







问题:姿态估计和动作识别是两个紧密相连的领域,但是很多工作都将他们分开考虑
思路:设计姿态估计和动作识别多任务框架
方法:从静态image中进行2D和3Dpose estimation,也能从video sequence中进行action recognition
1.摘要
action recognition和human pose estimation是两个紧密相连的领域,但是总是被分开处理。本文的模型就针对这个现状,提出了一个multitask framework,既能从静态image中进行2D和3Dpose estimation,也能从video sequence中进行action recognition。并且,作者证明了,end-to-end的优化方式比分开训练效果更好。此外,模型还能同时用不同领域的数据进行训练。
2.引言
本文提出了独特的端到端可训练的多任务框架,以联合处理2D和3D人体姿态估计和动作识别。
大多数姿态估计方法都执行热图预测,所以基于检测的方法需要不可微的argmax函数来恢复关节坐标作为后处理阶段,打破了端到端学习所需要的反向传播链。
本文主要是通过扩展可微soft-argmax来解决这一问题,用于关节的2D和3D位姿估计。这就可以讲动作识别叠加在姿态估计之上,从而形成一个端到端可训练的多任务框架。
贡献:1.提出的基于回归的姿态估计方法在3D和2D都有先进结果。
2.提出的姿态估计方法是基于静止图像的,无论是2D还是3D预测,都有受益于“野外”图像
3.动作识别方法基于RGB图像中提取的姿态和视觉信息
4.姿态估计方法可以同时使用多种类型的数据集进行训练,是的它能够从2D标注数据中归纳出3D预测。
3.方法
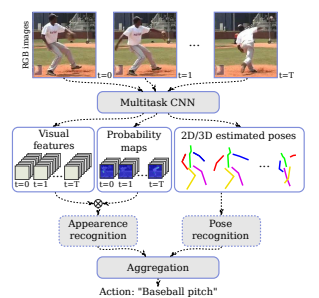
多任务框架图
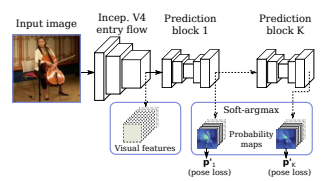
3.1 基于回归的姿态估计
姿态估计使用回归的方法,扩展Soft-argmax函数用于处理2D/3D姿态回归。姿态估计网络包括K个预测块,用于调整姿态,最后一个预测是姿态的估计。低层的视觉特征是副产物,姿态回归结构如下所示:
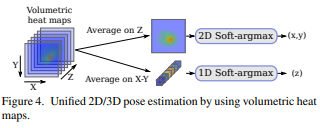
soft-argmax层,对于2D热力图输入,归一化的信号表示为关节点在(x,y)的概率图,关节点位置的期望为:
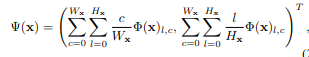
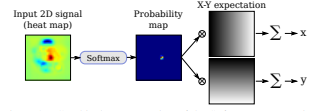
过程图如下:
2D/3D统一姿态估计框架
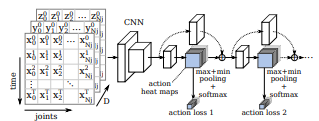
3.2 行为识别
分两步,其中一个基于行人关节点坐标序列,另外一个基于视觉特征序列。对于基于姿态的识别,使用全卷积网络从姿态中提取特征,生成行为热度图。
基于外观的识别,外观特征由低层视觉特征和行人部件概率图中提取,将视觉特征的张量与概率图相乘。
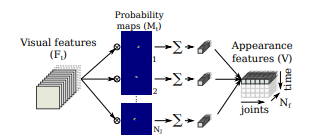
基于外形的识别和姿态识别的结果使用Softmax激活的全链接层组合。
4. 实验
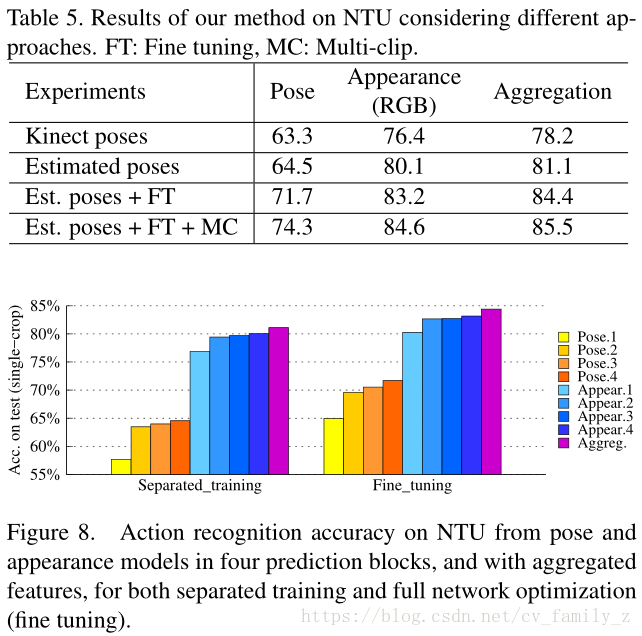
姿态及外形特征组合带来的效果提升,不太大,一个点左右。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









