







问题定义:构建传播最大化模型(最大化末态时的激活节点数量 )& 确定最具影响力节点
思考问题:
- 影响节点影响力的因素?
- 有向图和无向图的模型构建区别?
定义参数:
- 节点影响力的取值范围
- 节点影响力和其邻居节点影响力的关系表达式
- 非活跃节点的激活条件
- 非活跃节点的激活概率
问题瓶颈:
- 大规模网络计算量大,局部节点得不到优化
- 多个网络中,不能同时满足时间效率和传播范围
解决角度:
- 最大化激活节点数量(NP难) -贪心算法
- 分开考虑局部节点传播 & 扩大影响力范围值
解决方案:
综合考虑节点的度 & 局部优化 两个因素
( local node optimization & degree discount)
优化以往算法的不足,提升传播范围 & 时间计算效率(减少获得候选节点集 & 节点选择 的时间)指标
《Social network node infuence maximization method combined with degree discount and local node optimization》
with degree discount and local node optimization》)
现有在线社交网络传播扩散模型
1. 独立级联模型
根据激活概率,激活节点激活其邻居节点
2. 线性阈值模型
每个节点拥有激活阈值,累加超过激活阈值则被激活。
3. 加权级联模型(独立级联特例)
u对v的传播概率 = uv边的权重 / v的入度(影响v的节点总数)
对于传统社交网络中节点影响力最大化的问题,不可能同时选择节点和扩大大规模扩散的范围。基于局部节点优化和度折扣,提出一种新的节点影响最大化算法(度折扣和局部改进方法,DLIM)。首先,优化候选种子集;构造NAV(节点近似影响值)函数来计算局部节点的影响值。确定影响值相似的节点,选择源节点;相似度方法用于筛选和删除具有相似影响值的节点。其次,提出一种节点激活算法,以度折扣的思想过滤候选节点;构建DMAP(度折扣和最大激活概率)。该函数使用过滤的候选节点进行全局扩散。最后,利用所提出的DLIM算法选择种子节点对节点进行优化,利用独立级联传播模型对Wiki-Vote、NetHEPT、NetPHY和GrQc四个真实数据集的4个真实数据集和独立级联(IC)进行比较分析实验。对传播模型进行了对比分析实验。实验结果表明:与传统的度贴现算法相比,所提DLIM算法的传播范围提高了11.3%。时间效率比传统的度贴现算法快四个数量级。所提出的DLIM算法合理有效。它也可以应用于网络营销,产品推荐等领域。
基于degree discount的算法框架
- 总思路: 计算(选择) 节点的局部影响值,将其传播到全局进行节点选择 (平衡两个操作的时间,提高效率)
(1)利用计算 子图中心性(subgraph centrality),计算局部节点影响力
所有 i 的邻居节点对 i 的增强能力:

a 是节点 i 邻接矩阵的元素,t 是幂次
(2) 删除影响力大的节点,也可利用检查删除某一结点后网络拓扑生成树的方法衡量节点重要性:生成树越少,节点越重要。
- NAV 函数(计算节点u局部影响力) & DMAP 优化函数(计算节点u全局影响力) & 节点过滤函数
(1) u在两阶段(一跳v和二跳s邻居得到的 局部总影响),筛选 影响值最大 的节点为 源节点

- 一跳v对u的影响:
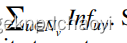
- 二跳s对u的影响:

- u到v & v到s的传播概率相同:

1.利用NAV函数,发现并激活第一级的源节点
2.利用NAV函数执行局部节点间影响值
3.节点影响值的计算与判断:第二阶段的节点受到影响,移除影响力相似的节点,然后进行第二次传播。
(2) DMAP(融合 度折扣和最大激活概率)
直接使用度折算法应用于影响最大化问题,其传播范围通常有限,性能不稳定,容易受到度折的影响
因此将度折现算法与局部节点激活的最大概率相结合,利用局部节点激活的最大概率计算节点集的最大激活概率** & 影响,然后选取节点进行全局扩散**
- 节点s的 最终全局影响值:(u到s & s到u 是可逆过程)
(SC种子集合u,SN源节点集合v)

- u对v的影响:

- 利用递归,则 s的全局影响 = v的局部影响 × uv之间的影响
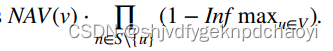

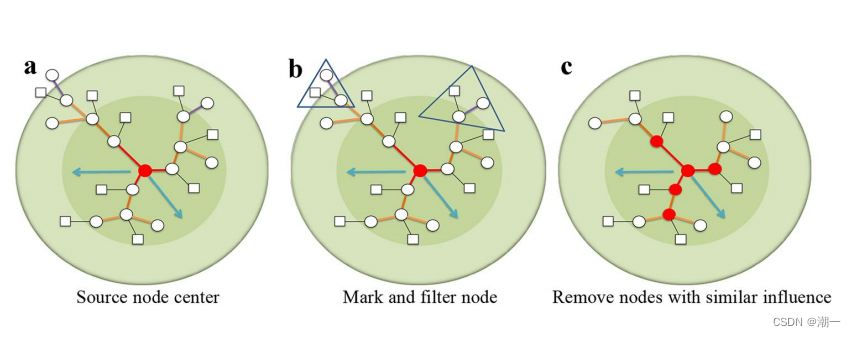
(3)利用 节点相似性 的 节点过滤函数
NAV函数用于计算两级传播过程中节点的局部影响值,局部影响值容易影响范围重合。因此将影响范围重合的节点进行过滤。
基于候candidate seed set的优化策略
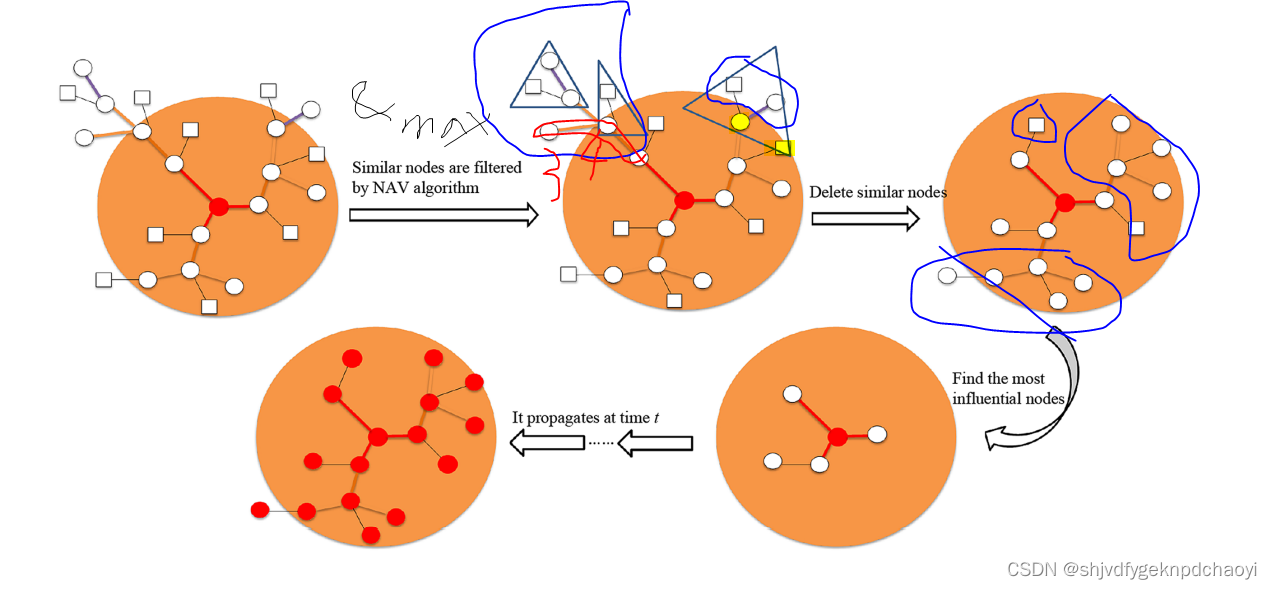
1.计算所有NAV,此时可能有相似点
2.删除相似点,此时保留⚪和 ▢,3号节点删除是因为4号删除
3.选择最大点被传播,一轮传播结束
第一步:源节点选择 source node selection

第二步:过滤候选节点 = 过滤源节点的原始节点集
Filtering of candidate nodes = select nodes from the original node set of source nodes.


















 2024
2024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











