








这篇论文提出了一种基于图注意力嵌入(GAEIM)的影响力最大化方法,主要创新点包括:
1. 图注意力嵌入模型的应用:论文中提出的GAEIM方法利用Node2Vec技术来学习节点的特征表示,并结合图注意力模型(Graph Attention Model)来学习更复杂的图拓扑结构。这使得算法能够在不同层级上有效地利用图的结构特征,从而更准确地识别出有影响力的种子节点。
2. 避免影响力重叠的策略:为了减少影响力的重叠,即避免选择影响力重叠较大的节点作为种子节点,论文提出了使用启发式方法选择候选种子节点,然后应用成本效益懒惰前向算法(CELF)来从这些候选种子节点中选择最终的种子节点集合。这种方法可以有效减少解决方案的次优问题,即减少因种子节点选择不当而导致的影响力扩散效果不理想的问题。
3. 实验评估的全面性:论文在多个真实数据集上评估了GAEIM算法的效果,并与现有的影响力最大化算法进行了比较。实验结果显示,GAEIM在影响力传播和效果方面优于其他比较方法,展示了其优越的性能。
这些创新点不仅提高了算法的效率和效果,也为解决社交网络中的影响力最大化问题提供了新的视角和方法。
本文提出的方法是基于图注意力嵌入的影响力最大化(GAEIM),主要包括以下几个关键步骤:
1. 节点特征嵌入学习
首先使用Node2Vec技术来学习节点的特征表示。Node2Vec是一种基于随机游走的网络节点特征学习方法,可以有效捕捉节点间的局部连接模式。接着,使用图注意力模型进一步学习更复杂的图拓扑结构。图注意力模型允许节点根据它们邻居的重要性和连接模式,动态地调整与邻居的连接权重。
2. 候选种子节点选择
在节点特征嵌入的基础上,通过启发式方法来评估和选择候选种子节点。这一过程考虑了节点的欧几里得距离来评估节点间的相似性,并计算每个节点在与其高度相关的节点集中出现的频率。选择出现频率高的节点作为候选种子节点。
3. 最终种子节点选择
为了解决影响力重叠的问题,文章采用成本效益懒惰前向(CELF)算法从候选种子节点中选择最终的种子节点集。CELF算法是一种优化的贪婪算法,通过减少不必要的影响力评估来提高选择过程的效率。
4. 算法评估
GAEIM算法在多个数据集上进行评估,与现有的影响力最大化算法相比,显示出了更好的传播效果和效率。这些数据集包括NetHEPT、NetScience、Citeseer和Cora等。
通过结合深度学习技术和传统的图理论方法,GAEIM算法能够更精确地挖掘和利用社交网络中的复杂结构信息,从而有效地解决影响力最大化问题。
Abstract
选择k个重要成员以最大化影响力传播是影响力分析中的一个关键算法挑战。这被称为社交网络中的影响力最大化(IM)问题。以往对于IM问题的研究主要存在两个问题:(1)复杂的图数据无法在图拓扑中得到有效利用,(2)容易出现影响重叠的问题,从而导致解决方案无法解决。种子集不理想。本文提出了一种基于图注意力嵌入(GAEIM)的影响力最大化方法来解决上述问题。 GAEIM通过Node2Vec学习浅层图结构,并利用图注意力机制学习更深层次的图结构,以提取与IM问题相关的信息。然后,为了减少影响重叠,我们在使用启发式算法选择预期种子节点后,应用经济有效的惰性前向算法(CELF)来选择最有影响力的种子节点。此外,我们还证明了 GAEIM 的单调性和子模性。因此,所提出的方法保证了 IM 问题的近似最优解。根据实验结果,在各种数据集上,与现有 IM 算法相比,GAEIM 算法表现出优越的影响传播和有效性。
关键词——图神经网络、社交网络、图拓扑、node2Vec、影响力最大化
I. INTRODUCTION
由于5G时代的出现和新媒体技术的不断进步,在线社交网络[1]变得越来越流行。过去几年虚拟社区的发展很大程度上归功于在线社交网络的出现。通过口碑机制,玩家通过一系列定期的个人活动(包括对话和材料交换)相互联系。它们已发展成为最重要、最高效的信息传播平台,使其能够快速传播到大量人群。 IM 是社交网络中广泛研究的信息传播问题,并且由于其潜在的商业价值,最近进行了大量研究。其目标是选择社交网络中的一些成员作为种子节点,然后通过他们传递信息来影响网络中的其他成员,并在信息传播过程中触及尽可能多的用户。 IM 有许多众所周知的应用,例如病毒式营销[2,3]、个性化推荐[4]、行为分析[5]、收入最大化[6]和意见形成[7]。
一般来说,约束优化问题和NPhard问题都可以用来定义IM。 IM 问题最初由 Domingos 和 Richardson 定义[8],他们将其作为优化问题进行研究,并提出了概率解决方案。 Kempe [9] 确定 IM 问题是一个 NP 困难的离散优化问题,他们开发了一种贪婪方法来解决它。利用影响传递的子模块性,Leskovec 的 [10] CELF 提案,比 Kempe 的贪婪方法快 700 倍。通过增强 CELF,Goyal 等人。文献[11]提出了CELF++方法,利用最大堆进一步减少每轮节点影响力增益的计算量,提高算法的时间效率。 Cheng [12] 在 2013 年提出了一种称为 StaticGreedy 的静态贪婪方法,以进一步最小化蒙特卡罗模拟的复杂性。该算法的性能比以前基于蒙特卡罗模拟的算法要好得多,同时每轮的蒙特卡罗模拟数量显着减少。
通过增强上述基于蒙特卡罗模拟的贪心算法,程序的时间效率得到了显着的提高。然而,运行该算法仍然需要相当长的时间。因此,研究人员利用网络的结构特性以及信息传播模型的某些方面,寻找高影响力的节点,并提出一些启发式算法。 Degree Discount 是 Chen 等人开发的算法[13]当一个节点被选为候选节点时,必须对其相邻节点的度进行折扣。 Wang等人提出了基于独立级联模型的最大影响树状法(MIA)。 [14]。该算法假设节点只能影响周围局部树结构中的邻居,并且只有概率最高的节点才被认为影响传播路径,这简化了节点影响传播的计算。
尽管IM问题已经被讨论,但仍然缺乏有效且准确的解决方案。目前传统的IM方法存在只能利用网络中浅层拓扑的缺陷。然而,随着深度学习技术的不断进步,数据维度大、数据稀疏的问题现在可以得到有效解决。在非结构化图数据中,图神经网络表现出了优异的性能[15]。面对具有图结构的复杂数据,图神经网络可以有效学习图中不同层次的结构特征,也可以学习节点中丰富的内容信息,将图结构信息与节点内容有效融合信息以获得低维密集节点特征表示。
本文提出了基于图注意力嵌入的GAEIM。首先,我们使用 Node2Vec 技术来学习节点特征表示。考虑到节点对其相邻节点的不同程度的关注,图关注模型用于学习更复杂的图拓扑。其次,采用启发式方法选择候选种子节点,使用欧氏距离评估节点之间的相似性。接下来,统计强相关节点集中各节点出现的频率,选择一些出现频率较高的节点作为候选种子节点集。 CELF用于从候选种子节点中选择最终的种子节点集合,以防止重叠影响的问题。与之前的研究相比,本文算法在利用图拓扑方面进行了改进。 GAEIM 基于四个数据集(包括 NetHEPT[16]、NetScience[16]、Citeseer 和 Cora)进行了广泛评估。实验结果表明,GAEIM的效果传播程度基本上优于各对比方法。
总之,贡献如下:
• 为了成功避免重叠影响的问题,本研究中提出的选择种子节点的新技术采用启发式方法在CELF 选择最终种子节点集之前选择候选种子节点。
• 根据每个节点的结构特征,GAEIM 确定哪些节点对网络最重要。
• 使用四个真实的数据集,我们通过实验评估了建议的方法。实验结果表明,GAEIM 比以前的 IM 算法性能更好,传播影响更广泛。
本文其余部分的结构如下:第二节涵盖了影响力最大化的相关研究;第三节对IM问题进行了形式化描述,并详细分析了GAEIM及其时间复杂度;在第四部分中,使用了大量测试来评估我们的方法的执行情况;最后,第五节总结。研究IM问题,首要的工作就是关注图神经网络,学习图结构数据中有用的特征信息。
II. RELATED WORK
IM 问题是一个经过深入研究的问题,涉及信息如何在社交网络上传播。社区结构是网络的关键组成部分之一,显着影响信息的传播方式。直观上,同一社区内的信息更容易传播,而不同社区之间的信息传播则更困难。曹在2010年提出了第一个基于社区的影响力最大化方法——社交网络中的最优分配方法(OASNET)[17]。该研究假设社区彼此不同,并且社区之间无法共享信息。整个过程分为两个阶段。 (1)使用基本的贪心算法从每个社区中选择候选种子节点,(2)从这些候选种子节点中选择最终的种子节点。尚等人[18]利用社区结构和信息传播的特点,提出了CoFIM框架。
基于社区的方法常常忽视连接不同社区的重叠节点的重要性。相反,他们倾向于关注评估社区内各个节点的影响力。不幸的是,忽略这些链接可能会导致种子节点选择不准确,并在影响传播期间降低性能。因此,Wang[19]提出了一种基于重叠社区的影响力最大化方法(CNCG)。该方法将网络划分为重叠的社区,然后提出种子节点选择策略,根据社区不同情况所获得的影响力来选择节点。启发式方法虽然速度很快,但种子节点选择的精度无法保证。因此,一般的影响力最大化方法会在算法的准确性和时间效率之间做出折衷。
为了有效利用网络拓扑特征和节点内容信息,Huang[20]提出了CIMA模型。社区检测、候选社区生成和种子节点选择构成了该模型的三个主要部分。该模型将图结构特征和节点属性特征嵌入到节点表示中,然后使用逻辑函数计算两个节点之间的影响概率。 Keikha等人[21]提出了基于深度学习的影响力最大化模型DeepIM。算法最初使用图嵌入方法来学习节点的特征表示,然后使用向量之间的单位点积来确定节点彼此之间的相似程度。对于每个节点,选择前r个最接近的节点进行计数,最后由统计频率最高的k个节点确定种子节点。
III. METHOD
A. Preliminary
在本文中,我们研究普通图的影响力最大化问题,( ) , G VE = 由 nn 个节点 { } 12 ,, ,n V vv v = 和 m 个边 { } ij E e VV = ⊆× 组成。 G 的拓扑可以定义为 nn × 邻接矩阵 ( ) ij nn Aa× = ,如果 ij eE ε ,则 1 ij a = ,否则 0 ij a=
IM 给出了一个网络 G 、正整数 k 、1 kn ≤≤ 和一个确定性影响传播模型,选取该网络中的 k 个节点作为种子节点集 S 。在o的影响下影响力传播模型中,种子节点集S对整个网络进行影响力传播,传播后受影响的节点数量最多。假设 ( ) S σ 表示节点集 S 的影响力扩散程度,S* 表示影响力扩散程度最大的种子节点,则 IM 问题可以用 ( ) , arg max S VS k S 来描述
边际增益将一个新激活的节点u加入到节点集合S中,形成一个新的节点集合S' = S ∪ {u}。节点集S'的影响扩散增益相比于节点集S是节点u在集合S下的边际增益,可以用以下方式描述:Δ(u|S) = σ(S ∪ {u}) - σ(S)。
这里,σ表示影响力的扩散函数,Δ(u|S) 表示在集合S下添加节点u的影响力增益。
B. Proposed Method
我们描述了GAEIM,该算法主要由三个阶段组成:节点特征嵌入学习、候选种子节点选择和种子节点选择。图1描述了算法的整体结构:

(1)节点特征嵌入学习:为了利用更复杂的图拓扑,在本文提出的GAEIM中,首先使用Node2Vec来学习节点特征表示。考虑到节点对其邻居节点的关注程度不同,使用图注意力模型来学习更复杂的图拓扑结构。
(2)候选种子节点选择:该阶段采用启发式方法选择候选种子节点。在获得网络的节点特征表示后,利用节点之间的欧氏距离来评估它们的相似程度,然后计算每个节点的强相关节点集。最后统计每个节点在其他节点的强相关节点集中出现的频率,进行排序,选择一些出现频率高的节点作为候选种子节点集
(3)选择种子节点:通过从潜在种子节点集中选择种子节点,可以加快算法的整体时间效率。本步骤使用CELF从候选种子节点中选择最终的种子节点集合,以消除节点间影响力重叠的问题
C. Feature Learning in IM
大多数IM问题方法都是基于用户的结构信息和网络拓扑来检查用户之间如何连接。建议使用 Node2Vec+ 图注意力模型来学习复杂的图结构特征。网络中的节点使用 Node2Vec[22] 进行采样。 Node2Vec基于二阶随机游走超参数q和p,考虑低阶邻居和高阶邻居之间的相似性,生成随机游走序列,能够灵活地捕获网络节点的同质性和结构相似性。然后,使用skip-gram算法最大化中心节点i v 和左右窗口长度ω内的上下文节点共现的概率。概率公式如(1)所示:

这里 ( ) i v φ 是节点的潜在特征表示。通过取(1)的对数来最小化最终的目标损失函数。之后,使用随机梯度下降方法实现优化收敛,并获得最终的节点特征表示。

采用图注意力技术来学习日益复杂的图拓扑。由于注意力系统的工作原理,用户会为其邻居节点分配不同的注意力,具有相似爱好或相似拓扑的邻居节点将被分配更大的注意力系数,这使得节点能够学习更复杂的图拓扑特征。为了使self-attention机制更加稳定,通常使用Vaswani[23]提出的多头attention机制,如(3)所示:

其中 k ij a a 表示第 k 个注意力层计算的注意力系数,k W 表示对节点特征进行线性变换的第 k 个可学习参数。
对于最后一层模型,首先计算k个特征的平均值,然后使用非线性激活函数进行非线性变换。节点更新如(4)所示:

Node2Vec + 图注意力模型首先通过使用采样的随机游走序列和负采样技术将浅层图结构学习为节点表示 i x [24]。接下来,使用双层图注意网络层处理 i x 以进一步学习更深的图结构。它为每个节点构造预定数量的路径,忽略网络搜索中节点的程度并学习复杂的图拓扑,从而提高了算法的有效性。图 2 描绘了节点特征学习过程

D. Seed Node Selection
上一节讲解了利用图形注意力机制来学习结构特征向量,为每个网络节点创建一个相关向量,为捕获节点的领域关系做准备。在本节中,为了衡量节点对彼此之间的相似程度,利用向量的欧几里得参数化[25],并且如(5)中所示,利用欧几里得参数化来确定节点 i 和 j 之间的相似性。
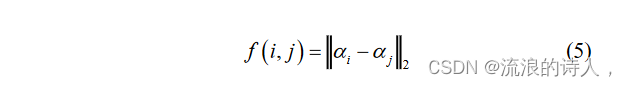
如果节点之间相似度较高,则认为节点更容易受到彼此影响,否则,节点不易受到彼此影响。
对于社交网络,信息在到达其二阶邻居之前可能传播的距离通常相当短[26]。网络中每个节点的相关向量是通过选择与该节点的一阶和二阶邻居的邻接矩阵相关联的特征向量来确定的。使用特征向量计算节点对之间的相似度,然后排序。若一阶邻居和二阶邻居节点的个数为 p n ,则选择相似度最大的 p rn × 节点作为强相关节点,其中 r 为强相关节点系数, p rn × ,节点向下取整。接下来,统计该节点在相关性显着的节点组中出现的次数,对节点频率进行排序后,选择实例数最多的 ck × 节点作为潜在种子节点。 c是候选种子节点相关系数,k代表种子节点的数量。
表1介绍了候选种子节点集的选择。第2-13行主要计算每个节点的强相关节点,第3行进行二阶邻居节点的搜索,然后第5-8行计算得到的邻居节点对的相似度,在接下来的9-12行中,对相似度进行排序以获得强相关节点。第 15 行到第 19 行计算每个节点作为紧密链接节点列表中的另一个节点出现的次数。对第 20-21 行中的统计频率进行排序会产生潜在种子节点的集合。
选择候选节点后,使用CELF[27]计算种子节点集S。

表2介绍了种子节点的选择。每个节点的影响传播在添加到优先级队列之前在第 2-5 行单独计算。第8-19行用于选择k个种子节点,第12-14行表示如果节点u之前被访问过,则意味着u是我们必须确定如何增加节点集传播度增益的节点。此时,将u放入种子节点集合中,并且然后开始寻找下一个种子节点。第15-17行,将计算出影响力扩散增益的节点放回优先级队列,然后将该节点标记为已访问。
E. Monotonicity and submodularity properties in GAEIM
前述部分中选择的候选节点可能存在影响力重叠,而影响力重叠对于种子节点集传播影响力的程度没有积极影响。为了量化种子集S的信息传播程度并为种子节点集的选择做好准备,执行启发式来选择预期种子节点。根据(6)。
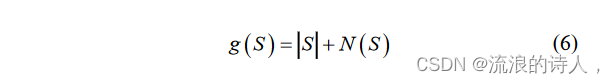
其中,S 是集合的大小,( ) NS 是集合 S 中不活动邻居节点的数量。在独立级联传播模型下,( ) gS 是单调且子模的。
首先,对于单调性,有 g(S ∪ {u}) ≥ g(S)。
其次,对于次模性,需要证明对于所有 S ⊆ T ⊆ V, ∀u ∈ V,有 g(S ∪ {u}) - g(S) ≥ g(T ∪ {u}) - g(T)。显然,S 是次模的,因此只需要考虑 N(S)。因为对于所有的 S ⊆ T,有 N(S) ≤ N(T),这意味着节点u在种子集S下能连接更多未激活的邻居。因此,N(S ∪ {u}) - N(S) ≤ N(T ∪ {u}) - N(T),所以 N(S) 也是次模的。既然 S 和 N(S) 都是次模的,那么 g(S) 也是次模的。因此,种子节点集S可以使用CELF算法来计算。在种子集中,首先选中的节点出现的频率比后面的高。由于种子集大小增长时,效应传播减少,因此影响力最大化是NP难问题,但建议的方法确保解决方案大致保持比率为 1 - 1/e - ε【9】。
F. Monotonicity and submodularity properties in GAEIM
分析算法的时间复杂度时考虑三个因素:节点特征学习、候选种子节点选择和种子节点选择。节点特征学习:若Node2vec中行走序列的长度为ll,则每个节点采样的序列数量为bb,模型中出现的节点特征的嵌入维数为dd。 Node2vec采样部分的复杂度为nnllbb,( ) () log O nlb n ∗ 为训练部分的复杂度。对于图注意力网络,时间复杂度为 ( ) 22 22 O nd nd n ++ 。总复杂度为 ( ) ( ) () () 22 2 2 log 1 O nd nd n d nlb n + + ++ +。候选种子节点选择:二阶邻居节点搜索的时间复杂度为 ( ) 2 O ng ,gg 的值反映了网络中邻居节点的平均数量。强相关节点的计算复杂度为( ) 2 O ng 。对节点频率进行排序以选择潜在种子节点的复杂度为 ( ) () log On n 级。整体时间复杂度为 ( ) () 2 2 log O ng n n +。种子节点选择:重新计算影响力扩散程度平均需要的节点数为t,因此如果每轮选择种子节点时都是tt,则kk为实际选择为种子节点的节点数。时间复杂度为 () () 2, , O kt g g kg ++ 。假设图注意力网络训练时的迭代次数为NN,在去除低阶复杂度的同时将上述部分的事件复杂度相加,整个算法的时间复杂度为 ( ) () 22 O N nd n d + 时间复杂度。图注意力网络是主要找到算法时间成本的地方。
IV. EXPERIMENTAL
A. Benchmark Dataset
本研究使用四个真实数据集来检验 GAEIM 传播其影响的能力。这四个数据集的具体数据统计如表3所示,其中平均节点度缩写为Avg.N.deg,最大度缩写为Max。 deg,聚类系数缩写为CC。

B. Benchmark Method
本文的比较方法如下:
度:采用以度大小为中心的基本启发式算法,通过选择度数最大的节点来识别最有影响力的节点。 S
D[28]:与度数类似,这种启发式方法使用度数大小作为关键因素,但方法不同。该算法选择度数最高的节点添加到种子节点,同时将其邻居节点的度数减一。
Pagerank[29]:Google 著名的网页排名算法,根据网页之间的超链接评估页面重要性。它还可以衡量网络图节点的重要性,并利用启发式概念来识别最具影响力的最佳节点集。
CoFIM:使用基于社区结构的启发式方法,通过 gg(SS) = NN(SS) + γγ|NNNN(SS)| 计算节点集的影响程度,其中γγ是超参数,NN(SS)表示节点集S的邻居节点的数量,NNNN(SS)表示节点集S的邻居节点所属的社区的数量。
DeepIM:该算法首先使用图嵌入技术学习节点的特征表示,然后通过计算节点的单位点的乘积来衡量节点的相似度。在使用统计频率最高的k个节点作为种子节点之前,选择距离每个节点最近的前r个节点进行统计。
C. Evaluation Metrics & Parameter Settings
指标:影响传播是我们在实验中衡量 GAEIM 性能的方式。由于GAEIM中学习节点特征表示部分需要在GPU上运行,而其他算法则在CPU上运行,因此很难比较两者的时间效率,因此不进行比较。解决影响传播问题是一个 NP 困难计算。 [28]因此,为了估计影响传播程度的值,通常的做法是进行蒙特卡罗模拟。在本实验中,我们首先使用算法计算种子节点集S。然后,我们进行10,000次独立级联模型模拟,以确定影响扩散程度


参数:GAEIM的所有重要超参数如表IV所示。其他比较方法中需要使用的超参数参考相应论文中使用的参数值。表 V 显示了实验中使用的每个数据集的强相关节点参数 r 的值。
D. Experimental results and analysis
使用传播概率为 p=0.1 的独立级联模型并选择 50 个种子节点,图 3 说明了五种算法如何在四个数据集上传播其影响

或者为每个数据集选择的种子节点集,GAEIM 本质上实现了最大的影响力传播。 CoFIM方法同样实现了高影响力传播程度。其他三种算法,Degree、SD 和 Pagerank,只能在数据集的一部分上取得良好的结果。在所有算法中,Degree 算法的种子节点对数据集的影响传播最弱。由于Degree算法使用度大小来寻找种子节点,这也表明仅依靠单一度中心性特征来寻找种子节点是不够有效的,需要更高效的算法来有效地发现种子节点。此外,GAEIM对种子节点的成功识别凸显了该算法的准确性。通过对上述四个数据集中不同算法的性能分析,首先证明了GAEIM的有效性。本文图神经网络学习到的较为复杂的图拓扑可以有效帮助挖掘最具影响力的节点,而种子节点选择策略可以有效避免重叠影响的问题。
NetHEPT 数据集比其他四个数据集大得多。 Degree、SD 和 PageRank 的影响力传播明显比 DeepIM、CoFIM 和 GAEIM 差。当种子节点为50时,GAEIM的影响力扩散更大比 CoFIM 的种子节点数在 15 到 35 个之间,GAEIM 比 CoFIM 更快,实现更大的影响力传递。
在 NetScience 数据集上,相同的 Degree、SD 和 Pagerank 的影响力传播比 CoFIM、DeepIM 和 GAEIM 更小。由于GAEIM可以通过图神经网络学习更复杂的图拓扑,因此与CoFIM和DeepIM相比,影响力传播更优越。
在Cora数据集上,各算法得到的影响力分布相差不大,特别是当种子节点集大小为1、5、10时,这些算法的影响力分布基本重合,说明在Cora中。数据集最有影响力的节点是度数最高的节点。然而,当种子节点数量增长时,当集合大小超过10时,GAEIM获得的影响力扩散开始与其他算法拉开小差距,并保持到最后。
在 Citeseer 数据集上,这些算法之间开始显现出一些差距。最明显的是学位。当每组种子数量在 20 到 50 之间时,影响力扩散程度逐渐弱于其他算法,并呈现增加趋势。当种子节点为 50 时,GAEIM 和 Degree 的影响力分布有 13% 的差异。这说明,在选择种子节点时,度数最高的节点并不总是最好的节点。
V. CONCLUSION
为了解决社交网络中影响力最大化的问题,我们建议使用 GAEIM 作为解决方案。为了增强算法的有效性并更深入地理解复杂的图拓扑,本文旨在进一步探索,我们使用Node2Vec来学习浅层图结构,然后通过图注意力机制处理节点特征,以进一步学习更深层次的图拓扑。为了选择最佳种子,使用启发式方法来查明影响最大的节点,从而缓解了影响重叠问题,并且所提出的方法保证了 IM 问题的近似最优解。实验中使用各种类型的真实数据来比较GAEIM和比较方法。结果表明,GAEIM 在影响传播和算法效率方面优于其他方法。未来的研究有望将所建议的方法的应用扩展到具有各种节点和连接的网络。为了识别最具影响力的用户并实现最大的影响力传播,我们还可以研究社交网络内特定用户之间的关系数据。















 770
770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









