







前言
之前的文章对集合整体做了一个介绍,并对其中一些主要的实现类,做了详细的介绍和分析,其中就包含HashMap,但是当时我们呢说它是线程不安全的。那么今天我们就介绍一个线程安全的HashMap,那就是ConcurrentHashMap
ConcurrentHashMap的优势
1.线程不安全的hashmap:之前文章介绍过,为什么hashmap是线程不安全的,那是因为,它的put操作可能导致循环链表的出现,从而出现死循环。
2.hashtable:hashtable虽然是线程安全的,但是我们之前说过,他用的是synchronized关键字,在put方法上,这个就导致它的效率是十分的低下的。
3.ConcurrentHashMap:那么ConcurrentHashMap是怎么既能加锁保持多线程的正确同步,又能保证效率不低下呢。这个就是分段锁的功劳了。分段锁其实就是将一堆数据,分为一块一块的,然后给每一块的数据加上锁,这样就减少了对锁的竞争,提升了效率。
ConcurrentHashMap的结构
下面这个图就是ConcurrentHashMap的大致结构
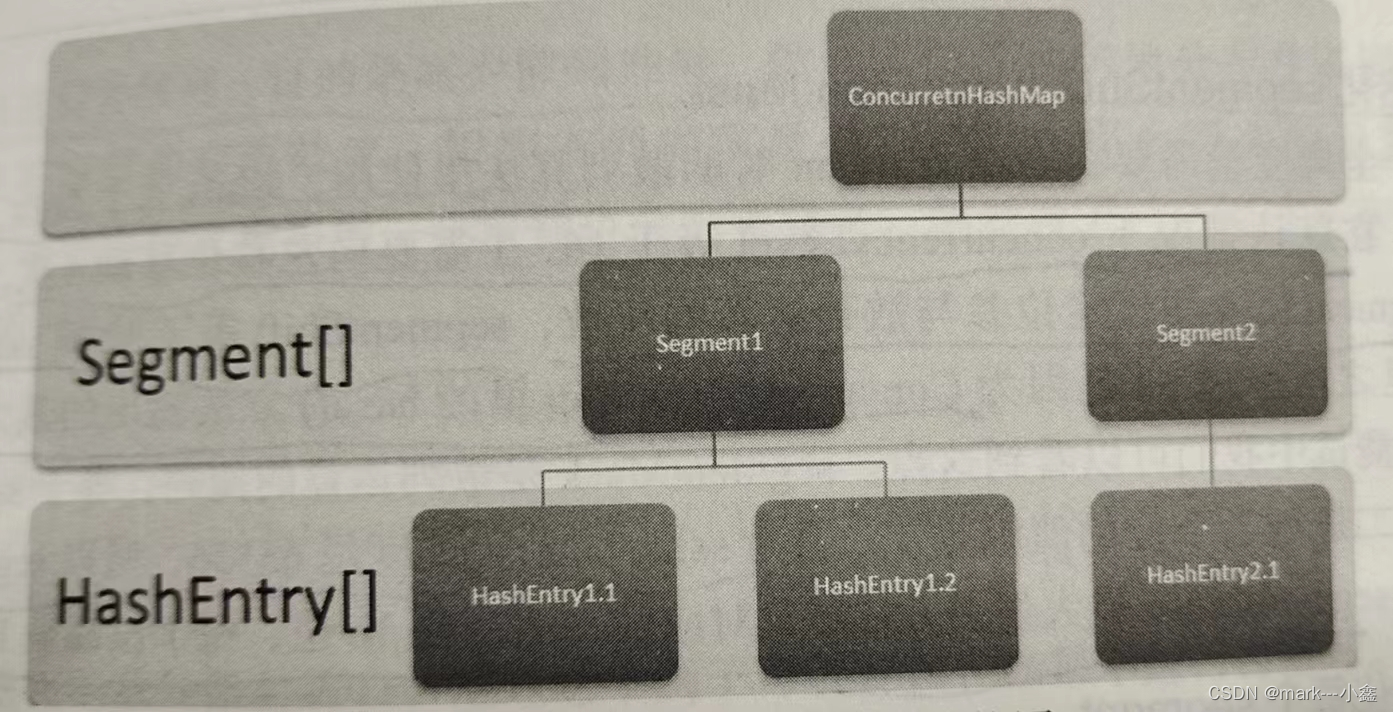
图中的HashEntry数组就相当于hashmap里面的entry数组。而这个Segment就相当于一个HashMap。ConcurrentHashMap感觉就像多个HashMap组合在一起。
ConcurrentHashMap初始化
ConcurrentHashMap初始化和当时的hashmap基本差不多,只是当时hashmap初始化的是Entry数组,这里初始化的是segment数组,同样,这个数组长度必须也的是2n次方。
但是它需要多初始化两个变量segementShift和segementMask。这两个,一个是散列运算的位数,一个是散列运算的掩码。
然后就是初始化segment,和初始化hashmap基本一致,可能某些参数不太一样。
ConcurrentHashMap的常见方法
1.get操作
先经过一次散列,定位到segement,然后再经过一次散列,定位到hashentry,最后匹配到元素,取出。这个操作是没有加锁的,原因就是它将需要用到的共享变量,都定义为volatile类型的,这个既不会读到过期变量,也能提升效率(这个前提是没有多线程的写入)。
定位hashentry和segement散列方法一样,但是与的值不一样,定位segement用的是元素通过hashcode再散列后得到的值的高位,而定位hashentry直接使用的是再散列后的值。
2.put操作
由于put方法需要对共享变量进行写入操作,所以为了线程安全,再操作共享变量的时候,必须加锁。
在插入之前需要进行两部操作,第一步就是判断是否需要扩容,第二不就是记录添加元素的位置,将其放在hashentry数组里面。(这个扩容操作和hashmap类似,这里不再赘述)
总结
ConcurrentHashMap采用了一种分段锁的方式,降低了锁冲突。从而实现了,不会牺牲特别多的效率去换取线程的安全。所以,在一些多线程的场景中,大家可以尝试使用ConcurrentHashMap。


















 4188
4188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











