







《Grokking DRL》笔记(Chapter 3-4)
Chapter 3
主要内容:如何求解MDPs, agent的目标是什么,两种求解MDPs的算法(动态规划算法):value iteration (VI) and policy iteration (PI)
本章内容只考虑sequential feedback。
The objective of a decision-making agents: maximize the return: the sum of rewards (discounted or undiscounted—depending on the value of gamma) during an episode or the entire life of the agent, depending on the task.
1. 基本概念的定义:
如何定义Return:可以通过以下两种方式进行理解,第一种是反向理解return,在一个Episode内得到了多少奖赏,第二种方式是前向理解,‘reward-to-go’
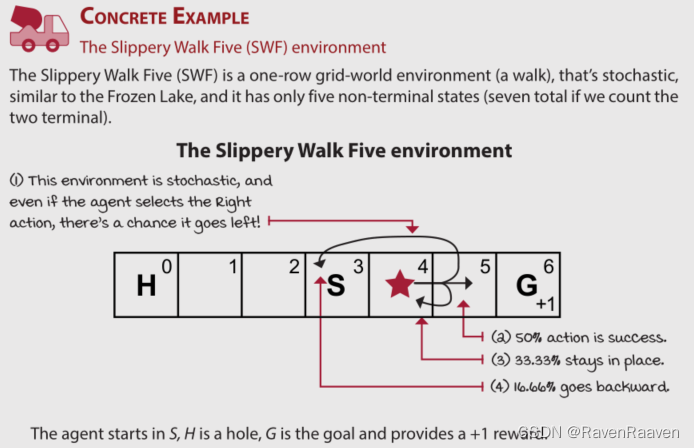
当给定了具体的环境状态转移函数之后,如何定义plan?: a sequence of actions from the START state to the GOAL state. 但没有考虑到环境的随机性。以FL, frozen lake环境为例,
如何定义Policy:需要考虑stochasticity之后的Plan。 衡量policy的好坏的依据是智能体能否最大化expected return.
智能体内部用于寻找最优策略的部分:policies, value function (包括state-value, action-value, action-advantage function)
如何定义State-value function?:

这里最重要的是一种recursive definition的方式,即当前状态的值函数与后续状态的值函数相关(bootstrapping)。V函数不能捕获其他环境的动态。
如何定义action-value function, Q function?: 首先其目的是在同一个policy下对比不同的actions,并选择更好的一个。

如何定义action-advantage function?

其描述的是采用某个具体动作的好坏。而 Q π ( s , a ) Q^{\pi}(s,a) Qπ(s,a)假设遵循策略 π \pi π并且之后采用动作 a a a。
如何定义Optimality?
1,最优策略:An optimal policy is a policy that for every state can obtain expected returns greater than or equal to any other policy。
2,最优state value function:An optimal state-value function is a state-value function with the maximum value across all policies for all states.
3,最优action value function: an action-value function with the maximum value across all policies for all state-action pairs
4,最优action advantage function: 数值大小是equal to or less than zero
最优策略可以不止一个,但三个最优值函数只能有一个。

2. Policy Iteration (Policy evaluation + policy improvement)
如何利用值函数评估策略?:第一种方法是Policy iteration, 第二种是value iteration
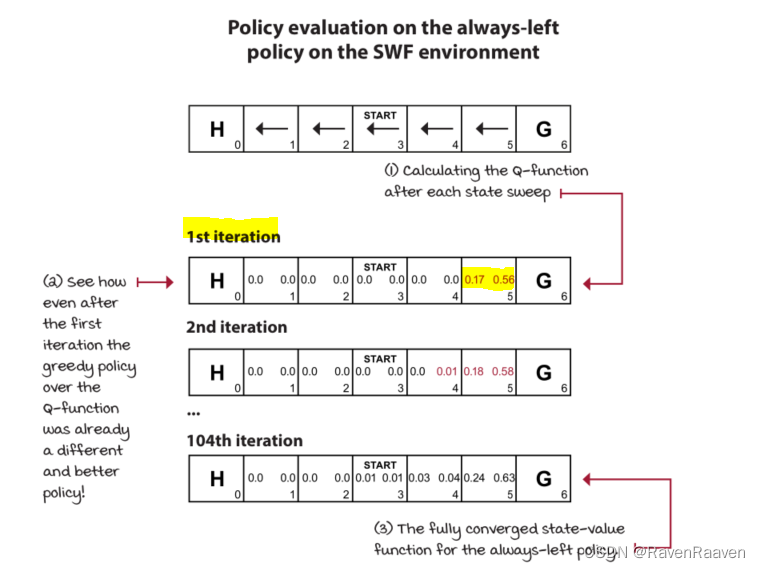
1, policy evaluation: 一般是iterative policy evaluation。该算法解决的问题是prediction problem, 即计算Predetermined policy(预先给定的策略)的值。

该式子是Bellman Equation的迭代形式。
该算法在每次迭代的过程中都会计算所有状态的值。该算法在迭代次数k接近无穷大的时候是收敛的。在判断算法是否收敛的时候采用一个较小的threshold去检测临近两个步骤的 V π ( s ) V^{\pi}(s) Vπ(s)值,一旦该差值小于threshold,则停止算法。(需要注意这里的iteration并不是Time steps, 即不与环境交互)

在计算第二步时的V值,即 V 2 π ( s ) V^{\pi}_2(s) V2π(s)时需要用到上一时刻计算得到的 V 1 π ( s ) V^{\pi}_1(s) V1π(s),这种技术叫做bootstrapping, calculating an estimate from an estimate is referred to as bootstrapping.
如何实现policy evaluation algorithm?

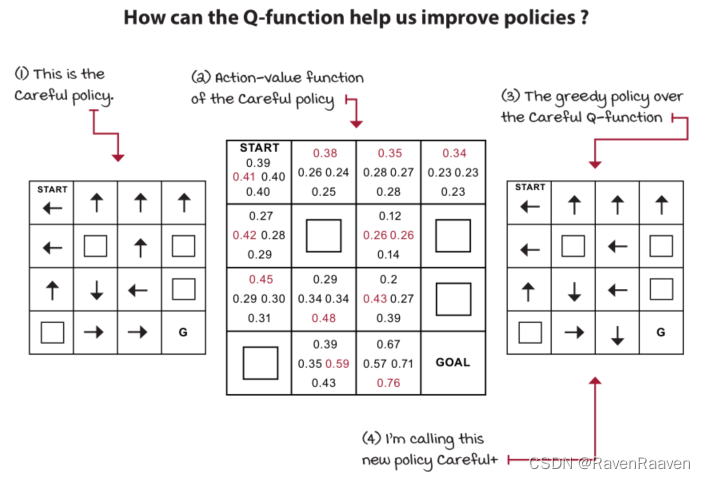
2, Policy Improvement: motivation:是否可以通过上述的policy evaluation algorithm, 利用其计算后得到的start position的V值进行rank. 但存在的问题是不能通过随机生成很多策略分别并计算该策略下的V值,这样浪费了计算资源。更好的方式是利用Q value function. 通过给定的MDP和计算得到的V function,可以计算得到Q-function。
步骤:利用state-value function和MDP计算action-value function, 之后根据计算得到的action-value function输出一个greedy policy。
举例:
一个策略比另一个策略好的条件是:We established that policy π \pi π is better than or equal to policy π ′ \pi' π′ if the expected return is better than or equal to π ′ \pi' π′ for all states. (注意是所有状态)
策略改进方程:

python code:

3,Policy Iteration: 算法开始的时候采用的是随机策略,并在Policy evaluation和policy improvement之间来回切换,直到达到最优策略。该方法最终能够收敛到最优策略和最优状态值函数(理论上有证明)。最优状态值函数下的最优策略可以有多个,因为有可能一些动作的Q函数值相等。
存在的问题是:会出现Q值相同的动作,在实践中,如果随机选择了这些动作,算法会给出并没有实质提升的不同策略。
3. Value Iteration
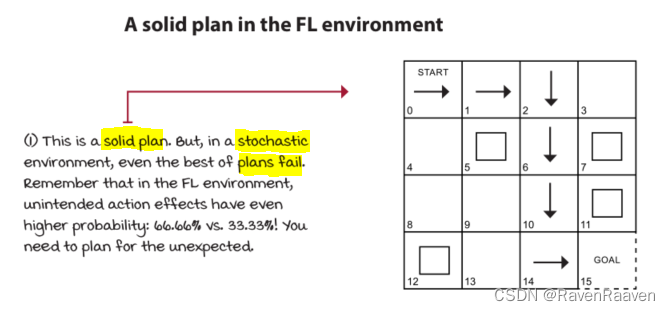
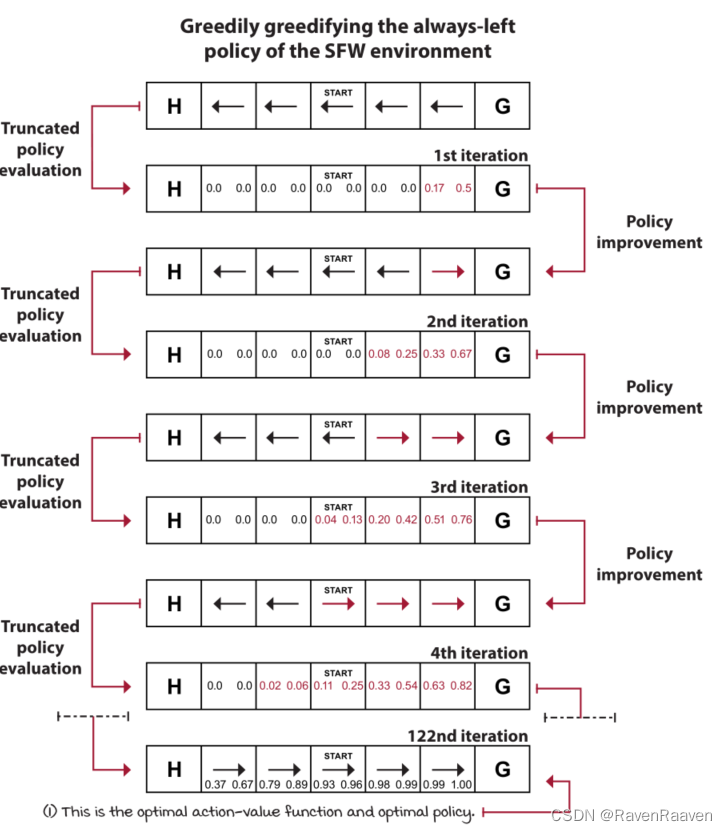
该方法的motivation: policy evaluation中evalution的计算速度较慢,因为要一直等到policy evaluation收敛到较为accurate values结束,值函数的更新速度较慢。对Policy evaluation进行适当的truncation(例如只需要对Policy evaluation进行一次计算即可, truncated policy evaluation after a single iteration)也同样可以得到更好的策略,举例如下图所示:
直观理解value iteration: ”greedily greedifying policies,” VI truncates the policy-evaluation phase after a single state sweep. 即只需要计算一次Policy evaluation并立刻使用greedy policy选取动作,本质上是single iteration of policy evaluation + policy improvement(最后时刻进行策略改进)。
value iteration equation :

在VI中,什么时候提取出最优策略?当算法中Q-function value收敛到最优值的时候,利用argmax提取出最优策略。
Value iteration和policy iteration都是generalized policy iteration (GPI)的两个实例。该思路指的是策略通过value function estimates进行更新,并且value function estimates向当前策略的真实值函数进行更新。
python code:

Chapter 4
主要想解决的问题是: 如何克服evaluative feedback,关注的问题是multi-armed bandits问题,**将evaluative feedback的问题孤立出来解决。**learning from evaluative feedback的难点在于智能体无法获取环境的MDP模型。evaluative feedback也就带来了exploration versus exploitation trade-off问题。
关键问题:智能体什么时候利用已有的知识或经验,什么时候采用其他未作过的动作探索环境?
关键点:exploration builds the knowledge that allows for effective exploitation探索能够为有效利用提供知识基础, and maximum exploitation is the ultimate goal of any decision maker决策算法的最终目的是最大化利用已有知识.
1. 基本环境和新引入的概念
Bandits环境:
Multi-armed bandits (MAB) 中状态空间和horizon都为1,动作空间不为1. 直观理解:“many-option, single-choice”
MAB研究的应用场景:广告系统, 电商网站,药物试验,搜索引擎等。

Regret概念: The cost of exploration
概念提出的背景:在Episodic task,例如chapter 3中的frozen lake, 智能体采取的是动作序列,因此智能体最大化cumulative undiscounted reward (or episode reward);而在MAB环境中,智能体的动作机会只有一次,因此最大化的reward只是单一Timestep的,去掉cumulative, discounted的描述。“maximize the expected reward,”这一目标不够准确,应改为“maximize the per-episode expected reward while still minimizing the total expected reward loss of rewards across all episodes”,
定义如下:total target的值越小越好,需要注意的是,计算Regret需要知道真实的MDP模型(如下图,需要计算optimal state value function)。

2. 一些常见的用于求解MAB的简单策略
三种解决exploration versus exploitation trade-off的三种方法:
1)random exploration strategies(向动作选择过程中加入randomness, 例如 ε − \varepsilon- ε−greedy等)
2)optimistic exploration strategies(在决策的问题中量化不确定性,动作选择偏好于那些有着最高不确定性的状态,“乐观”主义)
3)information state-space exploration strategies(向状态空间中加入不确定性,缺点在于增大了状态空间,增加了复杂度)
本章内容只关注于前两种解法。
(本章中计算Q值的方法都一样,不一样的是如何利用Q值进行动作的选择)
一个实例:Slippery Bandit Walk(BSW)
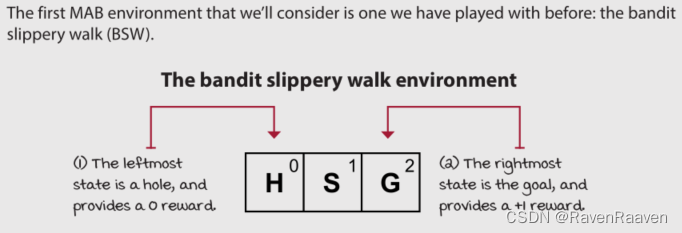
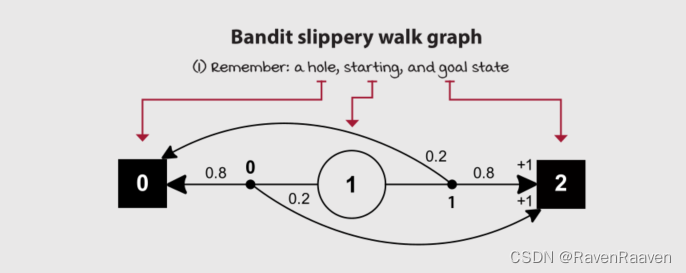
智能体采取动作0的reward是0.2, 智能体采用action1的reward是0.8。
提出的问题:智能体多快能找到最优动作?在最大化expected reward的过程中智能体积累的total regret是多少?
第一类方法:
两个baselines(一个是极端的greedy policy, 另一个是完全随机的策略)
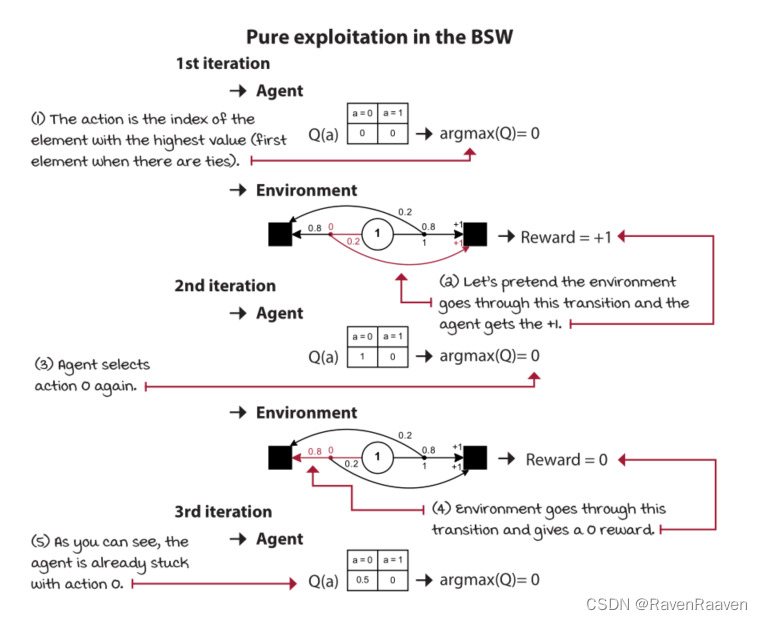

缺点是如果环境中没有负奖赏值,且Q-table初始化均为0,则greedy strategy会一直卡在first action上。
完全随机的策略,即完全探索:
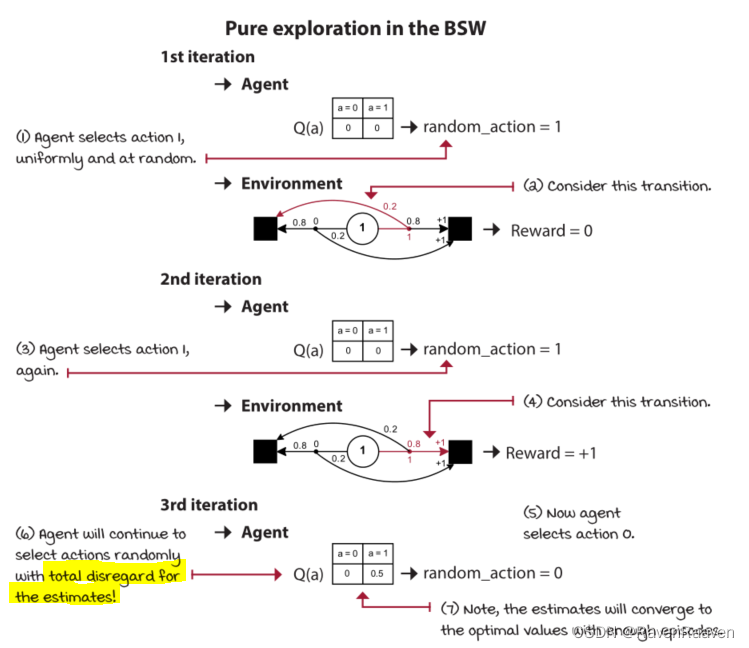
难点在于如何选择一种合适的随机探索方式,因为探索的方式可以有很多种(收集信息的方式有很多种),而利用exploitation的方法只有一种。
epsilon-greedy策略:结合了pure exploration and pure exploitation
首先产生随机数并判断其与epsilon的大小,如果产生的数大于epsilon则采用greedy策略,如果小于则采用random actions.
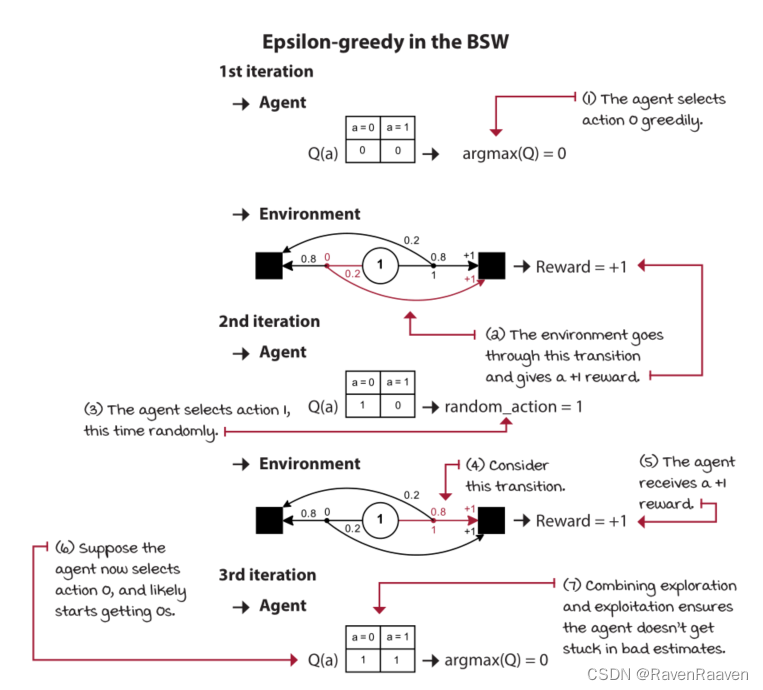
epsilon的大小并不代表着探索的比例。“exploration step” in epsilon-greedy includes the greedy action. 实际上智能体探索的比例取决于动作的数量,并且稍微小于epsilon的值。
Decaying epsilon-greedy策略: First maximize exploration, then exploitation,两种衰减方式,一种是线性,一种是指数型。
第二类方法:
Optimistic initialization乐观初始化: Start off believing it’s a wonderful world,又被称为optimism in the face of uncertainty.
直观理解:更偏好于那些还没有进行充分探索的动作。
如何做?将Q值的初始值增大,并采用greedy策略。负责计数的count也要大于1。
举例:
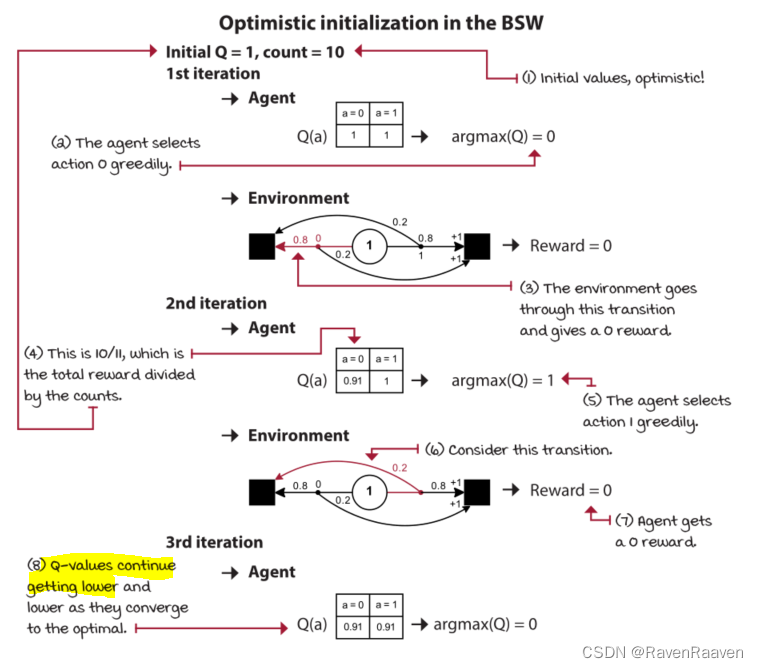
通过将Q值初始化为一个更高的值,算法能够鼓励智能体探索那些未被充分探索的动作。随着智能体与环境的不断交互,最终Q值会降低,并且会逐步收敛。
3. Strategic Exploration更为复杂的策略性探索
如果要将RL应用于实际场景中,那么随机探索的策略过于简单。epsilon-greedy之所以现在应用广泛是因为大部分的RL环境是基于虚拟环境的,安全性的考虑几乎没有。
1)Softmax strategy: 从action-value function中的概率分布中采样动作,选择某个动作的概率与当前的action value estimate成正比。该策略属于random exploration strategies, 与epsilon greedy从给定状态下可行动作空间中均匀分布采样不同,softmax更偏好于higher valued actions. 另外,可以向其中加入一个超参数,即temperature稀疏,用于调节算法对Q-values difference的敏感度sensitivity. 温度系数趋于无穷大的时候,动作的采样遵循均匀分布,若温度系数为0,则有最高Q值的动作的采样概率为1.


2)Upper Confidence Bound (UCB ): 属于第二类optimistic exploration strategies方法。上文中optimistic initialization strategy的问题:第一,我们并不能总是获取环境中的最大reward. 如果初始值大于实际的最大奖赏值,则算法需要更多的episodes交互时间;如果初始值小于实际的最大奖赏值,算法将不再是optimistic的。第二个问题是counts作为超参数需要不断调整,而实际上该参数想要表达的含义是Uncertainty of the estimate,并不能作为一个超参数。更好的方法是将Uncertainty作为一个bonus。
UCB中的optimism直观意义上来说是一种“realistic optimism” , Q-value estimate越不确定,越需要探索。


U函数的特性:函数曲线类似于指数下降的函数,但there’s a sharp decay early on and a long tail。举例说明:a 0 versus 100 attempts should give a higher bonus to 0 than to a 100 in a 100 versus 200 attempts.
UCB对Q-function的分布所作的假设非常少。
3)Thompson sampling:
The Thompson sampling strategy is a sample-based probability matching strategy that allows us to use Bayesian techniques to balance the exploration and exploitation trade-off.
简单的实现方法是将每一个Q-value当作高斯分布。但实际上可以使用任何一种概率分布作为先验分布(beta distribution相比高斯分布更为常见)。高斯分布中的均值是Q-value estimate,标准差测量了the uncertainty of the estimate,该值每个episode进行更新。
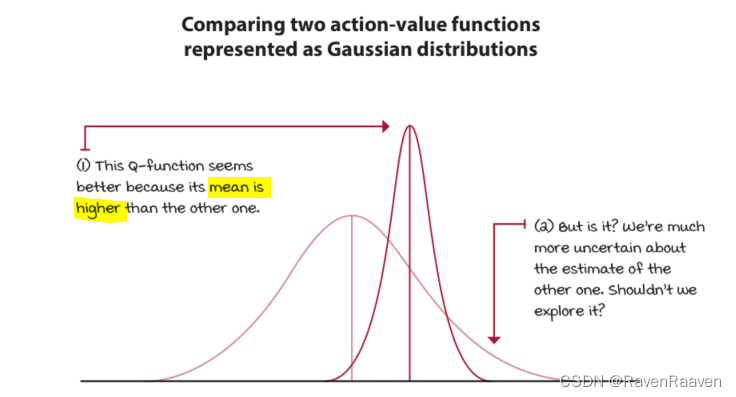
具体而言,从这些分布中采样,并选择有最大采样值的动作。更新高斯分布标准差的方式与UCB策略相似,当早期不确定较高的时候,标准差也高;最终高斯分布会变得狭长。

另一个例子:
(没太看懂这个环境在做什么,后续再补充)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









