







(八)StackGAN-v1 论文笔记与实战
一、背景及解决的问题
由文本生成高质量的图像是计算机视觉中一个极具挑战性的问题,然而,训练GAN从文本描述中生成高分辨率的真实感图像是非常困难的。简单地在最先进的GAN模型中添加更多的上采样层来生成高分辨率(例如256×256)图像通常会导致训练不稳定并产生无意义的输出。通过GAN生成高分辨率图像的主要困难在于自然图像分布和隐含模型分布在高维像素空间中可能不重叠,随着图像分辨率的提高,这个问题更加严重。
为了解决这个问题,stackGAN-v1提出了分两个阶段生成图像的模型。
第一阶段:在给定文本描述的基础上,绘制物体的原始形状和基本颜色,并从随机噪声矢量中绘制背景布局,生成低分辨率图像。
第二阶段:它纠正了在第一阶段的低分辨率图像中存在缺陷,并通过再次读取文本描述来完成对象的细节,从而生成高分辨率照片真实感图像。
通过对第一阶段结果和文本的再约束,第二阶段GAN学习捕捉第一阶段GAN省略的文本信息,并为对象绘制更多细节。由粗略排列的低分辨率图像生成的模型分布与真实图像分布相交的概率更大。这就是第二阶段GAN能够产生更好的高分辨率图像的根本原因。
二、Conditioning Augmentation(条件增强)

如上图所示,文本描述 t 首先由编码器编码,产生文本嵌入
φ
t
\varphi _t
φt。在之前的工作中,文本嵌入被非线性转换以生成作为生成器输入的条件潜在变量。然而,文本嵌入的潜在空间通常是高维的(>100维)。在数据量有限的情况下,这通常会导致潜在数据流形的不连续性,这是不可取的。为了解决这个问题,引入了条件增强技术来产生额外的条件变量
c
^
\hat c
c^, 这里的条件变量不是固定的,而是从独立的高斯分布
N
(
μ
(
φ
t
)
,
∑
(
φ
t
)
)
N (\mu(\varphi_t), \sum(\varphi_t))
N(μ(φt),∑(φt)) 中随机抽取隐变量
c
^
\hat c
c^ ,其中平均值
μ
(
φ
t
)
\mu(\varphi_t)
μ(φt) 和对角协方差矩阵
∑
(
φ
t
)
)
\sum(\varphi_t))
∑(φt)) 是文本embedding
φ
t
\varphi _t
φt 的函数。条件增强在少量图像-文本对的情况下产生更多的训练数据对,并有助于对条件流形的小扰动并且具有鲁棒性。为了进一步加强条件流形上的光滑性,避免过度拟合,作者在训练过程中为生成器的目标添加了以下正则化项:
D K L ( N ( μ ( φ t ) , ∑ ( φ t ) ) ) ∣ ∣ N ( 0 , I ) D_{KL}(N(\mu(\varphi_t), \sum(\varphi_t))) || N(0, I) DKL(N(μ(φt),∑(φt)))∣∣N(0,I)
不难看出,该正则项就是标准高斯分布与条件高斯分布之间的KL距离, 添加这种具有随机性的正则项,有利于模型对于同一句话可以产生满足条件约束但形状或姿势不同的图像,实现生成图像的多样性。
三、实现过程
(一)Stage-I GAN
第一个阶段是交替地最大化等式 (3) 中的
L
D
0
L_{D_0}
LD0 和最小化等式 (4) 中的
L
G
0
L_{G_0}
LG0:
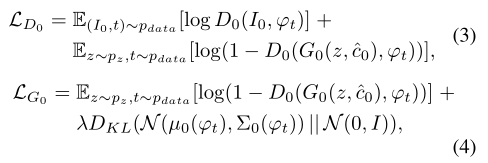
其中,
I
0
I_0
I0 表示真实图像,
λ
\lambda
λ = 1
模型结构:
对于生成器
G
0
G_0
G0 , 为了获得条件变量
c
^
\hat c
c^ ,必须先把
φ
t
\varphi_t
φt 输入到一个完全连接层中以产生
μ
0
\mu_0
μ0 和
σ
0
\sigma_0
σ0(其中,
σ
0
\sigma_0
σ0是
∑
0
\sum_0
∑0 的对角线的值),从而可以构成前面提到的高斯分布:
N
(
μ
0
(
φ
t
)
,
∑
0
(
φ
t
)
)
N (\mu_0(\varphi_t), \sum_0(\varphi_t))
N(μ0(φt),∑0(φt)) ,然后从该高斯分布中随机取样
c
^
0
\hat c_0
c^0,最终的条件向量
c
^
0
\hat c_0
c^0 的计算公式为:
c
^
0
\hat c_0
c^0 =
μ
0
\mu_0
μ0 +
σ
0
⊙
ϵ
\sigma_0 ⊙\epsilon
σ0⊙ϵ,其中,
⊙
⊙
⊙ 表示逐元素乘积,
ϵ
\epsilon
ϵ 表示从
N
(
0
,
I
)
N(0, I)
N(0,I) 中随机抽取的一个随机数。然后,
c
^
0
\hat c_0
c^0 和一个噪声向量 z 通过一系列的up-sampling blocks Concatenate 起来。
对于判别器
D
0
D_0
D0, the text embedding
φ
t
\varphi_t
φt 首先通过完全连接层压缩到
N
d
N_d
Nd 维,然后再复制形成
M
d
∗
M
d
∗
N
d
M_d * M_d * N_d
Md∗Md∗Nd 的张量,与此同时,将图像送入一系列的下采样块,直到它是
M
d
∗
M
d
M_d * M_d
Md∗Md 的空间维度,然后将图像的filter map 与 text embedding
φ
t
\varphi_t
φt 的通道维度连接起来,得到的张量被进一步送入1×1卷积层,以共同学习图像和文本的特征。最后,使用一个具有一个节点的完全连接层来生成决策得分。
(二)Stage-II GAN
根据生成的低分辨率的结果
s
0
s_0
s0 =
G
0
(
z
,
c
^
0
)
G_0(z,\hat c_0)
G0(z,c^0) 和高斯条件变量
c
^
0
\hat c_0
c^0,判别器
D
D
D 和
G
G
G 在第二阶段交替地最大化
L
D
L_D
LD 和最小化
L
G
L_G
LG :
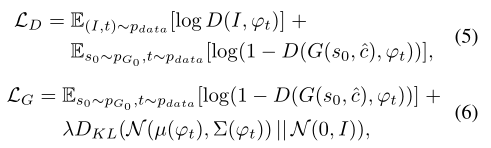
也即把第一阶段的 z 换成
s
0
s_0
s0 即可。本阶段使用的
c
^
0
\hat c_0
c^0 和第一阶段的
c
^
0
\hat c_0
c^0 共享相同的预训练text encoder, generating the same text embedding
φ
t
\varphi_t
φt,然而,Stage I 和Stage II 条件增强具有不同的全连接层,用于生成不同的平均值和标准差。以这种方式,阶段II GAN学习捕捉由阶段I GAN忽略的text embedding中的有用信息。
模型结构:
我们把 Stage-II 的generator 设计成带有残差块的 encoder-decoder network,与前一阶段类似,the text embeeding
φ
t
\varphi_t
φt 是用来生成
N
g
N_g
Ng 维的条件向量
c
^
\hat c
c^ ,然后复制为
M
g
∗
M
g
∗
N
g
M_g * M_g * N_g
Mg∗Mg∗Ng 的tensor, 与此同时,Stage-I 产生的
s
0
s_0
s0 被送入多个下采样块,直到变为
M
g
∗
M
g
M_g * M_g
Mg∗Mg,然后,The image features and the text features are concatenated along the channel dimension.
对于判别器,它的结构类似于第一阶段的判别器,只需要额外的下采样块,因为该级的图像尺寸较大。为了显式地执行GAN来学习图像和条件文本之间更好的对齐,我们采用了Reed等人提出的匹配感知鉴别器,而不是使用vanilla鉴别器。对于这两个阶段来说,在训练过程中,鉴别器将真实图像及其对应的文本描述作为正样本对,而负样本对由两组组成。第一种是嵌入不匹配文本的真实图像,第二种是具有相应文本嵌入的合成图像。
四、实现细节
上采样块包括最近邻上采样和3×3步长为1的卷积。批量标准化和ReLU激活应用在除最后一个之外的每个卷积之后。剩余的块由3×3步长为1的卷积,批量标准化和ReLU组成。在128×128 Stack-GAN模型中使用两个残差块,而在256×256模型中使用四个残余块。 下采样块由4×4步长为2的卷积,批量归一化和LeakyReLU组成,除了第一个没有批量标准化,其他都使用了批量标准化。默认情况下, N g N_g Ng = 128, N z N_z Nz = 100, M g M_g Mg = 16, M d M_d Md = 4, N d N_d Nd = 128 ,对于训练的过程,作者首先用六百个周期迭代训练第一阶段GAN的 D 0 D_0 D0 和 G 0 G_0 G0 。然后,用另外六百个周期迭代地训练第二阶段 GAN 的 D 和 G ,来修正第一层GAN的结果。所有网络都使用 Adam 进行训练,求解器的批量大小为64,初始学习率为0.0002。学习率每100个周期衰减到先前值的1/2。
五、完整代码
参数初始化:
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import random
import os
import torchvision
parser = argparse.ArgumentParser()
parser.add_argument('--text_dimension', type = int, default=1024, help='the dimension of text embedding')
parser.add_argument('--condition_dim', type = int, default=128, help='the dimension of condition')
parser.add_argument('--gf_dim', type = int, default=128)
parser.add_argument('--df_dim', type = int, default=64)
parser.add_argument('--z_dim', type = int, default=100)
parser.add_argument('--residual_num', type = int, default = 4, help='the number of residual block')
parser.add_argument('--lr', type = float, default=0.0002)
parser.add_argument('--b1', type = float, default=0.5)
parser.add_argument('--b2', type = float, default=0.999)
parser.add_argument('--dataDir', default='data')
parser.add_argument('--s1_start_epoch', type = int, default=1) # 按情况更改
parser.add_argument('--s2_start_epoch', type = int, default=20)# 情况更改
parser.add_argument('--num_epochs', type = int, default=200)
parser.add_argument('--batch_size', type = int, default=64)
opt = parser.parse_args(args = [])
random.seed(999)
torch.manual_seed(999)
网络结构:
'''网络模型'''
def conv3x3(in_fea, out_fea, stride = 1):
"3x3 convolution with padding"
return nn.Conv2d(in_fea, out_fea, kernel_size=3, stride=stride,padding=1,bias=False)
# Upsale the spatial size by a factor of 2
def upBlock(in_fea, out_fea):
block = nn.Sequential(
nn.Upsample(scale_factor=2, mode='nearest'),
conv3x3(in_fea,out_fea),
nn.BatchNorm2d(out_fea),
nn.ReLU(True)
)
return block
# residual block
class ResBlock(nn.Module):
def __init__(self, channel_num):
super(ResBlock, self).__init__()
self.block = nn.Sequential(
conv3x3(channel_num,channel_num),
nn.BatchNorm2d(channel_num),
nn.ReLU(True),
conv3x3(channel_num,channel_num),
nn.BatchNorm2d(channel_num)
)
self.relu = nn.ReLU(True)
def forward(self, x):
residual = x
out = self.block(x)
out = out + residual
out = self.relu(out)
return out
class CA_NET(nn.Module):
# the Condition Augumentation(条件增强)
# some code is modified from vae examples
# (https://github.com/pytorch/examples/blob/master/vae/main.py)
def __init__(self):
super(CA_NET, self).__init__()
self.t_dim = opt.text_dimension
self.c_dim = opt.condition_dim
self.fc = nn.Linear(self.t_dim, self.c_dim*2, bias=False)
self.relu = nn.ReLU(True)
def encode(self, text_embedding):
x = self.relu(self.fc(text_embedding))
mu = x[:, :self.c_dim] # 前面c_dim用作均值输出
log_var = x[:, self.c_dim:] # 后面c_dim用作log方差输出
return mu, log_var
def reparameter(self, mu, log_var):
std = torch.exp(0.5*log_var)
# eps = torch.randn(*std.shape, device = device) # !!!!!!!!!!!!!!!!!!!!!
eps = torch.cuda.FloatTensor(std.size()).normal_()
return mu + torch.mul(std, eps)
def forward(self, text_embedding):
mu, log_var = self.encode(text_embedding)
c_code = self.reparameter(mu, log_var)
return c_code, mu, log_var
class D_GET_LOGITS(nn.Module):
'''这部分的作用是:真正的最后的输出,输入是两部分,一部分是Condition_dim = (b, 128, 4, 4),
另一部分是第一阶段生成的image,reshape成(b, 512, 4, 4), 然后把这两部分在第二个维度上cancate起来,作为输入'''
def __init__(self, ndf, nc):
super(D_GET_LOGITS, self).__init__()
self.df_dim = ndf # 默认 64
self.c_dim = nc # 默认 128
self.out_logits = nn.Sequential( # 输入 [b, 512+128, 4, 4]
conv3x3(ndf * 8 + nc, ndf * 8), # --> [b, 512, 4, 4]
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace = True),
nn.Conv2d(ndf * 8, 1, kernel_size=4, stride=4), # --> [b, 1, 1, 1]
nn.Sigmoid()
)
def forward(self, img_code, c_code):
# conditioning output
c_code = c_code.view(-1, self.c_dim, 1, 1)
c_code = c_code.repeat(1, 1, 4, 4)
# state size (ngf+egf) x 4 x 4
img_c_code = torch.cat((img_code, c_code), dim = 1)
output = self.out_logits(img_c_code)
return output.view(-1)
# ############# Networks for stageI GAN #############
class STAGE1_G(nn.Module):
def __init__(self):
super(STAGE1_G, self).__init__()
self.gf_dim = opt.gf_dim # 默认 128
self.c_dim = opt.condition_dim # 默认 128
self.z_dim = opt.z_dim # 默认 100
self.define_module()
def define_module(self):
ninput = self.z_dim + self.c_dim
ngf = self.gf_dim
# TEXT.DIMENSION -> GAN.CONDITION_DIM
self.ca_net = CA_NET()
# -> ngf x 4 x 4
self.fc = nn.Sequential(
nn.Linear(ninput, ngf * 4 * 4, bias = False),
nn.BatchNorm1d(ngf * 4 * 4),
nn.ReLU(True)
)
# ngf x 4 x 4 -> ngf/2 x 8 x 8
self.upsample1 = upBlock(ngf, ngf//2)
# -> ngf/4 x 16 x 16
self.upsample2 = upBlock(ngf//2, ngf//4)
# -> ngf/8 x 32 x 32
self.upsample3 = upBlock(ngf//4, ngf//8)
# -> ngf/16 x 64 x 64
self.upsample4 = upBlock(ngf//8, ngf//16)
# -> 3 x 64 x 64
self.img = nn.Sequential(
conv3x3(ngf//16, 3),
nn.Tanh()
)
def forward(self, text_embedding, noise):
c_code, mu, log_var = self.ca_net(text_embedding)
z_c_code = torch.cat((noise, c_code), dim = 1)
img_code = self.fc(z_c_code)
img_code = img_code.view(-1, self.gf_dim, 4, 4) # !!!!千万不要忘记这一步
fake_img = self.upsample1(img_code)
fake_img = self.upsample2(fake_img)
fake_img = self.upsample3(fake_img)
fake_img = self.upsample4(fake_img)
# state size 3 x 64 x 64
fake_img = self.img(fake_img)
return _, fake_img, mu, log_var
class STAGE1_D(nn.Module):
def __init__(self):
super(STAGE1_D,self).__init__()
self.df_dim = opt.df_dim # 默认 64
self.c_dim = opt.condition_dim # 默认 128
self.define_module()
def define_module(self):
ndf, nc = self.df_dim, self.c_dim
# 这部分把image变成-->[b, 512, 4, 4]
self.encode_img = nn.Sequential( # 输入shape [b, 3, 64, 64]
nn.Conv2d(3, ndf, 4, 2, 1, bias = False), # --> [b, 64, 32, 32]
nn.LeakyReLU(0.2, True),
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias = False), # --> [b, 128, 16, 16]
nn.BatchNorm2d(ndf*2),
nn.LeakyReLU(0.2, True),
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias = False), # --> [b, 256, 8, 8]
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, True),
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias = False), # --> [b, 512, 4, 4]
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, True),
)
self.get_cont_logits = D_GET_LOGITS(ndf, nc)
def forward(self, img):
img_code = self.encode_img(img)
return img_code
# ############# Networks for stageII GAN #############
class STAGE2_G(nn.Module):
def __init__(self, STAGE1_G):
super(STAGE2_G, self).__init__()
self.gf_dim = opt.gf_dim
self.c_dim = opt.condition_dim
self.STAGE1_G = STAGE1_G
# fix parameters of stageI GAN
for param in self.STAGE1_G.parameters():
param.requires_grad = False
self.define_module()
def _make_residual_net(self, block, channel_num):
layers = []
for i in range(opt.residual_num):
layers.append(block(channel_num))
return nn.Sequential(*layers)
def define_module(self):
ngf = self.gf_dim # 默认 128
# TEXT.DIMENSION -> GAN.CONDITION_DIM
self.ca_net = CA_NET()
# 这部分的作用就是把(3, 64, 64)的图片 --> 4*ngf x 16 x 16 (512, 16, 16)
self.encoder = nn.Sequential(
conv3x3(3, ngf), # --> [128, 64, 64]
nn.ReLU(True),
nn.Conv2d(ngf, ngf * 2, 4, 2, 1, bias = False), # --> [256, 32, 32]
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
nn.Conv2d(ngf * 2, ngf * 4, 4, 2, 1, bias = False), # --> [512, 16, 16]
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
)
self.hr_joint = nn.Sequential(
conv3x3(self.c_dim + ngf * 4, ngf * 4),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
)
self.residual = self._make_residual_net(ResBlock, ngf * 4)
# 输入 [b, 512, 16, 16]
self.upsample1 = upBlock(ngf * 4, ngf * 2) # --> [b, 256, 32, 32]
self.upsample2 = upBlock(ngf * 2, ngf) # --> [b, 128, 64, 64]
self.upsample3 = upBlock(ngf, ngf//2) # --> [b, 64, 128, 128]
self.upsample4 = upBlock(ngf//2, ngf//4) # --> [b, 32, 256, 256]
self.img = nn.Sequential(
conv3x3(ngf//4, 3), # --> [b, 3, 256, 256]
nn.Tanh()
)
def forward(self, text_embedding, noise):
_, stage1_img, _, _ = self.STAGE1_G(text_embedding, noise)
stage1_img = stage1_img.detach()
encode_img = self.encoder(stage1_img)
c_code, mu, log_var = self.ca_net(text_embedding)
c_code = c_code.view(-1, self.c_dim, 1, 1)
c_code = c_code.repeat(1, 1, 16, 16)
img_c_code = torch.cat((encode_img, c_code), dim = 1)
h_code = self.hr_joint(img_c_code)
h_code = self.residual(h_code)
h_code = self.upsample1(h_code)
h_code = self.upsample2(h_code)
h_code = self.upsample3(h_code)
h_code = self.upsample4(h_code)
fake_img = self.img(h_code)
return stage1_img, fake_img, mu, log_var
class STAGE2_D(nn.Module):
def __init__(self):
super(STAGE2_D, self).__init__()
self.df_dim = opt.df_dim # 默认 64
self.c_dim = opt.condition_dim # 默认 128
self.define_module()
def define_module(self):
ndf, nc = self.df_dim, self.c_dim
self.encode_img = nn.Sequential(
# 输入 [b, 3, 256, 256]
nn.Conv2d(3, ndf, 4, 2, 1, bias = False), # --> [b, 64, 128, 128]
nn.LeakyReLU(0.2, True),
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias = False), # --> [b, 128, 64, 64]
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, True),
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias = False), # --> [b, 256, 32, 32]
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, True),
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias = False), # --> [b, 512, 16, 16]
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, True),
nn.Conv2d(ndf * 8, ndf * 16, 4, 2, 1, bias = False), # --> [b, 1024, 8, 8]
nn.BatchNorm2d(ndf * 16),
nn.LeakyReLU(0.2, True),
nn.Conv2d(ndf * 16, ndf * 32, 4, 2, 1, bias = False), # --> [b, 2048, 4, 4]
nn.BatchNorm2d(ndf * 32),
nn.LeakyReLU(0.2, True),
conv3x3(ndf * 32, ndf * 16), # --> [b, 1024, 4, 4]
nn.BatchNorm2d(ndf * 16),
nn.LeakyReLU(0.2, True),
conv3x3(ndf * 16, ndf * 8), # --> [b, 512, 4, 4]
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, True)
)
self.get_cont_logits = D_GET_LOGITS(ndf, nc)
def forward(self, img):
img_code = self.encode_img(img)
return img_code
数据集处理:
'''dataset'''
import torchvision.transforms as transforms
import numpy as np
import pandas as pd
from PIL import Image
import pickle
from torch.utils.data import Dataset, DataLoader
class birdDataset(Dataset):
def __init__(self, dataDir, split = 'train', imgsize = 64, transform = None):
super(birdDataset, self).__init__()
self.dataDir = dataDir
self.imgsize = imgsize
self.transform = transform
self.bbox = self.load_bbox()
self.filenames = self.load_filenames(dataDir, split)
self.embeddings = self.load_embedding(dataDir, split)
def load_bbox(self):
'''返回{图片名称:bbox}的字典
例如:{'002.Laysan_Albatross/Laysan_Albatross_0017_614': [82.0, 75.0, 308.0, 260.0],
'002.Laysan_Albatross/Laysan_Albatross_0018_492': [89.0, 172.0, 108.0, 146.0],
'002.Laysan_Albatross/Laysan_Albatross_0021_737': [83.0, 124.0, 211.0, 250.0],
.................}'''
# 我的项目的dataDir是'../dataset'
pth = os.path.join(self.dataDir, 'CUB_200_2011', 'bounding_boxes.txt')
#delin_whitespace: 设置空格为分隔符,此时delimiter参数失效, header = None表示不把第一行作为头部
bbox_data = pd.read_csv(pth, delim_whitespace= True, header=None)
file_path = os.path.join(self.dataDir, 'CUB_200_2011', 'images.txt')
df_filenames = pd.read_csv(file_path, delim_whitespace=True, header=None)
filenames = sorted(df_filenames[1].tolist())
# filename[:-4] 表示去掉图片名称最后的.jpg
fname_bbox_dict = {filename[:-4]:[] for filename in filenames}
for i in range(len(filenames)):
data = bbox_data.iloc[i][1:].tolist()
k = filenames[i][:-4]
fname_bbox_dict[k] = data
return fname_bbox_dict
def get_img(self, img_path, bbox):
img = Image.open(img_path).convert('RGB') # 读取图片,为了防止不是RGB图片,这里进行了转换
width, height = img.size
if bbox is not None:
R = int(np.maximum(bbox[2], bbox[3]) * 0.75)
center_x = int((2 * bbox[0] + bbox[2]) / 2)
center_y = int((2 * bbox[1] + bbox[3]) / 2)
y1 = np.maximum(0, center_y - R)
y2 = np.minimum(height, center_y + R)
x1 = np.maximum(0, center_x - R)
x2 = np.minimum(width, center_x + R)
img = img.crop([x1, y1, x2, y2])
load_size = int(self.imgsize * 76 / 64)
img = img.resize((load_size, load_size), Image.BILINEAR)
if self.transform is not None:
img = self.transform(img)
return img
def load_embedding(self, dataDir, split):
embedding_filename = os.path.join(dataDir, 'birds', split, 'char-CNN-RNN-embeddings.pickle')
with open(embedding_filename, 'rb') as f:
embeddings = pickle.load(f, encoding='bytes')
embeddings = np.array(embeddings) # 返回的是list, 转为array
# print('embeddings:', embeddings.shape) # embeddings: (8855, 10, 1024)
return embeddings
def load_filenames(self, dataDir, split):
'''返回图片的名称:
例如:['002.Laysan_Albatross/Laysan_Albatross_0002_1027',
'002.Laysan_Albatross/Laysan_Albatross_0003_1033',
'002.Laysan_Albatross/Laysan_Albatross_0082_524',
'002.Laysan_Albatross/Laysan_Albatross_0044_784',
....]
保存的filenames.pickle文件本身不带后缀'''
file_path = os.path.join(dataDir, 'birds', split, 'filenames.pickle')
with open(file_path, 'rb') as f:
filenames = pickle.load(f)
return filenames
def __getitem__(self, index):
key = self.filenames[index] # 取出图片名称, 不含.jpg
if self.bbox is not None:
bbox = self.bbox[key] # 根据图片名称在franme_bbox_dict字典中找出对应的bbox
else:
bbox = None
embeddings = self.embeddings[index, :, :] # 取出对应的embedding
img_path = os.path.join(self.dataDir, 'CUB_200_2011', 'images', key+'.jpg') # 得到图片的全路径
image = self.get_img(img_path, bbox) # 获取图片
# random select a sentence
sample = np.random.randint(0, embeddings.shape[0]-1)
embedding = embeddings[sample, :]
return image, embedding
def __len__(self):
return len(self.filenames)
Stage-I 训练:
device = torch.device('cuda: 0' if torch.cuda.is_available() else 'cpu')
'''开始训练STAGE_1'''
def KL_loss(mean, log_var): # 传入μ,log(σ^2)
# -0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)
temp = -mean**2 - torch.exp(log_var) + 1 + log_var
KLD = torch.mean(temp) * (-0.5)
return KLD
'''权重初始化'''
def weight_init_normal(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
'''计算生成器的损失'''
def cal_G_loss(netD, fake_imgs, real_labels, c_code):
criterion = nn.BCELoss()
img_code = netD(fake_imgs) # 将图片输入netD后得到(512, 4, 4)的shape --> img_code
img_cond_output = netD.get_cont_logits(img_code, c_code) # img_code连同c_code一起输入到判别器
err_G = criterion(img_cond_output, real_labels)
return err_G
'''计算判别器的损失'''
def cal_D_loss(netD, real_imgs, fake_imgs, real_labels, fake_labels, c_code):
criterion = nn.BCELoss()
batch_size = real_imgs.size(0)
c_code = c_code.detach()
fake_imgs = fake_imgs.detach()
real_imgs_code = netD(real_imgs)
fake_imgs_code = netD(fake_imgs)
real_output = netD.get_cont_logits(real_imgs_code, c_code) # 真实图片及其配对文字输出
err_D_real = criterion(real_output, real_labels)
unmatched_output = netD.get_cont_logits(real_imgs_code[:(batch_size-1)], c_code[1:]) # 输出真实图片与文字不匹配
err_D_unmatched = criterion(unmatched_output, real_labels[1:])
fake_output = netD.get_cont_logits(fake_imgs_code, c_code) # fake图片及其配对文字输出
err_D_fake = criterion(fake_output, fake_labels)
err_D = err_D_real + (err_D_fake + err_D_unmatched) * 0.5
return err_D, err_D_real.item(), err_D_unmatched.item(), err_D_fake.item()
def main():
transform = transforms.Compose([
transforms.RandomCrop(64),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_dataset = birdDataset(dataDir = opt.dataDir, split='train', imgsize=64, transform = transform)
train_loader = DataLoader(train_dataset, batch_size = opt.batch_size, shuffle=True, num_workers=0)
test_dataset = birdDataset(dataDir= opt.dataDir, split= 'test', imgsize=64, transform = transform)
test_loader = DataLoader(test_dataset, batch_size=opt.batch_size, shuffle=True, num_workers=0)
netG = STAGE1_G().to(device)
netD = STAGE1_D().to(device)
if opt.s1_start_epoch != 1 :
# Load pretrained models
netG.load_state_dict(torch.load('model/stage-I/netG_epoch_{}.pth'.format(opt.s1_start_epoch)))
netD.load_state_dict(torch.load('model/stage-I/netD_epoch_{}.pth'.format(opt.s1_start_epoch)))
else: # Initialize weights
netG.apply(weight_init_normal)
netD.apply(weight_init_normal)
optim_D = torch.optim.Adam(netD.parameters(), lr = opt.lr, betas=(opt.b1, opt.b2))
optim_G = torch.optim.Adam(netG.parameters(), lr = opt.lr, betas=(opt.b1, opt.b2))
fixed_noise = torch.rand(opt.batch_size, opt.z_dim, device = device)
for epoch in range(opt.s1_start_epoch, opt.num_epochs+1):
# 每过50个epoch, 学习率下降一半
if epoch % 50 == 1 and epoch > 1:
opt.lr = opt.lr * 0.5
for param_group in optim_G.param_groups:
param_group['lr'] = opt.lr
for param_group in optim_D.param_groups:
param_group['lr'] = opt.lr
for i, data in enumerate(train_loader, 0):
real_imgs, text_embedding = data
real_imgs = real_imgs.to(device)
text_embedding = text_embedding.to(device)
b_size = real_imgs.shape[0]
real_labels = torch.full(size = (b_size,), fill_value = 1.0, device = device)
fake_labels = torch.full(size = (b_size,), fill_value = 0.0, device = device)
'''update discriminator'''
netD.zero_grad()
# genetate fake_image
noise = torch.rand(b_size, opt.z_dim, device = device)
_, fake_imgs, mu, log_var = netG(text_embedding, noise)
'''这个地方是真的有疑惑,为什么论文作者在这里传入的c_code是均值mu, 就是在计算损失的时候才传入均值作为c_code'''
err_D, err_D_real, err_D_unmatched, err_D_fake = cal_D_loss(netD, real_imgs, fake_imgs, real_labels, fake_labels,mu)
err_D.backward()
optim_D.step()
'''update generator'''
netG.zero_grad()
err_G = cal_G_loss(netD, fake_imgs, real_labels, mu)
err_G += KL_loss(mu, log_var)
err_G.backward()
optim_G.step()
if i % 20 == 0: # 每过50个batch就打印一次loss
print('[Epoch %d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tLoss_D_R: %.4f\tLoss_D_Unmatch: %.4f\tLoss_D_F %.4f'
% (epoch, opt.num_epochs, i, len(train_loader),
err_D.item(), err_G.item(), err_D_real, err_D_unmatched, err_D_fake))
if epoch % 10 == 0 : # 每10个epoch测试一次
with torch.no_grad():
real_imgs, text_embedding = next(iter(test_loader))
real_imgs = real_imgs.to(device)
text_embedding = text_embedding.to(device)
# genetate fake_image
_, fake_imgs, _, _ = netG(text_embedding, fixed_noise)
real_imgs = torchvision.utils.make_grid(real_imgs.cpu(), nrow=8, normalize=True)
fake_imgs = torchvision.utils.make_grid(fake_imgs.detach().cpu(), nrow=8, normalize=True)
img_grid = torch.cat((real_imgs, fake_imgs), dim = 2)
torchvision.utils.save_image(img_grid, 'picture/stage-I/{}.jpg'.format(epoch), nrow = 16, normalize=False)
torch.save(netG.state_dict(), 'model/stage-I/netG_epoch_{}.pth'.format(epoch))
torch.save(netD.state_dict(), 'model/stage-I/netD_epoch_{}.pth'.format(epoch))
if __name__ == '__main__':
main()
Stage-II 训练:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def KL_loss(mean, log_var): # 传入μ,log(σ^2)
# -0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)
temp = -mean**2 - torch.exp(log_var) + 1 + log_var
KLD = torch.mean(temp) * (-0.5)
return KLD
'''权重初始化'''
def weight_init_normal(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
'''计算生成器的损失'''
def cal_G_loss(netD, fake_imgs, real_labels, c_code):
criterion = nn.BCELoss()
img_code = netD(fake_imgs) # 将图片输入netD后得到(512, 4, 4)的shape --> img_code
img_cond_output = netD.get_cont_logits(img_code, c_code) # img_code连同c_code一起输入到判别器
err_G = criterion(img_cond_output, real_labels)
return err_G
'''计算判别器的损失'''
def cal_D_loss(netD, real_imgs, fake_imgs, real_labels, fake_labels, c_code):
criterion = nn.BCELoss()
batch_size = real_imgs.size(0)
c_code = c_code.detach()
fake_imgs = fake_imgs.detach()
real_imgs_code = netD(real_imgs)
fake_imgs_code = netD(fake_imgs)
real_output = netD.get_cont_logits(real_imgs_code, c_code) # 真实图片及其配对文字输出
err_D_real = criterion(real_output, real_labels)
unmatched_output = netD.get_cont_logits(real_imgs_code[:(batch_size-1)], c_code[1:]) # 输出真实图片与文字不匹配
err_D_unmatched = criterion(unmatched_output, real_labels[1:])
fake_output = netD.get_cont_logits(fake_imgs_code, c_code) # fake图片及其配对文字输出
err_D_fake = criterion(fake_output, fake_labels)
err_D = err_D_real + (err_D_fake + err_D_unmatched) * 0.5
return err_D, err_D_real.item(), err_D_unmatched.item(), err_D_fake.item()
def main():
transform = transforms.Compose([
transforms.RandomCrop(256),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_dataset = birdDataset(dataDir = opt.dataDir, split='train', imgsize=256, transform = transform)
train_loader = DataLoader(train_dataset, batch_size = opt.batch_size, shuffle=True, num_workers=0)
test_dataset = birdDataset(dataDir= opt.dataDir, split= 'test', imgsize=256, transform = transform)
test_loader = DataLoader(test_dataset, batch_size=opt.batch_size, shuffle=True, num_workers=0)
G1 = STAGE1_G()
G1.load_state_dict(torch.load('model/stage-I/netG_epoch_200.pth'))
G1.eval() # G1 设置为测试模式
netG = STAGE2_G(G1).to(device)
netD = STAGE2_D().to(device)
if opt.s2_start_epoch != 1 :
# Load pretrained models
netG.load_state_dict(torch.load('model/stage-II/netG2_epoch_{}.pth'.format(opt.s2_start_epoch)))
netD.load_state_dict(torch.load('model/stage-II/netD2_epoch_{}.pth'.format(opt.s2_start_epoch)))
else:
netG.apply(weight_init_normal)
netD.apply(weight_init_normal)
optim_D = torch.optim.Adam(netD.parameters(), lr = opt.lr, betas=(opt.b1, opt.b2))
# remove the parameter from Stage-I generator
netG_param = []
for p in netG.parameters():
if p.requires_grad:
netG_param.append(p)
optim_G = torch.optim.Adam(netG_param, lr = opt.lr, betas=(opt.b1, opt.b2))
fixed_noise = torch.rand(opt.batch_size, opt.z_dim, device = device)
for epoch in range(opt.s2_start_epoch, opt.num_epochs+1):
# 每过50个epoch, 学习率下降一半 (我这里和论文中不一致,论文中是100个epoch减少一次,因为我训练的epoch没有像论文中那样多,
# 所以我自己设置了每50个epoch学习率减少一次)
if epoch % 50 == 1 and epoch > 1:
opt.lr = opt.lr * 0.5
for param_group in optim_G.param_groups:
param_group['lr'] = opt.lr
for param_group in optim_D.param_groups:
param_group['lr'] = opt.lr
for i, data in enumerate(train_loader, 0):
real_imgs, text_embedding = data
real_imgs = real_imgs.to(device)
text_embedding = text_embedding.to(device)
b_size = real_imgs.shape[0]
real_labels = torch.full(size = (b_size,), fill_value = 1.0, device = device)
fake_labels = torch.full(size = (b_size,), fill_value = 0.0, device = device)
'''update discriminator'''
netD.zero_grad()
# genetate fake_image
noise = torch.rand(b_size, opt.z_dim, device = device)
stageI_img, fake_imgs, mu, log_var = netG(text_embedding, noise)
'''这个地方是真的有疑惑,为什么论文作者在这里传入的c_code是均值mu, 就是在计算损失的时候才传入均值作为c_code'''
err_D, err_D_real, err_D_unmatched, err_D_fake = cal_D_loss(netD, real_imgs, fake_imgs, real_labels, fake_labels,mu)
err_D.backward()
optim_D.step()
'''update generator'''
netG.zero_grad()
err_G = cal_G_loss(netD, fake_imgs, real_labels, mu)
err_G += KL_loss(mu, log_var)
err_G.backward()
optim_G.step()
if i % 20 == 0: # 每过50个batch就打印一次loss
print('[Epoch %d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tLoss_D_R: %.4f\tLoss_D_Unmatch: %.4f\tLoss_D_F %.4f'
% (epoch, opt.num_epochs, i, len(train_loader),
err_D.item(), err_G.item(), err_D_real, err_D_unmatched, err_D_fake))
if epoch % 10 == 0 : # 每10个epoch测试一次
with torch.no_grad():
real_imgs, text_embedding = next(iter(test_loader))
real_imgs = real_imgs.to(device)
text_embedding = text_embedding.to(device)
# genetate fake_image
stageI_img, fake_imgs, _, _ = netG(text_embedding, fixed_noise)
real_imgs = torchvision.utils.make_grid(real_imgs.cpu(), nrow=8, normalize=True)
fake_imgs = torchvision.utils.make_grid(fake_imgs.cpu().detach(), nrow=8, normalize=True)
img_grid = torch.cat((real_imgs, fake_imgs), dim = 2)
torchvision.utils.save_image(img_grid, 'picture/stage-II/stage2_{}.jpg'.format(epoch), nrow = 8, normalize=False)
torch.save(netG.state_dict(), 'model/stage-II/netG2_epoch_{}.pth'.format(epoch))
torch.save(netD.state_dict(), 'model/stage-II/netD2_epoch_{}.pth'.format(epoch))
if __name__ == '__main__':
main()
六、训练结果
stage-II 部分训练过程:

stage-I 结果(1080ti 11G 跑了100个epoch):
epoch = 100: 左边8 * 8 = 64 是原图,右边8 * 8 是生成图

stage- II 结果(Tesla V100 16G 跑了100个epoch):
epoch = 100:

七、遇到的问题及解决
1.报错:RuntimeError: Expected object of device type cuda but got device type cpu for argument #1 ‘self’ in call to _th_mm
每次快训练完一个epoch的时候就报这个错误
[Epoch 0/150][0/139] Loss_D: 1.5227 Loss_G: 0.0484 Loss_D_R: 0.7135 Loss_D_Unmatch: 0.7130 Loss_D_F 0.9054
[Epoch 0/150][20/139] Loss_D: 0.4132 Loss_G: 4.0370 Loss_D_R: 0.1938 Loss_D_Unmatch: 0.1941 Loss_D_F 0.2447
[Epoch 0/150][40/139] Loss_D: 0.3920 Loss_G: 5.0670 Loss_D_R: 0.0967 Loss_D_Unmatch: 0.1042 Loss_D_F 0.4863
[Epoch 0/150][60/139] Loss_D: 2.6354 Loss_G: 2.6068 Loss_D_R: 0.0025 Loss_D_Unmatch: 0.0023 Loss_D_F 5.2634
[Epoch 0/150][80/139] Loss_D: 0.2268 Loss_G: 3.0667 Loss_D_R: 0.1089 Loss_D_Unmatch: 0.1176 Loss_D_F 0.1183
[Epoch 0/150][100/139] Loss_D: 0.5236 Loss_G: 3.2538 Loss_D_R: 0.1222 Loss_D_Unmatch: 0.1221 Loss_D_F 0.6808
[Epoch 0/150][120/139] Loss_D: 0.3369 Loss_G: 2.6883 Loss_D_R: 0.1911 Loss_D_Unmatch: 0.2010 Loss_D_F 0.0905
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-330-4e7aecf0f178> in <module>
124
125 if __name__ == '__main__':
--> 126 main()
<ipython-input-330-4e7aecf0f178> in main()
113 text_embedding = text_embedding.to(device)
114 # genetate fake_image
--> 115 _, fake_imgs, _, _ = netG(text_embeddings, fixed_noise)
116 real_imgs = torchvision.utils.make_grid(real_imgs.cpu(), nrow=8, normalize=True)
117 fake_imgs = torchvision.utils.make_grid(fake_imgs.detach().cpu(), nrow=8, normalize=True)
D:\myUtils\anaconda3\lib\site-packages\torch\nn\modules\module.py in __call__(self, *input, **kwargs)
548 result = self._slow_forward(*input, **kwargs)
549 else:
--> 550 result = self.forward(*input, **kwargs)
551 for hook in self._forward_hooks.values():
552 hook_result = hook(self, input, result)
<ipython-input-328-930c20581050> in forward(self, text_embedding, noise)
117 )
118 def forward(self, text_embedding, noise):
--> 119 c_code, mu, log_var = self.ca_net(text_embedding)
120 z_c_code = torch.cat((noise, c_code), dim = 1)
121 img_code = self.fc(z_c_code)
D:\myUtils\anaconda3\lib\site-packages\torch\nn\modules\module.py in __call__(self, *input, **kwargs)
548 result = self._slow_forward(*input, **kwargs)
549 else:
--> 550 result = self.forward(*input, **kwargs)
551 for hook in self._forward_hooks.values():
552 hook_result = hook(self, input, result)
<ipython-input-328-930c20581050> in forward(self, text_embedding)
55 return mu + torch.mul(std, eps)
56 def forward(self, text_embedding):
---> 57 mu, log_var = self.encode(text_embedding)
58 c_code = self.reparameter(mu, log_var)
59 return c_code, mu, log_var
<ipython-input-328-930c20581050> in encode(self, text_embedding)
45
46 def encode(self, text_embedding):
---> 47 x = self.relu(self.fc(text_embedding))
48 mu = x[:, :self.c_dim] # 前面c_dim用作均值输出
49 log_var = x[:, self.c_dim:] # 后面c_dim用作log方差输出
D:\myUtils\anaconda3\lib\site-packages\torch\nn\modules\module.py in __call__(self, *input, **kwargs)
548 result = self._slow_forward(*input, **kwargs)
549 else:
--> 550 result = self.forward(*input, **kwargs)
551 for hook in self._forward_hooks.values():
552 hook_result = hook(self, input, result)
D:\myUtils\anaconda3\lib\site-packages\torch\nn\modules\linear.py in forward(self, input)
85
86 def forward(self, input):
---> 87 return F.linear(input, self.weight, self.bias)
88
89 def extra_repr(self):
D:\myUtils\anaconda3\lib\site-packages\torch\nn\functional.py in linear(input, weight, bias)
1610 ret = torch.addmm(bias, input, weight.t())
1611 else:
-> 1612 output = input.matmul(weight.t())
1613 if bias is not None:
1614 output += bias
RuntimeError: Expected object of device type cuda but got device type cpu for argument #1 'self' in call to _th_mm
解决:在对应处的text_embedding都改为text_embedding.cuda() 关于这点为什么要加入cuda很疑惑,明明在在训练阶段传入的text_embedding已经放在GPU中了。
后来在服务器上跑并没有出现这个问题,说明是我电脑的原因。
pickle.load()读取文件错误















 947
947











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









