







1 论文基本信息
题目:一种新型的不平衡分类模型(DDAE)
作者:Jian Yin,1,4 Chunjing Gan,1,4 Kaiqi Zhao,2 Xuan Lin,3 Zhe Quan,3 Zhi-Jie Wang1,4,5,*
1中山大学数据与计算机科学学院,广州,中国
2奥克兰大学计算机科学学院,新西兰奥克兰
3湖南大学信息科学与工程学院,长沙
4广东省大数据分析与处理重点实验室,广州,中国
5大数据分析与应用国家工程实验室,北京,中国
期刊会议:The Thirty-Fourth AAAI Conference on Artificial Intelligence
2 论文的主要内容
本文关注于不平衡数据的分类问题,在他人研究的基础上进行整合,将不平衡分布,代价敏感学习,数据空间改进,集成学习等学习方法进行融合,提出了一种新型的模型来解决不平衡二分类问题的限制,最后在多个数据集上进行测试并评价。
2.1 介绍
本模型集成了采样技术,数据空间构建,代价敏感学习,集成学习等算法和技术。
具体地说,该模型主要有四个部分组成:
数据块构建组件(DBC):使用欠采样或是过采样技术将数据集分为平衡的数据。
数据空间改进组件(DSI):改变数据空间以便数据样本可以接近(K近邻数据)拥有同样的标签的数据,并且可以与其他的类间隔较大。
自适应权重调整组件(AWA):为集成学习组件获取class-wise权重,以减轻“不稳定样本”带来的问题。
集成学习组件(EL):结合了多种分类器,根据权重投票得出最终的分类结果。
2.2 相关的工作
采样理论
代价敏感理论
集成学习理论
2.3 不平衡分类模型
DDAE:DBC,DSI,AWA,EL。
主要流程如下所述:
Step 0:将数据集划分为训练数据集和测试数据集;
Step 1:从训练数据集中取出数据放到DBC组件中,获得大量的平衡数据块;
Step 2:将每个数据块送到DSI组件中以改善数据空间;与此同时,AWA组件在每个数据块的基础上计算class-wise权重;
Step 3:其次,将被DSI处理过的数据应用基础的分类算法(K近邻),EL组件共同利用权重和基础分类器来产生分类标签,最终训练模型被应用到测试集。
2.3.1 数据块构造
将数据集分类多个子集,保证每个子集大致相同,用过采样技术复制少数的样本,将每个子集的副本和多数集的子集结合,仅适用每个块多数样本的一部分(欠采样技术)。
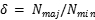
算法流程:
Input:数据集D
Output:数据块中的一个数据集B
1:基于数据集D获得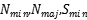 ,和
,和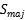
2:将多数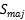 分成
分成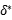
3:对于i从1到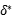 做一下循环
做一下循环
4:将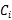 和
和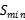 放到空的数据块
放到空的数据块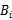 中。
中。
5:结束循环
6:返回数据集B
2.3.2 数据空间改进
该模型结合了度量学习技术,采用大间距近邻算法(large margin nearest neighbor (LMNN) algorithm)。此算法的主要作用是学习一个变换矩阵L,合并了损失函数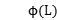 ,可以将不同标签的数据样本之间的距离尽可能的推远,将具有相同标签的数据样本尽可能的拉近,损失函数如下:
,可以将不同标签的数据样本之间的距离尽可能的推远,将具有相同标签的数据样本尽可能的拉近,损失函数如下:

 是一个正实数被用作两个部件push/pull(推拉)的权重,
是一个正实数被用作两个部件push/pull(推拉)的权重,
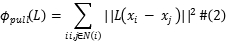
 .
.
N(i):是数据i的K近邻具有相同的标签。
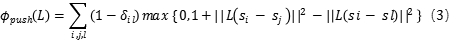
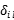 用以确定
用以确定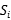 和
和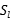 是否属于相同的类别。其值为1或0.
是否属于相同的类别。其值为1或0.
2.3.3 自适应权重调整
KNN的弊端:当数据周围的正值邻居和负值邻居的数量很近似时,此时KNN分类器就很难确定该数据的分类,将正负数据之差的绝对值设为positive****-**negative count difference (PNCD)。**
如果PNCD大于阈值 τ,便把这个样本当做稳定样本,否则当做不稳定样本。
不稳定混淆矩阵:
| Sample | Predict as negative | Predict as Positive |
|---|---|---|
| Positive | 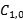 |  C
1
,
1
C_{1,1}
C1,1
C
1
,
1
C_{1,1}
C1,1 |
| Negative | 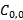 | 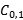 |
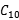 :正样本被预测为负样本的数据个数。
:正样本被预测为负样本的数据个数。
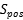 :真实标签是正值的数样本,
:真实标签是正值的数样本,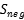 :真实标签是负值的数据样本
:真实标签是负值的数据样本
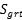 :正值预测大于负值预测的不稳定样本的数量,
:正值预测大于负值预测的不稳定样本的数量,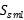 : 负值预测大于正值预测的不稳定样本的数量
: 负值预测大于正值预测的不稳定样本的数量
其中: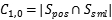
在非平衡数据集中,小类的损失代价要大于大类的损失代价。(不失一般性),假设大小样本之间的损失率为**x,**AWA的主要目的是为正值和负值输出调整权重,最大化不稳定混淆矩阵的总体增益,初始状态下,默认权重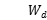 设为1.尝试调整正值输出的权重,设
设为1.尝试调整正值输出的权重,设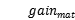 为总体增益(保持默认权重时),
为总体增益(保持默认权重时),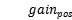 (调高正值权重),
(调高正值权重),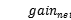 (调高负值权重)。
(调高负值权重)。
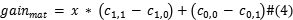
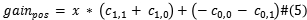
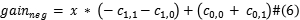
之后,根据最大增益调整权重.
如果最大增益是mat,则将正负输出的权重设为 ,否则选取最大增益,更新协同权重
,否则选取最大增益,更新协同权重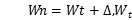 是权重阈值,
是权重阈值, 是一个小的实数。
是一个小的实数。
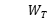 的计算公式如下所示:
的计算公式如下所示:
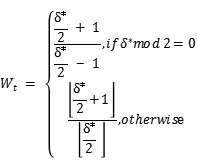
最后考虑从所有数据块中获得的权重对,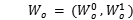 。基于不同权重对的频率。如果比例是小于阈值的
。基于不同权重对的频率。如果比例是小于阈值的 的,
的,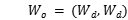 .
.
2.3.4 集成学习
多个分类器共同合作投票选出最终的决策结果。在二分类问题下,设有m个分类器,两个分类类别,如果第i个分类器的输出是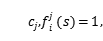 否则为0.
否则为0.
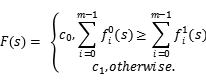
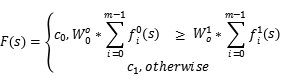
3 测试对比
测试使用14个数据集。分别和四种算法进行比较
(IML,RP,CAdaMEC,MWMOTE)进行比较,:使用G-mean, F-measure and AUC进行评价。
IML:通过使用迭代矩阵学习技术,构建一个稳定的邻居数据空间,选择k 近邻算法(KNN)作为分类器。
RP:一个基于递归的集成方法,他不平衡分类问题转化为平衡数据分类问题,采用多数投票的集成规则来构建集成分类器。
CAdaMEC:基于带有正确校准的代价损失学习理论,使用决策树作为分类器。
MWMOTE:一个合成过采样理论,它的每一个少数样本都会根据与最近的几个多数样本的欧几里得距离来分配一个权重。然后产生一个来自已标记权重的合成样本。
在测试正类样本极度小的数据集时,IML,CAdaMEC和MWMOTE都把样本分成了负类,并没有检测出正类样本。在检测正类样本方面,此模型做的最好,也表明此模型在检测正类样本时更高效。在某些数据集上可以达到百分百的召回率。
4 结论
测试结果此模型在多数的数据集上跑赢前沿的方法,其中有一半的数据集持续的表现优于对比算法。 :18.6%.
:18.6%.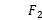 :17.1%.AUC:18.7%.
:17.1%.AUC:18.7%.
但在某些样本中表现较为糟糕,表示本模型倾向于尽可能找到更多正类样本。在高度倾斜的类上表现优异。
5 分析
此模型在他人研究的基础上将多种方法进行融合,其中又有部分的创新。首先此模型在数据采样,空间改进,权重分配,集成学习等方面都进行了工作,尽可能的保证最终的预测结果。
5.1 模型的创新点
在数据处理阶段,一般来说在处理非平衡数据时,对于多数样本采用欠采样或者对于少数样本过采样,这样就可以获得一个比较平衡的数据集。但在此模型中,首先将多数样本分成若干个子集,在对少数样本进行过采样,将少数样本的过采样结果与多数样本的子集结合形成若干个数据块,之后在对数据块进行操作。这样做可以尽可能的保留数据的信息,一般对于多数集采用欠采样算法会导致数据信息的丢失,从而弱化分类器的分类效果,而在此模型中可以最大化的利用有用的数据信息,多个数据块互相补充,最终训练出一个最佳的分类模型。
在数据空间的改进中此模型结合了变换矩阵和损失函数。使得相同类别的标签的数据距离较近,不同类别的数据距离尽可能的远,从而使得训练分类器时更加的容易,准确率也会得到提升。
此外,此模型还可以根据训练结果自适应的调整分类器的权重,并且引入权重对,在处理每一个数据块时都会生成一个权重对,最后根据所有权重对的情况得到此分类器的权重。
且正负输出有着各自的权重。
在其他的集成学习算法中,普遍将每个分类器的权重设为相同的值,通过投票获得最终的分类结果。但这样做容易造成结果的偏差,为了解决这个问题,此模型提出了一种自适应权重调整机制,并且为正负输出分别设置了一个权重,也就是权重对,根据最大增益来调整权重。
一般的集成学习在每个分类器得出结果之后进行投票便得出了最终的分类结果,但在此模型中作者又给所有预测的结果之和添加了一个权重,以此来进一步增强结果的可靠性。
5.2 模型的不足
在测试中,此模型表现较差的情况是在不平衡率最小的数据集上取得的,这表明此方法倾向于找到更多的少数样本,并且在高度不平衡的数据集上表现较好,平衡数据集上的表现反而差强人意。产生这种现象的主要原因应该是少数样本会被赋予更高的权重,在进行分类时自然会向其倾斜,在样本不平衡率较低时反而会影响分类的效果。
5.3 可继续研究的方向
未来的研究方向:扩展模型到多标签的分类器问题。
可以利用聚类方法改进分类结果,
结合其他的分类器:SVM,神经网络。
将模型扩展到图片,时间序列等。















 968
968











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









