







 本文提出了一种新的文本到图像合成方法,通过门控跨词视觉注意力单元和细化机制,解决了传统方法在处理复杂文本和图像细节上的问题。实验结果表明,新方法在COCO和CUB数据集上在多样性和现实性方面有所提升,且能生成更符合文本描述的高分辨率图像。
本文提出了一种新的文本到图像合成方法,通过门控跨词视觉注意力单元和细化机制,解决了传统方法在处理复杂文本和图像细节上的问题。实验结果表明,新方法在COCO和CUB数据集上在多样性和现实性方面有所提升,且能生成更符合文本描述的高分辨率图像。
1 研究目的
在研究中,作者发现了以下问题:
传统的Txt2Img合成方法在处理复杂的文本描述时,往往难以准确捕捉和表达文本中的关键信息,导致生成的图像与文本描述存在较大的差异。此外,这些方法在生成图像的精细细节方面也存在不足,使得生成的图像质量不高。
为了解决上面的问题,作者提出了以下解决办法:
提出了门控跨词视觉注意力单元(GCAU)。通过引入跨词视觉注意力机制,该方法能够更准确地理解文本描述,并生成与文本内容高度一致的图像。同时,门控细化机制能够进一步优化生成的图像,提高图像的精细度和逼真度。
——首先,输入句子中的每个单词都提供了描述图像内容的不同信息。应考虑图像信息以确定每个单词的重要性,还应考虑单词信息来确定图像每个子区域的重要性。
为此,我们提出了一种跨词视觉注意机制。它通过视觉到单词 (V2W) 注意力专注于相关单词,并通过单词到视觉 (W2V) 注意力专注于相关图像子区域来选择重要的单词。
——其次,如果在图像细化的多个阶段使用相同的词表示,该过程可能会变得无效。
为此,我们提出了一种门控细化机制,基于在多个图像细化阶段更新的图像表示,从更新的单词表示中动态选择重要的单词信息来细化生成的图像。
2 结构框架
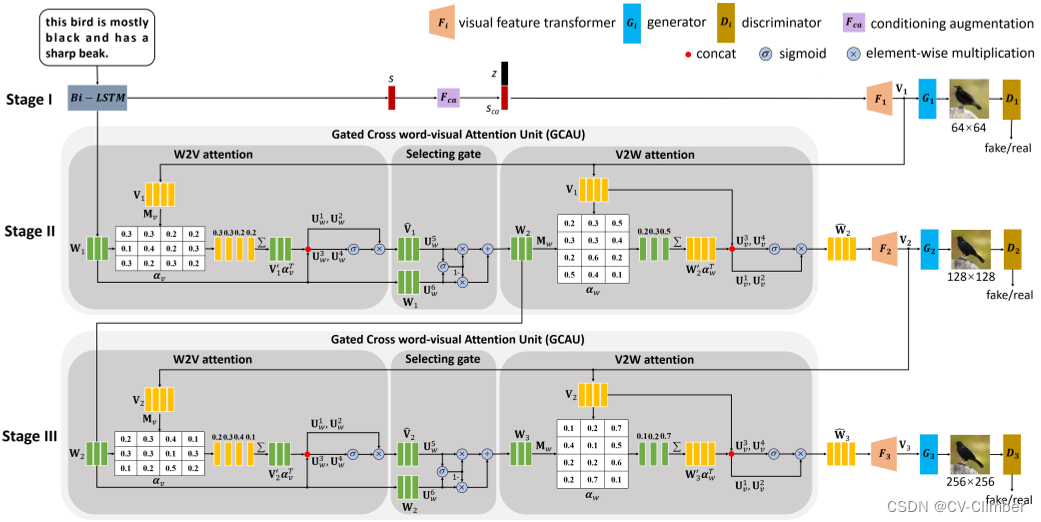
基于多级 GAN 的 Txt2Img 合成框架,来构建门控跨词视觉注意力单元。提出的门控跨词视觉注意单元,包含W2V注意、V2W注意和选择门,用于第二阶段和第三阶段。
首先生成低分辨率的初始图像,然后通过几个阶段进行细化,得到最终的高分辨率合成图像。
Vi 和 Wi 分别是视觉特征和单词特征
Fca 表示将句子向量转换为条件向量的条件增强
z ∼ N (0, 1) 是一个随机噪声向量
Fi 表示第 i 阶段的视觉特征转换器
Gi 表示第 i 阶段的生成器
Di 表示第 i 阶段的鉴别器
- 在第一阶段中,输入句子文本经过Bi-LSTM文本编码器对输入文本描述进行编码,得到词特征W1和句子特征s
- 其中句子特征经过Fca将句子特征转换为条件向量的条件增强,然后将得到的Sca
- 再将Sca和噪声z进行结合,送到视觉特征转换器F1中,经过F1得到视觉特征V1
- V1被送到G1中生成一个低分辨率的初始图像,在经过D1鉴别器进行鉴别
- V1还被送到第二阶段中的GCAU中,经过 W2V 和 V2W 两个单元
2.1 W2V注意

- 首先,它通过 1×1 卷积算子 Mv (·) 将视觉特征Vi从 视觉语义空间 转换为 单词语义空间,以获得映射的视觉特征矩阵
,
- 然后,计算映射的视
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









