






来自:包包算法笔记
在前文我们提到过,大模型训练中数据的多样性和质量是最重要的两个维度,并且在结尾挖了一个大坑,希望有大佬愿意研究多样性的scaling laws。
这次,复旦MOSS团队带着数据配比scaling laws就来了。

题目:Data Mixing Laws: Optimizing Data Mixture by Predicting Language Modeling Performance
地址:https://arxiv.org/abs/2403.16952
代码:https://github.com/yegcjs/mixinglaws现有关于多样性的研究,通常依赖于启发式或定性策略来调整混合比例,缺乏对模型性能与数据混合比例关系的定量理解。
这篇文章旨在探索模型性能与数据混合比例之间的定量可预测性,并提出一种方法来优化数据混合比例,以提升预训练模型的效率和性能。
说白了,就是量化多样性和loss的关系,通过在小规模数据集上拟合这多样性和loss的关系,通过小实验来推演大实验,可以在实际训练之前预测不同混合比例下模型的性能。
实验结果表明,该方法能够有效地优化RedPajama数据集上1B模型的训练混合比例,使其在100B个token的训练中达到与默认混合比例训练多训48%step的性能。
此外,该方法还成功应用于持续预训练,准确预测了避免灾难性遗忘的关键混合比例,并展现了“动态数据调度”的潜力。
下面让我们来看看作者具体咋做的。
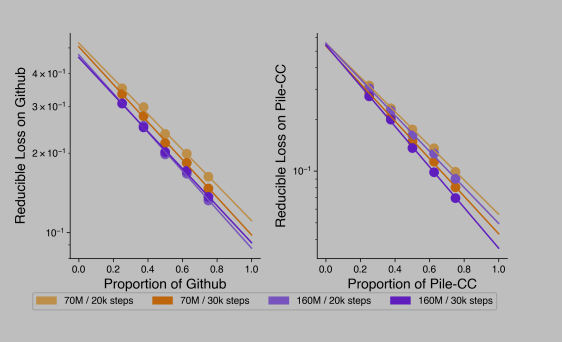
作者先把问题简化,在两个不同领域数据混合情况下开始研究。探索当训练数据集仅由两个领域的数据组成时,这些数据的混合比例如何影响模型在特定领域上的损失。
基于这些观察结果,作者提出了一个初步的预测模型,该模型能够根据数据混合比例来预测模型在特定领域上的损失。
通过这个研究,能够更好地理解和预测不同数据混合比例对模型性能的影响,这对于优化模型训练和提高其在各种任务上的表现具有重要意义。
最重要的是得到了这么一个函数可以拟合两个数据集的不同比例和loss:
对应图为:
作者后面将研究从两个领域混合的情况扩展到更普遍的多领域混合数据的情况。
目的是探索和理解当训练数据包含多个领域时,这些领域的混合比例如何影响模型在各个领域上的损失。与两个领域混合的情况相比,多领域混合数据增加了问题的复杂性。在多领域混合的情况下,需要考虑更多的变量和它们之间的相互作用,这使得确定数据混合比例与损失之间关系的函数形式变得更加困难。为了适应多领域混合的情况,作者设计了新的实验,这些实验涉及在包含三个不同领域的数据混合上训练模型。这三个领域可以是GitHub、Pile-CC和Books3等,它们是Pile数据集的子集。作者基于两个原则(兼容性和对称性)提出了几种可能的函数形式,这些函数能够描述多领域混合数据中损失与混合比例之间的关系。
通过实验验证,作者确定了最合适的函数形式,这个函数是:
我们回头看看这个函数,其实相当于一个单层的神经网络,用了exp激活函数,然后进行了线性变换。
用图来表达这个网络结构就是:
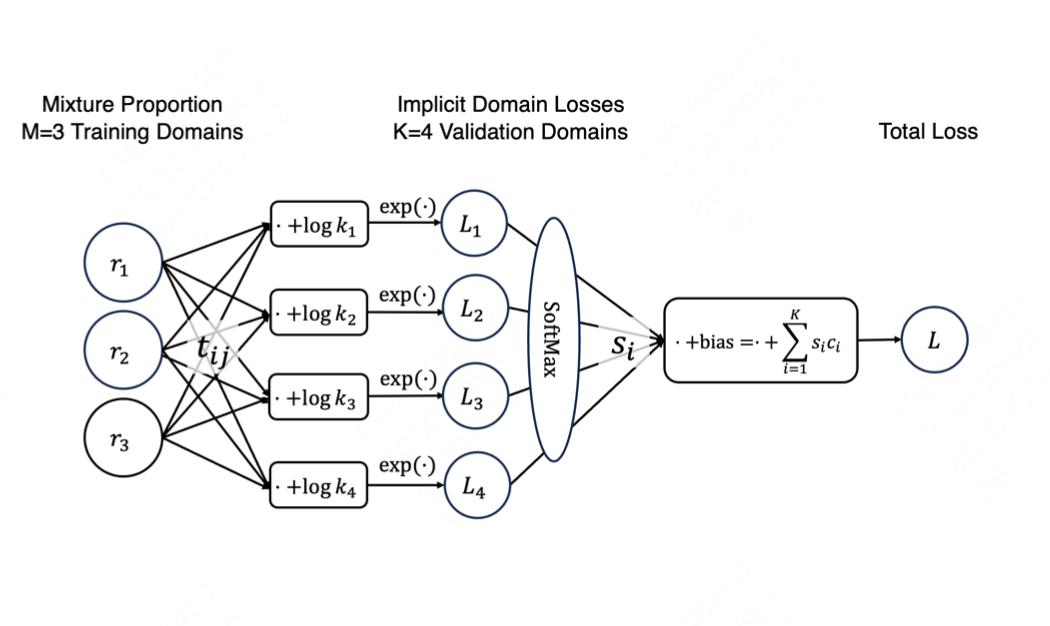
这么做的道理,个人理解是比例变得极端时候,loss会爆涨,所以exp激活会拟合的比较好。
然后需要预测总loss的时候,加一个自动学习的求和函数。
混合多种领域的实验结果如下:
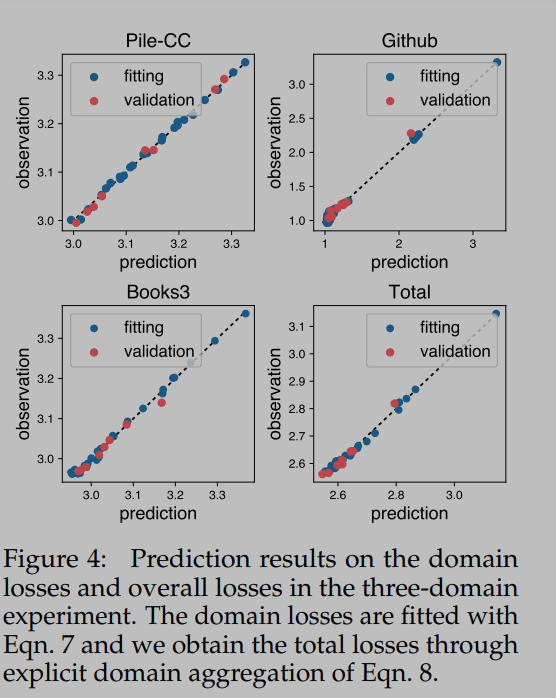
作者是实证分析得出来的网络架构,然后非线性不是很高,符合混合比例与最终结果的不复杂关系建模的设定。
当把模型大小和训练step,多样性结合到一起的时候,可以这么做scalinglaw。
 翻译算法
翻译算法
遍历不同的比例,(例如,1:2:3、3:2:1、等等)
遍历不同的模型大小,(例如,70M、160M、305M和410M)
1.拟合训练步数scalinglaw:使用从小规模模型获得的数据,研究者拟合一个关于训练步数的缩放法则。这个法则能够预测在更多训练步数下模型的损失。
2.拟合模型大小的scalinglaw:同样,研究者使用实验数据来拟合一个关于模型大小的缩放法则。这个法则可以预测在更大模型大小下模型的损失。
3.拟合混合比例的scalinglaw:结合训练步数法则和模型大小法则,研究者可以预测在目标模型大小(例如,1B模型)和目标训练步数(例如,100B个token)下,不同数据混合比例的损失。过程和这个图示一致:
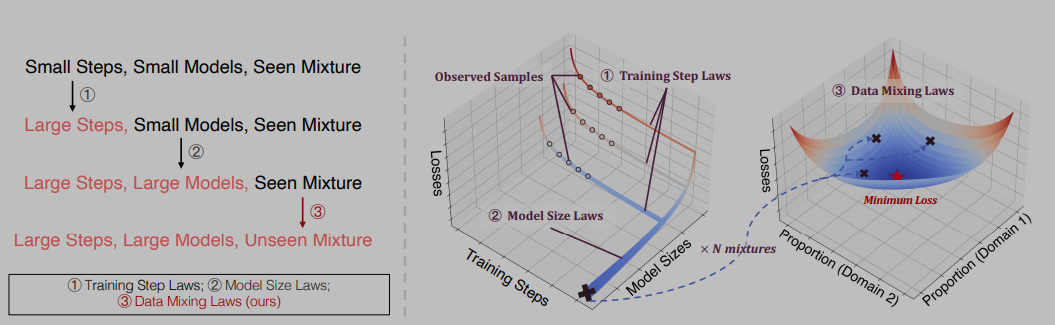
另外这个方法可以用于规避灾遗忘问题:
避免灾难遗忘问题最常用的方法就是用一定的原始同分布数据混合新数据进行继续预训练,在继续预训练中,数据调度是指如何安排和组织不同类型和领域的数据,以便在训练过程中有效地传递给模型。一个好的数据调度计划可以帮助模型更好地学习和适应新的知识,同时保持对旧知识的记忆力。
作者提出了将数据混合法则应用于继续预训练的想法。通过预测不同数据混合比例对模型性能的影响,可以创建一个动态的数据调度计划,这个计划能够在训练过程中根据模型的需要调整数据的混合比例。
通过应用数据混合法则,可以找到最佳的域数据混合比例,以维持模型在原始领域上的性能,同时学习新的知识。
作者设计了这样的实验,用的 Pile and python code 混合数据,使用Pythia-70M基座继续预训练,预测混合后的loss,并实验画出了训练曲线。用论文中提到的方法,准确地找到了维持原始领域模型性能的关键混合比例,让训练后的基座还有python的能力,并且有pile的能力。
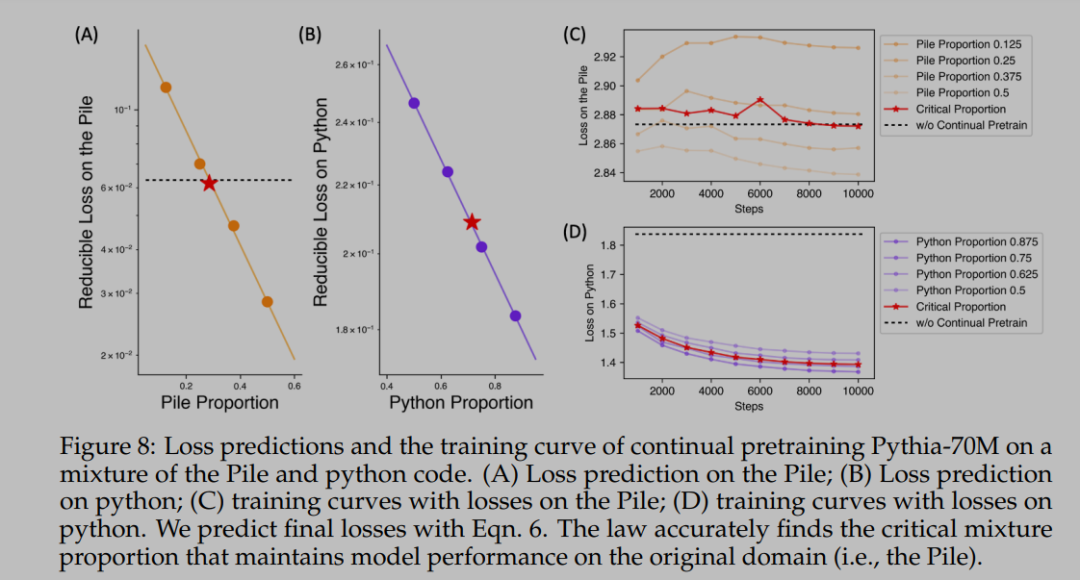
整体看起来,作者给了很强的假设,与大多数缩放法则一样,是基于经验的发现,做实验反推。另外,用学习参数的方法来拟合scalinglaw,有非常强的先验假设,用什么样的结构,模型,激活函数等等都有待商榷。
作者也说了,这个工作开启了对预训练数据策划的定量预测方法的研究。随着对数据工程的关注度日益提高,我们希望我们的探索能够促进这一研究领域的进一步定量研究和理论分析。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 250
250

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









