







第一章 计算机系统
哈佛结构是一种将程序指令存储和数据存储分开的存储器结构。目前使用哈佛结构的中央处理器和微控制器有很多,ARM9、ARM10和ARM11,51单片机属于哈佛结构。
冯·诺伊曼结构也称普林斯顿结构,是一种将程序指令存储器和数据存储器合并在一起的存储器结构。根据这一原理制造的计算机被称为冯·诺依曼结构计算机
**程序存储:**指令以代码的形式事先输入到计算机的主存储器中,然后按其在存储器中的首地址执行程序的第一条指令,以后就按该程序的规定顺序执行其他指令,直至程序执行结束。即按地址访问并顺序执行指令
- 计算机硬件系统由五大部件组成(存储器、运算器、控制器、输出设备、输入设备)
- 指令和数据以同等地位存于存储器,可按地址寻访
- 指令和数据用二进制表示
- 指令由操作码和地址码组成
- 存储程序
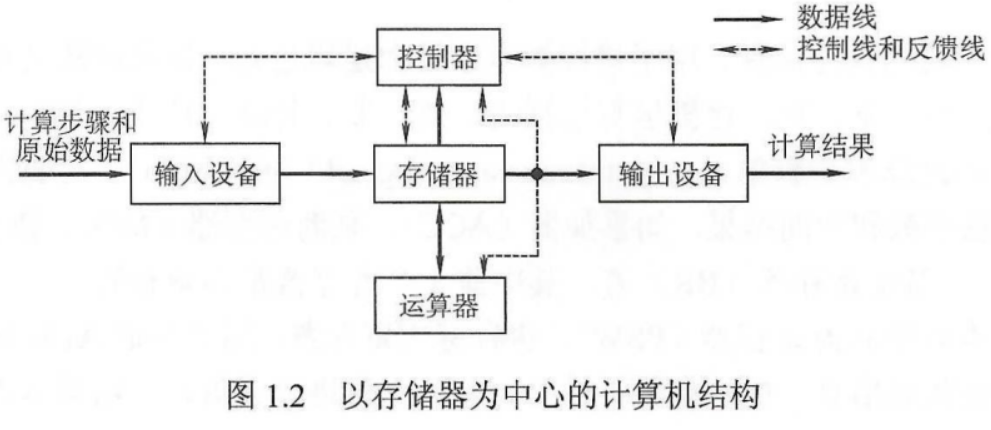
以运算器为中心,且是单处理机,基本工作方式是控制流驱动方式!
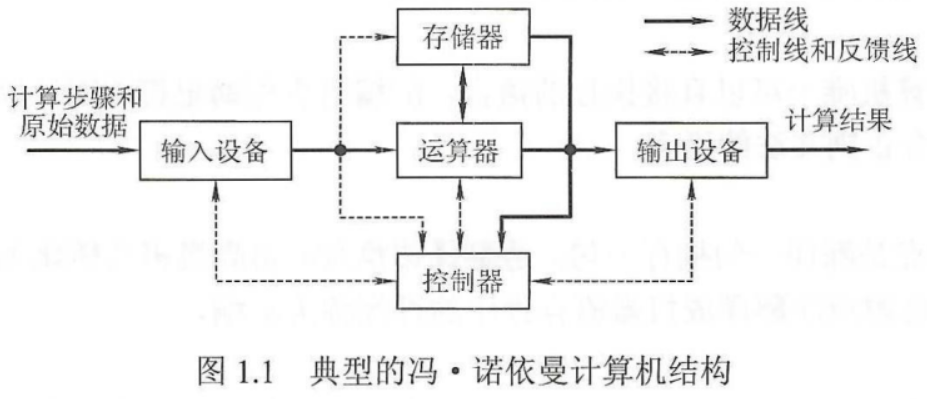
一、计算机工作原理
1. 计算机指令格式
指令是能够被计算机识别的二进制代码,用于指示计算机执行某种操作。
- 计算机指令 = 操作码+操作数(地址码)
2.计算机指令的寻址方式
- 指令寻址
- 顺序寻址
- 跳跃寻址
-
数据寻址
- 立即寻址(所需操作数由指令的地址码部分直接给出)
- 直接寻址(指令的地址码部分给出操作数在存储器中的地址)
- 隐含寻址(操作数隐含在操作码或某个寄存器中)
- 间接寻址、寄存器寻址、寄存器间接寻址等
3. 计算机指令系统
一台计算机有多种作用不同的指令,所有指令的集合称为计算机指令系统。
- 数据传送指令
- 程序控制指令
- 数据处理指令
- 输入/输出指令
- 其他指令
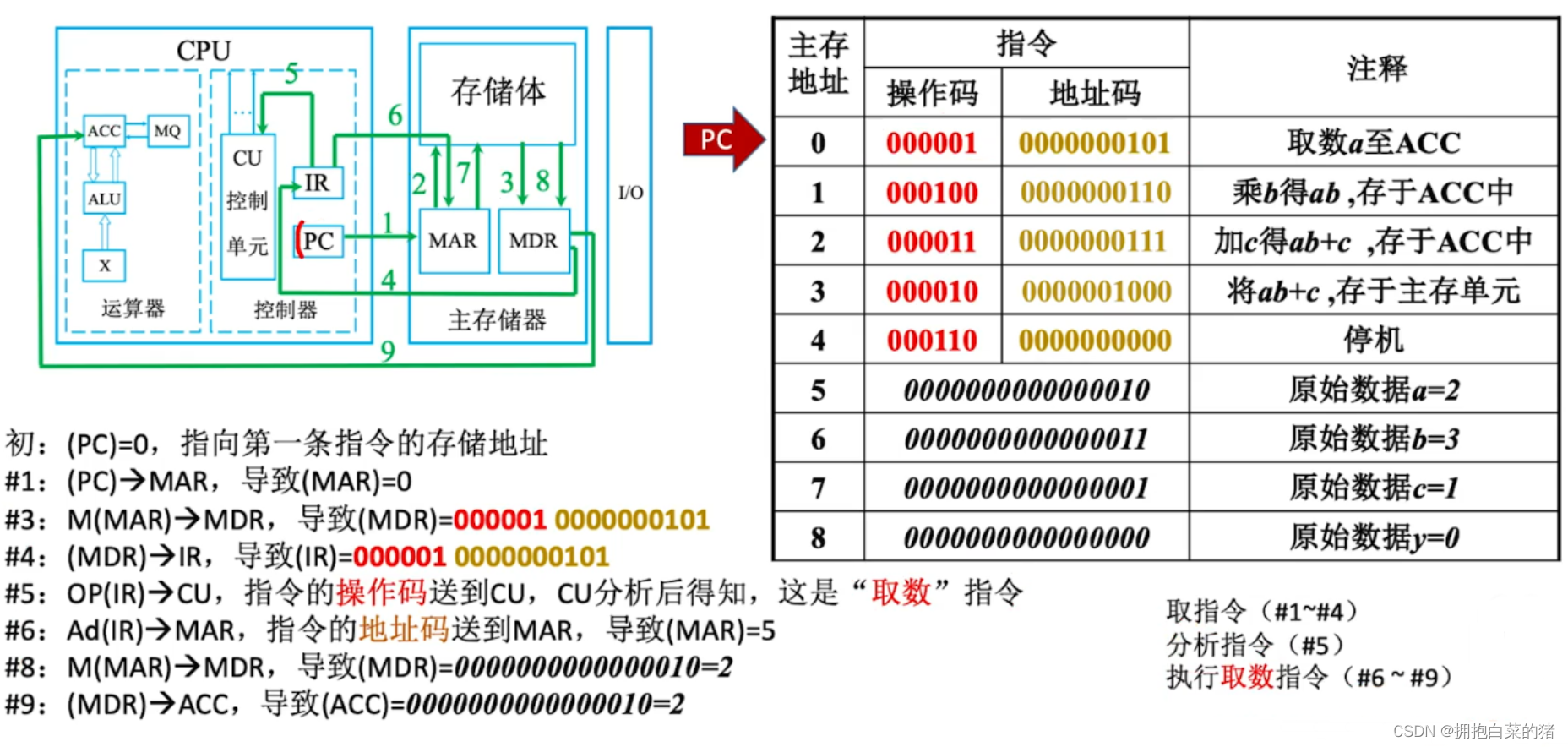
4. 计算机执行指令的基本过程
- 取指令:按照程序计数器地址,从内存储器中取出当前要执行的指令送到指令寄存器
- 分析指令:由译码器对指令中的操作码进行译码,将指令中的操作码转换成相应的控制信息,由指令中的指令码确定操作数存放的地址
- 执行指令:由控制电路发出一系列控制信息,由源地址码所指出的源操作数做该指令所要求的操作,并将操作结果放到由目的地址吗指出的地方
- 修改程序计数器:一条指令执行完后,根据程序的要求修改程序的计数器的值
5.指令执行的时序
- 机器周期:内存中读取一个指令字的最短时间,每个机器周期至少完成一个基本操作
- 指令周期:计算机完成一条指令所花费的时间
二、计算机硬件系统
现代计算机组结构
- 控制器:获取指令、分析指令、执行指令、存储结果
- 运算器:执行算术运算和逻辑运算、数据的比较、移位等操作,并控制速度
- 存储器:
- 内存-主存储器
- 只读存储器ROM:断电保存,容量小,存放固定的程序和数据
- 随机存储器RAM:可读可写,断电后信息丢失
- 静态随机存储器SRAM:速度快,一般应用在CPU内部作为Cache
- 动态随机存储器DRAM
- 高速缓冲存储器Cache:解决CPU和内存之间的的速度冲突问题
- 外存-辅助存储器
- 磁盘/光盘/闪存(SD卡 CF卡 MMC卡)
- 内存-主存储器
- 输入设备:键盘、鼠标
- 输出设备:显示终端、打印机


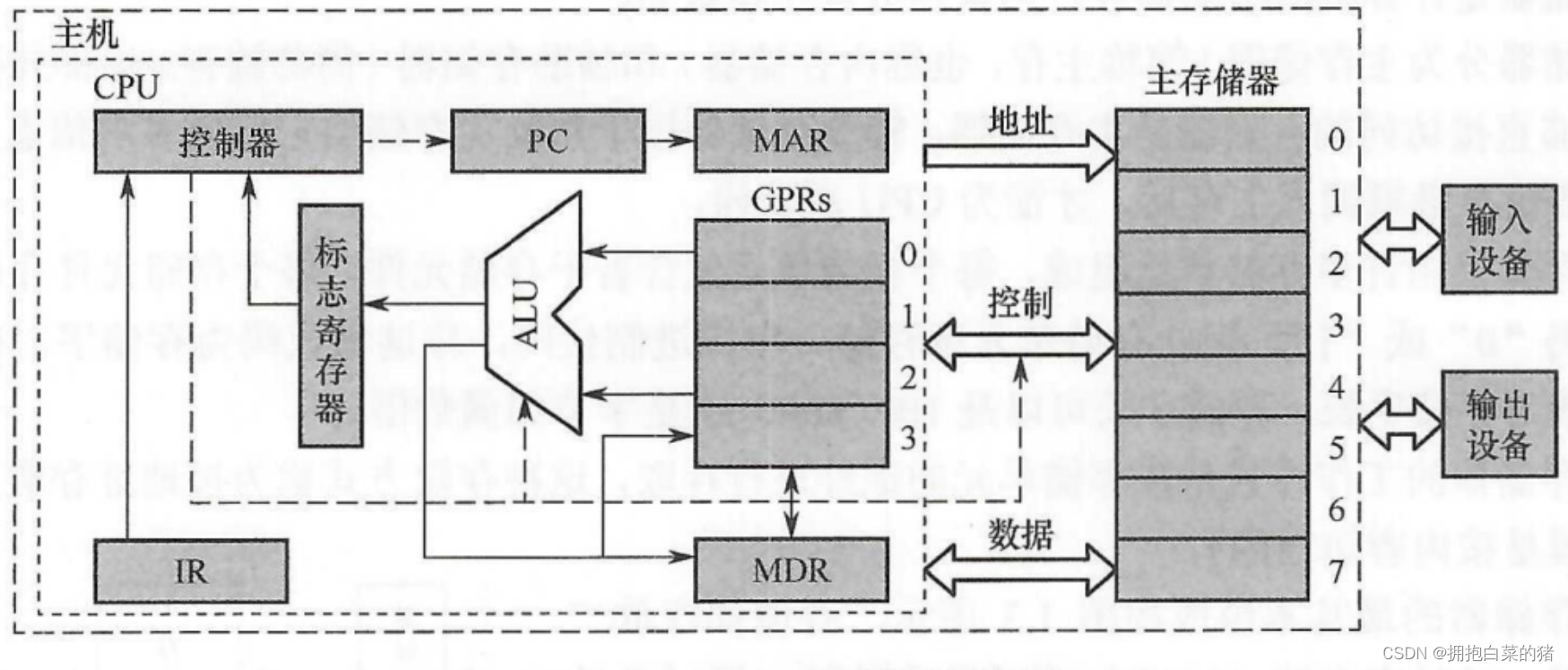
- IR存放当下欲执行的指令;PC存放下一条指令的地址;
- MAR存放欲访问的存储单元地址;MDR存放从存储单元取来的数据

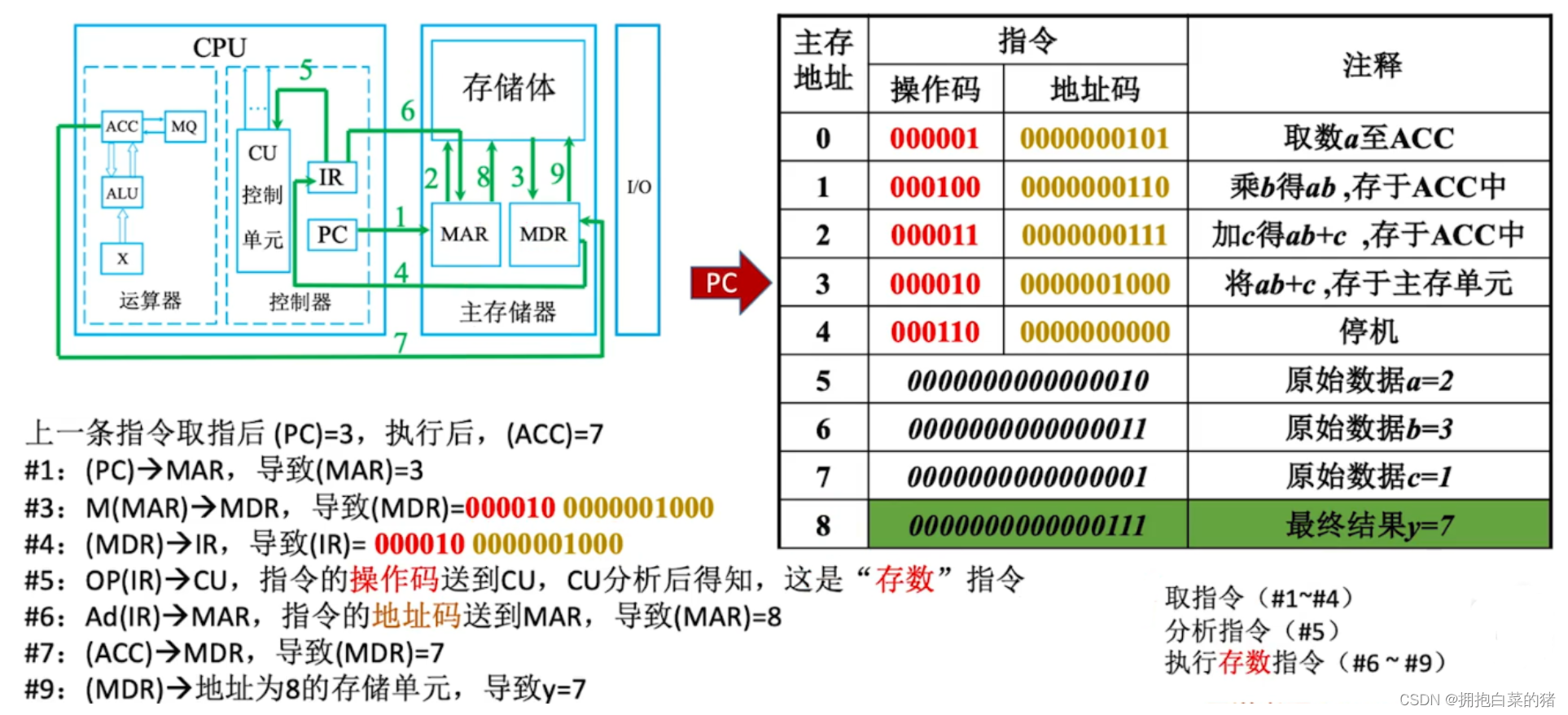
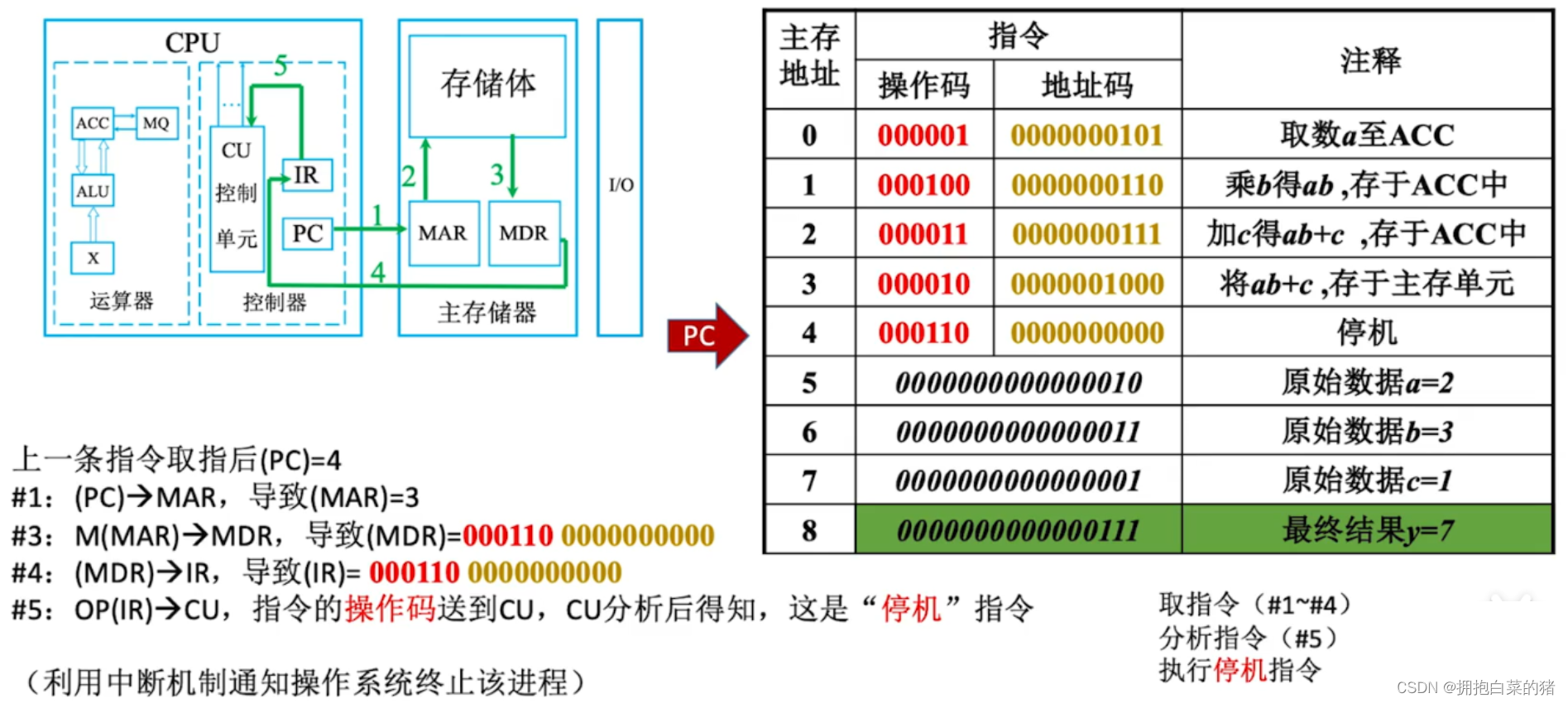
三、总线
总线是连接计算机中各个部件的信息传输线,是各个部件共享的传输介质
- 片内总线:芯片内部的总线
- 系统总线:计算机各部件之间的信息传输线
- 数据总线:双向 与机器字长、存储字长有关
- 地址总线:单向 与存储地址、I/O地址有关,由CPU发出
- 控制总线:有出 有入,存储器读、存储器写、总线允许、中断确认
- 通信总线:计算机系统之间或计算机系统与其他系统(如控制仪表、移动通信等)之间的通信
- 串行通信总线
- 并行通信总线
第二章 数据存储
机器内存中只能存储二进制0和1,所以当我们想要使用各式各样的符号时,只要使用对应的ASCII码,编译器会将它们转换成二进制编码,进而被机器识别。
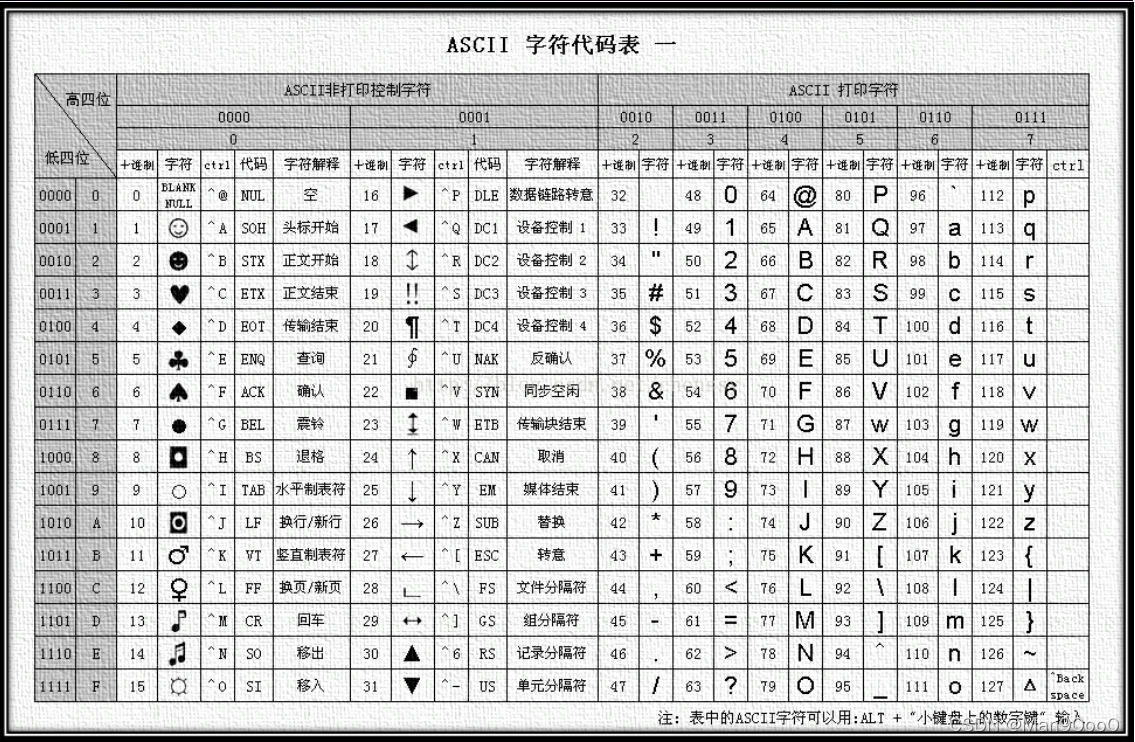
一、数据的内部表示
1.进位计数制及其相互转换
- 基数:拥有的数字个数
- 权 : 每位数字的值
(1)分类
- 无符号数:非负整数,机器的字长的全部位数均用来表示数值大小
- 带符号数:符号位(机器数): 0为正 1为负
(2)编码
- 原码:符号位(0为正 1为负)+绝对值
- 反码:
- 正数:反码=原码
- 负数:反码=符号位+绝对值各位取反
- 补码:
- 正数:补码=原码
- 负数:补码=反码+1
-
偏移码:补码的符号位取反
(3)运算
- 加减运算
- 算数移位运算(操作数符号不变)
- 逻辑移位运算(无符号数移位)
3.浮点数的表示和运算

二、大小端存储
大小端只是针对字节的,对于仅有一个字节的char类型来说,无所谓大小端,即不谈大小端。
- 大端模式:数据的低位保存在内存的高地址中,而数据的高位保存在内存的低地址中
- 小端模式:数据的低位保存在内存的低地址中,而数据的高位保存在内存的高地址中
为什么有大端和小端?
因为在计算机系统中是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit。 但是在C语言中除了8 bit的char外,还有16 bit的short型,32 bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端和小端存储模式。
我们常用的 X86 结构是小端模式,而 KEIL C51 则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
第三章 程序编译
源文件先经过编译器编译为目标文件,最后由链接器将库文件和目标文件结合,成为可执行文件。


一、编译
1. 预编译Preprocessing
- 将头文件的声明导入源文件中
- #define 的替换
- 删除注释
2. 编译Compilation:将C语言代码转为汇编代码
- 语法分析
- 词法分析
- 语义分析
- 符号汇总:将全局变量以及函数形成一个符号
3. 汇编Assembly:将汇编代码转为二进制文件,生成 .o 文件
一个符号是一个标识,汇编时会给符号一个地址,最终将所有符号及其地址组合,生成符号表。
二、链接
Linking:相同内容进行合并
1. 合并段表
- 每一个汇编后的 .o 文件都有一个段
- 如果x.c调用了y.c,这两个段会结合在一起,即.o文件的结合,最终形成段表。
2. 符号表的合并和重定位
main函数内的全局变量与函数只能算一个标识,没有自己的意义,靠着这个标识去找到main函数外的函数或者全局变量。一旦找到,就是将他们的符号表合并。

三、运行
- 程序先载入内存中,一般由操作系统完成。
- 程序的执行便开始,接着便调用main函数。
- 开始执行程序代码。这个时候程序将使用一个运行时堆栈(stack),存储函数的局部变量和返回地址。程序同时也可以使用静态(static)内存,存储于静态内存中的变量在程序的整个执行过程并一直保留他们的值。
- 终止程序。正常终止main函数;也有可能是意外终止。
四、GCC/G++
安装TDM-GCC / MinGW-w64
| GCC 选项 | 说明 | 案例 |
|---|---|---|
| -E | 预处理指定的源文件,不进行编译 | gcc -E hello.c -o hello.i |
| -S | 编译指定的源文件,不进行汇编 | gcc -S hello.i -o hello.s |
| -c | 汇编指定的源文件,不进行链接 | gcc -c hello.s -o hello.o |
| -o | 将一至多个源文件直接生成可执行文件 | g++ test.cpp -o test (test为指定输出文件名) |
| -I [大写 i] | 指定头文件搜索目录 /usr/include 里的不用指定 | g++ -I ./myinclude test.cpp -o test |
| -l [library] | 编译时指定库文件 | g++ -l glog test.cpp -o test |
| -L | 编译时指定库文件路径 /lib 和 /usr/lib 和 /usr/local/lib 里的不用指定 | g++ -L /home/mylib -l mytest test.cpp -o test |
| -fpic/fPIC | 生成与位置无关的代码(静态/动态库) | g++ test.cpp -I ./include -fPIC -shared -o mylib.so |
| -std | 设置编译标准 | g++ -std=c++11 test.cpp |
| -O[n] | n范围:0~3,编译器优化选项的4个级别 | |
| -g | 编译带调试信息的可执行文件 | g++ -g test.cpp -o test |
| -D | 在程序编译的时候,指定一个宏 | |
| -Wall | 生成gcc提供的警告信息 | g++ -wall test.cpp |
| -w | 关闭所有警告信息 | g++ -w test.cpp |
五、CMake
Linux学习日记22——vscode和cmake_linux vscode cmake_herb.dr的博客-CSDN博客
安装CMake,编写 CMake 配置文件 CMakeLists.txt
基本语法格式
- 指令(参数1 参数2 ...) ,参数之间使用空格或分号分开
- 指令不分大小写,参数和变量区分大小写
- 变量取值${var} :${PROJECT_NAME}工程名 ${PROJECT_SOURCE_DIR}工程路径
重要指令
| CMake 指令 | 语法 |
|---|---|
| 指定 CMake 的最小版本要求 | cmake_minimum_required (VERSION 3.15) |
| 定义Cmake工程名称 | project (Project-Name) |
| 显式的定义变量 | set (SRC_LIST [source1 source2 ... sourceN]) |
| 添加头文件路径 == g++ -I参数 | include_directories (dir1 dir2 ...) |
| 同目录下所有的源文件存在变量中 | aux_source_directory(dir var) |
| 生成可执行文件 | add_executable(exename source1 source2 ... sourceN) |
| 链接共享库== g++ -I参数 | target_link_libraries(target library1 library2...) |
| 生成共享/静态库文件 | add_ library(libname SHARED/STATIC source1 source2... sourceN) |
| 添加库文件路径== g++ -L参数 | link_directories(dir1 dir2 ....) |
| 添加编译参数 | add_compile_options(-Wall -std=c++11 -02 ...) |
| 添加存放源文件的子目录 | add_subdirectory(sub_dir) |
# 1. 在当前目录下,创建 build 文件夹
mkdir build
# 2. 进入到 bui1d 文件夹
cd build
# 3. 编译上级月录的 CMakeLists.txt,生成 Makefile 和其他文件
cmake
# 4. 执行 make 命令,生成 target
make含opencv的例子:
cmake_minimum_required ( VERSION 3.15 )
set(PROJECT_NAME Test)
set(SRC test.cpp)
project(${PROJECT_NAME})
find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})
link_directories(${OpenCV_LIB_DIRS})
add_executable(${PROJECT_NAME} ${SRC})
target_link_libraries(${PROJECT_NAME} ${OpenCV_LIBS})
第四章 操作系统
一、OS
计算机操作系统概述(计算机操作系统入门指南)_麟先生Coding的博客-CSDN博客
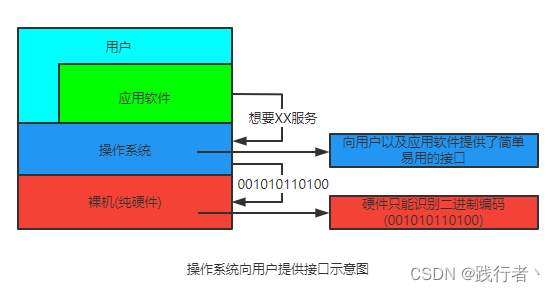
(1)操作系统功能
- 作为计算机系统资源的管理者:处理机管理、存储器管理、设备管理和文件管理
- 作为用户与计算机硬件系统之间的接口:命令接口和程序接口
- 作为对计算机资源的扩充:给予裸机灵魂
(2)操作系统的特征
- 并行:指两个或多个事件在同一个时刻同时发生
- 多核CPU同一时刻可以同时执行多个程序,多个程序可以并行地执行
- 并发:指两个或多个事件在同一时间间隔内发生(宏观同时微观交替)
- 单核CPU同一时刻只能执行一个程序,各个程序只能并发地执行
- 共享:并发和共享互为存在条件
- 互斥共享:当资源被程序占用时,其它想使用的程序只能等待
- 同时共享:某种资源并发的被多个程序访问
- 虚拟性:虚拟和异步特性前提是具有并发性
- 时分复用技术:如虚拟处理器,资源在时间上进行复用,不同程序并发使用
- 空分复用技术:如虚拟磁盘、虚拟内存等
- 异步性:多个进程的执行以“停停走走”的方式运行,而且每个进程执行的情况也是未知的
(3)操作系统的运行机制
- 两种指令:特权指令与非特权指令
- 两种程序:内核程序与用户程序
- 两种状态:用户态与内核态
-
系统内核:
- 时钟管理
- 中断机制
- 原语:操作系统的最底层,是最接近硬件的部分,运行一气呵成,无法被中断
- 系统控制的数据结构及处理:进程管理、存储器管理、设备管理
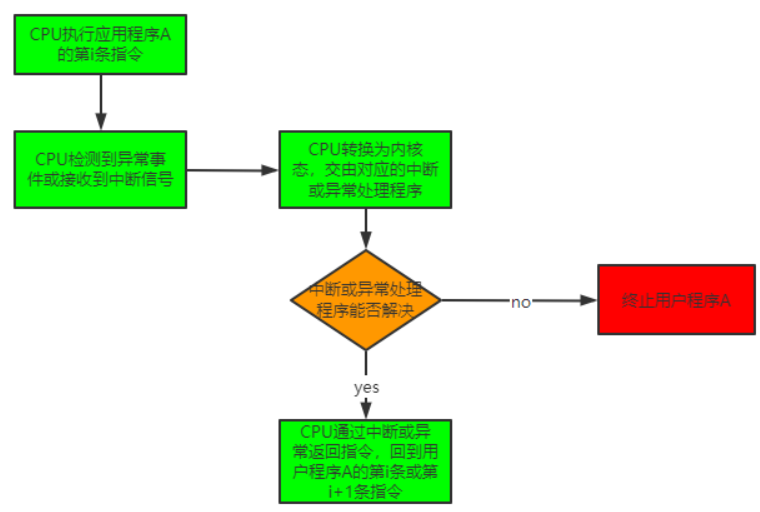
(4)中断和异常
- 外中断:时钟中断、I/O中断强求
- 内中断:陷入、故障、终止
二、进程
【操作系统-进程】进程的概念_进程和进程实体_Mount256的博客-CSDN博客
进程是进程实体的运行过程,是系统进行资源分配、拥有资源和调度的一个基本单位。
(1)进程实体:进程是动态的,进程实体(进程映像)是静态的
- 进程控制块PCB:用于描述和控制进程运行的通用数据结构,记录进程当前状态和控制进程运行的全部信息,是进程存在的唯一标识。
- 程序段:程序的代码(指令序列)
- 数据段:运行过程中产生的数据
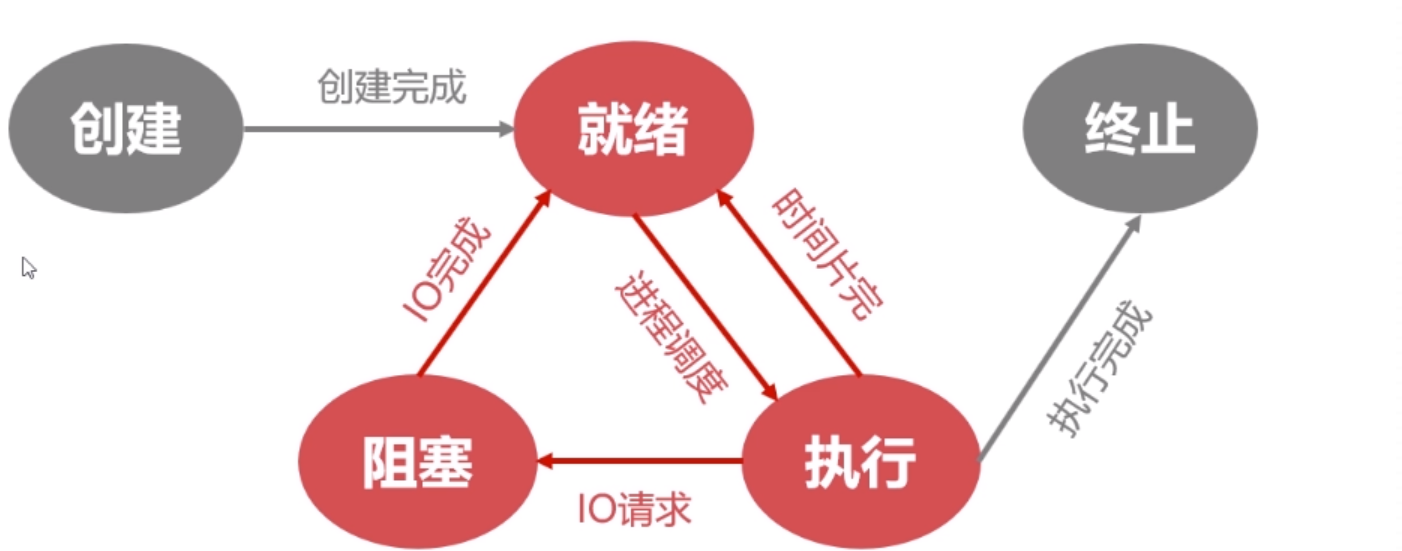
(2)进程的状态
- 创建:创建进程时拥有进程控制块但其它资源尚未就绪
- 就绪:进程控制块、内存、栈空间、堆空间等资源都准备好,一旦获取cpu便可执行。
- 运行:进程获得CPU,其程序正在执行。
- 阻塞:进程在执行中因某原因放弃CPU的状态,阻塞进程以队列的形式放置
- 终止:进程结束由系统清理或者归还进程控制块的状态
创建进程:
from multiprocessing import process
def fun():
...
p=process(target=fun)
p.start()from multiprocessing import process
class MyNewProcess(process):
def run(self):
...
p=MyNewProcess()
p.start()(3)进程间通信
- 管道(pipe):半双工、具有固定的读端和写端,用于具有亲缘关系(父子/兄弟)进程间的通信,通过内核缓冲区实现数据传输。
- 有名管道(named pipe):以磁盘文件的方式存在,在系统中有对应的路径,可以实现本机任两个进程间通信。管道的本质是内核维护了一块缓冲区与管道文件相关联,对管道文件的操作被内核转换成对这块缓冲区内存的操作
- 信号(signal):是在软件层次上对中断机制的一种模拟,它是比较复杂的通信方式,用于通知进程有某事件发生,一个进程收到一个信号与处理器收到一个中断请求效果上是一致的
- 信号量(semaphore):是一个计数器,主要作为进程之间及同一种进程的不同线程之间得对共享数据的同步和互斥手段
- 消息队列(message queue):消息的链接表,是一系列保存在内核中消息的列表。优势是对每个消息指定待定的消息类型,接收的时候不需要照队列次序,而是可以自定义条件接收持定类型的消息
- 共享内存(shared memory):使得多个进程可以访问同一块内存空间,多个进程将同一块物理内存(用户空间)映射到自己的虚拟地址空间中。
- 套接字(socket):用于网络中不同机器之间的进程间通信
三、线程
| 项目 | 引入进程和线程的操作系统 | 仅引入进程的操作系统 |
|---|---|---|
| 状态 | 线程和进程都有创建态、就绪态、运行态、阻塞态、终止态 | 进程有创建态、就绪态、运行态、阻塞态、终止态 |
| 组成 | 线程 ID、线程控制块(TCB);进程 ID、进程控制块PCB | 进程 ID、进程控制块PCB |
| 调度 | 同一进程下的线程切换不引起进程切换,调度开销小;从一个进程中的线程切换到另一个进程中的线程引起进程切换(线程是调度的基本单位) | 一定引起进程切换,调度开销大(进程是调度的基本单位) |
| 系统资源 | 进程拥有系统资源,线程不拥有系统资源,但可以访问它从属于进程的系统资源(进程是资源分配的基本单位) | 进程拥有系统资源(进程是资源分配的基本单位) |
| 系统开销 | 创建、撤销、切换线程的开销比进程的小 | 创建、撤销、切换进程的开销大 |
| 独立性 | 每个进程都有自己独立的地址空间,而同一进程的不同线程共享同一地址空间 | 每个进程都有自己独立的地址空间 |
| 处理机 | 多个线程分配在多个处理机上 | 进程只能运行在一个处理机上 |
进程调度算法
- 先来先服务:按照在就绪队列中的先后顺序执行。
- 短进程优先:优先选择就绪队列中估计运行时间最短的进程,不利于长作业进程的执行。
- 高优先权优先:进程附带优先权,优先选择权重高的进程,可以使得紧迫的任务优先处理。
- 时间片轮转:按照FIFO的原则排列就绪进程,每次从队列头部取出待执行进程,分配一个时间片执行,是相对公平的调度算法,但是不能保证就是响应用户。
- 多级反馈队列:不必事先知道各种进程所需要执行的时间,是当前一种较好的进程调度算法
创建线程
import threading
def task 1(num,num2):
pass
t1=threading.Thread(target=函数名,args=(11,),kwargs={"num2":22}) #args必须是元组
t1.start() #真正的创建线程若函数间数据相互影响,进程结束则函数结束,易乱套。因此提出类方式,使数据跟功能成为整体
inport threading
class 类名(threading.Thread)
def run(self):
pass
t1=类名()
t1.start() #自动运行run方法(不能用t1.run)线程间通信
- 互斥量(锁):只有拥有互斥量的线程才能执行任务
- 信号量(semaphore):是一个计数器
- 事件:事件机制,允许一个线程在处理完一个任务后,主动唤醒另外一个线程执行任务
队列:
- 队列Queue:先进先出(FIFO),可以存放任意类型数据
- 堆栈Queue:后进先出(LIFO),可以存放任意数据类型
- 优先级Queue: 存放的是元组类型,第1个元素表示优先级,第2个表示存储的数据
- 优先级数字越小优先级越高,数据优先级高的优先被取出
Queue.qsize():返回当前队列包含的消息数量
Queue.empty():如果队列为空,返回True,反之False
Queue.full():如果队列满了,返回True,反之False
Queue.get([block[, timeout]]):获取队列中的一条消息,然后将其从列队中移除,block默认值为True
i. 如果block使用默认值,且没有设置timeout(单位秒),消息列队如果为空,此时程序将被阻塞(停在读取状态),直到从消息列队读到消息为止,如果设置了timeout,则会等待timeout秒,若还没读取到任何消息,则抛出Queue.Empty异常
ii. 如果block值为False,消息列队如果为空,则会立刻抛出Queue.Empty异常
Queue.get_nowait():相当Queue.get(False)
Queue.put(item,[block[, timeout]]):将item消息写入队列,block默认值为True
i. 如果block使用默认值,且没有设置timeout(单位秒),消息列队如果已经没有空间可写入,此时程序将被阻塞(停在写入状态),直到从消息列队腾出空间为止,如果设置了timeout,则会等待timeout秒,若还没空间,则抛出Queue.Full异常
ii. 如果block值为False,消息列队如果没有空间可写入,则会立刻抛出Queue.Full异常
g. Queue.put_nowait(item):相当Queue.put(item, False)全局变量:
通过全局变量可以解决多个线程之间共享数据的问题,但是,使用不够恰当会乱套
- 线程对全局变量随意遂改可能造成多线程之间对全局变量的混乱(即线程非安全)
- 此外,如果多个线程同时对同一个全局变量操作,会出现资源竞争问题,从而数据结果会不正确 解决方法:互斥锁
# 创建锁(全局)
mutex = threading.Lock()
# 锁定
mutex.acquire()
......#中间的内容不被打扰
# 释放
mutex.release()进程池:
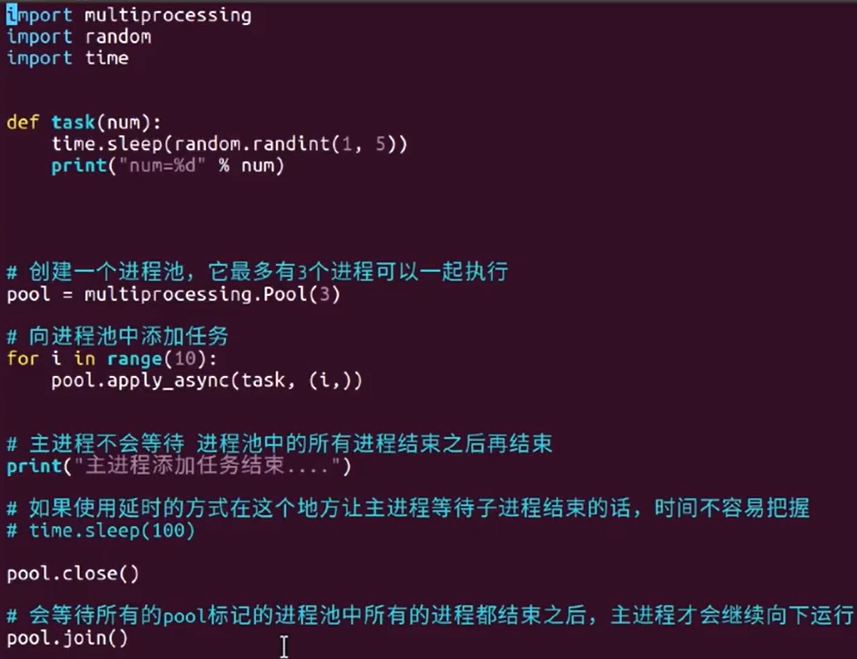
进程池可以让创建的进程重复利用,而之前的进程函数执行完进程也就结束了,创建一个进程和释放一个进程的所用到的资源比较多,频繁创建和释放反而不会加快代码执行,进程池可节省资源使用
第五章 开机自启动
上电开机:Delete键/F11进入BIOS—Advanced—Restore AC Power Loss—Power on F10保存
1. Windows
Win + R—shell:startup—把要开机自启的程序文件或快捷方式复制到打开的窗口中即可
Windows设置程序开机自启动的几种方法(整理发布)_开机自启动设置-CSDN博客
2. Linux
ubuntu开机自启python_JulyLi2019的博客-CSDN博客
要激活虚拟环境,才可正确运行下载的库
#!/bin/bash
cd /home/XXX/Projects/Project/
source venv/bin/activate
python3 XXX.pysudo chmod -R 777 run.sh
gnome-terminal -- bash -c /home/XXX/Projects/Project/run.sh















 8237
8237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









