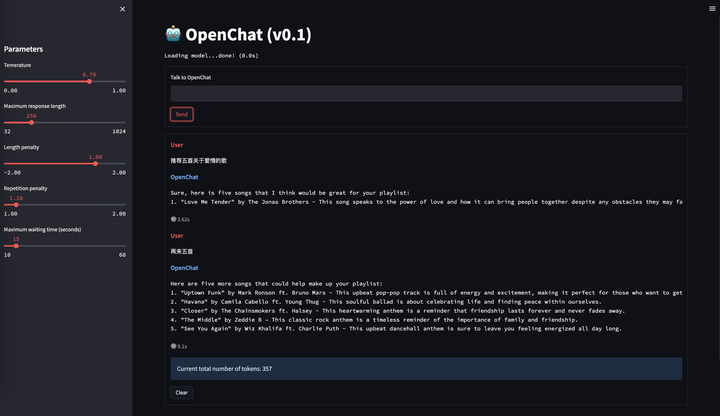
OpenChat 001 跨语言对齐能力
从上面的例子可以看到,一月份的OpenChat 001就已经具备了指令遵循能力和多轮能力,而且我们还惊喜的发现它具有很强的跨语言对齐能力,它的基座预训练语料中几乎不存在中文,但是却可以理解中文并用英文回答。这在当时给了我们很大信心。
后来流浪地球2上映,加上我们发现OpenChat这个名字已经被人用过了,于是改名为MOSS。
MOSS 002
OpenChat 001不具备中文能力,不知道关于自己的信息(比如名字、能力等)&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 5206
5206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











