







医学图像分割最成功的方法是使用依赖卷积运算作为主要构建块的深度学习模型。
卷积具有重要的特性,例如稀疏交互、权重共享和平移等变性。这些特性使卷积神经网络 (CNN) 具有强大且有用的归纳偏差,可用于视觉任务。
给定一个三维图像,我们的网络将其划分为个3D块,其中n=3或5。并为每个块计算一个一维的嵌入。网络根据这些补丁嵌入之间的自注意力机制,预测图像块中中心区域的分割图。这意味着网络会考虑所有补丁的信息,并通过计算它们之间的依赖关系来确定中心区域每个像素的类别标签。当标记训练数据较少时,通过预训练,我们提出的网络相对于 CNN 的优势可能非常显著。
- 分割图(Segmentation Map):在图像处理中,分割图是一个与输入图像大小相同的矩阵,其中每个像素通常对应一个类别标签,表示该像素属于图像中的哪个部分或对象。
- 图像块(Block)和中心区域(Center Patch):图像被划分为多个小块或区域,其中每个块包含多个子块或补丁(patch)。中心区域通常指的是这些块中的一个特定区域,可能是为了专注于图像的某个重要部分。
- 补丁嵌入(Patch Embeddings):通常,图像首先被转换为一系列嵌入向量(或特征向量),每个向量代表图像的一个小块或补丁。这些嵌入向量是模型的输入,并用于计算自注意力权重。
1. 介绍
图像分割是医学图像分析的核心任务。它通常用于量化感兴趣的体积/器官的大小和形状、人口研究、疾病量化、治疗计划和计算机辅助干预。
医学图像分割中的经典方法涵盖从区域生长[11]和可变形模型[36]到基于图集的方法[32]、贝叶斯方法[29]、图割[26]、聚类方法[12]等。
目前工作的一个共同特征是使用卷积运算作为网络的主要构建块。所提出的网络架构在卷积运算的排列方式方面也有所不同。人们已经尝试使用循环网络和注意力机制进行医学图像分割。
卷积运算的有效性归因于:①局部(稀疏)连接;②参数(权重)共享;③平移等方差。
平移等方差(Shift-equivariance)描述的是网络对于输入图像中对象的平移具有等变性的特性。具体来说,如果输入图像中的对象发生平移(即在同一平面内,按照某个直线方向做相同距离的移动),那么网络输出的特征图也会相应地发生平移,但特征表示本身(如对象的识别)不会改变。
典型图像中的像素数量远大于自然语言处理应用中的数据单元(例如单词)数量。
ViT则是将图像块而不是像素视为图像中的信息单位。ViT 将图像块嵌入到共享空间中,并使用自注意力模块学习这些嵌入之间的关系。通过使用 CNN 教师的知识蒸馏并使用标准训练数据和计算资源,Transformer 网络可以实现与 CNN 相当的图像分类准确度水平。
文章提出的内容
基于 3D 图像块线性嵌入之间的自注意力的网络架构,无需任何卷积操作
提出了预训练方法,当有大量未标记的训练图像可用时,该方法可以提高我们网络的分割准确率。我们表明,当标记的训练图像数量较少时,我们的网络表现优于采用预训练的最先进的 CNN。
2. 方法
2.1 提出的网络
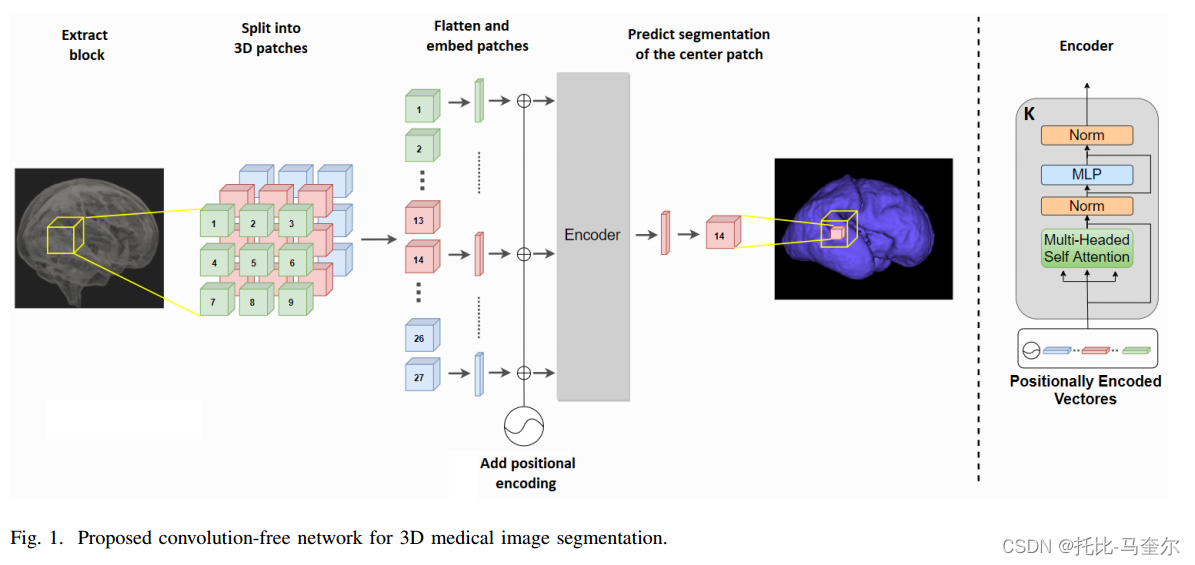
网络输入的是一个3维Block ,其中
表示Block在每个维度上的范围(以体素为单位),c是图像通道的数量,Block被划分为
个连续的不重叠的三维补丁
,其中
是每一个补丁的边长,
表示块中的补丁数。网络使用 B 中所有 N 个 patch 中的图像信息来预测中心 patch 的分割。
Voxel是指三维体素,是一种三维图形表示方法。它将一个三维空间分成许多小的立方体(即voxel),每个voxel都代表一个具有特定属性(如颜色、透明度、密度、纹理、光照和碰撞检测等方面的信息)的空间单元。与二维像素类似,voxel是三维像素的缩写。
N个补丁中的每一个都被展平为大小为并使用可训练映射
嵌入到
中。
不使用任何额外的令牌,因为这不会以任何方式提高我们网络的分段性能。嵌入补丁的序列
构成网络的输入。矩阵
旨在学习位置编码。如果没有这样的位置信息,变换器就会忽略输入序列的排序,因为注意机制是排列不变的。因此,在大多数 NLP 应用中,这种嵌入非常重要。
编码器
编码器有 K 个阶段,每个阶段由多头自注意力(MSA)和后续的两层全连接前馈网络(FFN)组成。MSA和FFN模块都包含残差连接、ReLU激活和层归一化。从上述嵌入和位置编码补丁序列 开始,编码器的第 k 级将执行以下操作以将
映射到
:
1. 在 MSA 中经过
个单独的头。第 i 个头:
a) 根据输入序列计算查询、键和值序列:
b) 计算自注意力矩阵,然后计算转换后的值:
2. 头的输出被堆叠并重新投影回
其中
3. MSA模块的输出计算如下:
4. 经过两层FFN以获得第
个编码器的输出:
最后一个编码器阶段 XK 的输出将通过最终的 FFN 层,将其投影到 上,然后重新整形为
,其中
是类的数量(对于二进制分割,
= 2 ):
是块中心补丁的预测分割
2.2 模型训练
训练网络参数以最大化和使用 Adam 的中心补丁的真实分割之间的 Dice 相似系数 DSC。使用的批量大小为 10 ,学习率为
,如果在训练后验证损失没有减少,则学习率会减少一半。
预训练
对于一张图像,手动分割大脑皮层板等复杂结构可能需要医学专家花费数小时的时间。因此,能够以较少的标记训练图像实现高精度的方法具有很高的优势。为了在标记训练图像不足的情况下提高网络性能,我们建议首先在未标记数据上对网络进行预训练,以进行去噪或修复任务。
对于去噪预训练,我们在输入块 B 中添加 的高斯噪声,而对于修复预训练,将Block的补丁中心设置为常数0。在这两种情况下,目标都是块的无噪声中心补丁。对于预训练,我们使用不同的输出层(没有 softmax 操作)并训练网络以最小化预测和目标之间的
范数。
为了对预训练网络进行微调以完成分割任务,引入一个带有 softmax 的新输出层,并在标记数据上训练网络,如上一段所述。我们对标记图像上的整个网络(而不仅仅是输出层)进行微调,因为我们发现对分割任务的整个网络进行微调可以获得更好的结果。
2.3 数据
使用约 的训练图像进行验证,最终模型在测试图像上进行评估。图像被随机分为训练/验证/测试。

3. 结果和讨论
采用滑动窗口的方式应用我们的网络,为了生成整个图像的注意力图,我们在滑动窗口的每个位置都计算注意力矩阵(这些矩阵的大小为)。在每个滑动窗口的位置,注意力矩阵沿着列方向进行求和,计算每个补丁(或图像部分)从其他补丁那里获得的整体注意力。以滑动窗口的方式执行上述计算,并计算体素级的平均值(voxel-wise average),最终得到注意力图。注意力图可以指示图像的每个部分受到了多少关注。
一般来说,网络的早期阶段具有更广泛的注意力范围。关注感兴趣器官(此处为胰腺)周围的其他结构和解剖特征。网络的更深阶段更关注胰腺本身。
在每个阶段,MSA 模块的四个独立头采用截然不同的注意力模式。这表明 MSA 的多头设计使网络能够更灵活地学习注意力模式,从而有助于提高分割精度。
增加补丁的数量/大小或增加网络深度通常会导致准确性略有提高。此外,与自由参数/可学习位置编码相比,使用固定位置编码或不使用位置编码会略微降低分割精度。最后,使用单头注意力会显著降低分割精度,这表明多头设计对于使网络能够学习相邻补丁之间更复杂的关系的重要性。
模型基于相邻 3D 块之间的自注意力。 我们的结果表明,所提出的网络在三个医学图像分割数据集上的表现可以胜过最先进的 CNN。通过对未标记图像进行去噪和修复任务的预训练,当只有 5-15 张标记的训练图像可用时,我们的网络也比 CNN 表现更好。















 1078
1078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









