







 通过对汽车数据进行聚类分析,找到了vokswagen汽车的竞品,并详细分析了‘vokswagenrabbit’与其他竞品间的差异。
通过对汽车数据进行聚类分析,找到了vokswagen汽车的竞品,并详细分析了‘vokswagenrabbit’与其他竞品间的差异。
赛题背景
赛题以竞品分析为背景,通过数据的聚类,为汽车提供聚类分类。对于指定的车型,可以通过聚类分析找到其竞品车型。通过这道赛题,鼓励学习者利用车型数据,进行车型画像的分析,为产品的定位,竞品分析提供数据决策。
赛题数据
数据源:car_price.csv,数据包括了205款车的26个字段
https://tianchi.aliyun.com/competition/entrance/531892/information
赛题任务
选手需要对该汽车数据进行聚类分析,并找到vokswagen汽车的相应竞品。要求选手在天池实验室中用notebook完成以上任务,并分享到比赛论坛。(聚类分析是常用的数据分析方法之一,不仅可以帮助我们对用户进行分组,还可以帮我们对产品进行分组(比如竞品分析) 这里的聚类个数选手可以根据数据集的特点自己指定,并说明聚类的依据)
一、数据探索
-
了解数据类型及基本情况
-
数据质量检查:主要包括检查数据中是否有错误,如拼写有误等
-
对空值、重复值、异常值等检测
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#高清显示图片
%matplotlib inline
%config InlineBackend.figure_format="retina"
#保证可以显示中文字体
plt.rcParams['font.sans-serif']=['SimHei']
#正常显示负号
plt.rcParams['axes.unicode_minus']=False
#获取数据
car_price=pd.read_csv('./car_price.csv')
car_price.head()

#查看数据类型和非空、重复值
car_price.info()
car_price.duplicated().sum()
数据集中共205行记录,26个字段;没有空值,重复数据为0。
其中,数据类型dtypes: float64(8), int64(8), object(10);
数据特征具体可区分为3大类:
第一类:汽车ID类属性
1 Car_ID 车号
3 CarName 车名
第二类:类别型变量(10个)
2 Symboling 保险风险评级
4 fueltype 燃料类型
5 aspiration 发动机吸气形式
6 doornumber 车门数
7 carbody 车身型式
8 drivewheel 驱动轮
9 enginelocation 发动机位置
15 enginetype 发动机型号
16 cylindernumber 气缸数
18 fuelsystem 燃油系统
第三类:连续数值型变量(14个)
10 wheelbase 轴距
11 carlength 车长
12 carwidth 车宽
13 carheight 车高
14 curbweight 整备质量(汽车净重)
17 enginesize 发动机尺寸
19 boreratio 气缸横截面面积与冲程比
20 stroke 发动机冲程
21 compressionratio 压缩比
22 horsepower 马力
23 peakrpm 最大功率转速
24 citympg 城市里程(每加仑英里数)
25 highwaympg 高速公路里程(每加仑英里数)
26 price(Dependent variable) 价格(因变量)
1.2 检查变量特征取值情况
1.2.1 检查类别型变量
查看类别属性特征分类取值情况(并检查信息拼写错误等)
# 提取类别变量的列名
cate_columns=['symboling','fueltype','aspiration','doornumber','carbody','drivewheel','enginelocation','enginetype','fuelsystem','cylindernumber']
#打印类别变量每个分类的取值情况
for i in cate_columns:
print(i)
print(set(car_price[i]))
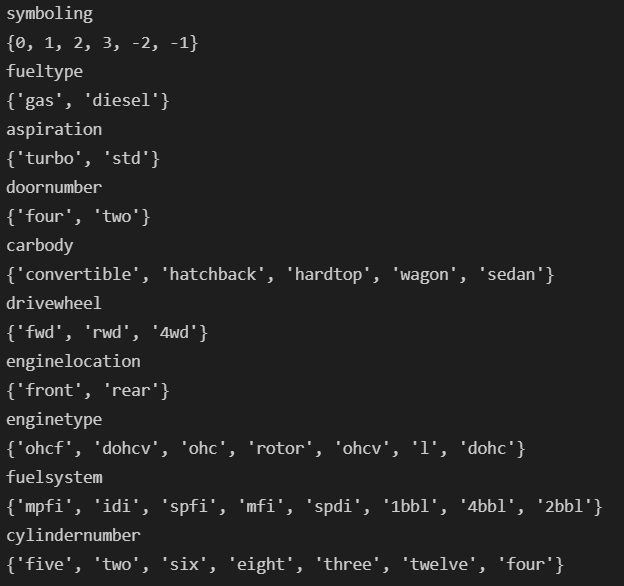
由上面可检查类别型特征数据是否有拼写错误,还可知道特征的具体分类情况;
分类取值具有大小意义的,如:
①保险风险评级Symboling的取值范围为:0、 1、2、3、-2、-1,虽是分类特征但其取值是有大小意义的;
②气缸数cylindernumber取值:{‘three’, ‘six’, ‘eight’, ‘five’, ‘four’, ‘twelve’, ‘two’},这7个取值也是有大小意义的,在同等缸径下,缸数越多,排量越大,功率越高;在同等排量下,缸数越多,缸径越小,转速可以提高,从而获得较大的提升功率;
其他分类取值没有大小意义的,如:
车门数doornumber分’two’、 'four’两类,因车门数是跟车外形设计有关,如公务用途的轿车为四门,而运动用途跑车为两门,完全是不同类型的车型,其取值没有大小意义,只是分类;
fueltype 燃料类型分’gas’和’diesel’两类,等等只是类别上属性的分类。
可看到有很多命名是不规则的,需要修正。如:‘toyouta’, ‘maxda’, ‘porcshce’,‘Nissan’, ‘vw’,‘vokswagen’.
#气缸数可使用具体的数值替换分类
car_price['cylindernumber']=car_price.cylindernumber.replace({'two':2,'three':3,'four':4,'five':5,'six':6,'eight':8,'twelve':12})
1.2.2 检查数值型变量
查看数值型变量取值情况,并检查是否有异常值
#提取变量特征数据(除了'car_ID'和'CarName')
car_df=car_price.drop(['car_ID','CarName'],axis=1)
#查看连续数值型情况,并是检查否有异常值
#对数据进行描述性统计
car_df.describe()

从上面数据看,数据集不存在违背常理的异常值
#还可以描绘数据集的箱线图,查看异常值
#提取连续数值型数据的列名
num_cols=car_df.columns.drop(cate_columns)
print(num_cols)
#绘制连续数值型数据的箱线图,检查异常值
import seaborn as sns
fig=plt.figure(figsize=(12,8))
i=1
for col in num_cols:
ax=fig.add_subplot(3,5,i)
sns.boxplot(data=car_df[col],ax=ax)
i=i+1
plt.title(col)
plt.subplots_adjust(wspace=0.4,hspace=0.3)
plt.show()

由各特征的箱线图可知,部分特征存在离群点,但不存在特别明显的离群点,可接受。
#去重查看CarName
print(car_price['CarName'].drop_duplicates())#验证是否object全部改为数值类型
1.3 检查特征数据之间的逻辑关系
分析特征之间是否存在逻辑关系,是否可以进行数据特征融合或拆分等等。
1.3.1 由carName拆分品牌信息
由CarName数据组成信息,第一个英文为其车型的品牌
#利用split,由CarName拆出品牌信息
carBrand=car_price['CarName'].str.split(expand=True)[0]
#查看汽车品牌名称(过滤重复)
print(set(carBrand))
由CarName的信息可看出:
1、去重后的CarName有147个记录,说明有重复命名的车名,不是唯一值;
2、可由CarName的组成信息,第一个英文为其品牌,可以split出汽车的品牌
3、CarName部分命名不规则,有错误,如:Nissan,maxda,;(但考虑到赛题中任务为‘找到vokswagen汽车的相应竞品’,不确定其中的‘vokswagen’是故意特指id为183的CarName中‘vokswagen rabbit’,还是大众volkswagen 的错误拼写,所以不修改CarName中的错误,只在导出的品牌名中修改)
#修改品牌名称的不规则命名
carBrand=carBrand.replace({'porcshce':'porsche','vokswagen':'volkswagen','Nissan':'nissan','maxda':'mazda','vw':'volkswagen','toyouta':'toyota'})
print(set(carBrand))
#将carBrand放入原数据集中
car_price['carBrand']=carBrand
1.3.2 根据车长划分车型大小
在汽车销售等实际业务中,很多消费者购买需求有时会根据考虑车型的大小来考虑。
欧系分类,按德国标准,车型大小可按照车长,轴距划分为6类:
1、微型车(A00):车长小于3.7M;轴距小于:2.35M;
2、小型车(A0):车长小于4.3M;轴距小于:2.5M;
3、紧凑型车(A):车长小于4.6M;轴距小于:2.7M;
4、中型车(B):车长小于4.9M;轴距小于:2.8M;
5、中大型车(C):车长小于5.1M;轴距小于:2.9M;
6、豪华车(D):车长大于5.1M;轴距大于:2.9M。
而要注意,数据集中车长宽高和轴距单位均为英寸,需要进行单位的转换:1英寸=0.0254米。
按车身长度分类界限:微型车: A00 <145.67 ;小型车: A0 <169.29 ;紧凑型车:A <181.10 ;中型车: B <192.91 ;中大型车:C <200.79 ;大型车: D >200.79
# 由上面描述性统计可知,车身长范围为141.1~208.1英寸之间,可划分为6类
bins=[min(car_df.carlength)-0.01,145.67,169.29,181.10,192.91,200.79,max(car_df.carlength)+0.01]
label=['A00','A0','A','B','C','D']
carSize=pd.cut(car_df.carlength,bins,labels=label)
print(carSize)
#将车型大小分类放入数据集中
car_price['carSize']=carSize
car_df['carSize']=carSize
车型大小分类,为Categories (6, object): [‘A00’ < ‘A0’ < ‘A’ < ‘B’ < ‘C’ < ‘D’],其取值有大小的意义
当有车型大小分类后,选择特征聚类时,车身的长和宽可剔除,而在同类车型中车高和轴距则可当为车身空间舒适性度量来分析
#查看数值型特征的相关系数
df_corr=car_df.corr()
df_corr
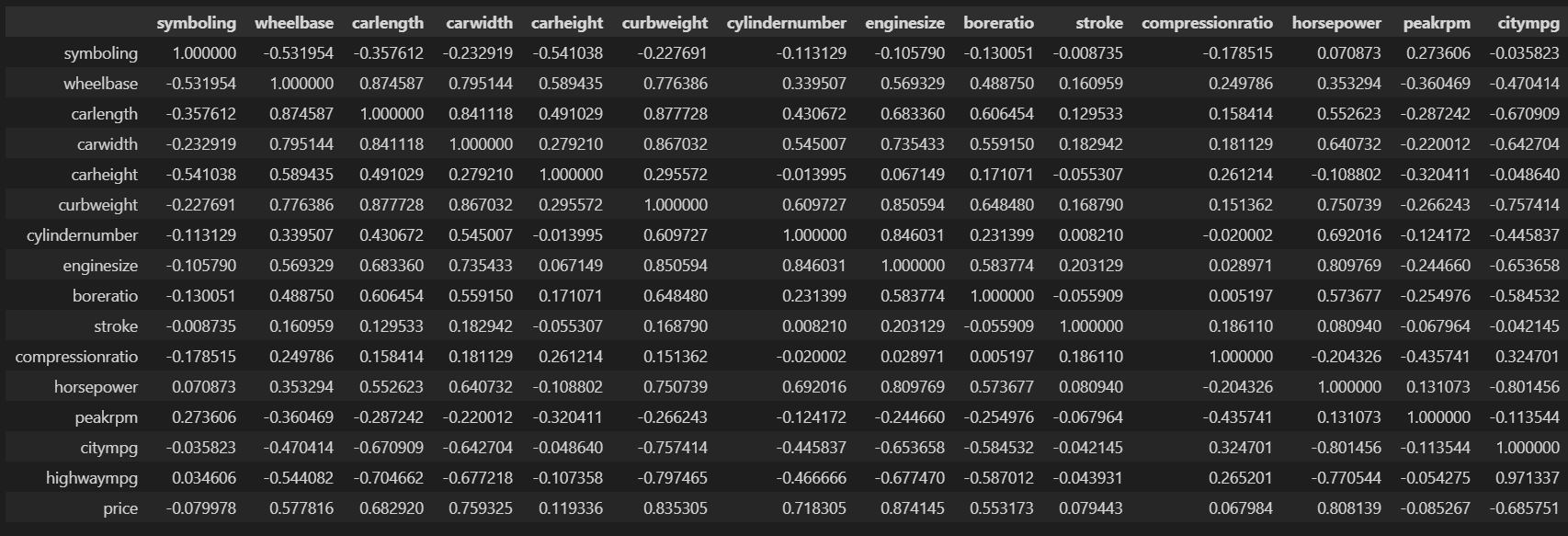
#绘制相关性热力图
mask=np.zeros_like(df_corr)
mask[np.triu_indices_from(mask)]=True
plt.figure(figsize=(10,10))
with sns.axes_style("white"):
ax=sns.heatmap(df_corr,mask=mask,square=True,annot=True,cmap='bwr')
ax.set_title("df_corr Variables Relation")
plt.show()

相关系数分类: 0.8-1.0 极强相关;0.6-0.8 强相关;0.4-0.6 中等程度相关;0.2-0.4 弱相关;0.0-0.2 极弱相关或无相关
由上面热力图可看出: 车长、宽、轴距三者都极强相关,整备质量和车长、宽、发动机尺寸极强相关,价格与车整备质量、发动机尺寸、马力具有极强相关性,等等。部分数据之间存在高度相似,数据存在冗余。
二、数据预处理
2.1 筛选合适的变量特征
carSize可代表车型大小,剔除carlength
#剔除carlength
features=car_df.drop(['carlength'],axis=1)
2.2 对类别型变量进行数值映射和one-hot编码
# 将取值具有大小意义的类别型变量数据转变为数值型映射
features1=features.copy()
#使用LabelEncoder对不具实体数值数据编码
from sklearn.preprocessing import LabelEncoder
carSize1=LabelEncoder().fit_transform(features1['carSize'])
features1['carSize']=carSize1
#对于类别离散型特征,取值间没有大小意义的,可采用one-hot编码
cate=features1.select_dtypes(include='object').columns
print(cate)
features1=features1.join(pd.get_dummies(features1[cate])).drop(cate,axis=1)
features1.head()

对数值型数据进行one-hot编码后,数据变量由原来24列变为47列,维度变大。
2.3 对数值型变量标准化
数据变量之间存在量级的差异,需要进行数据标准化
#对数值型数据进行归一化
from sklearn import preprocessing
features1=preprocessing.MinMaxScaler().fit_transform(features1)
features1=pd.DataFrame(features1)
features1.head()

2.4 利用PCA对高维数据进行降维
目的:在‘信息’损失较小的前提下,将高维数据转换到低维,从而减少计算量。把可能具有线性相关的高维变量合成线性无关的低维变量,成为主成分。保留最大的方差方向,使从变换特征回到原始特征的误差最小。
#对数据集进行PCA降维(信息保留为99.99%)
from sklearn.decomposition import PCA
pca=PCA(n_components=0.9999) #保证降维后的数据保持90%的信息,则填0.9
features2=pca.fit_transform(features1)
#降维后,每个主要成分的解释方差占比(解释PC携带的信息多少)
ratio=pca.explained_variance_ratio_
print('各主成分的解释方差占比:',ratio)
#降维后有几个成分
print('降维后有几个成分:',len(ratio))
#累计解释方差占比
cum_ratio=np.cumsum(ratio)
print('累计解释方差占比:',cum_ratio)
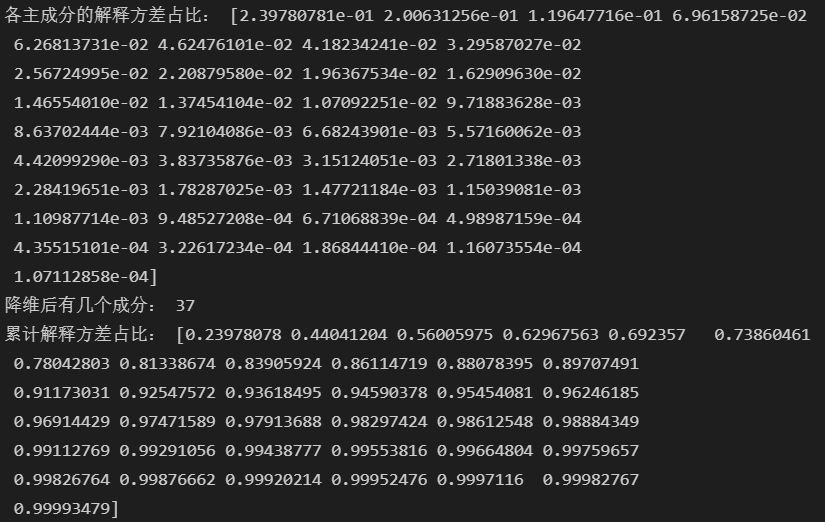
#绘制PCA降维后各成分方差占比的直方图和累计方差占比折线图
plt.figure(figsize=(8,6))
X=range(1,len(ratio)+1)
Y=ratio
plt.bar(X,Y,edgecolor='black')
plt.plot(X,Y,'r.-')
plt.plot(X,cum_ratio,'b.-')
plt.ylabel('explained_variance_ratio')
plt.xlabel('PCA')
plt.show()

蓝色折线为累计方差占比。 降维后,选择几个维度表示原数据集的特征更合适: 一般会根据帕累托的二八原则,选择累计解释方差大于80%的前几个成分。根据蓝色折线图各成分的累计方差占比看出,当选取保留8个主要成分时,累计解释方差大于80%。
#PCA选择降维保留7个主要成分
pca=PCA(n_components=8)
features3=pca.fit_transform(features1)
#降维后的累计各成分方差占比和(即解释PC携带的信息多少)
print(sum(pca.explained_variance_ratio_))
降维后,解释PC有效信息保留约81%。
三、K-Means聚类模型应用
3.1 利用肘方法确定簇的最佳数量
K-Means没有确定k值,可以通过肘部法来估计聚类数量
手肘法的核心指标是SSE(sum of the squared errors,误差平方和)
随着聚类数k的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,那么误差平方和SSE自然会逐渐变小。并且,当k小于真实聚类数时,由于k的增大会大幅增加每个簇的聚合程度,故SSE的下降幅度会很大,而当k到达真实聚类数时,再增加k所得到的聚合程度回报会迅速变小,所以SSE的下降幅度会骤减,然后随着k值的继续增大而趋于平缓,也就是说SSE和k的关系图是一个手肘的形状。(下降率突然变缓时即认为是最佳的k值)
##肘方法看k值,簇内离差平方和
#对每一个k值进行聚类并且记下对于的SSE,然后画出k和SSE的关系图
from sklearn.cluster import KMeans
sse=[]
for i in range(1,15):
km=KMeans(n_clusters=i,init='k-means++',n_init=10,max_iter=300,random_state=0)
km.fit(features3)
sse.append(km.inertia_)
plt.plot(range(1,15),sse,marker='*')
plt.xlabel('n_clusters')
plt.ylabel('distortions')
plt.title("The Elbow Method")
plt.show()

由上面肘方图可以看到,拐点在k=5处,所以k的取值为5.
3.2 应用K-Means聚类模型
#进行K-Means聚类分析
kmeans=KMeans(n_clusters=5,init='k-means++',n_init=10,max_iter=300,random_state=0)
kmeans.fit(features3)
lab=kmeans.predict(features3)
print(lab)
3.3 对聚类效果评估
3.3.1 查看聚类后的效果
通过绘制聚类后结果的散点图,查看每簇间距离效果
#绘制聚类结果2维的散点图
plt.figure(figsize=(8,8))
plt.scatter(features3[:,0],features3[:,1],c=lab)
for ii in np.arange(205):
plt.text(features3[ii,0],features3[ii,1],s=car_price.car_ID[ii])
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.title('K-Means PCA')
plt.show()

上面以占比最大的前2个主成分画出的二维散点图,发现右下蓝色这簇部分聚类点距离很远,效果似乎不是很好;而其他四簇效果还好。 考虑到保留的主成分为8个,且前两个主成分累计可解释方差占比仅约为44%,损失信息较多,所以尝试利用前3个主成分画3d效果图再查看。
#绘制聚类结果后3d散点图
from mpl_toolkits.mplot3d import Axes3D
plt.figure(figsize=(8,8))
ax=plt.subplot(111,projection='3d')
ax.scatter(features3[:,0],features3[:,1],features3[:,2],c=lab)
#视角转换,转换后更易看出簇群
ax.view_init(30,45)
ax.set_xlabel('PC1')
ax.set_ylabel('PC2')
ax.set_zlabel('PC3')
plt.show()
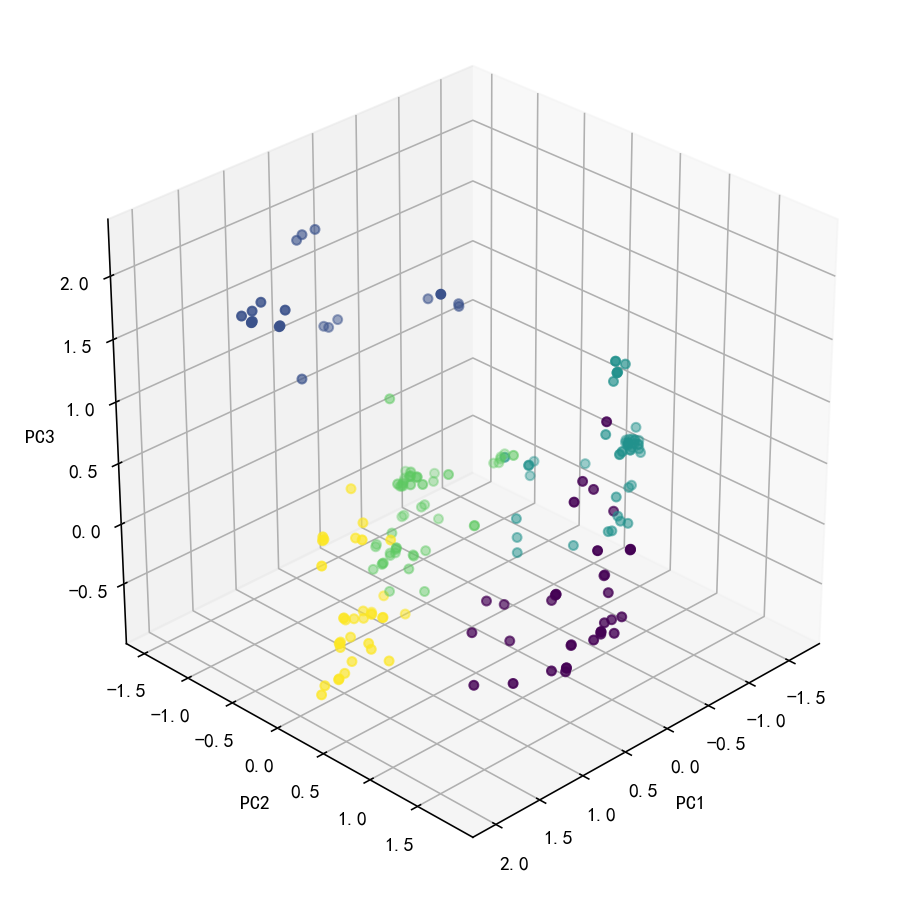
3d散点图看,聚类各簇的效果还好
3.3.2 利用轮廓系数评估聚类效果
肘图选择k值是比较直观但较为粗糙的方法。使用轮廓分数,即所有实例的平均轮廓系数来选择k值更为精确。该方法的核心指标是轮廓系数(Silhouette Coefficient),求出所有样本的轮廓系数后再求平均值就得到了平均轮廓系数。
平均轮廓系数的取值范围为[-1,1]:接近+1点系数表示该实例很好地位于自身的集群中,并且远离其他集群;而接近0点系数表示该实例接近一个集群的边界;接近-1点系数,意味着该实例已分配给错误的集群。
簇内样本的距离越近,簇间样本距离越远,平均轮廓系数越大,聚类效果越好。
#绘制轮廓图和3d散点图
from sklearn.datasets import make_blobs
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.cm as cm
from mpl_toolkits.mplot3d import Axes3D
for n_clusters in range(2,9):
fig=plt.figure(figsize=(12,6))
ax1=fig.add_subplot(121)
ax2=fig.add_subplot(122,projection='3d')
ax1.set_xlim([-0.1,1])
ax1.set_ylim([0,len(features3)+(n_clusters+1)*10])
km=KMeans(n_clusters=n_clusters,init='k-means++',n_init=10,max_iter=300,random_state=0)
y_km=km.fit_predict(features3)
silhouette_avg=silhouette_score(features3,y_km)
print('n_cluster=',n_clusters,'The average silhouette_score is :',silhouette_avg)
cluster_labels=np.unique(y_km)
silhouette_vals=silhouette_samples(features3,y_km,metric='euclidean')
y_ax_lower=10
for i in range(n_clusters):
c_silhouette_vals=silhouette_vals[y_km==i]
c_silhouette_vals.sort()
cluster_i=c_silhouette_vals.shape[0]
y_ax_upper=y_ax_lower+cluster_i
color=cm.nipy_spectral(float(i)/n_clusters)
ax1.fill_betweenx(range(y_ax_lower,y_ax_upper),0,c_silhouette_vals,edgecolor='none',color=color)
ax1.text(-0.05,y_ax_lower+0.5*cluster_i,str(i))
y_ax_lower=y_ax_upper+10
ax1.set_title('The silhouette plot for the various clusters')
ax1.set_xlabel('The silhouette coefficient values')
ax1.set_ylabel('Cluster label')
ax1.axvline(x=silhouette_avg,color='red',linestyle='--')
ax1.set_yticks([])
ax1.set_xticks([-0.1,0,0.2,0.4,0.6,0.8,1.0])
colors=cm.nipy_spectral(y_km.astype(float)/n_clusters)
ax2.scatter(features3[:,0],features3[:,1],features3[:,2],marker='.',s=30,lw=0,alpha=0.7,c=colors,edgecolor='k')
centers=km.cluster_centers_
ax2.scatter(centers[:,0],centers[:,1],centers[:,2],marker='o',c='white',alpha=1,s=200,edgecolor='k')
for i,c in enumerate(centers):
ax2.scatter(c[0],c[1],c[2],marker='$%d$' % i,alpha=1,s=50,edgecolor='k')
ax2.set_title("The visualization of the clustered data.")
ax2.set_xlabel("Feature space for the 1st feature")
ax2.set_ylabel("Feature space for the 2nd feature")
ax2.view_init(30,45)
plt.suptitle(("Silhouette analysis for KMeans clustering on sample data "
"with n_clusters = %d" % n_clusters),
fontsize=14, fontweight='bold')
plt.show()

结合轮廓图和3d散点图: 当k太小时,单独的集群会合并;而当k太大时,某些集群会被分成多个。
当k=2,每个集群很大且很大部分实例系数接近0,表明集群内很大部分实例接近边界,一些单独的集群被合并了,模型效果不好;
当k=3时,集群‘0’大部分实例轮廓系数低于集群的轮廓分数,且有小部分实例系数小于0趋向-1,说明该部分实例可能已分配给错误的集群;
k=4时,集群‘0’大部分实例轮廓系数低于集群的轮廓分数且接近0,说明这些实例接近边界,该集群可能分为2个单独集群更合适;
k=7或8时,某些集群被分成多个,中心非常接近,导致非常糟糕的模型;
当k为5或6时,大多数实例都超出虚线,集群看起来很好,聚类效果都很好。按得分排k更佳是6>5,当k=5时,集群‘3’很大,k=6时,各个集群分布更均衡一些;
综上所述,k值选取5或6都可以,聚类模型效果都可以,但考虑各集群均衡些,所以选取k=6。
#调整选择k=6进行聚类
kmeans=KMeans(n_clusters=6,init='k-means++',n_init=10,max_iter=300,random_state=0)
y_pred=kmeans.fit_predict(features3)
print(y_pred)
#将聚类后的类目放入原特征数据中
car_df_km=car_price.copy()
car_df_km['km_result']=y_pred
四、聚类结果展示
4.1 聚类结果统计
#统计聚类后每个集群的车型数
car_df_km.groupby('km_result')['car_ID'].count()
#统计每个集群各个品牌的车型数
car_df_km.groupby(by=['km_result','carBrand'])['car_ID'].count()
#统计每个品牌所属各个集群的车型数
car_df_km.groupby(by=['carBrand','km_result'])['km_result'].count()
4.2 提取Volkswagen的竞品
Volkswagen对应同一个集群内的其他车型,均为其竞品
1、找出特指’vokswagen’的车型同一集群的车型
2、若’vokswagen’不为特指,而是拼写错误;那需要找出大众volkswagen品牌同一集群的其他车型(由上面的统计可知,volkswagen大众品牌所属的分类有0、1、2类,然后各分类中同一类型的车型为竞品)
#查看特指车名‘vokswagen’车型的聚类集群
df=car_df_km.loc[:,['car_ID','CarName','carBrand','km_result']]
print(df.loc[df['CarName'].str.contains("vokswagen")])
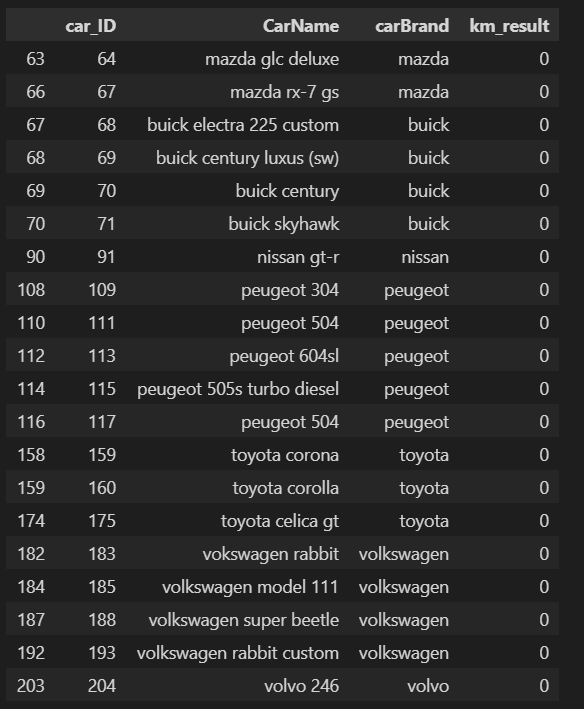
’vokswagen’的车名为‘vokswagen rabbit’,car_ID 为183,集群分类为0.
#查看特指车名为‘vokswagen’车型的竞品车型(分类0的所有车型)
df.loc[df['km_result']==0]
#查看大众volkswagen品牌各集群内的竞品车型
df_volk=df.loc[df['km_result']<3].sort_values(by=['km_result','carBrand'])
df_volk

4.3 对’vokswagen’车型的竞品分析
这里主要针对特指‘vokswagen’车型的竞品分析,若要分析‘Volkswagen’大众品牌的也可同理按每个集群进行分析
#提取分类为0的所有车型特征数据
df0=car_df_km.loc[car_df_km['km_result']==0]
df0.head()
df0_1=df0.drop(['car_ID','CarName','km_result'],axis=1)
#查看集群0的车型所有特征分布
fig=plt.figure(figsize=(20,20))
i=1
for c in df0_1.columns:
ax=fig.add_subplot(7,4,i)
if df0_1[c].dtypes=='int' or df0_1[c].dtypes=='float':
sns.histplot(df0_1[c],ax=ax)
else:
sns.barplot(df0_1[c].value_counts().index,df0_1[c].value_counts(),ax=ax)
i=i+1
plt.xlabel('')
plt.title(c)
plt.subplots_adjust(top=1.2)
plt.show()

由集群0的变量特征分布图可知,类别型变量取值只有一种的有:fueltype : {‘diesel’};enginelocation : {‘front’};fuelsystem : {‘idi’};这些共性的特征在竞品分析时可不考虑。
根据乘用车的汽车用户需求特点,一般首先会考虑车型大小级别;而乘用车的对比也是基于同等级别的车型大小进行(如,不可能拿一个D级豪华型车与A级紧凑型车来对比的)。
#对不同车型级别、品牌、车身等类型特征进行数据透视
df2=df0.pivot_table(index=['carSize','carbody','carBrand','CarName'])
df2
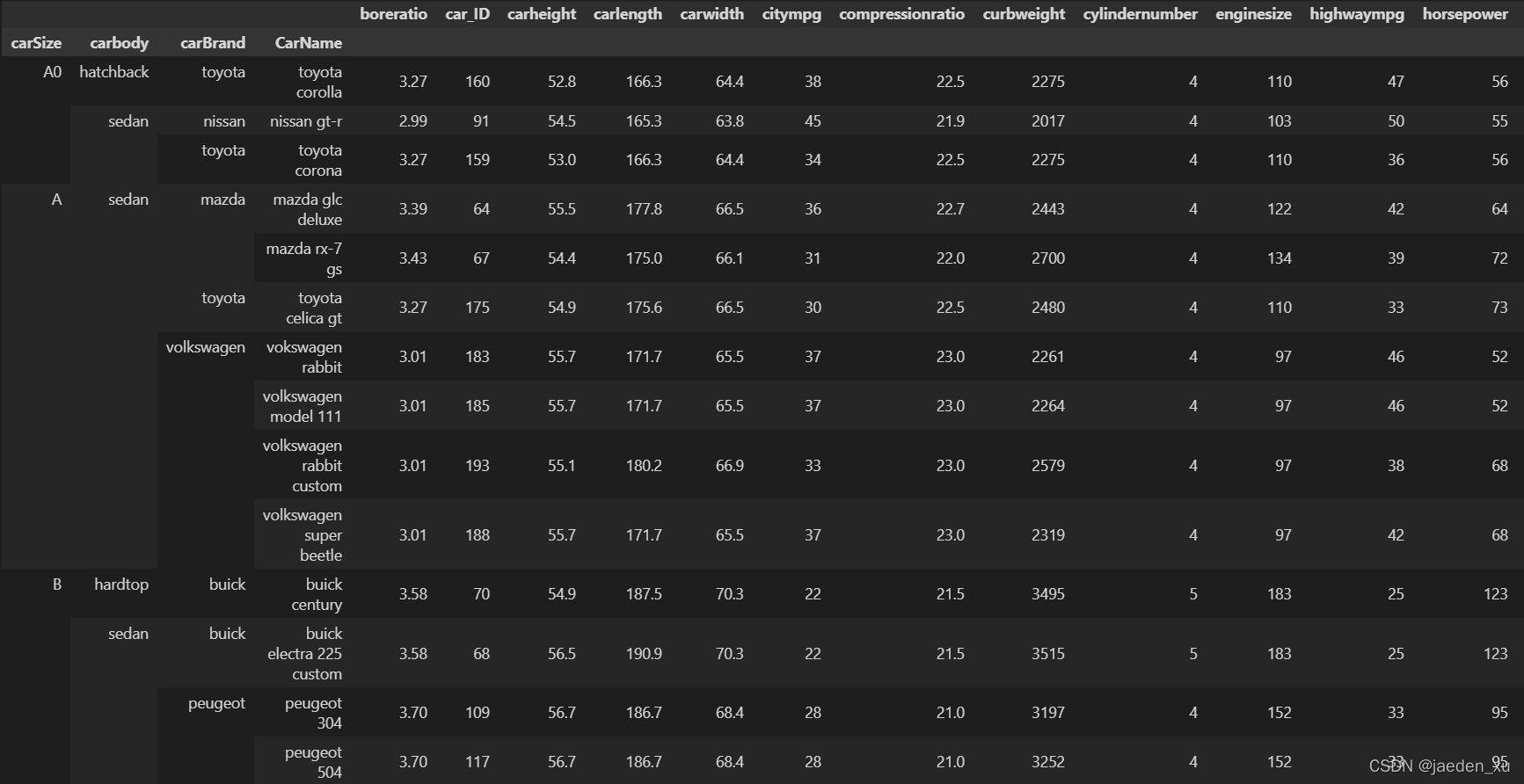
数据透视可知,集群0中所有的车型大小级别为:A0小型车、A紧凑型车、B中型车、C中大型车、D豪华型车; 而car_ID为183的‘vokswagen rabbit’属于A级紧凑型车,所以它最直接的细分竞品为集群0中的A级车中的其他6辆。
#提取集群0中的A级车
df0_A=df0.loc[df0['carSize']=='A']
df0_A
#查看集群0中A级车型的类别型变量的分类情况
ate_col=df0_A.select_dtypes(include='object').columns
df3=df0_A[ate_col]
df3

集群0中A级车型这7款车中,所属品牌分别为:大众(3辆)、马自达(2辆)、丰田(1辆),其中所有车型车身均为‘sedan’,燃料类型均为柴油,发动机均为前置,发动机型号均为‘ohc’,燃油系统均为‘idi’;只有‘mazda rx-7 gs’车型发动机为前置后驱动,其他6款均为前置前驱;另外,只有目标车型‘vokswagen rabbit’为双开门的三厢车,其他车型的为四开门的三厢车。
#对集群0中A级车的特征进行数据透视
df4=df0_A.pivot_table(index=['carBrand','CarName','doornumber','aspiration','drivewheel'])
df4
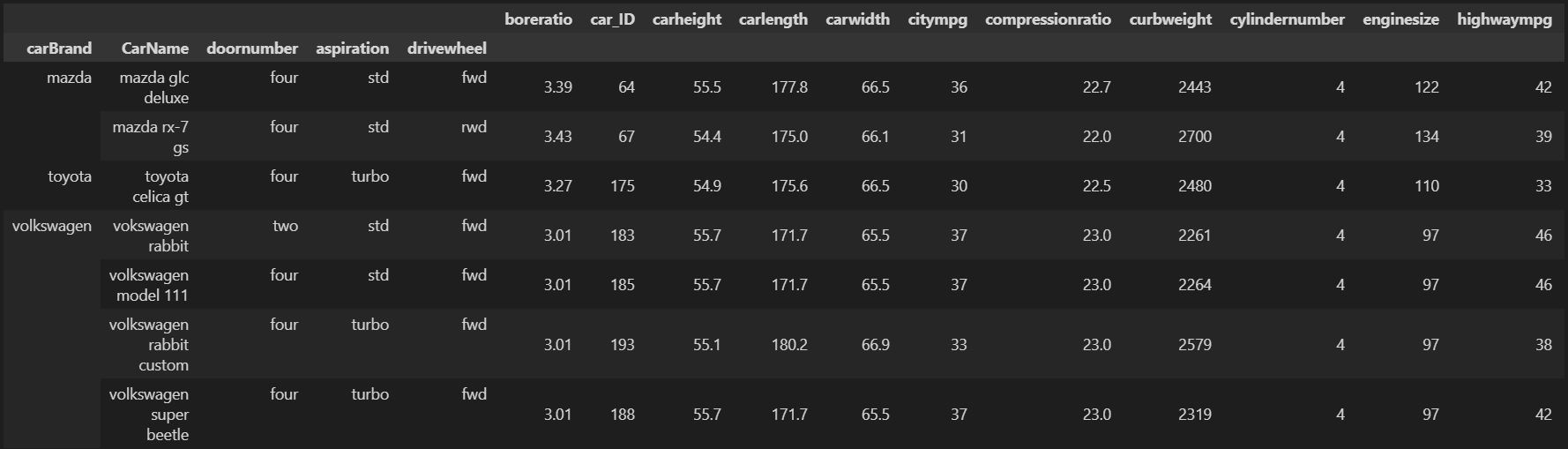
包含‘vokswagen rabbit’在内的7辆A级车中均有4个气缸,冲程范围在3.4-3.64,最大功率转速范围在4500-4800,压缩比范围在22.5-23.0,车身宽范围66.1-66.9,车高范围在54.4-55.7,气缸横截面面积与冲程比范围在3.01-3.43;以上这些数据都是比较相似的。
一般汽车关注点在:车型级别(carSize)、品牌(carBrand)、动力性能(马力horsepower)、质量安全(Symboling )、油耗(citympg、highwaympg)、空间体验(轴距wheelbase)、车身(carbody、curbweight) 等等。
下面提取其他一些不同关键特征进行考量‘vokswagen rabbit’与其他竞品之间的差异化:
基本信息:‘carBrand’,‘doornumber’, ‘curbweight’
油耗:‘highwaympg’、‘citympg’
安全性:‘symboling’
底盘制动:‘drivewheel’
动力性能:‘aspiration’, ‘enginesize’, ‘horsepower’
空间体验:‘wheelbase’
价格: ‘price’
#对油耗的分析('citympg','highwaympg')
lab=df0_A['CarName']
fig,ax=plt.subplots(figsize=(10,8))
ax.barh(range(len(lab)),df0_A['highwaympg'],tick_label=lab,color='red')
ax.barh(range(len(lab)),df0_A['citympg'],tick_label=lab,color='blue')
for i,(highway,city) in enumerate(zip(df0_A['highwaympg'],df0_A['citympg'])):
ax.text(highway,i,highway,ha='right')
ax.text(city,i,city,ha='right')
plt.legend(('highwaympg','citympg'), loc='upper right')
plt.title('miles per gallon')
plt.show()

’vokswagen rabbit‘车的油耗与‘Volkswagen model 111’一样,在7款车中并列最低,其在高速公路上每加仑油可跑46英里,而在城市这种交通比较繁忙糟糕的环境每加仑油可跑37英里,比最低的‘toyota celica gt’多了7英里;可见其油耗较其他款车型低。
#其他6个特征分析
colors=['yellow', 'blue', 'green','red', 'gray','tan','darkviolet']
col2=['symboling','wheelbase','enginesize','horsepower','curbweight','price']
data=df0_A[col2]
fig=plt.figure(figsize=(10,8))
i=1
for c in data.columns:
ax=fig.add_subplot(3,2,i)
plt.barh(range(len(lab)),data[c],tick_label=lab,color=colors)
for y,x in enumerate(data[c].values):
plt.text(x,y,"%s" %x)
i=i+1
plt.xlabel('')
plt.title(c)
plt.subplots_adjust(top=1.2,wspace=0.7)
plt.show()

由上面条形图,‘vokswagen rabbit’与其他竞品相比:
质量安全方面:其保险风险评级为2,比马自达品牌和丰田品牌车型相对更具有风险;
车身空间方面:轴距是最小的;
动力方面:发动机尺寸和马力都是最小的;
车重方面:整备质量最小的;
价格方面:价格是最小的;
4.4 总结和建议
综上所述,‘'vokswagen rabbit‘’与集群0中同是A级的竞品相比:
劣势:质量安全性偏低、车身空间偏小、动力马力偏小
优势:车身轻、油耗低、价格低(在类似的配置中性价比非常高)
设计特点:双车门三厢车
产品定位:“经济适用、城市代步紧凑型A级轿车”
建议: 在销售推广时,可偏重于:①同类配置车型中超高的性价比;②油耗低,城市代步非常省油省钱;③车身小巧,停车方便;④双车门设计,个性独特

















 671
671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









