







AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
方法
之前方法
将transformer与CNN融合
transformer特点
self-attention导致input变成 n 2 n^2 n2级别(this does not scale to realistic input sizes?我这里是否可以理解为,输入规模太大以致于现实无法训练)
- 解决方法:
- 只在局部运用self-attention (这些局部点积的自注意力块完全可以取代卷积的功能)
- 可伸缩的全局注意力机制
Vit
完全抛弃CNN
将图像分解成多个patches然后将形成的线性的嵌入序列作为输入输入倒Transformer中。
特点
对输入图像按照2*2分解成patches,然后在顶层运用自注意力机制。(该机制来源于另一篇论文,本来存在的局限是在低分辨率的图像表现效果更好,改进以后可以用在中等分辨率照片处理)
缺点
在中等规模数据集上,表现比ResNet低了几个百分点。(CNN存在平移不变性和局部性的归纳偏置)
平移不变性:系统产生完全相同的响应(输出),不管它的输入是如何平移的
局部性:空间联系近大远小。
优点
在较大规模数据集反而比ResNet高了几个百分点。
流程
- 将分辨率为 H ∗ W H*W H∗W,通道为C的图片分割成分辨率为 P ∗ P P*P P∗P的通道为C的块,我们可以得到块数 N = H ∗ W / P 2 N=H*W/P^2 N=H∗W/P2
- Transformer在所有图层上使用恒定的特征向量D,因此将patch展平,并使用可训练的线性投影(全连接层)映射到D的大小。
- 同时额外增加一个 x c l a s s x_{class} xclass,其本身不参与encoder当中,但是将会保存key,value作为预测所用(这里主要是因为没有用倒decoder)。
- 增加一个position嵌入来保留位置信息。
- 加入了多头注意力机制和多层感知机
- Layernorm归一化
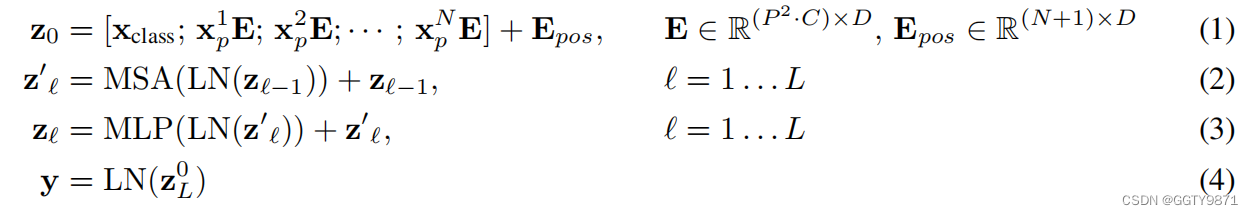
- 在更大规模的数据集合上进行训练,去掉 X c l a s s X_{class} Xclass
- 本实验是自监督的我们需要的是无监督的,不过可以参考















 2725
2725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









