







偏标签学习的研究现状
现有的偏标签学习的消歧方法大致可分为三类:基于平均的消歧策略(Averaging-based Disambiguation Strategies)、基于辨识的消歧策略(Identification-based Disambiguation Strategies)和基于流形假设的消歧策略(Manifold Assumption-based Disambiguation Strategies)。
1.基于平均的消歧策略,通过给候选标签中的标签赋予每个样本相同的权重来识别真实标签,然后通过对所有候选标签或其邻域中的候选标签的输出进行平均来获得预测。遵循这种策略,基于平均的消歧策略可以进一步分为基于辨识的学习方法和基于实例的学习方法。
2.基于辨识的消歧策略,不同于基于平均的消歧策略,现有的基于辨识的消歧策略通过将真实标签直接确定为 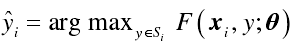
的方式,将其视为潜在变量。
3.基于流形假设的消歧策略,不同于上述策略利用候选标签集构造偏标签学习算法。由于上述策略的泛化能力上限通常受到噪声标签的限制,因此为了突破这一局限性,基于流形假设的消歧策略,利用了流形假设认为相似的样本向量拥有相似的输出这一特性,尽可能从偏标记数据集中挖掘有用的信息。
reference
[1]闵子剑.(2020).适用于偏标记学习的概率传播算法(硕士学位论文,重庆邮电大学).https://kns.cnki.net/KCMS/detail/detail.aspx?dbname=CMFD202101&filename=1020416843.nh















 204
204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









