







目录
1.前言
MNIST是一个手写体数字的图片数据集,该数据集来由美国国家标准与技术研究所(National Institute of Standards and Technology (NIST))发起整理,一共统计了来自250个不同的人手写数字图片,其中50%是高中生,50%来自人口普查局的工作人员。该数据集的收集目的是希望通过算法,实现对手写数字的识别。被广泛地应用于机器学习和深度学习领域,用来测试算法的效果,例如线性分类器(Linear Classifiers)、K-近邻算法(K-Nearest Neighbors)、支持向量机(SVMs)、神经网络(Neural Nets)、卷积神经网络(Convolutional nets)等等。 1998年,Yan LeCun 等人发表了论文《Gradient-Based Learning Applied to Document Recognition》,首次提出了LeNet-5 网络,利用上述数据集实现了手写字体的识别。本篇博客也根据LeNet5网络结构进行理解后,搭建最原始的神经网络。
2.使用的工具介绍
2.1.TensorboardX
Tensorboardx 是 TensorFlow 的一个附加工具,可以记录训练过程的数字、图像等内容,类似于tensoboard,在机器视觉的可视化中使用起来很方便。具体使用参照这里
2.2.Netron
Netron支持主流各种框架的模型结构可视化工作,支持windows,Linux,mac系统,使用起来很方便,直接去GitHub中下载exe文件就可以使用,然后将训练的模型保存为.pth等文件,在软件中打开文件即可。效果如下
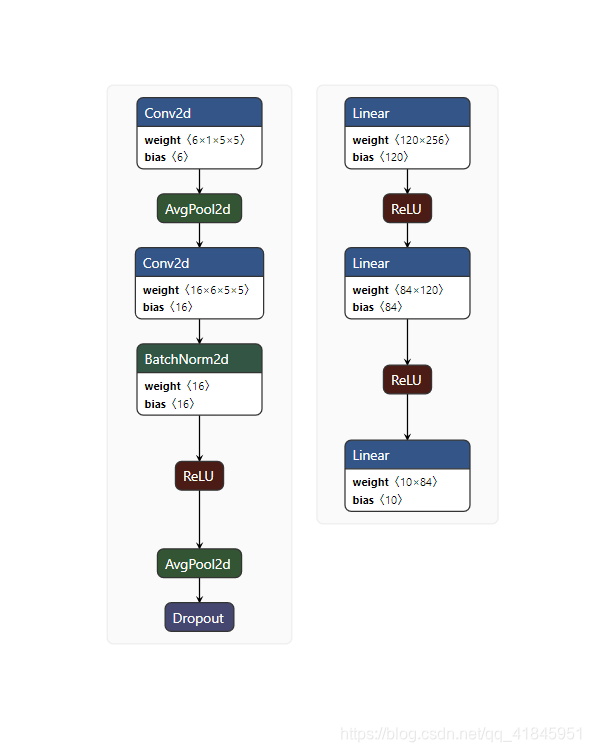
当然也是可以直接通过pip install netron进行安装。
3.搭建CNN神经网络
3.1 CNN结构

此模型的结构是卷积层--池化层--卷积层--池化层--全连接层
3.1.1卷积层
卷积层(Convolutional layer)由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法最佳化得到的。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网路能从低级特征中迭代提取更复杂的特征。
主要的工作原理就是通过n*n大小的kernel对每张图片的每各通道进行扫描,每次都是选取n*n大小的数据跟kernel上的数据进行运算,得出一个值,而后继续一定,直到扫描完所有数据。
3.1.2池化层
池化层是夹在连续卷积层中间的,用于压缩数据和参数的量,减小过拟合。简而言之,如果输入是图像的话,那么池化层的最主要作用就是压缩图像。
下采样层也叫池化层,其具体操作与卷积层的操作基本相同,只不过下采样的卷积核为只取对应位置的最大值、平均值等(最大池化、平均池化),即矩阵之间的运算规律不一样,并且不经过反向传播的修改。如图
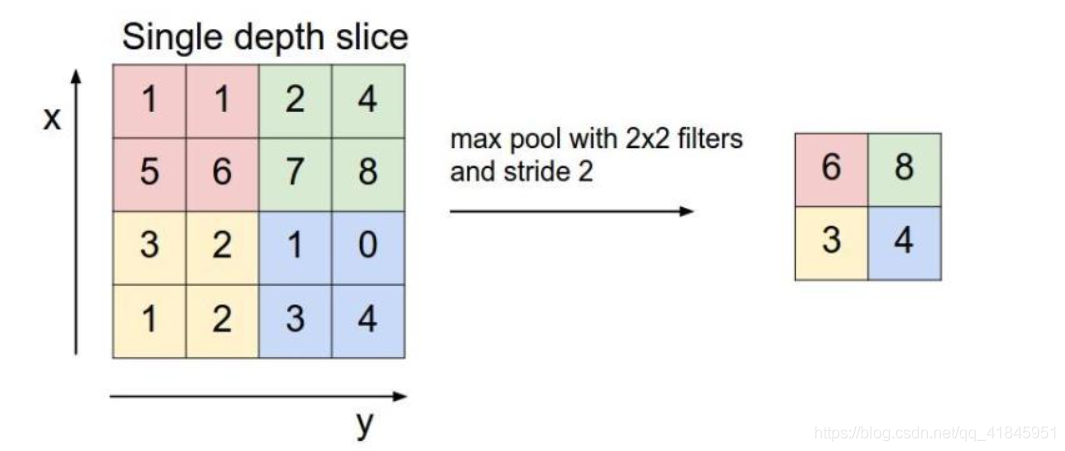
2*2的kernel对4*4的数据进行扫描,每次移动两步,那么算出来的值也就是一个2*2大小的数据。
因此池化层的作用就是保证特征不变,因为每次都还是会采样,保留重要的特征,其次就是特征降维,当特征量太多,我们会选择将一些没有用的特征丢掉,只保留有用的特征。
3.1.3全连接层
全连接层的 作用就是分类,具体描述在我上一篇博客,并且还附有代码。
3.2构建CNN与代码实现
导入数据,并且查看数据,MINIST数据集包含train和test数据集,我们直接用train和test一个做训练集一个做测试集。
batch_size = 512
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 992
992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









