







第一章 初识Python
Python它是一种直译式,面向对象,解释式的脚本语言。有很多库,被称为胶水语言。
def print_hi(name):
print(f'Hi, {name}')
if __name__ == '__main__':
print_hi('PyCharm')- 分号 ; 分割一行多句
- 新行作为语句的结束标识,可以使用
\将一行语句分为多行显示( [], {}, 或 () 中不用 ) - 使用缩进来表示代码块,不需要使用大括号 {}
# 注释一行'''注释多行''' """注释多行""" (python中单引号=双引号)- pass 是空语句,它不做任何事情,一般用做占位语句,作用是保持程序结构的完整性。
第二章 数据结构
一、基础知识
1. 标识符
Python 中以下划线开头的标识符有特殊含义:
- _xxx :表示不能直接访问的类属性,需通过类提供的接口访问,不能用from xxx import * 导入
- __xx:表示私有成员
- __xx__:表示 Python 中内置标识
关键字:Python关键字大全
| and | exec | not | assert | finally | or | as |
|---|---|---|---|---|---|---|
| break | for | pass | class | from | true | |
| continue | global | raise | def | if | return | false |
| del | import | try | elif | in | while | none |
| else | is | with | except | lambda | yield | nonlocal |
2. 命名空间
通常在不同时刻创建的命名空间拥有不同的生命周期:
- 内置:在 Python 解释器启动时创建,退出时销毁。
- 全局:在模块定义被读入时创建,在 Python 解释器退出时销毁。
- 局部:对于类,在 Python 解释器读到类定义时创建,类定义结束后销毁;对于函数,在函数被调用时创建,函数执行完成或出现未捕获的异常时销毁。
3. 作用域
- 局部:最先被搜索的最内部作用域,包含局部名称。
- 嵌套:根据嵌套层次由内向外搜索,包含非全局、非局部名称。
- 全局:倒数第二个被搜索,包含当前模块的全局名称。
- 内建:最后被搜索,包含内置名称的命名空间。
修改作用域:
global:修改局部作用域的变量为全局作用域nonlocal:修改嵌套作用域中的变量为全局作用域
4. 引用
- 引用是一种变量指向数据存储空间的现象
- 相同数据在内存空间中仅占用一个存储空间
二、数据类型
type(变量/常量) # 可查询变量所指的对象类型1. 数字Num
数据类型:int(整数)float(浮点数)complex(复数)
bool(布尔)None(空值)
| 模块 | 描述 |
|---|---|
| math | 提供了对 C 标准定义的数学函数的访问(不适用于复数) |
| cmath | 提供了一些关于复数的数学函数 |
| decimal | 为快速正确舍入的十进制浮点运算提供支持 |
| fractions | 为分数运算提供支持 |
| random | 实现各种分布的伪随机数生成器 |
| statistics | 提供了用于计算数字数据的数理统计量的函数 |
| math模块中函数 | 描述 |
|---|---|
| abs(x) | 返回 x 的绝对值 |
| ceil(x) | 返回 x 的上入整数,如:math.ceil(1.1) 返回 2 |
| floor(x) | 返回 x 的下舍整数,如:math.floor(1.1) 返回 1 |
| exp(x) | 返回 e 的 x 次幂 |
| log(x) | 返回以 e 为底 x 的对数 |
| log10(x) | 返回以 10 为底 x 的对数 |
| pow(x, y) | 返回 x 的 y 次幂 |
| sqrt(x) | 返回 x 的平方根 |
| factorial(x) | 返回 x 的阶乘 |
2. 字符串Str
通过单引号 '、双引号 "、三引号 ''' 或 """ 来定
my_str.find(str start=0, end=len(mystr)) # 检测str1是否包含在my_str中,如果是返回开始的索引值,否则返回-1
my_str.rfind(str, start=0, end=len(my_str)) # 从右边开始查找
my_str.count(str, start=0, end=len(mystr)) # 返回str在start和end之间在my_str里面出现的次数
my_str.replace(str1, str2, mystr.count(str1)) # 把my_str中的str1替换成str2,如果count指定,则替换不超过count次
my_str.split(str=" ", maxsplit) # 以str为分隔符切片my_str,如果maxsplit有指定值,则仅分隔 maxsplit个子字符串
my_str.startswith(hello) # 检查字符串是否是以hello开头, 是则返回True,否则返回False
my_str.endswith(obj) # 检查字符串是否以obj结束,如果是返回True,否则返回 False.
my_str.lower() # 所有大写字符变小写
my_str.upper() # 所有小写字母变大写
my_str.strip() # 删除字符串两端的空白字符
my_str.partition(str) # 把my_str以str分割成三部分,str前,str和str后
my_str.splitlines() # 按照行分隔,返回一个包含各行作为元素的列表
my_str.isalpha() # 如果 my_str 所有字符都是字母(空格、小数点不算) 则返回 True,否则返回 False
my_str.isdigit() # 如果 my_str 只包含数字则返回 True 否则返回 False.
my_str.isalnum() # 如果 my_str 所有字符都是字母或数字则返回 True,否则返回 False
my_str.join(str) # my_str 中每个元素后面插入str,构造出一个新的字符串序列sequene
- 一块存放多个值的连续内存空间,按顺序排列,每个值所在位置都有一个编号,称其为索引
- 字符串、列表、元组
操作:
- 索引:通过下标访问对应元素,seq[0~n-1] / seq[-1~-n]


- 切片: 访问一定范围内的元素,seq[start : end : step](无start /end表最末,左闭右开原则)
- 加乘: 通过+/*使序列相加或重复
- 检查成员: 检查某元素是否为序列的成员,val in seq / val not in seq
- 遍历成员: 依次读取序列元素,for i in seq / while i<length
| 函数 | 描述 |
|---|---|
| len() | 计算序列的长度 |
| max() | 找出序列中的最大元素 |
| min() | 找出序列中的最小元素 |
| list() | 将序列转换为列表 |
| str() | 将序列转换为字符串 |
| sum() | 计算元素的和 |
| sorted() | 对元素进行排序 |
| enumerate() | 将序列组合为一个索引序列,多用在 for 循环中 |
3. 列表List[]
列表VS数组:都能存储多个数据,列表可以存储不同类似的数据,而数组只能存储相同数据类型
# 增
my_list.append(obj) # 向列表末尾添加一个新元素(追加单个)
my_list.extend(my_list1) # 将另一个列表中的元素逐一添加到列表中(追加多个)
my_list.insert(index, obj) # 在指定位置前插入元素
my_list.copy() # 复制列表
#删
del my_list[2] # 根据下标进行删除
my_list.pop() # 删除最后一个元素
my_list.remove(obj) # 删除指定的数据
my_list.clear() # 清空列表
#改
my_list[下标] = obj
#查
obj in my_list
my_list.count(obj) # 统计列表中某个元素出现的次数
my_list.index(obj) # 查找某个元素在列表中首次出现的位置
4. 元组Tuple()
元组VS列表:都能存储多个数据,但元组不能修改,数据较安全, 因此成为了python的默认形式
- 元组只有一个元素时,要写上逗号 (3,) 用于区分数值运算中处理运算符优先级的( 3 )
- 元组中元素不能被修改,可用重新赋值的方式操作
- 元组中的元素不能被删除,只能删除整个元组
5. 集合Set{}
集合可以存储多个数据,数据不能重复会自动去重,所以实际存储顺序与定义的顺序没有关系
- 列表、元组、集合可互转:不是对原数据进行修改,而是得到一个新的数据
6. 字典Dict{}
- 增删改查等使用数字下标易错乱,改为自定义标识,键值对 {Key:Value}
- Key相当于集合中的下标值012...,所以Key值不能相同,且无序号了所以无序存放
- 空集合和空字典都是{},为了不容易混乱,使用如下方式:
- blank_set=set() # 空集合
- blank_dict=dict()# 空字典
# 增
my_dict['新键'] = 新数据 #这个“键”在字典中不存在,那么就会新增这个元素。
#删
del my_dict[Key] # 删除指定的键值对
del my_dict # 删除整个字典
my_dict.clear() # 清空整个字典数据,但不删除
#改
my_dict['键'] = 新数据 # 只要通过key找到,即可修改
#查
my_dict[key] #若访问不存在的键,则会报错
my_dict.get(key, default=None) #返回指定键的值,如果键不在字典中返回 default 设置的默认值,也可以将none修改为想要返回的内容
# 默认遍历键,my_dict.value遍历键值,my_dict.sort遍历键值对分析总结:列表、元组、集合、字典各有特点,不同场合使用不同特色存储
- 列表:推荐使用,数据类型相同,且可能需要对数据进行操作
- 元组:使用一般,数据类型相同,且不能修改这些数据
- 集合:使用较少,数据去重
- 字典:使用较多,数据类型不同,且这些数据都是相当于一个整体的
三、数据处理
1. 推导式
for ... in ...是一种快速生成数据的方式,可以用一行代码生成有规律的列表
- 列表推导式: [xxx for 变量 in 可迭代对象 ]
- 没有元组推导式,而是生成器
- 集合推导式: {xxx for 变量 in 可迭代对象}
- 字典推导式 :{xxx:xxx for 变量 in 可迭代对象}
2. 拆包
拆包(解包)是一种快速提取数据的方式
- 拆列表 a,b=[1,2]
- 拆元组 a,b=(1,2)
- 拆集合 a,b={1,2} 每次结果乱序
- 拆字典 a,b={}取到的是字典的key,取value要用遍历 for k, v in dict1.items():
经典面试题(交换a,b的值)

|

|

|
3. 枚举
枚举的定义可以通过继承 Enum 的方式来实现
from enum import Enum
@unique
class 枚举名(Enum):
枚举成员表
枚举名.枚举成员 # 访问枚举成员
枚举名.枚举成员.name # 访问枚举成员名称
枚举名.枚举成员.value # 访问枚举成员值
- 成员名不可重复,成员值可重复
- 装饰器
@unique保证成员值不可重复
第三章 语法结构
一、模块
Python 有很多自带的模块(标准库)和第三方模块,从包中引入模块:
- import ...
- from ... import ...
os 模块:负责与操作系统进行交互
os.getcwd() # 查看当前路径
os.listdir(path) # 返回指定目录下包含的文件和目录名列表
os.path.abspath(path) # 返回路径path的绝对路径
os.path.split(path) # 将路径path拆分为目录和文件两部分,返回结果为元组类型
os.path.join(path, *paths)# 将一个或多个 path(文件或目录) 进行拼接
os.path.getctime(path)# 返回 path(文件或目录) 在系统中的创建时间。
os.path.getmtime(path)# 返回 path(文件或目录)的最后修改时间。
os.path.getatime(path)# 返回 path(文件或目录)的最后访问时间。
os.path.exists(path) # 判断 path(文件或目录)是否存在,存在返回 True,否则返回 False。
os.path.isdir(path) # 判断 path 是否为目录。
os.path.isfile(path) # 判断 path 是否为文件。
os.path.getsize(path) # 返回 path 的大小,以字节为单位,若 path 是目录则返回 0。
os.mkdir() # 创建一个目录
os.makedirs() #创建多级目录。
os.chdir(path) # 将当前工作目录更改为 path。
os.system(command) #调用 shell 脚本sys 模块:负责与 Python 解释器进行交互
sys.argv # 返回传递给Python脚本的命令行参数列表
sys.exit() # 退出当前程序
sys.version # 返回 Python 解释器的版本信息
sys.winver # 返回 Python 解释器主版号
sys.platform # 返回操作系统平台名称
sys.path # 返回模块的搜索路径列表
sys.maxsiz # 返回支持的最大整数值
sys.maxunico # 返回支持的最大 Unicode 值
sys.copyright # 返回 Python 版权信息
sys.modules # 以字典类型返回系统导入的模块
sys.byteorder # 返回本地字节规则的指示器
sys.executable # 返回 Python 解释器所在路径
sys.stdout.write(obj) # 标准输出
sys.stdin.readline() # 标准输入
sys.stderr.write() # 错误输出
sys.getdefaultencoding() # 返回当前默认字符串编码的名称
sys.getrefcount(obj) # 返回对象的引用计数
sys.getrecursionlimit() # 返回支持的递归深度
sys.getsizeof(object[, default]) # 以字节为单位返回对象的大小
sys.setswitchinterval(interval) # 设置线程切换的时间间隔
sys.getswitchinterval() # 返回线程切换时间间隔二、函数
1. 自定义函数
def 函数名(参数):
函数体
return 返回值(1)函数参数
- 必需参数:实参与形参顺序对应、个数相同
- 缺省参数:形参名=XXX 传则替换,不传则用默认(若为列表则每次调用都为同一个列表)
- 命名参数:形参名=实参 (整体不带缺省/命名的在左,整体带的在右,不可夹杂)
- 不定长参数:参数个数不确定
- * args会以元组的形式导入(*表特殊,变量仍是args)
- ** kwargs会以字典的形式导入 以形参名=实参传(args中数据通过遍历元组/字典读取)
- *args在前**kwargs在后,即多余的给args,带形参名=XXX格式的给**kwargs
(2)返回值
- 一个函数中只能有1个return被执行,
- 结束函数的执行,后面函数体语句不执行
- 默认none,可通过return返回列表、元组、集合、字典等从而实现一次性返回多个数据
(3)函数拆包
- 函数的返回值拆包
- */**对列表集合/字典拆包去命名参数
2. 匿名函数
一个没有名字的函数 把def name换成了lambda
lambda 形参1, 形参2, 形参3... : 表达式
#lambda函数能接收任何数量的参数但只能返回一个表达式的值,其默认就是返回的,不用写return- 变量名=lambda 参数 : 表达式,通过变量名()调用
- lambda 参数 : 表达式整体当实参
3. 迭代器
- 可迭代对象:具有
__iter__()方法,它们均可使用for循环遍历 - 迭代器iterator:具有
__iter__()和__next__()两个方法,是一个可记住遍历位置的对象 - 迭代器一定是可迭代的,反之不成立如list dict str,不过可通过 iter() 获得其迭代器对象
iter(可迭代对象)获取可迭代对象的迭代器,对迭代器使用next(迭代器)获取下一条数据,当没有下一项数据时抛出 StopIteration 异常迭代结束

for 循环语句的实现便是利用了迭代器
自定义迭代器
- 迭代对象返+迭代器 ,集成在一个类中
- 迭代对象+迭代器 两个类分开, 调用关系
4. 生成器
generator:元素可按某种算法推算,则不必创建完整的列表,边循环边计算,只存算法占用内存小
生成器是用来创建迭代器的工具,创建生成器:
- 生成器表达式:nums=(.. for ...in...)推导式的[]换成()
- 函数+yield语句
- 保存当前运行状态(断点),然后暂停执行,即将生成器(函数)挂起,将yield关键字后面表达式的值作为返回值返回,此时可以理解为起到了return的作用
- 可以使用next()函数让生成器从断点处继续执行,即唤醒生成器(函数)
- 还可以使用send()函数来唤醒执行,好处是:可以在唤醒的同时向断点处传入一个附加数据
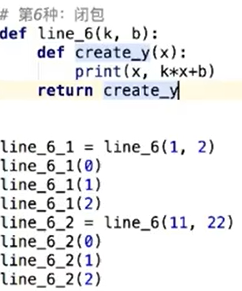
5. 闭包
closure:调用一个带有返回值的函数 x,此时函数 x 返回一个函数 y,这个函数 y 就被称作闭包
- 内部函数用到了外部函数的局部变量或者形参,其被永久存储
- 闭包与类有一些相似,比如:它们都能实现数据的封装、方法的复用等;此外,通过使用闭包可以避免使用全局变量,还能将函数与其所操作的数据关连起来。
函数、匿名函数、闭包、对象当做实参时,有什么区别?
- 匿名函数能完成基本的简单功能,传递是这个函数的引用 只有功能
- 普通函数能完成较为复杂的功能,传递是这个函数的引用 只有功能
- 闭包能完成较为复杂的功能,传递是这个闭包中的函数及数据(形参)
- 对象能完成最为复杂的功能,传递是很多功能+很多数据(形参)

|

|

|
|
6. 装饰器
decorator:是一种闭包的应用,在不修改原函数代码的基础上,对函数执行之前和执行之后添加额外功能,它就是语法糖。
定义装饰函数/类
@装饰函数名/类名
定义业务函数- 装饰器可以基于函数实现也可基于类实现
- 装饰函数也是可以接受参数的
- 支持多个装饰器同时使用
三、语法
1. 条件语句
- if 语句
- if...else 语句
- if...elif...elif...else 语句
- 无 switch 语句
2. 循环语句
- for 循环,函数体内无法调用次数变量
- while 循环
- 无 do...while语句
3. 转向语句
- break
- continue
- else
4. 异常处理

BaseException
+-- SystemExit
+-- KeyboardInterrupt
+-- GeneratorExit
+-- Exception
+-- StopIteration
+-- StopAsyncIteration
+-- ArithmeticError
| +-- FloatingPointError
| +-- OverflowError
| +-- ZeroDivisionError
+-- AssertionError
+-- AttributeError
+-- BufferError
+-- EOFError
+-- ImportError
| +-- ModuleNotFoundError
+-- LookupError
| +-- IndexError
| +-- KeyError
+-- MemoryError
+-- NameError
| +-- UnboundLocalError
+-- OSError
| +-- BlockingIOError
| +-- ChildProcessError
| +-- ConnectionError
| | +-- BrokenPipeError
| | +-- ConnectionAbortedError
| | +-- ConnectionRefusedError
| | +-- ConnectionResetError
| +-- FileExistsError
| +-- FileNotFoundError
| +-- InterruptedError
| +-- IsADirectoryError
| +-- NotADirectoryError
| +-- PermissionError
| +-- ProcessLookupError
| +-- TimeoutError
+-- ReferenceError
+-- RuntimeError
| +-- NotImplementedError
| +-- RecursionError
+-- SyntaxError
| +-- IndentationError
| +-- TabError
+-- SystemError
+-- TypeError
+-- ValueError
| +-- UnicodeError
| +-- UnicodeDecodeError
| +-- UnicodeEncodeError
| +-- UnicodeTranslateError
+-- Warning
+-- DeprecationWarning
+-- PendingDeprecationWarning
+-- RuntimeWarning
+-- SyntaxWarning
+-- UserWarning
+-- FutureWarning
+-- ImportWarning
+-- UnicodeWarning
+-- BytesWarning
+-- ResourceWarning| 异常名称 | 描述 |
|---|---|
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| Exception | 常规错误的基类 |
| StopIteration | 迭代器没有更多的值 |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| StandardError | 所有的内建标准异常的基类 |
| ArithmeticError | 所有数值计算错误的基类 |
| FloatingPointError | 浮点计算错误 |
| OverflowError | 数值运算超出最大限制 |
| ZeroDivisionError | 除(或取模)零 (所有数据类型) |
| AssertionError | 断言语句失败 |
| AttributeError | 对象没有这个属性 |
| EOFError | 没有内建输入,到达EOF 标记 |
| EnvironmentError | 操作系统错误的基类 |
| IOError | 输入/输出操作失败 |
| OSError | 操作系统错误 |
| WindowsError | 系统调用失败 |
| ImportError | 导入模块/对象失败 |
| LookupError | 无效数据查询的基类 |
| IndexError | 序列中没有此索引(index) |
| KeyError | 映射中没有这个键 |
| MemoryError | 内存溢出错误(对于Python 解释器不是致命的) |
| NameError | 未声明/初始化对象 (没有属性) |
| UnboundLocalError | 访问未初始化的本地变量 |
| ReferenceError | 弱引用(Weak reference)试图访问已经垃圾回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| NotImplementedError | 尚未实现的方法 |
| SyntaxError | Python 语法错误 |
| IndentationError | 缩进错误 |
| TabError | Tab 和空格混用 |
| SystemError | 一般的解释器系统错误 |
| TypeError | 对类型无效的操作 |
| ValueError | 传入无效的参数 |
| UnicodeError | Unicode 相关的错误 |
| UnicodeDecodeError | Unicode 解码时的错误 |
| UnicodeEncodeError | Unicode 编码时错误 |
| UnicodeTranslateError | Unicode 转换时错误 |
| Warning | 警告的基类 |
| DeprecationWarning | 关于被弃用的特征的警告 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| OverflowWarning | 旧的关于自动提升为长整型(long)的警告 |
| PendingDeprecationWarning | 关于特性将会被废弃的警告 |
| RuntimeWarning | 可疑的运行时行为(runtime behavior)的警告 |
| SyntaxWarning | 可疑的语法的警告 |
| UserWarning | 用户代码生成的警告 |
四、输入输出
1.标准输入输出
input()
- 会把用户输入的任何值都作为字符串来对待 ,str = input("请输入:")
- 如果一个程序需要获取多个数据,那么就要用多个input,即一个变量存储一个输入数据
print()
-
格式字符串:%

-
新格式字符串:字符串.format() = print(f'.....')
# 1.通过位置
print('{o},{1}'.format('laowang',20)) # laowang,20
print('{0]-{1}'.format('laowang',20)) # laowang-20
print('{},{}'.format('laowang',20)) # 1aowang,20
print('{1},{0},{1}'.format('laowang',20)) # 20,1aowang,20
print('{name},{age}'.format(age=18,name='laowang')) # laowang,18
# 2.通过关键字参数
class Person:
def _init_(self,name,age):
self.name = name
self.age = age
def _str_(self):
return 'name is {a.name},age is {a.age} old'.format(a=self)
print(Person('laowang',18)) # name is laowang,age is 18 old
# 3.通过映射list
a_list=['laowang',20,'China']
print('my name is {0[0]},from {0[2]},age is {0[1]}'.format(a_list)) # my name is laowang,from China,age is 20
# 4.通过映射dict
b_dict ={'name':'laowang','age':20,'province':'shandong'}
print('my name is {name},age is {age},from {province}'.format(**b_dict))
print('my name is {info[name]},age is {info[age]},from {info[province]}'.format(info=b_dict))
# print('my name is {info["name"]},age is {info["age"]},from {info["province"]}'.format(info=b_dict)) # 错误的
#5.填充与对齐
print('****{:>8}****'.format('189')) # **** 189****
print('****{:<8}****'.format('189')) # ****189 ****
print('****{:0>8}****'.format('189')) # ****00000189****
print('****{:a>8}****'.format('l89')) # ****aaaaa189****
#精度与类型f
print('{:.2f}'.format(321.33345)) # 保留两位小数 321.33
#用来做金额的干位分隔符
print('{:,}'.format(1234567890)) # 1,234,567,890
#其他类型主要就是进制了,b、d、0、X分别是二进制、十进制以、八进制、十六进制。
print('{:b}'.format(18)) # 二进制10010
print('{:d}'.format(18)) #十进制18
print('{:o}'.format(18)) #八进制22
print('{:x}'.format(18) #十六进制122. 正则表达式
regex101: build, test, and debug regex
正则表达式是一个强大的字符串处理工具,进行单个字符检查。
content = '''
Python3 高级开发工程师 上海互教教育科技有限公司上海-浦东新区2万/月02-18满员
测试开发工程师(C++/python) 上海墨鹍数码科技有限公司上海-浦东新区2.5万/每月02-18未满员
Python3 开发工程师 上海德拓信息技术股份有限公司上海-徐汇区1.3万/每月02-18剩余11人
测试开发工程师(Python) 赫里普(上海)信息科技有限公司上海-浦东新区1.1万/每月02-18剩余5人
Python高级开发工程师 上海行动教育科技股份有限公司上海-闵行区2.8万/月02-18剩余255人
python开发工程师 上海优似腾软件开发有限公司上海-浦东新区2.5万/每月02-18满员
'''
import re
p = re.compile(r'([\d.]+)万/每{0,1}月')
for one in p.findall(content):
print(one) #2 2.5 1.3 1.1 2.8 2.5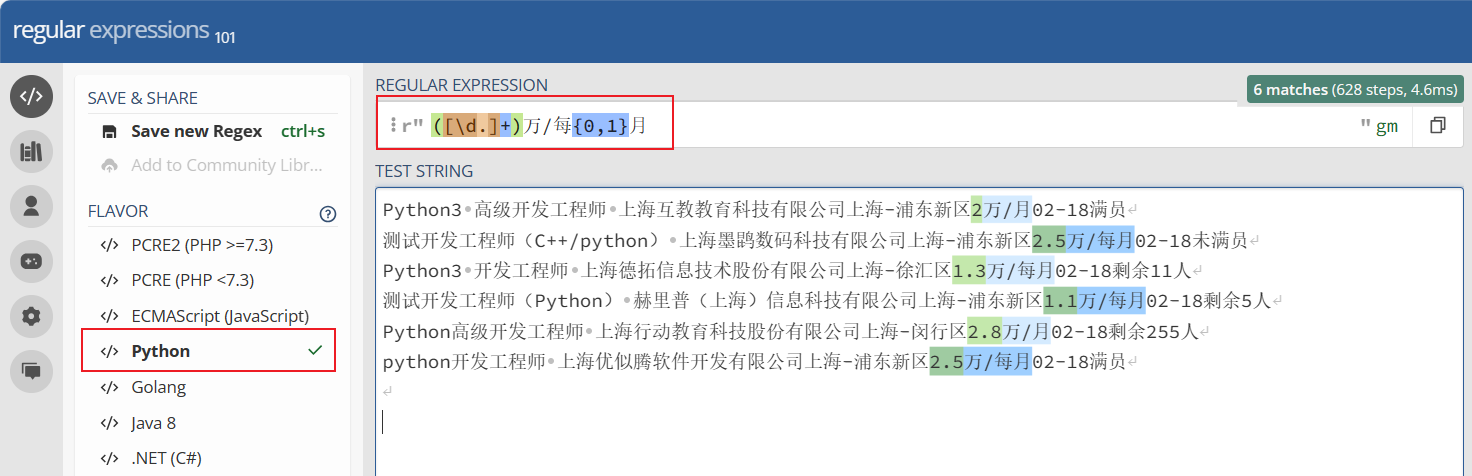
(1)运算符
- 原义字符:字符本身的含义,可以直接匹配。r,表示原始字符串
- 转义字符:不表示字符而表示其他含义

- 特殊字符:匹配某种类型的字符
| 单个字符 | 个数 | 位置点 |
|---|---|---|
| . 任意字符,除了换行符 | * 任意次 | ^ 开头 |
| \w 数字字母下划线或汉字,\W 非word | + 至少一次 | $ 结尾 |
| \d 数字,相当于[0-9],\D非数字[^0-9] | ?最多一次 | \b 边界 \B非边界 |
| \s 空白符(空格、tab等),\S 非空白符 | {n} 出现n次,{n,}至少n次,{n,m} 出现n-m次 |
- 在正则表达式中,*、?都是贪婪的,使用他们时,会尽可能多的匹配内容。
- 使用非贪婪模式,可以在*后面加上?
| 整体代表单个字符 | 范围 |
|---|---|
| [] | []内,多选一 |
| [^] | []外(非),多选一 |
| - | 左到右,多选一 |
| | | 左或右,二选一 |
(2)方法
# re模块的主要方法
re.compile(pattern, flags=0) #编译正则表达式,生成一个正则表达式对象。flags匹配模式
re.search(pattern, string, flags=0)#扫描整个字符串找到匹配样式的第一个位置,并返回一个相应的匹配对象;如果没有匹配,就返回一个 None。
re.match(pattern, string, flags=0)#如果字符串开始的0或者多个字符匹配到了正则表达式样式,就返回一个相应的匹配对象;如果没有匹配,就返回None。
re.fullmatch(pattern, string, flags=0)#如果整个字符串匹配到正则表达式样式,就返回一个相应的匹配对象;否则就返回一个 None。
re.split(pattern, string, maxsplit=0, flags=0)#用 pattern 分开 string,如果在 pattern 中捕获到括号,那么所有的组里的文字也会包含在列表里,如果 maxsplit 非零,最多进行 maxsplit 次分隔,剩下的字符全部返回到列表的最后一个元素。
re.findall(pattern, string, flags=0) #对string返回一个不重复的pattern的匹配列表,string 从左到右进行扫描,匹配按找到的顺序返回,如果样式里存在一到多个组,就返回一个组合列表,空匹配也会包含在结果里。
re.finditer(pattern, string, flags=0)#pattern 在 string 里所有的非重复匹配,返回为一个迭代器 iterator 保存了匹配对象,string 从左到右扫描,匹配按顺序排列。
re.sub(pattern, repl, string, count=0, flags=0)#返回通过使用 repl 替换在 string 最左边非重叠出现的 pattern 而获得的字符串,count 表示匹配后替换的最大次数,默认 0 表示替换所有的匹配。
re.subn(pattern, repl, string, count=0, flags=0)#行为与 re.sub() 相同,但返回的是一个元组。
re.escape(pattern)#转义 pattern 中的特殊字符。
re.purge()#清除正则表达式缓存。| 匹配模式 | 说明 |
|---|---|
re.A | 让 \w, \W, \b, \B, \d, \D, \s, \S 只匹配 ASCII |
re.I | 忽略大小写 |
re.M | 多行模式 |
re.L | 由当前语言区域决定 \w, \W, \b, \B 和大小写敏感匹配 |
re.S | . 匹配包括换行符在内的任意字符 |
re.U | 在 Python3 中是冗余的,因为 Python3 中字符串已经默认为 Unicode |
re.X | 忽略空格和 # 后面的注释 |
# 正则表达式对象的主要方法
Pattern.search(string[, pos[, endpos]])#扫描整个 string 寻找第一个匹配的位置,并返回一个相应的匹配对象,如果没有匹配,就返回 None;可选参数 pos 给出了字符串中开始搜索的位置索引,默认为 0;可选参数 endpos 限定了字符串搜索的结束。
Pattern.match(string[, pos[, endpos]])#如果 string 的开始位置能够找到这个正则样式的任意个匹配,就返回一个相应的匹配对象,如果不匹配,就返回 None。
Pattern.fullmatch(string[, pos[, endpos]])#如果整个 string 匹配这个正则表达式,就返回一个相应的匹配对象,否则就返回 None。
Pattern.split(string, maxsplit=0)#等价于 re.split() 函数,使用了编译后的样式
Pattern.findall(string[, pos[, endpos]])#使用了编译后样式,可以接收可选参数 pos 和 endpos,限制搜索范围。
Pattern.finditer(string[, pos[, endpos]])#使用了编译后样式,可以接收可选参数 pos 和 endpos ,限制搜索范围
Pattern.sub(repl, string, count=0)#使用了编译后的样式
Pattern.subn(repl, string, count=0)#使用了编译后的样式# 匹配对象的主要方法
Match.expand(template)#对 template 进行反斜杠转义替换并且返回
Match.group([group1, ...])#返回一个或者多个匹配的子组
Match.groups(default=None)#返回一个元组,包含所有匹配的子组,在样式中出现的从 1 到任意多的组合,default 参数用于不参与匹配的情况,默认为 None
Match.groupdict(default=None)#返回一个字典,包含了所有的命名子组,default 参数用于不参与匹配的组合,默认为 None。
Match.start([group]) 和 Match.end([group])#返回 group 匹配到的字串的开始和结束标号
Match.span([group])#对于一个匹配 m,返回一个二元组 (m.start(group), m.end(group))3. 文件操作
f=open(file, mode='r') # 打开文件,返回文件对象
f.write(str) # 将字符串写入文件,返回写入字符长度
f.writelines(s) # 向文件写入一个字符串列表
f.read([size]) # 读取指定的字节数,参数可选,无参或参数为负时读取所有
f.readline() # 读取一行
f.readlines() # 读取所有行并返回列表
f.close() # 关闭文件。关闭后文件不能再进行读写操作。
with open() as f # 进阶中采用 with 进行文件关闭,
f.tell() # 返回文件对象在文件中的当前位置
f.seek(offset[, whence])# 将文件对象移动到指定的位置;offset 表示移动的偏移量;whence 为可选参数,值为 0 表示从文件开头起算(默认值)、值为 1 表示使用当前文件位置、值为 2 表示使用文件末尾作为参考点| 模式 | 描述 |
|---|---|
| r | 读取(默认) |
| w | 写入,并先截断文件 |
| x | 排它性创建,如果文件已存在则失败 |
| a | 写入,如果文件存在则在末尾追加 |
| b | 二进制模式 |
| t | 文本模式(默认) |
| + | 更新磁盘文件(读取并写入) |
3. with与上下文管理器
系统资源执行完业务后必须关闭,一般使用XXX.close(),但这样方式在产生异常时不会被调用。
上下文管理器申请及释放资源,而with会自动调用申请资源,以及释放资源的代码,所以更便捷。
- 含 __enter__() 和 __exit__() 方法的对象,上下文管理器对象可以使用 with 关键字
- contextmanager 的装饰器更加简化,通过 yield 将函数分割成两部分
第四章 类和对象
-
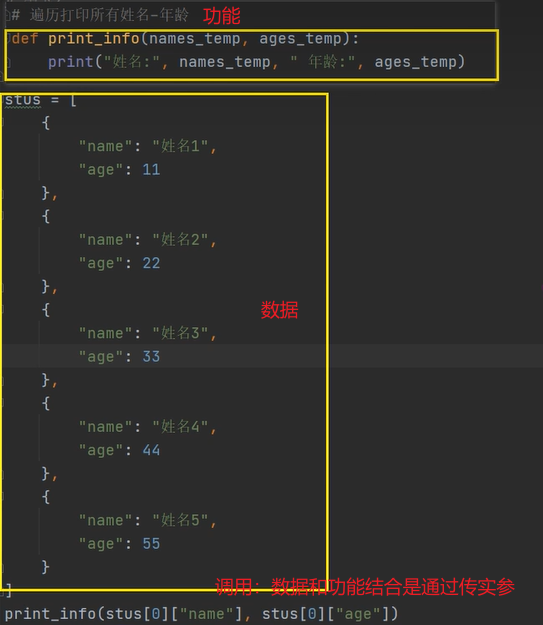
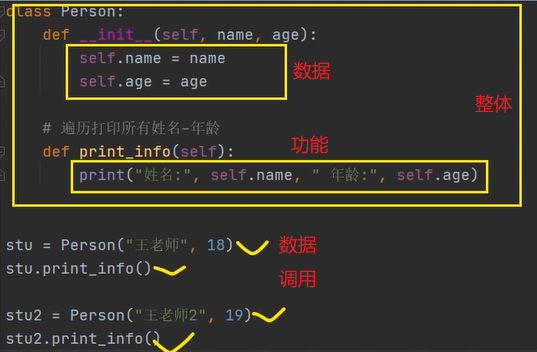
面向对象VS面向过程
面向过程:数据和功能分离,下标错位/全局变量等易乱套
面向对象:数据和功能形成整体
面向对象编程有3个特征:封装 继承 多态
|
|
一、类
- 经典类(旧式类):class 类名
- 新式类定义形式: class 类名(object) (object 是Python 里所有类的最顶级父类)
1. 属性成员
2. 方法成员
3. 静态类型
class 类名:
@staticmethod
def A(): # 形参不含self
pass
实例对象.静态方法()# 调用
类名.静态方法() # 调用4. 类属性、类方法、类对象
当通过同一个类创建了多个实例对象之后,每个实例对象之间是相互隔离的。
- 类属性:多个对象之间共享数据
class 类名:
类属性 = ....
def __init__(self, name):
.....
类名.类属性名 #调用 - 类方法:对类属性进行操作
class 类名:
@classmethod
def 类方法名(cls): # cls指向类对象
pass
类名.类方法名 #调用
对象名.类方法名 #调用 - 类对象:定义的类其实就是一个对象,为将其与自身实例化后的对象区分,将其叫做类对象
实例化对象是由类对象创建的,类对象对于实例化对象而言是共享的,实例对象只存储各自独有的
- 类属性
- 所有的方法(魔法方法、实例方法、静态方法 、类方法)
5.dir(类名) 魔法属性
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__']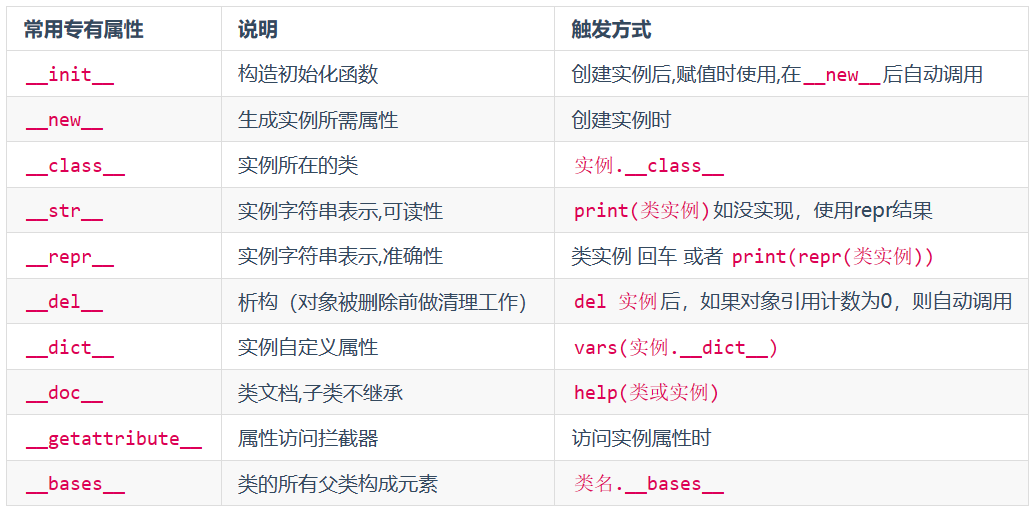
二、对象
1. 对象定义
- 对象名 = 类名(参数)
2. 成员访问
- 对象名.属性
- 对象名.方法(实参)
3. self 自动指向实例对象
- self仅仅是一个变量名,也可将self换为其他任意的名字
- self会在类定义方法时自动填写
5. 对象关联
- 对象名.属性名=另外一个对象名
- 另外一个对象的引用当作实参
三、继承
Class类名(Class1,Class2...)
重写:对象调用时先子类后父类查找,所以子类中的方法可覆盖父类中的同名方法,从而改写
super().父类方法名():在父类的基础上进一步新增而已
四、多态
Python中的多态体现的非常不明显,因为Python不需要写类型
第五章 结构与算法
10 个数据结构:数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、Trie 树;
10 个算法:递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法。















 3380
3380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









