







 文章介绍了一种名为DenseDiffusion的新方法,通过在预训练的文本到图像模型基础上引入复杂调制策略,解决现有模型在密集字幕下合成图像时的布局控制问题。方法通过分析注意力图并动态调节注意力,以提高图像生成的保真度和布局准确性。
文章介绍了一种名为DenseDiffusion的新方法,通过在预训练的文本到图像模型基础上引入复杂调制策略,解决现有模型在密集字幕下合成图像时的布局控制问题。方法通过分析注意力图并动态调节注意力,以提高图像生成的保真度和布局准确性。
1 研究目的
该文献的研究目的主要是:
探讨一种更为广泛的调制方法,通过设计多个正则化项来优化图像合成过程中的空间控制。论文的大致思想是,在现有的基于数据驱动的图像合成系统基础上,通过引入更复杂的调制策略,实现对文本描述和空间控制更为精确的图像合成。
在研究中,作者发现了以下问题:
现有的文本到图像扩散模型很难在给定密集字幕的情况下合成逼真的图像,并且倾向于省略或混合不同对象的视觉特征。其中每个文本提示为特定图像区域提供详细的描述,用户很难仅使用文本提示精确控制生成图像的场景布局。有些模型提供了对图像布局的控制,但它们通常需要每次重新训练新的控制类型或增加推理时间。
为了解决这些问题,作者提出了一种新的方法:
提出了 DenseDiffusion,这是一种无需训练的方法,它采用预训练的文本到图像模型来处理这种密集的字幕,同时提供对场景布局的控制。
- 首先分析了生成的图像布局与预训练模型的中间注意图之间的关系,以表明生成的图像的布局与自我注意和交叉注意图显著相关,但专注于空间控制而不是图像编辑的图像合成。
- 接下来,基于这一观察,动态根据布局条件调节中间注意力图,开发了一种注意力调制方法,根据布局引导对象出现在特定区域。不需要额外的微调或数据集
- 进一步提出考虑原始注意力分数的值范围并根据每个片段的面积调整调制程度。
该方法基于自注意力和交叉注意力映射,通过实时调制中间注意力映射来适应布局条件。
此外,作者还考虑了原始注意力得分的值范围,并根据每个区域的面积调整调制的程度。
这种方法旨在更准确地反映文本和布局条件,从而提高图像合成的质量和灵活性
2 方法介绍
2.1 前期介绍
2.1.1 注意力分数分析
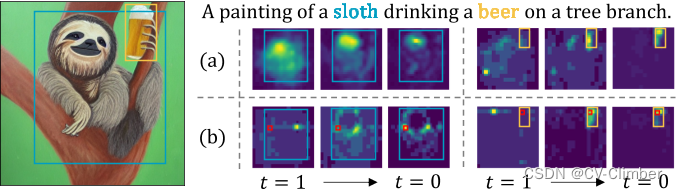
通过分析稳定扩散产生的16 × 16注意图来展示类似的趋势。
随着图像生成的进行,注意力图往往类似于上面的图像布局。
- 在 (a) 中,可视化了“sloth”和“beer”的交叉注意力图。感兴趣的对象用蓝色和黄色的边界框概述。
- 在 (b) 中,展示了自注意力层中红框中标记的标记键注意力图。
- 由于时间步 t 接近零,属于同一对象的标记更仔细地通信,影响图像布局。
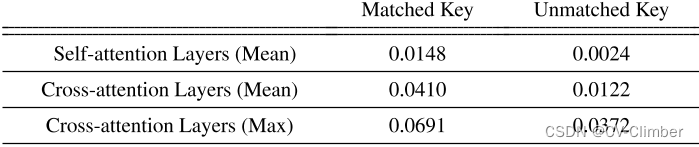
匹配键和未匹配键的注意力分数分析。首先,YOLOv7检测对象边界框。
- 在交叉注意力层的上下文中,如果键的文本标记与框的类标签匹配,定义一个匹配键。
- 在自注意力层中,框内的图像标记有资格作为匹配的键。
- 在这两个层中,匹配的键始终比不匹配的键具有更高的平均值和最大注意力值;属于同一对象的查询键对在生成过程中往往具有更大的分数。
为什么要进行匹配键和为匹配键的注意力分数分析?
其目的主要是为了探究和解释在自注意力层和交叉注意力层
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









