







1,机器学习概述
what?机器学习是从数据中自动分析获得规律并利用规律对未知数据进行预测。
why?解放生产力,解决专业问题,提供社会便利.
aim:让机器学习程序替换手动的步骤,减少企业的成本也提高企业的效率。
2,数据集的结构
机器学习的数据:文件CSV。
工具:pandas,numpy
可用数据集:kaggle,scikit-learn,UCI
结构:特征值+目标值(有些数据集可以没有目标值)
3,数据的特征工程
缺失值,数据转换,重复值
特征处理工具:pandas,sklearn
特征工程:是将原始数据转换为更好的代表预测模型的潜在问题的特征的过程,从而提高了对未知数据的预测准确性。
意义:直接影响模型效果
scikit-learn库:机器学习工具,丰富的API(分类,回归,聚类,降维,模型选择,特征工程)
特征抽取:将文本等数据进行特征值化(为了计算机更好理解数据)
API:sklearn.feature_extraction
字典特征抽取:对字典数据进行特征值化
类:sklearn.feature_extraction.DictVectorizer
文本特征抽取:对文本数据进行特征值化
类:sklearn.feature_extraction.text.CountVectorizer
归一化:通过对原始数据进行变换把数据映射到(默认【0,1】之间)
 sklearn归一化API:sklearn.preprocessing.MinMaxScaler
sklearn归一化API:sklearn.preprocessing.MinMaxScaler
目的:使得某一个特征对最终结果不会造成干扰时就需要归一化(即把所有特征综合到一起评估)
问题:由于异常点的介入可能导致最大最小值发生变化,所以这种方法鲁棒性较差,只适合传统精确小数据场景。于是标准化应运而生。
标准化:通过对原始数据进行变换把数据变换到均值为0,方差为1 的范围内
 对于归一化来讲,如果出现异常点,影响了最大最小值,那么结果显然会发生改变。
对于归一化来讲,如果出现异常点,影响了最大最小值,那么结果显然会发生改变。
对于标准化来讲,如果出现异常点由于具有一定数据量,少量的异常点对于平均值的影响并不大,从而方差改变较小
标准差API:sklearn.preprocessing.StandardScaler
4,数据的类型
数值型数据:标准缩放,1)归一化,2)标准化,3)缺失值
如何处理缺失值?删除和插补(通过平均值或者中位数填补)
缺失值API:from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy=“median”)
类别型数据:one-hot编码
时间类型:时间的切分
数据降维:(维度即为特征数量)
1)特征选择:从所有特征中选择部分特征作为训练集特征
主要方法:Filter(过滤式):Variance Threshold
Embedded(嵌入式):正则化,决策树
Wrapper(包裹式)
特征选择API:sklearn.feature_selection.VarianceThreshold
2)主成分分析PCA
API:sklearn.decomposition
PCA:一种分析,简化数据集的技术(数据特征之间通常是相关的)
目的:使数据压缩,尽可能降低原数据的维数,损失少量信息
作用:可以削减回归分析或者聚类分析中特征的数量
5,机器学习算法基础
1)sklearn数据集与估计器
1,数据集划分
一般的数据集会划分为两部分:
训练集:用于构建模型
测试集:用于评估模型是否有效
一般有7-3分,8-2分,最科学的划分是训练集占75%,测试集占25%。
2,sklearn数据集接口介绍
API:sklearn.model_selection.train_test_split

3,sklearn分类数据集
sklearn.datasets.load_iris() # 加载并返回鸢尾花数据集
sklearn.datasets.load_digits() # 加载并返回数字数据集

4,sklearn回归数据集
 5,转换器与预估器
5,转换器与预估器
fit_transform():输入数据直接进行转换
fit():输入数据,但不做事情,计算平均值,方差等
transform():进行数据的转换

2)分类算法-k近邻算法
分类算法的判定依据:离散型数据
数据需要做标准化
k取值:1,3,5,7
knn简介
3)k-近邻算法实例
算法API:sklearn.neighbors.kneighbors_graph
# coding: gbk
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
import pandas as pd
def knncls():
"""
K-近邻预测用户签到位置
:return:
"""
# 读取数据
data = pd.read_csv("B:/PycharmProjects/PythonProject/机器学习/data/FBlocation/train.csv")
print(data.head(10))
# 处理数据
# 1,缩小数据,查询数据
data = data.query("x > 1.0 & x < 1.25 & y > 2.5 & y < 2.75")
# 处理时间的数据
time_value = pd.to_datetime(data['time'], unit='s') # 将时间戳转化为时间标准形式
print(time_value)
# 把日期格式转化为字典格式
time_value = pd.DatetimeIndex(time_value)
# 构造一些特征
data['day'] = time_value.day
data['hour'] = time_value.hour
data['weekday'] = time_value.weekday
# 把时间戳特征删除
data.drop(['time'], axis=1)
print(data)
# 把签到数量少于n个目标位置删除
place_count = data.groupby('place_id').count()
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data['place_id'].isin(tf.place_id)]
# 取出数据当中的特征值和目标值
y = data['place_id']
x = data.drop(['place_id'], axis=1)
# 进行数据的分割训练集合测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 特征工程(标准化)
std = StandardScaler() # 实例化
# 对测试集和训练集的特征值进行标准化
x_train = std.fit_transform(x_train)
x_test = std.fit_transform(x_test)
# 进行算法流程
knn = KNeighborsClassifier(n_neighbors=5) # 实例化
knn.fit(x_train,y_train)
# 得出预测结果
y_predict = knn.predict(x_test)
print("预测的目标签到位置:", y_predict)
# 得出准确率
print("预测的准确率:", knn.score(x_test, y_test))
return None
if __name__ == "__main__":
knncls()
4)分类模型的评估

5)分类算法-朴素贝叶斯算法
概率与贝叶斯原理
朴素贝叶斯:特征独立



6)朴素贝叶斯算法实例
朴素贝叶斯API:sklearn.naive_bayes.MultinomialNB
# coding: gbk
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
import pandas as pd
def naviebayes():
"""
朴素贝叶斯进行文本分类
:return:
"""
news = fetch_20newsgroups(subset='all')
# 进行数据分割
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25)
# 对数据集进行特征抽取
tf = TfidfVectorizer()
# 以训练集当中的词列表进行每篇文章重要性统计['a','b','c','d']
x_train = tf.fit_transform(x_train)
print(tf.get_feature_names())
x_test = tf.transform(x_test)
# 进行朴素贝叶斯算法预测
mlt = MultinomialNB(alpha=1.0) # alpha是拉普拉斯平滑系数
print(x_train.toarray())
mlt.fit(x_train,y_train)
y_predict = mlt.predict(x_test)
print("预测的文章类别为: ", y_predict)
print("准确率为: ",mlt.score(x_test, y_test))
return None
if __name__ == "__main__":
naviebayes()
总结:优点:发源于古典数学,有稳定的分类效果。
对缺失数据不太敏感,算法简单,常用于文本分类。
分类准确度高,速度快
缺点:
由于使用样本属性独立性假设,所以如果样本属性有关联时效果不好。
朴素贝叶斯训练集如果误差大,结果肯定不好。不需要调参
7)模型的选择与调优
准确率,精确率,召回率
分类模型评估API:sklearn.metrics.classification_report
1,交叉验证:为了让被评估的模型更加准确可信

2,网格搜索:为了调超参数
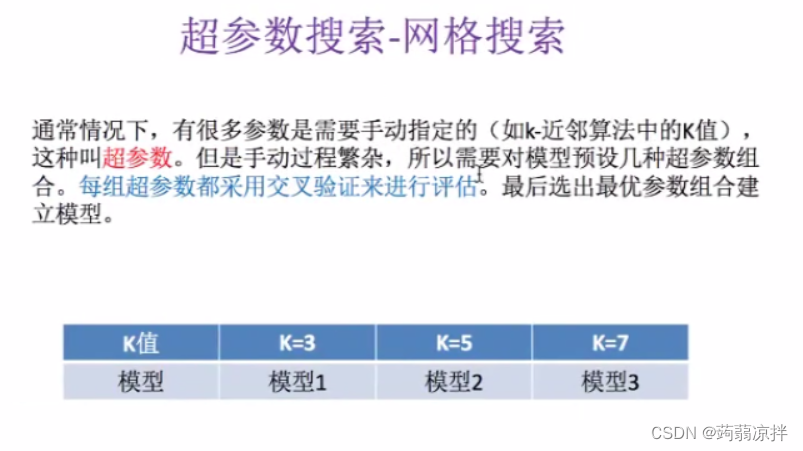 网格搜素API:sklearn.model_selection.GridSearchCV
网格搜素API:sklearn.model_selection.GridSearchCV
8)决策树与随机森林
1,认识决策树
决策树算法是一种监督学习算法,利用分类的思想,来根据数据的特征构建数模型,从而达到数据的筛选,打标签,决策的目标决策树算法
2,信息论基础-银行贷款分析
信息论基础
信息增益

3,决策树的生成与泰坦尼克号乘客生存分类
# coding: gbk
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
import pandas as pd
from sklearn.tree import DecisionTreeClassifier, export_graphviz
def decision():
"""
决策树对泰坦尼克号进行预测生死
:return:
"""
# 获取数据
titan = pd.read_csv("B:/PycharmProjects/PythonProject/机器学习/data/titanic/train.csv")
# 处理数据,找出特征值和目标值
x = titan[['Pclass', 'Age', 'Sex']]
y = titan[['Survived']]
# 缺失值处理
x['Age'].fillna(x['Age'].mean(), inplace=True) # 用平均值填补
# 分割数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 进行处理(特征工程)特征->类别->one-hot编码
dict = DictVectorizer(sparse=False)
x_train = dict.fit_transform(x_train.to_dict(orient="records"))
print(dict.get_feature_names())
print(x_test)
x_test = dict.transform(x_test.to_dict(orient="records"))
print(x_train)
# 用决策树进行预测
dec = DecisionTreeClassifier(max_depth=8)
dec.fit(x_train,y_train)
# 预测准确率
print("预测准确率:", dec.score(x_test, y_test))
# 导出决策树的结构
export_graphviz(dec, out_file="./tree.dot", feature_names=['年龄', 'Pclass=1st', '女性', '男性'])
return None
if __name__ == "__main__":
decision()
 4,集成学习方法–随机森林
4,集成学习方法–随机森林
1)什么是随机森林
集成学习方法:通过建立几个模型组合的来解决单一预测问题,它的工作原理是生成多个分类器或模型,各自独立的学习和做出预测。这些预测最后结合成单预测,因此优于任何一个单分类做出的预测
随机森林:包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定
2)随机森林的过程和优势
随机森林
3)泰坦尼克号乘客生存分类分析
# 随机森林进行预测(超参数调优)
rf = RandomForestClassifier()
param = {"n_estimators": [120, 200, 300, 500, 800, 1200], "max_depth": [5, 8, 15, 20]}
# 网格搜索与交叉验证
gc = GridSearchCV(rf, param_grid=param, cv=2)
gc.fit(x_train,y_train)
print("准确率:", gc.score(x_test,y_test))
print("查看选择的参数模型:", gc.best_params_)















 361
361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









