







汇编语言
-
x86架构下的寄存器模型

-
通用寄存器:32 位时代
32 位 x86 架构中的通用寄存器有:eax, ecx, edx, ebx, esi, edi, esp, ebp;
其中 esp 是堆栈指针寄存器,和函数的调用与返回相关。
其中 eax 是用于保存返回值的寄存器。
-
通用寄存器:64 位时代
64 位 x86 架构中的通用寄存器有:rax, rcx, rdx, rbx, rsi, rdi, rsp, rbp, r8, r9, r10, r11, …, r15;
其中 r8 到 r15 是 64 位 x86 新增的寄存器,给了汇编程序员更大的空间,降低了编译器处理寄存器翻车(register spill)的压力。
因此 64 位比 32 位机器相比,除了内存突破 4GB 限制外,也有一定性能优势。
rsp是堆栈寄存器。
-
8位,16位,32位,64位版本之间的关系:共用低位
al, ax, eax, rax:
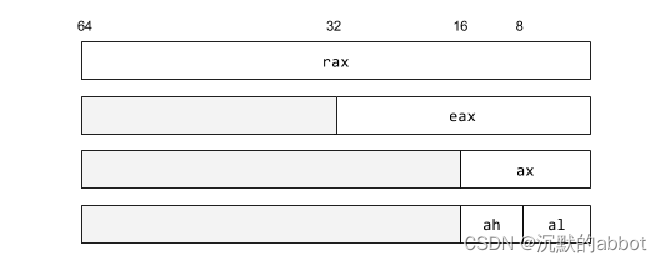
r15b, r15w, r15d, r15:

-
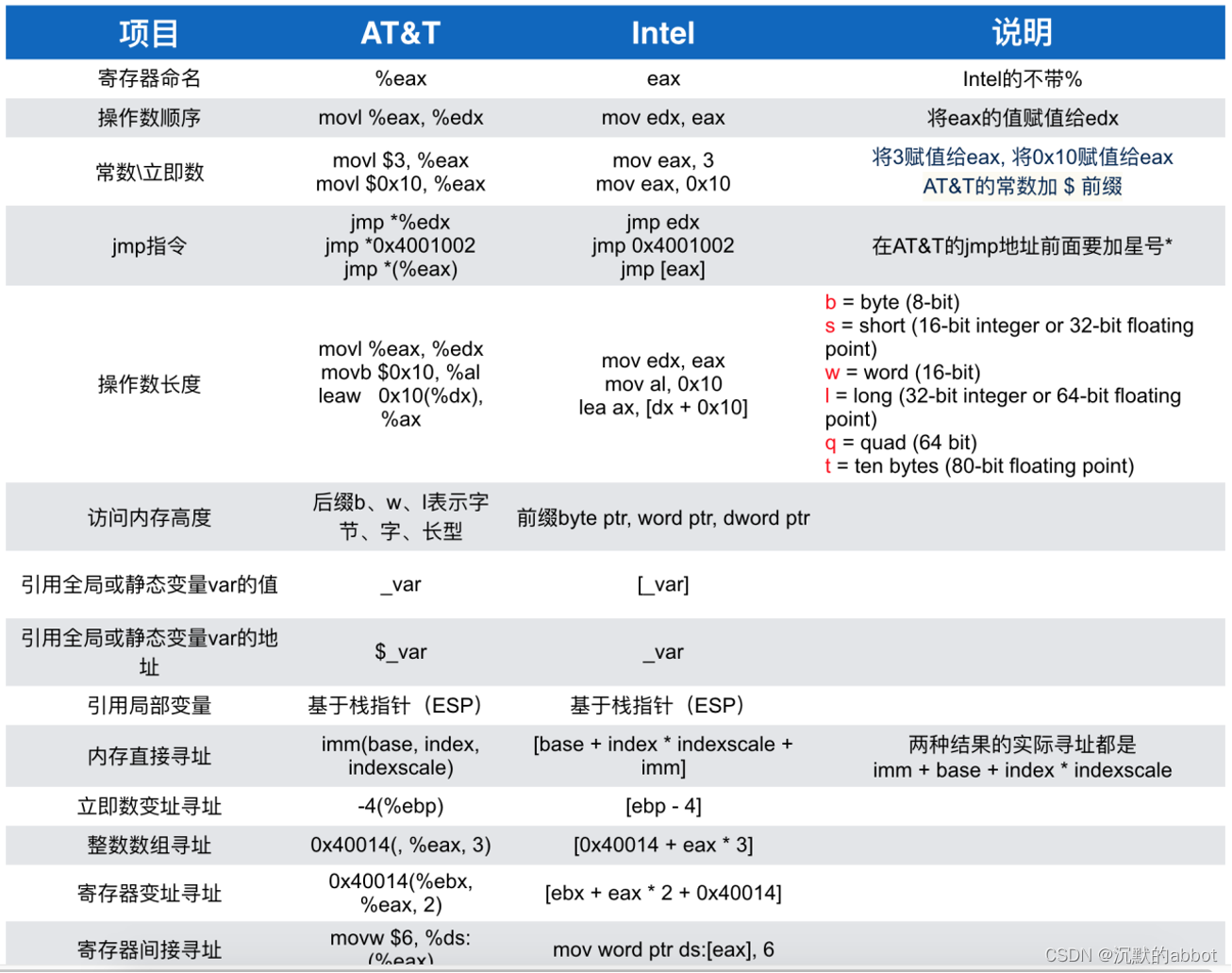
AT&T 汇编语言
-
avx512用的是zmm(512位),avx用ymm(256位),sse用xmm(128位)
-
编译程序为汇编代码,从而查看编译器优化情况的方式
gcc -fomit-frame-pointer -fverbose-asm -S main.cc -o main.S # -fomit-frame-pointer 选项是让生成的汇编代码更简洁 # -fverbose-asm 选项是让生成的汇编代码有注释,说明该汇编代码对应源程序中的第几行 # 可以-O开启优化 gcc -O3 -fomit-frame-pointer -fverbose-asm -S main.cc -o main.S -
返回值通过eax传出
int func() { return 42; }_Z4funcv: .LFB0: .cfi_startproc # main.cpp:2: return 42; movl $42, %eax #, _1 # main.cpp:3: } ret -
编译器的优化对比
int func(int a, int b, int c, int d, int e, int f) { return a; }# gcc -fomit-frame-pointer -fverbose-asm -S main.cpp -o /tmp/main.S _Z4funciiiiii: .LFB0: .cfi_startproc movl %edi, -4(%rsp) # a, a movl %esi, -8(%rsp) # b, b movl %edx, -12(%rsp) # c, c movl %ecx, -16(%rsp) # d, d movl %r8d, -20(%rsp) # e, e movl %r9d, -24(%rsp) # f, f # main.cpp:2: return a; movl -4(%rsp), %eax # a, _2 # main.cpp:3: } ret .cfi_endproc开启-O3优化
# gcc -O3 -fomit-frame-pointer -fverbose-asm -S main.cpp -o /tmp/main.S _Z4funciiiiii: .LFB0: .cfi_startproc # main.cpp:1: int func(int a, int b, int c, int d, int e, int f) { movl %edi, %eax # tmp90, a # main.cpp:3: } ret .cfi_endproc -
32位乘法运算:imull
int func(int a, int b) { return a * b; }_Z4funcii: .LFB0: .cfi_startproc # main.cpp:2: return a * b; movl %edi, %eax # tmp86, tmp86 imull %esi, %eax # tmp87, tmp86 # main.cpp:3: } ret .cfi_endproc -
64位乘法运算:imulq
long long func(long long a, long long b) { return a * b; }_Z4funcxx: .LFB0: .cfi_startproc # main.cpp:2: return a * b; movq %rdi, %rax # tmp86, tmp86 imulq %rsi, %rax # tmp87, tmp86 # main.cpp:3: } ret .cfi_endproc -
整数加法:被优化成 leal 了
int func(int a, int b) { return a + b; }_Z4funcii: .LFB0: .cfi_startproc # main.cpp:2: return a + b; leal (%rdi,%rsi), %eax #, tmp85 # main.cpp:3: } ret .cfi_endproc -
整数加常数乘整数:都可以被优化成 leal
int func(int a, int b) { return a + 8 * b; }_Z4funcii: .LFB0: .cfi_startproc # main.cpp:2: return a + 8 * b; leal (%rdi,%rsi,8), %eax #, tmp86 # main.cpp:3: } ret .cfi_endproc -
指针访问对象:线性访问地址
int func(int *a, int b) { return a[b]; }_Z4funcPii: .LFB0: .cfi_startproc # main.cpp:2: return a[b]; # 因为地址是64位,所以先移动到64位寄存器上,相当于rsi = (int64_t)esi movslq %esi, %rsi # tmp92, b # main.cpp:2: return a[b]; # 乘4是因为int大小为64,相当于eax = *(int *)(rdi + rsi * 64) movl (%rdi,%rsi,4), %eax # *_3, *_3 # main.cpp:3: } ret .cfi_endproc -
指针的索引:尽量用 size_t
size_t 在 64 位系统上相当于 uint64_t,size_t 在 32 位系统上相当于 uint32_t;
从而不需要用 movslq 从 32 位符号扩展到 64 位,更高效。而且也能处理数组大小超过 INT_MAX 的情况,推荐始终用 size_t 表示数组大小和索引。
eax = *(int *)(rdi + rsi * 4)
#include <cstdint> int func(int *a, std::size_t b) { return a[b]; }_Z4funcPim: .LFB2: .cfi_startproc # main.cpp:4: return a[b]; movl (%rdi,%rsi,4), %eax # *_2, *_2 # main.cpp:5: } ret .cfi_endproc -
浮点作为参数和返回:xmm 系列寄存器
第二个s代表single,单精度浮点数。
float func(float a, float b) { return a + b; }_Z4funcff: .LFB0: .cfi_startproc # main.cpp:2: return a + b; addss %xmm1, %xmm0 # tmp87, tmp85 # main.cpp:3: } ret .cfi_endproc -
什么是 xmm 系列寄存器?
xmm 寄存器有 128 位宽。
可以容纳 4 个 float,或 2 个 double。
刚才的案例中只用到了 xmm 的低 32 位用于存储 1 个 float。
-
addss 是什么意思?
可以拆分成三个部分:add,s,s
- add 表示执行加法操作。
- 第一个 s 表示标量(scalar),只对 xmm 的最低位进行运算;也可以是 p 表示矢量(packed),一次对 xmm 中所有位进行运算。
- 第二个 s 表示单精度浮点数(single),即 float 类型;也可以是 d 表示双精度浮点数(double),即 double 类型。
addss:一个 float 加法。
addsd:一个 double 加法。
addps:四个 float 加法。
addpd:两个 double 加法。
如果你看到编译器生成的汇编里,有大量 ss 结尾的指令则说明矢量化失败;如果看到大多数都是 ps 结尾则说明矢量化成功。
-
为什么需要 SIMD?单个指令处理四个数据
- 这种单个指令处理多个数据的技术称为 SIMD(single-instruction multiple-data)。
他可以大大增加计算密集型程序的吞吐量。 - 因为 SIMD 把 4 个 float 打包到一个 xmm 寄存器里同时运算,很像数学中矢量的逐元素加法。因此 SIMD 又被称为矢量,而原始的一次只能处理 1 个 float 的方式,则称为标量。
- 在一定条件下,编译器能够把一个处理标量 float 的代码,转换成一个利用 SIMD 指令的,处理矢量 float 的代码,从而增强你程序的吞吐能力!
- 通常认为利用同时处理 4 个 float 的 SIMD 指令可以加速 4 倍。但是如果你的算法不适合 SIMD,则可能加速达不到 4 倍;也有因为 SIMD 让访问内存更有规律,节约了指令解码和指令缓存的压力等原因,出现加速超过 4 倍的情况。
- 这种单个指令处理多个数据的技术称为 SIMD(single-instruction multiple-data)。
基础的编译器优化
-
编译器优化:代数化简
int func(int a, int b) { int c = a + b; int d = a - b; return (c + d) / 2; }_Z4funcii: .LFB0: .cfi_startproc # main.cpp:1: int func(int a, int b) { movl %edi, %eax # tmp86, a # main.cpp:5: } ret .cfi_endproc -
编译器优化:常量折叠
int func() { int a = 32; int b = 10; return a + b; }_Z4funcv: .LFB0: .cfi_startproc # main.cpp:5: } movl $42, %eax #, ret .cfi_endproc -
编译器优化:举个例子
int func(int n) { int ret = 0; for (int i = 1; i <= 100; i++) { ret += i; } return ret; }_Z4funci: .LFB0: .cfi_startproc # main.cpp:7: } movl $5050, %eax #, ret .cfi_endproc -
编译器优化:并不是万能的
#include <vector> #include <numeric> int func() { std::vector<int> arr; for (int i = 1; i <= 100; i++) { arr.push_back(i); } return std::reduce(arr.begin(), arr.end()); }.LFB1115: .cfi_startproc pushq %r15 # .cfi_def_cfa_offset 16 .cfi_offset 15, -16 movq %rdx, %r15 # tmp143, __args#0 # /usr/local/gcc-12/include/c++/12.2.0/bits/stl_vector.h:1893: if (max_size() - size() < __n) movabsq $2305843009213693951, %rdx #, tmp122 # /usr/local/gcc-12/include/c++/12.2.0/bits/vector.tcc:439: vector<_Tp, _Alloc>:: pushq %r14 # .cfi_def_cfa_offset 24 .cfi_offset 14, -24 pushq %r13 # .cfi_def_cfa_offset 32 .cfi_offset 13, -32 pushq %r12 # .cfi_def_cfa_offset 40 .cfi_offset 12, -40 pushq %rbp # .cfi_def_cfa_offset 48 .cfi_offset 6, -48 pushq %rbx # .cfi_def_cfa_offset 56 .cfi_offset 3, -56 subq $24, %rsp #, .cfi_def_cfa_offset 80 movq 8(%rdi), %r12 # MEM[(int * *)this_16(D) + 8B], _47 movq (%rdi), %r13 # MEM[(int * *)this_16(D)], _46 # /usr/local/gcc-12/include/c++/12.2.0/bits/stl_vector.h:988: { return size_type(this->_M_impl._M_finish - this->_M_impl._M_start); } ......结论:尽量避免代码复杂化,避免使用会造成 new/delete 的容器。
简单的代码,比什么优化手段都强。
-
造成 new/delete 的容器:内存分配在堆上的容器
- 存储在堆上(妨碍优化)
- vector, map, set, string, function, any
- unique_ptr, shared_ptr, weak_ptr
-
分配在栈上的容器
- 存储在栈上(利于优化)
- array, bitset, glm::vec, string_view
- pair, tuple, optional, variant
-
存储在栈上无法动态扩充大小,这就是为什么 vector 这种数据结构要存在堆上,而固定长度的 array 可以存在栈上。
-
上述代码改为array,编译成汇编后还是优化失败
#include <array> #include <numeric> int func() { std::array<int,100> arr; for (int i = 1; i <= 100; i++) { arr[i-1] = i; } return std::reduce(arr.begin(), arr.end()); } -
改用手写的 reduce,还是优化失败
#include <array> #include <numeric> int func() { std::array<int,100> arr; for (int i = 1; i <= 100; i++) { arr[i-1] = i; } int ret = 0; for(int i = 1; i <= 100; ++i){ ret += arr[i-1]; } return ret; } -
当把array的大小改为10之后,优化成功。
结论:代码过于复杂,涉及的语句数量过多时,编译器会放弃优化!
简单的代码,比什么优化手段都强。
-
constexpr:强迫编译器在编译期求值
如果发现编译器放弃了自动优化,可以用 constexpr 函数迫使编译器进行常量折叠,但是这样会在编译期耗费较多的性能!
但是,constexpr 函数中无法使用非 constexpr 的容器:vector, map, set, string 等……
constexpr只能用栈上的容器,不能用堆上的容器。
#include <array> template <int N> constexpr int func_impl() { std::array<int, N> arr{}; for (int i = 1; i <= N; i++) { arr[i - 1] = i; } int ret = 0; for (int i = 1; i <= N; i++) { ret += arr[i - 1]; } return ret; } int func() { constexpr int ret = func_impl<50000>(); return ret; }_Z4funcv: .LFB450: .cfi_startproc # main.cpp:19: } movl $1250025000, %eax #, ret .cfi_endproc
内联
-
函数分为两种,外部和内部函数。
- 外部函数:声明和实现分开在不同文件,这种函数编译器没办法优化,只能生成一个call函数来进行调用这个函数;
- 内部函数:声明和实现在同一文件,编译器可以看到函数实现,从而可以进行优化。
-
调用外部函数:call 指令
int other(int a); int func() { return other(233); }# gcc -O3 -fomit-frame-pointer -fverbose-asm -S main.cpp -o /tmp/main.S _Z4funcv: .LFB0: .cfi_startproc subq $8, %rsp #, .cfi_def_cfa_offset 16 # main.cpp:4: return other(233); movl $233, %edi #, call _Z5otheri@PLT # # main.cpp:5: } addq $8, %rsp #, .cfi_def_cfa_offset 8 ret .cfi_endproc@PLT 是 Procedure Linkage Table 的缩写,即函数链接表。链接器会查找其他 .o 文件中是否定义了 _Z5otheri 这个符号,如果定义了则把这个 @PLT 替换为他的地址。
-
编译器优化:call 变 jmp
# gcc -O3 -fomit-frame-pointer -fverbose-asm -S main.cpp -o /tmp/main.S _Z4funcv: .LFB0: .cfi_startproc # main.cpp:4: return other(233); movl $233, %edi #, jmp _Z5otheri@PLT # .cfi_endproc -
多个函数定义在同一个文件中
int other(int a) { return a; } int func() { return other(233); }# gcc -fomit-frame-pointer -fverbose-asm -S main.cpp -o /tmp/main.S _Z5otheri: .LFB0: .cfi_startproc movl %edi, -4(%rsp) # a, a # main.cpp:2: return a; movl -4(%rsp), %eax # a, _2 # main.cpp:3: } ret .cfi_endproc .LFE0: .size _Z5otheri, .-_Z5otheri .globl _Z4funcv .type _Z4funcv, @function _Z4funcv: .LFB1: .cfi_startproc # main.cpp:6: return other(233); movl $233, %edi #, call _Z5otheri # # main.cpp:7: } ret .cfi_endproc如果 _Z5otheri 定义在同一个文件中,编译器会直接调用,没有 @PLT 表示未定义对象。减轻了链接器的负担。
-
编译器优化:内联化
只有定义在同一个文件的函数可以被内联!否则编译器看不见函数体里的内容怎么内联呢?
为了效率我们可以尽量把常用函数定义在头文件里,然后声明为 static。这样调用他们的时候编译器看得到他们的函数体,从而有机会内联。
内联:当编译器看得到被调用函数(other)实现的时候,会直接把函数实现贴到调用他的函数(func)里。
int other(int a) { return a; } int func() { return other(233); }# gcc -O3 -fomit-frame-pointer -fverbose-asm -S main.cpp -o /tmp/main.S _Z5otheri: .LFB0: .cfi_startproc # main.cpp:1: int other(int a) { movl %edi, %eax # tmp85, a # main.cpp:3: } ret .cfi_endproc .LFE0: .size _Z5otheri, .-_Z5otheri .p2align 4 .globl _Z4funcv .type _Z4funcv, @function _Z4funcv: .LFB1: .cfi_startproc # main.cpp:7: } movl $233, %eax #, ret .cfi_endproc -
局部可见函数:static
声明static函数,只有在本文件中可见,所以直接不生成other函数了,从而进行内联。
static int other(int a) { return a; } int func() { return other(233); }_Z4funcv: .LFB1: .cfi_startproc # main.cpp:7: } movl $233, %eax #, ret .cfi_endproc不写static也可以内联,但是会生成other函数的。
-
现代inline关键字对于内联根本无用。
在现代编译器的高强度优化下,加不加 inline 无所谓;
编译器不是傻子,只要他看得见 other 的函数体定义,就会自动内联;
内联与否和 inline 没关系,内联与否只取决于是否在同文件,且函数体够小;
要性能的,定义在头文件声明为 static 即可,没必要加 inline 的;
static 纯粹是为了避免多个 .cpp 引用同一个头文件造成冲突,并不是必须 static 才内联;
如果你不确定某修改是否能提升性能,那你最好实际测一下,不要脑内模拟;
inline 在现代 C++ 中有其他含义,但和内联没有关系,他是一个迷惑性的名字。
-
在线做编译器实验推荐这个网站:https://godbolt.org/。
指针
-
指针别名现象
void func(int *a, int *b, int *c) { *c = *a; *c = *b; }_Z4funcPiS_S_: .LFB0: .cfi_startproc # main.cpp:2: *c = *a; movl (%rdi), %eax # *a_4(D), _1 # main.cpp:2: *c = *a; movl %eax, (%rdx) # _1, *c_5(D) # main.cpp:3: *c = *b; movl (%rsi), %eax # *b_7(D), _2 # main.cpp:3: *c = *b; movl %eax, (%rdx) # _2, *c_5(D) # main.cpp:4: } ret .cfi_endproc之所以未作优化,是害怕出现指针别名现象:
int main(){ int a,b; func(&a,&b,&b); } -
告诉编译器别怕指针别名:__restrict 关键字
__restrict 是一个提示性的关键字,是程序员向编译器保证:这些指针之间不会发生重叠!
从而他可以放心地优化成功。
void func(int *__restrict a, int *__restrict b, int *__restrict c) { *c = *a; *c = *b; }_Z4funcPiS_S_: .LFB0: .cfi_startproc # main.cpp:3: *c = *b; movl (%rsi), %eax # *b_5(D), *b_5(D) movl %eax, (%rdx) # *b_5(D), *c_4(D) # main.cpp:4: } ret .cfi_endproc -
__restrict 关键字:只需加在非 const 的即可
__restrict 只需要加在所有具有写入访问的指针上,就可以优化成功。
而我们可以用 const 禁止写入访问。
void func(int const *a, int const *b, int *__restrict c) { *c = *a; *c = *b; }_Z4funcPKiS0_Pi: .LFB0: .cfi_startproc # main.cpp:3: *c = *b; movl (%rsi), %eax # *b_5(D), *b_5(D) movl %eax, (%rdx) # *b_5(D), *c_4(D) # main.cpp:4: } ret .cfi_endproc结论:所有非 const 的指针都声明 __restrict。
-
禁止优化:volatile
加了 volatile 的对象,编译器会放弃优化对他的读写操作。
做性能实验的时候非常有用。// 不加volatile int func(int *a) { *a = 42; return *a; }_Z4funcPi: .LFB0: .cfi_startproc # main.cpp:2: *a = 42; movl $42, (%rdi) #, *a_2(D) # main.cpp:4: } movl $42, %eax #, ret .cfi_endproc// 加volatile int func(int volatile *a) { *a = 42; return *a; }_Z4funcPVi: .LFB0: .cfi_startproc # main.cpp:2: *a = 42; movl $42, (%rdi) #, *a_2(D) # main.cpp:3: return *a; movl (%rdi), %eax # *a_2(D), <retval> # main.cpp:4: } ret .cfi_endproc -
两者区别
- volatile int *a 或 int volatile *a
- int *__restrict a
- 语法上区别:volatile 在 * 前面而 __restrict 在 * 后面。
- 功能上区别:volatile 是禁用优化,__restrict 是帮助优化。
- 是否属于标准上区别:
volatile 和 const 一样是 C++ 标准的一部分。
restrict 是 C99 标准关键字,但不是 C++ 标准的关键字。
__restrict 其实是编译器的“私货”,好在大多数主流编译器都支持。 - volatile的应用对象可以不是指针。
-
编译器优化:合并写入
void func(int *a) { a[0] = 123; a[1] = 456; }将两个 int32 的写入合并为一个 int64 的写入。
.LFB0: .cfi_startproc # main.cpp:2: a[0] = 123; movq .LC0(%rip), %rax #, tmp83 movq %rax, (%rdi) # tmp83, MEM <vector(2) int> [(int *)a_2(D)] # main.cpp:4: } ret .cfi_endproc -
合并写入:不能跳跃
void func(int *a) { a[0] = 123; a[2] = 456; }但如果访问的两个元素地址间有跳跃,就不能合并了。
_Z4funcPi: .LFB0: .cfi_startproc # main.cpp:2: a[0] = 123; movl $123, (%rdi) #, *a_2(D) # main.cpp:3: a[2] = 456; movl $456, 8(%rdi) #, MEM[(int *)a_2(D) + 8B] # main.cpp:4: } ret .cfi_endproc
矢量化
-
更宽的合并写入:矢量化指令(SIMD)
void func(int *a) { a[0] = 111; a[1] = 222; a[2] = 333; a[3] = 444; }两个 int32 可以合并为一个 int64,四个 int32 可以合并为一个 __m128;
xmm0 由 SSE 引入,是个 128 位寄存器,他可以一次存储 4 个 int,或 4 个 float
movups:move unaligned packed single,u 代表 (%rdi) 的地址不一定对齐到 16 字节;
movaps:move aligned packed single。
_Z4funcPi: .LFB0: .cfi_startproc # main.cpp:2: a[0] = 111; movdqa .LC0(%rip), %xmm0 #, tmp83 movups %xmm0, (%rdi) # tmp83, MEM <vector(4) int> [(int *)a_2(D)] # main.cpp:6: } ret .cfi_endproc -
SIMD 指令:敢不敢再宽一点
两个 int32 可以合并为一个 int64,四个 int32 可以合并为一个 __m128,八个 int32 可以合并为一个 __m256。
void func(int *a) { a[0] = 111; a[1] = 222; a[2] = 333; a[3] = 444; a[4] = 555; a[5] = 666; a[6] = 777; a[7] = 888; }为什么编译器没有用 256 位的 ymm0?因为他不敢保证运行这个程序的电脑支持 AVX 指令集……
_Z4funcPi: .LFB0: .cfi_startproc # main.cpp:2: a[0] = 111; movdqa .LC0(%rip), %xmm0 #, tmp83 movups %xmm0, (%rdi) # tmp83, MEM <vector(4) int> [(int *)a_2(D)] movdqa .LC1(%rip), %xmm0 #, tmp84 movups %xmm0, 16(%rdi) # tmp84, MEM <vector(4) int> [(int *)a_2(D) + 16B] # main.cpp:10: } ret .cfi_endproc .LFE0: .size _Z4funcPi, .-_Z4funcPi .section .rodata.cst16,"aM",@progbits,16 .align 16 .LC0: .long 111 .long 222 .long 333 .long 444 .align 16 .LC1: .long 555 .long 666 .long 777 .long 888 -
让编译器自动检测当前硬件支持的指令集
编译选项-march=native 让编译器自动判断当前硬件支持的指令。
void func(int *a) { a[0] = 111; a[1] = 222; a[2] = 333; a[3] = 444; a[4] = 555; a[5] = 666; a[6] = 777; a[7] = 888; }# gcc -march=native -O3 -fomit-frame-pointer -fverbose-asm -S main.cpp -o /tmp/main.S _Z4funcPi: .LFB0: .cfi_startproc # main.cpp:2: a[0] = 111; vmovdqa .LC0(%rip), %ymm0 #, tmp83 vmovdqu %ymm0, (%rdi) # tmp83, MEM <vector(8) int> [(int *)a_2(D)] vzeroupper # main.cpp:10: } ret .cfi_endproc .LFE0: .size _Z4funcPi, .-_Z4funcPi .section .rodata.cst32,"aM",@progbits,32 .align 32 .LC0: .long 111 .long 222 .long 333 .long 444 .long 555 .long 666 .long 777 .long 888 -
数组清零:自动调用标准库的 memset
void func(int *a, int n) { for (int i = 0; i < n; i++) { a[i] = 0; } }_Z4funcPii: .LFB0: .cfi_startproc # main.cpp:2: for (int i = 0; i < n; i++) { testl %esi, %esi # n jle .L1 #, # main.cpp:3: a[i] = 0; movl %esi, %esi # n, n leaq 0(,%rsi,4), %rdx #, tmp88 xorl %esi, %esi # jmp memset # .p2align 4,,10 .p2align 3 .L1: # main.cpp:5: } ret .cfi_endprocmemcpy 同理,不必为了高效,手动改写成对 memcpy/memset 的调用,影响可读性。编译器会自动分析你是在做拷贝或是清零,并优化成对标准库这俩的调用。
-
从 0 到 1024 填充:SIMD 加速
paddd:四个 int 的加法
movdqa:加载四个 intvoid func(int *a) { for (int i = 0; i < 1024; i++) { a[i] = i; } }_Z4funcPi: .LFB0: .cfi_startproc # main.cpp:1: void func(int *a) { movdqa .LC0(%rip), %xmm0 #, vect_vec_iv_.4 movdqa .LC1(%rip), %xmm2 #, tmp89 leaq 4096(%rdi), %rax #, _9 .p2align 4,,10 .p2align 3 .L2: movdqa %xmm0, %xmm1 # vect_vec_iv_.4, vect_vec_iv_.4 addq $16, %rdi #, ivtmp.10 paddd %xmm2, %xmm0 # tmp89, vect_vec_iv_.4 # main.cpp:3: a[i] = i; movups %xmm1, -16(%rdi) # vect_vec_iv_.4, MEM <vector(4) int> [(int *)_2] cmpq %rdi, %rax # ivtmp.10, _9 jne .L2 #, # main.cpp:5: } ret .cfi_endproc一次写入 4 个 int,一次计算 4 个 int 的加法,从而更加高效;
但这样有个缺点,那就是数组的大小必须为 4 的整数倍,否则就会写入越界的地址!
-
如果不是 4 的倍数?边界特判法
void func(int *a, int n) { for (int i = 0; i < n; i++) { a[i] = i; } }先以4个int为单位,矢量计算,然后标量计算。
_Z4funcPii: .LFB0: .cfi_startproc # main.cpp:2: for (int i = 0; i < n; i++) { testl %esi, %esi # n jle .L1 #, leal -1(%rsi), %eax #, tmp105 cmpl $2, %eax #, tmp105 jbe .L6 #, movl %esi, %edx # n, bnd.5 movdqa .LC0(%rip), %xmm0 #, vect_vec_iv_.8 movdqa .LC1(%rip), %xmm2 #, tmp111 movq %rdi, %rax # a, ivtmp.15 shrl $2, %edx #, salq $4, %rdx #, tmp108 addq %rdi, %rdx # a, _44 .p2align 4,,10 .p2align 3 .L4: movdqa %xmm0, %xmm1 # vect_vec_iv_.8, vect_vec_iv_.8 addq $16, %rax #, ivtmp.15 paddd %xmm2, %xmm0 # tmp111, vect_vec_iv_.8 # main.cpp:3: a[i] = i; movups %xmm1, -16(%rax) # vect_vec_iv_.8, MEM <vector(4) int> [(int *)_18] cmpq %rdx, %rax # _44, ivtmp.15 jne .L4 #, movl %esi, %eax # n, _15 andl $-4, %eax #, _15 testb $3, %sil #, n je .L9 #, .L3: # main.cpp:3: a[i] = i; movslq %eax, %rdx # _15, _15 # main.cpp:3: a[i] = i; movl %eax, (%rdi,%rdx,4) # _15, *_10 # main.cpp:3: a[i] = i; leaq 0(,%rdx,4), %rcx #, _3 # main.cpp:2: for (int i = 0; i < n; i++) { leal 1(%rax), %edx #, i # main.cpp:2: for (int i = 0; i < n; i++) { cmpl %esi, %edx # n, i jge .L1 #, # main.cpp:2: for (int i = 0; i < n; i++) { addl $2, %eax #, i # main.cpp:3: a[i] = i; movl %eax, 8(%rdi,%rcx) # i, *_22 .L1: # main.cpp:5: } ret .p2align 4,,10 .p2align 3 .L9: ret .L6: # main.cpp:2: for (int i = 0; i < n; i++) { xorl %eax, %eax # _15 jmp .L3 # .cfi_endproc -
n 总是 4 的倍数?避免边界特判
如果你能保证 n 总是 4 的倍数,也可以这样写,编译器会发现 n % 4 总是 = 0,从而不会生成边界特判的分支。
void func(int *a, int n) { n = n / 4 * 4; for (int i = 0; i < n; i++) { a[i] = i; } }_Z4funcPii: .LFB0: .cfi_startproc # main.cpp:2: n = n / 4 * 4; leal 3(%rsi), %eax #, tmp96 testl %esi, %esi # n cmovns %esi, %eax # tmp96,, n, n # main.cpp:3: for (int i = 0; i < n; i++) { andl $-4, %eax #, n jle .L1 #, shrl $2, %eax #, movdqa .LC0(%rip), %xmm0 #, vect_vec_iv_.6 movdqa .LC1(%rip), %xmm2 #, tmp102 salq $4, %rax #, tmp100 addq %rdi, %rax # ivtmp.12, _20 .p2align 4,,10 .p2align 3 .L3: movdqa %xmm0, %xmm1 # vect_vec_iv_.6, vect_vec_iv_.6 addq $16, %rdi #, ivtmp.12 paddd %xmm2, %xmm0 # tmp102, vect_vec_iv_.6 # main.cpp:4: a[i] = i; movups %xmm1, -16(%rdi) # vect_vec_iv_.6, MEM <vector(4) int> [(int *)_3] cmpq %rax, %rdi # _20, ivtmp.12 jne .L3 #, .L1: # main.cpp:6: } ret .cfi_endproc -
假定指针是 16 字节对齐的:assume_aligned
如果能保证指针 a 总是对齐到 16 字节,在 GCC 编译器中这样写:
void func(int *a, int n) { n = n / 4 * 4; a = (int *)__builtin_assume_aligned(a, 16); for (int i = 0; i < n; i++) { a[i] = i; } }但这样不通用,因此 C++20 引入了标准化的 std::assume_aligned:
void func(int *a, int n) { n = n / 4 * 4; a = std::assume_aligned<16>(a); for (int i = 0; i < n; i++) { a[i] = i; } }movups 变成了 movaps,对齐的读写可能带来微乎其微的性能提升……
_Z4funcPii: .LFB0: .cfi_startproc # main.cpp:2: n = n / 4 * 4; leal 3(%rsi), %eax #, tmp96 testl %esi, %esi # n cmovns %esi, %eax # tmp96,, n, n # main.cpp:4: for (int i = 0; i < n; i++) { andl $-4, %eax #, n jle .L1 #, shrl $2, %eax #, movdqa .LC0(%rip), %xmm0 #, vect_vec_iv_.6 movdqa .LC1(%rip), %xmm2 #, tmp102 salq $4, %rax #, tmp100 addq %rdi, %rax # ivtmp.12, _21 .p2align 4,,10 .p2align 3 .L3: movdqa %xmm0, %xmm1 # vect_vec_iv_.6, vect_vec_iv_.6 addq $16, %rdi #, ivtmp.12 paddd %xmm2, %xmm0 # tmp102, vect_vec_iv_.6 # main.cpp:5: a[i] = i; movaps %xmm1, -16(%rdi) # vect_vec_iv_.6, MEM <vector(4) int> [(int *)_3] cmpq %rax, %rdi # _21, ivtmp.12 jne .L3 #, .L1: # main.cpp:7: } ret .cfi_endproc -
数组求和:reduction 的优化
float func(float *a) { float ret = 0; for (int i = 0; i < 1024; i++) { ret += a[i]; } return ret; }编译器应该做类似下面伪代码的一个优化:
#include <x86intrin.h> float func(float *a) { __m128 ret = _mm_setzero_ps(); for (int i = 0; i < 1024; i += 4) { __m128 a_i = _mm_loadu_ps(&a[i]); ret = _mm_add_ps(ret, a_i); } float r[4]; _mm_storeu_ps(r, ret); return r[0] + r[1] + r[2] + r[3]; }不知道为什么,gcc12.2.0这里并没有做simd优化:
_Z4funcPf: .LFB0: .cfi_startproc leaq 4096(%rdi), %rax #, _4 # main.cpp:2: float ret = 0; pxor %xmm0, %xmm0 # <retval> .p2align 4,,10 .p2align 3 .L2: addss (%rdi), %xmm0 # BIT_FIELD_REF <MEM <vector(4) float> [(float *)_3], 32, 0>, stmp_ret_10.7 addq $16, %rdi #, ivtmp.13 addss -12(%rdi), %xmm0 # BIT_FIELD_REF <MEM <vector(4) float> [(float *)_3], 32, 32>, stmp_ret_10.7 # main.cpp:4: ret += a[i]; addss -8(%rdi), %xmm0 # BIT_FIELD_REF <MEM <vector(4) float> [(float *)_3], 32, 64>, stmp_ret_10.7 addss -4(%rdi), %xmm0 # BIT_FIELD_REF <MEM <vector(4) float> [(float *)_3], 32, 96>, <retval> cmpq %rdi, %rax # ivtmp.13, _4 jne .L2 #, # main.cpp:7: } ret .cfi_endproc
循环
-
循环中的矢量化:还在伺候指针别名
编译器还在担心 a 和 b 指向的数组是否有重合。考虑 func(a, a + 1) 的情况,那样会产生数据依赖链,没法 SIMD 化。为了优化而不失正确性,他索性生成两份代码:
一份是 SIMD 的,一份是传统标量的,在运行时检测 a, b 指针的差是否超过 1024 来判断是否有重叠现象:
- 如果没有重叠,则跳转到 SIMD 版本高效运行。
- 如果重叠,则跳转到标量版本低效运行,但至少不会错。
void func(float *a, float *b) { for (int i = 0; i < 1024; i++) { a[i] = b[i] + 1; } }_Z4funcPfS_: .LFB0: .cfi_startproc leaq 4(%rsi), %rdx #, tmp93 movq %rdi, %rax # a, tmp94 movss .LC1(%rip), %xmm1 #, tmp102 subq %rdx, %rax # tmp93, tmp94 cmpq $8, %rax #, tmp94 # main.cpp:1: void func(float *a, float *b) { movl $0, %eax #, ivtmp.19 jbe .L2 #, shufps $0, %xmm1, %xmm1 # tmp103 .p2align 4,,10 .p2align 3 .L3: # main.cpp:3: a[i] = b[i] + 1; movups (%rsi,%rax), %xmm0 # MEM <vector(4) float> [(float *)b_10(D) + ivtmp.24_1 * 1], vect__6.7 addps %xmm1, %xmm0 # tmp103, vect__6.7 # main.cpp:3: a[i] = b[i] + 1; movups %xmm0, (%rdi,%rax) # vect__6.7, MEM <vector(4) float> [(float *)a_11(D) + ivtmp.24_1 * 1] addq $16, %rax #, ivtmp.24 cmpq $4096, %rax #, ivtmp.24 jne .L3 #, ret .p2align 4,,10 .p2align 3 .L2: # main.cpp:3: a[i] = b[i] + 1; movss (%rsi,%rax), %xmm0 # MEM[(float *)b_10(D) + ivtmp.19_21 * 1], tmp99 addss %xmm1, %xmm0 # tmp102, tmp99 # main.cpp:3: a[i] = b[i] + 1; movss %xmm0, (%rdi,%rax) # tmp99, MEM[(float *)a_11(D) + ivtmp.19_21 * 1] # main.cpp:2: for (int i = 0; i < 1024; i++) { addq $4, %rax #, ivtmp.19 cmpq $4096, %rax #, ivtmp.19 jne .L2 #, # main.cpp:5: } ret .cfi_endproc -
循环中的矢量化:解决指针别名
所以加上 __restrict 关键字,打消编译器的顾虑;
这下只生成一个 SIMD 版本了,没有了运行时判断重叠的焦虑。
void func(float *__restrict a, float *__restrict b) { for (int i = 0; i < 1024; i++) { a[i] = b[i] + 1; } } -
循环中的矢量化:OpenMP 强制矢量化
除了可以用 __restrict 让编译器放心做 SIMD 优化外,还可以用 OpenMP 的指令,来迫使编译器无视指针别名的问题,并启用 SIMD 优化。不过你得给编译器打开 -fopenmp 这个选项。
void func(float *a, float *b) { #pragma omp simd for (int i = 0; i < 1024; i++) { a[i] = b[i] + 1; } }# gcc -fopenmp -O3 -fomit-frame-pointer -fverbose-asm -S main.cpp -o /tmp/main.S _Z4funcPfS_: .LFB0: .cfi_startproc movss .LC1(%rip), %xmm1 #, tmp91 # main.cpp:1: void func(float *a, float *b) { xorl %eax, %eax # ivtmp.14 shufps $0, %xmm1, %xmm1 # tmp91 .p2align 4,,10 .p2align 3 .L2: # main.cpp:4: a[i] = b[i] + 1; movups (%rsi,%rax), %xmm0 # MEM <vector(4) float> [(float *)b_6(D) + ivtmp.14_21 * 1], vect__11.7 addps %xmm1, %xmm0 # tmp91, vect__11.7 # main.cpp:4: a[i] = b[i] + 1; movups %xmm0, (%rdi,%rax) # vect__11.7, MEM <vector(4) float> [(float *)a_9(D) + ivtmp.14_21 * 1] addq $16, %rax #, ivtmp.14 cmpq $4096, %rax #, ivtmp.14 jne .L2 #, # main.cpp:6: } ret .cfi_endproc -
循环中的矢量化:编译器提示忽略指针别名
除了可以用 __restrict,#pragma omp simd 外,对于 GCC 编译器还可以用:
#pragma GCC ivdep表示忽视下方 for 循环内可能的指针别名现象。
不同的编译器这个 pragma 指令不同,这里只是拿 GCC 举例,其他编译器请自行查找资料。
void func(float *a, float *b) { #pragma GCC ivdep for (int i = 0; i < 1024; i++) { a[i] = b[i] + 1; } } -
循环中的 if 语句:挪到外面来
void func(float *__restrict a, float *__restrict b, bool is_mul) { for (int i = 0; i < 1024; i++) { if (is_mul) { a[i] = a[i] * b[i]; } else { a[i] = a[i] + b[i]; } } }这个案例中,作者的用意很明显,在 is_mul 为真时执行 a *= b,否则执行 a += b。
然而有 if 分支的循环体是难以 SIMD 矢量化的。
编译器看到 is_mul 是一个常量,于是把 if 分支判断挪到了 for 外面来。
相当于生成了两个版本,一个乘法,一个加法。
// 优化后: void func(float *__restrict a, float *__restrict b, bool is_mul) { if(is_mul){ for (int i = 0; i < 1024; i++) { a[i] = a[i] * b[i]; } } else{ for (int i = 0; i < 1024; i++) { a[i] = a[i] + b[i]; } } }这样就可以自由地使用 SIMD 指令。
-
循环中的不变量:挪到外面来
优化前:
void func(float *__restrict a, float *__restrict b, float dt) { for (int i = 0; i < 1024; i++) { a[i] = a[i] + b[i] * dt * dt; } }_Z4funcPfS_f: .LFB0: .cfi_startproc # main.cpp:1: void func(float *__restrict a, float *__restrict b, float dt) { xorl %eax, %eax # ivtmp.19 shufps $0, %xmm0, %xmm0 # vect_cst__25 .p2align 4,,10 .p2align 3 .L2: # main.cpp:3: a[i] = a[i] + b[i] * dt * dt; movups (%rsi,%rax), %xmm1 # MEM <vector(4) float> [(float *)b_14(D) + ivtmp.19_35 * 1], vect__7.10 # main.cpp:3: a[i] = a[i] + b[i] * dt * dt; movups (%rdi,%rax), %xmm2 # MEM <vector(4) float> [(float *)a_13(D) + ivtmp.19_35 * 1], tmp103 # main.cpp:3: a[i] = a[i] + b[i] * dt * dt; mulps %xmm0, %xmm1 # vect_cst__25, vect__7.10 # main.cpp:3: a[i] = a[i] + b[i] * dt * dt; mulps %xmm0, %xmm1 # vect_cst__25, vect__8.11 # main.cpp:3: a[i] = a[i] + b[i] * dt * dt; addps %xmm2, %xmm1 # tmp103, vect__9.12 # main.cpp:3: a[i] = a[i] + b[i] * dt * dt; movups %xmm1, (%rdi,%rax) # vect__9.12, MEM <vector(4) float> [(float *)a_13(D) + ivtmp.19_35 * 1] addq $16, %rax #, ivtmp.19 cmpq $4096, %rax #, ivtmp.19 jne .L2 #, # main.cpp:5: } ret .cfi_endproc优化后:
void func(float *__restrict a, float *__restrict b, float dt) { for (int i = 0; i < 1024; i++) { a[i] = a[i] + b[i] * (dt * dt); } }_Z4funcPfS_f: .LFB0: .cfi_startproc # main.cpp:3: a[i] = a[i] + b[i] * (dt * dt); mulss %xmm0, %xmm0 # tmp99, _7 xorl %eax, %eax # ivtmp.18 shufps $0, %xmm0, %xmm0 # vect_cst__22 .p2align 4,,10 .p2align 3 .L2: # main.cpp:3: a[i] = a[i] + b[i] * (dt * dt); movups (%rsi,%rax), %xmm1 # MEM <vector(4) float> [(float *)b_14(D) + ivtmp.18_32 * 1], vect__8.10 # main.cpp:3: a[i] = a[i] + b[i] * (dt * dt); movups (%rdi,%rax), %xmm2 # MEM <vector(4) float> [(float *)a_13(D) + ivtmp.18_32 * 1], tmp102 # main.cpp:3: a[i] = a[i] + b[i] * (dt * dt); mulps %xmm0, %xmm1 # vect_cst__22, vect__8.10 # main.cpp:3: a[i] = a[i] + b[i] * (dt * dt); addps %xmm2, %xmm1 # tmp102, vect__9.11 # main.cpp:3: a[i] = a[i] + b[i] * (dt * dt); movups %xmm1, (%rdi,%rax) # vect__9.11, MEM <vector(4) float> [(float *)a_13(D) + ivtmp.18_32 * 1] addq $16, %rax #, ivtmp.18 cmpq $4096, %rax #, ivtmp.18 jne .L2 #, # main.cpp:5: } ret .cfi_endproc编译器能识别括号,要么帮编译器打上括号帮助他识别,要么手动提取不变量到循环体外。
-
调用不在同一个文件的函数:SIMD 优化失败
编译器看不到那个文件的 other 函数里是什么,哪怕 other 在定义他的文件里是个空函数,他也不敢优化掉。
-
解决方案:放在同一个文件里
结论:避免在 for 循环体里调用外部函数,把他们移到同一个文件里,或者放在头文件声明为 static 函数。
-
循环中的下标:随机访问
矢量化失败!
void func(float *a, int *b) { for (int i = 0; i < 1024; i++) { a[b[i]] += 1; } }_Z4funcPfPi: .LFB0: .cfi_startproc movss .LC0(%rip), %xmm1 #, tmp99 leaq 4096(%rsi), %rdx #, _29 .p2align 4,,10 .p2align 3 .L2: # main.cpp:3: a[b[i]] += 1; movslq (%rsi), %rax # MEM[(int *)_34], MEM[(int *)_34] # main.cpp:2: for (int i = 0; i < 1024; i++) { addq $4, %rsi #, ivtmp.10 # main.cpp:3: a[b[i]] += 1; leaq (%rdi,%rax,4), %rax #, _7 # main.cpp:3: a[b[i]] += 1; movss (%rax), %xmm0 # *_7, tmp96 addss %xmm1, %xmm0 # tmp99, tmp96 movss %xmm0, (%rax) # tmp96, *_7 # main.cpp:2: for (int i = 0; i < 1024; i++) { cmpq %rsi, %rdx # ivtmp.10, _29 jne .L2 #, # main.cpp:5: } ret .cfi_endproc -
循环中的下标:跳跃访问
矢量化部分成功,但是非常艰难
void func(float *a) { for (int i = 0; i < 1024; i++) { a[i * 2] += 1; } }_Z4funcPf: .LFB0: .cfi_startproc movss .LC1(%rip), %xmm2 #, tmp126 movq %rdi, %rax # a, ivtmp.15 leaq 8160(%rdi), %rdx #, _24 shufps $0, %xmm2, %xmm2 # tmp126 .p2align 4,,10 .p2align 3 .L2: # main.cpp:3: a[i * 2] += 1; movups (%rax), %xmm0 # MEM <vector(4) float> [(float *)_3], tmp104 movups 16(%rax), %xmm3 # MEM <vector(4) float> [(float *)_3 + 16B], tmp131 addq $32, %rax #, ivtmp.15 shufps $136, %xmm3, %xmm0 #, tmp131, tmp104 # main.cpp:3: a[i * 2] += 1; addps %xmm2, %xmm0 # tmp126, vect__6.10 movaps %xmm0, %xmm1 # vect__6.10, tmp109 movss %xmm0, -32(%rax) # vect__6.10, MEM[(float *)_3] shufps $85, %xmm0, %xmm1 #, vect__6.10, tmp109 movss %xmm1, -24(%rax) # tmp109, MEM[(float *)_3 + 8B] movaps %xmm0, %xmm1 # vect__6.10, tmp111 unpckhps %xmm0, %xmm1 # vect__6.10, tmp111 shufps $255, %xmm0, %xmm0 #, vect__6.10, tmp113 movss %xmm0, -8(%rax) # tmp113, MEM[(float *)_3 + 24B] movss %xmm1, -16(%rax) # tmp111, MEM[(float *)_3 + 16B] cmpq %rdx, %rax # _24, ivtmp.15 jne .L2 #, # main.cpp:3: a[i * 2] += 1; movss .LC1(%rip), %xmm0 #, tmp116 movss 8160(%rdi), %xmm1 # MEM[(float *)a_10(D) + 8160B], tmp114 addss %xmm0, %xmm1 # tmp116, tmp114 movss %xmm1, 8160(%rdi) # tmp114, MEM[(float *)a_10(D) + 8160B] movss 8168(%rdi), %xmm1 # MEM[(float *)a_10(D) + 8168B], tmp117 addss %xmm0, %xmm1 # tmp116, tmp117 movss %xmm1, 8168(%rdi) # tmp117, MEM[(float *)a_10(D) + 8168B] movss 8176(%rdi), %xmm1 # MEM[(float *)a_10(D) + 8176B], tmp120 addss %xmm0, %xmm1 # tmp116, tmp120 addss 8184(%rdi), %xmm0 # MEM[(float *)a_10(D) + 8184B], tmp123 movss %xmm1, 8176(%rdi) # tmp120, MEM[(float *)a_10(D) + 8176B] movss %xmm0, 8184(%rdi) # tmp123, MEM[(float *)a_10(D) + 8184B] # main.cpp:5: } ret .cfi_endproc -
循环中的下标:连续访问
矢量化大成功!
void func(float *a) { for (int i = 0; i < 1024; i++) { a[i] += 1; } }_Z4funcPf: .LFB0: .cfi_startproc movss .LC1(%rip), %xmm1 #, tmp92 leaq 4096(%rdi), %rax #, _5 shufps $0, %xmm1, %xmm1 # tmp92 .p2align 4,,10 .p2align 3 .L2: # main.cpp:3: a[i] += 1; movups (%rdi), %xmm0 # MEM <vector(4) float> [(float *)_2], vect__5.7 addq $16, %rdi #, ivtmp.15 addps %xmm1, %xmm0 # tmp92, vect__5.7 movups %xmm0, -16(%rdi) # vect__5.7, MEM <vector(4) float> [(float *)_2] cmpq %rdi, %rax # ivtmp.15, _5 jne .L2 #, # main.cpp:5: } ret .cfi_endproc结论:不管是编译器还是 CPU,都喜欢顺序的连续访问。
-
编译器指令:循环展开
void func(float *a) { for (int i = 0; i < 1024; i++) { a[i] = 1; } }为什么需要循环展开:每次执行循环体 a[i] = 1后,都要进行一次判断 i < 1024。导致一部分时间花在判断是否结束循环,而不是循环体里。
优化1:
//不建议手动这样写,会妨碍编译器的 SIMD 矢量化 void func(float *a) { for (int i = 0; i < 1024; i += 4) { a[i + 0] = 1; a[i + 1] = 1; a[i + 2] = 1; a[i + 3] = 1; } }优化2:对于 GCC 编译器,可以用
#pragma GCC unroll 4表示把循环体展开为4个。对小的循环体进行 unroll 可能是划算的,但最好不要 unroll 大的循环体,否则会造成指令缓存的压力反而变慢!
void func(float *a) { #pragma GCC unroll 4 for (int i = 0; i < 1024; i++) { a[i] = 1; } }_Z4funcPf: .LFB0: .cfi_startproc movss .LC1(%rip), %xmm0 #, tmp88 leaq 4096(%rdi), %rdx #, _9 shufps $0, %xmm0, %xmm0 # tmp88 .p2align 4,,10 .p2align 3 .L2: # main.cpp:4: a[i] = 1; movups %xmm0, (%rdi) # tmp88, MEM <vector(4) float> [(float *)_2] addq $64, %rdi #, ivtmp.9 movups %xmm0, -48(%rdi) # tmp88, MEM <vector(4) float> [(float *)_2] movups %xmm0, -32(%rdi) # tmp88, MEM <vector(4) float> [(float *)_2] movups %xmm0, -16(%rdi) # tmp88, MEM <vector(4) float> [(float *)_2] cmpq %rdi, %rdx # ivtmp.9, _9 jne .L2 #, # main.cpp:6: } ret .cfi_endproc优化效果:movups重复了四次。
结构体
-
两个float,对齐到8字节
struct MyVec { float x; float y; }; MyVec a[1024]; void func() { for (int i = 0; i < 1024; i++) { a[i].x *= a[i].y; } }成功矢量化
_Z4funcv: .LFB0: .cfi_startproc movl $a, %eax #, ivtmp.14 .p2align 4,,10 .p2align 3 .L2: # main.cpp:10: a[i].x *= a[i].y; movaps (%rax), %xmm1 # MEM <vector(4) float> [(float *)_2], vect__1.6 addq $32, %rax #, ivtmp.14 movaps %xmm1, %xmm0 # vect__1.6, tmp94 shufps $221, -16(%rax), %xmm1 #, MEM <vector(4) float> [(float *)_2 + 16B], tmp95 shufps $136, -16(%rax), %xmm0 #, MEM <vector(4) float> [(float *)_2 + 16B], tmp94 # main.cpp:10: a[i].x *= a[i].y; mulps %xmm1, %xmm0 # tmp95, vect__3.8 movaps %xmm0, %xmm1 # vect__3.8, tmp98 movss %xmm0, -32(%rax) # vect__3.8, MEM[(float *)_2] shufps $85, %xmm0, %xmm1 #, vect__3.8, tmp98 movss %xmm1, -24(%rax) # tmp98, MEM[(float *)_2 + 8B] movaps %xmm0, %xmm1 # vect__3.8, tmp100 unpckhps %xmm0, %xmm1 # vect__3.8, tmp100 shufps $255, %xmm0, %xmm0 #, vect__3.8, tmp102 movss %xmm0, -8(%rax) # tmp102, MEM[(float *)_2 + 24B] movss %xmm1, -16(%rax) # tmp100, MEM[(float *)_2 + 16B] cmpq $a+8192, %rax #, ivtmp.14 jne .L2 #, # main.cpp:12: } ret .cfi_endproc -
三个 float:对齐到 12 字节
struct MyVec { float x; float y; float z; }; MyVec a[1024]; void func() { for (int i = 0; i < 1024; i++) { a[i].x *= a[i].y; } }这里我用gcc12.2.0,从movps来看,矢量化成功了,在彭于斌的课程中可能因为gcc版本的问题,矢量化失败,生成了标量的低效代码。
_Z4funcv: .LFB0: .cfi_startproc movl $a, %eax #, ivtmp.15 movl $a+12288, %edx #, _10 .p2align 4,,10 .p2align 3 .L2: # main.cpp:11: a[i].x *= a[i].y; movq (%rax), %xmm2 # MEM <vector(2) float> [(float *)_23], vect__1.6 movq 16(%rax), %xmm1 # MEM <vector(2) float> [(float *)_23 + 16B], MEM <vector(2) float> [(float *)_23 + 16B] addq $24, %rax #, ivtmp.15 movaps %xmm2, %xmm0 # vect__1.6, tmp94 shufps $0xe1, %xmm0, %xmm0 # tmp94, tmp94 unpcklps %xmm1, %xmm0 # MEM <vector(2) float> [(float *)_23 + 16B], tmp95 movq -16(%rax), %xmm1 # MEM <vector(2) float> [(float *)_23 + 8B], MEM <vector(2) float> [(float *)_23 + 8B] movss %xmm2, %xmm1 # vect__1.6, tmp97 # main.cpp:11: a[i].x *= a[i].y; mulps %xmm1, %xmm0 # tmp97, vect__3.9 movss %xmm0, -24(%rax) # vect__3.9, MEM[(float *)_23] shufps $0xe5, %xmm0, %xmm0 # vect__3.9 movss %xmm0, -12(%rax) # vect__3.9, MEM[(float *)_23 + 12B] cmpq %rax, %rdx # ivtmp.15, _10 jne .L2 #, # main.cpp:13: } ret .cfi_endproc往 struct 里添加了个根本没有用到的 z,却直接导致了优化失败!这是为什么?
-
添加一个辅助对齐的变量:对齐到 16 字节
struct MyVec { float x; float y; float z; char padding[4]; }; MyVec a[1024]; void func() { for (int i = 0; i < 1024; i++) { a[i].x *= a[i].y; } }追加了一个没有用的 4 字节变量,整个结构体变成 16 字节大小,矢量化反而成功了??
_Z4funcv: .LFB0: .cfi_startproc movl $a, %eax #, ivtmp.16 .p2align 4,,10 .p2align 3 .L2: # main.cpp:12: a[i].x *= a[i].y; movaps (%rax), %xmm1 # MEM <vector(4) float> [(float *)_27], vect__1.6 movaps 32(%rax), %xmm2 # MEM <vector(4) float> [(float *)_27 + 32B], vect__1.8 addq $64, %rax #, ivtmp.16 movaps %xmm1, %xmm0 # vect__1.6, tmp100 movaps %xmm2, %xmm3 # vect__1.8, tmp101 shufps $136, -48(%rax), %xmm0 #, MEM <vector(4) float> [(float *)_27 + 16B], tmp100 shufps $136, -16(%rax), %xmm3 #, MEM <vector(4) float> [(float *)_27 + 48B], tmp101 shufps $221, -48(%rax), %xmm1 #, MEM <vector(4) float> [(float *)_27 + 16B], tmp103 shufps $221, -16(%rax), %xmm2 #, MEM <vector(4) float> [(float *)_27 + 48B], tmp104 shufps $136, %xmm3, %xmm0 #, tmp101, tmp102 shufps $136, %xmm2, %xmm1 #, tmp104, tmp105 # main.cpp:12: a[i].x *= a[i].y; mulps %xmm1, %xmm0 # tmp105, vect__3.10 movaps %xmm0, %xmm1 # vect__3.10, tmp108 movss %xmm0, -64(%rax) # vect__3.10, MEM[(float *)_27] shufps $85, %xmm0, %xmm1 #, vect__3.10, tmp108 movss %xmm1, -48(%rax) # tmp108, MEM[(float *)_27 + 16B] movaps %xmm0, %xmm1 # vect__3.10, tmp110 unpckhps %xmm0, %xmm1 # vect__3.10, tmp110 shufps $255, %xmm0, %xmm0 #, vect__3.10, tmp112 movss %xmm0, -16(%rax) # tmp112, MEM[(float *)_27 + 48B] movss %xmm1, -32(%rax) # tmp110, MEM[(float *)_27 + 32B] cmpq $a+16384, %rax #, ivtmp.16 jne .L2 #, # main.cpp:14: } ret .cfi_endproc结论:计算机喜欢 2 的整数幂,2, 4, 8, 16, 32, 64, 128…结构体大小若不是 2 的整数幂,往往会导致 SIMD 优化失败。
-
C++11 新语法:alignas
在 struct 后加上 alignas(要对齐到的字节数) 即可实现同样效果,就不需要手动写 padding 变量了。
struct alignas(16) MyVec { float x; float y; float z; }; MyVec a[1024]; void func() { for (int i = 0; i < 1024; i++) { a[i].x *= a[i].y; } }那是不是所有结构体打上 alignas(16) 我的程序就会变快?
错了,有可能不仅不变快,反而还变慢!SIMD 和缓存行对齐只是性能优化的一个点,又不是全部。还要考虑结构体变大会导致内存带宽的占用,对缓存的占用等一系列连锁反应,总之,要根据实际情况选择优化方案。 -
结构体的内存布局:AOS 与 SOA
- AOS(Array of Struct)单个对象的属性紧挨着存xyzxyzxyzxyz
- SOA(Struct of Array)属性分离存储在多个数组xxxxyyyyzzzz
- AOS 必须对齐到 2 的幂才高效,SOA 就不需要。
- AOS 符合直觉,不一定要存储在数组这种线性结构,而 SOA 可能无法保证多个数组大小一致。
- SOA 不符合直觉,但通常是更高效的!
-
AOS:紧凑存储多个属性
符合一般面向对象编程 (OOP) 的习惯,但常常不利于性能,不利于simd优化。
struct alignas(16) MyVec { float x; float y; float z; }; MyVec a[1024]; void func() { for (int i = 0; i < 1024; i++) { a[i].x *= a[i].y; } } -
SOA:分离存储多个属性
不符合面向对象编程 (OOP) 的习惯,但常常有利于性能。又称之为面向数据编程 (DOP)。
struct MyVec { float x[1024]; float y[1024]; float z[1024]; }; MyVec a; void func() { for (int i = 0; i < 1024; i++) { a.x[i] *= a.y[i]; } } -
AOSOA:中间方案
4 个对象一组打包成 SOA,再用一个 n / 4 大小的数组存储为 AOS。
优点:SOA 便于 SIMD 优化;AOS 便于存储在传统容器;AOSOA 两者得兼!
缺点:需要两层 for 循环,不利于随机访问;需要数组大小是 4 的整数倍,不过可以用边界特判法解决。
struct MyVec { float x[4]; float y[4]; float z[4]; }; MyVec a[1024 / 4]; void func() { for (int i = 0; i < 1024 / 4; i++) { for (int j = 0; j < 4; j++) { a[i].x[j] *= a[i].y[j]; } } }
STL容器
-
std::vector:也有指针别名问题
#include <vector> void func(std::vector<int> &a, std::vector<int> &b, std::vector<int> &c) { c[0] = a[0]; c[0] = b[0]; }_Z4funcRSt6vectorIiSaIiEES2_S2_: .LFB1021: .cfi_startproc # main.cpp:5: std::vector<int> &c) { movq %rdx, %rax # c, tmp94 # main.cpp:6: c[0] = a[0]; movq (%rdi), %rdx # a_4(D)->D.22009._M_impl.D.21316._M_start, a_4(D)->D.22009._M_impl.D.21316._M_start # /usr/local/gcc-12/include/c++/12.2.0/bits/stl_vector.h:1124: return *(this->_M_impl._M_start + __n); movq (%rax), %rax # c_6(D)->D.22009._M_impl.D.21316._M_start, _10 # main.cpp:6: c[0] = a[0]; movl (%rdx), %edx # MEM[(value_type &)_11], _1 movl %edx, (%rax) # _1, MEM[(value_type &)_10] # main.cpp:7: c[0] = b[0]; movq (%rsi), %rdx # b_8(D)->D.22009._M_impl.D.21316._M_start, b_8(D)->D.22009._M_impl.D.21316._M_start movl (%rdx), %edx # MEM[(value_type &)_5], _2 movl %edx, (%rax) # _2, MEM[(value_type &)_10] # main.cpp:8: } ret .cfi_endproc -
_restrict:能否用于 std::vector?
#include <vector> void func(std::vector<int> &__restrict a, std::vector<int> &__restrict b, std::vector<int> &__restrict c) { c[0] = a[0]; c[0] = b[0]; }测试发现并没有优化,没用!
-
解决方案:
pragma omp simd或pragma GCC ivdepC/C++ 的缺点:指针的自由度过高,允许多个 immutable reference 指向同一个对象,而 Rust 从语法层面禁止,从而让编译器放心大胆优化。
#include <vector> void func(std::vector<int> &a, std::vector<int> &b) { #pragma GCC ivdep for (int i = 0; i < 1024; i++) { a[i] = b[i] + 1; } }#include <vector> void func(std::vector<int> &a, std::vector<int> &b) { #pragma omp simd for (int i = 0; i < 1024; i++) { a[i] = b[i] + 1; } }_Z4funcRSt6vectorIiSaIiEES2_: .LFB1021: .cfi_startproc # /usr/local/gcc-12/include/c++/12.2.0/bits/stl_vector.h:1124: return *(this->_M_impl._M_start + __n); movq (%rsi), %rcx # b_7(D)->D.22009._M_impl.D.21316._M_start, _13 movq (%rdi), %rdx # a_8(D)->D.22009._M_impl.D.21316._M_start, _9 xorl %eax, %eax # ivtmp.15 movdqa .LC0(%rip), %xmm1 #, tmp92 .p2align 4,,10 .p2align 3 .L2: # main.cpp:7: a[i] = b[i] + 1; movdqu (%rcx,%rax), %xmm0 # MEM <vector(4) int> [(value_type &)_13 + ivtmp.15_23 * 1], vect__3.8 paddd %xmm1, %xmm0 # tmp92, vect__3.8 # main.cpp:7: a[i] = b[i] + 1; movups %xmm0, (%rdx,%rax) # vect__3.8, MEM <vector(4) int> [(value_type &)_9 + ivtmp.15_23 * 1] addq $16, %rax #, ivtmp.15 cmpq $4096, %rax #, ivtmp.15 jne .L2 #, # main.cpp:9: } ret .cfi_endproc -
std::vector:也能实现 SOA!
// 优化前 #include <vector> struct MyVec { float x; float y; float z; }; std::vector<MyVec> a; void func() { for (std::size_t i = 0; i < a.size(); i++) { a[i].x *= a[i].y; } }// 优化后 #include <vector> struct MyVec { std::vector<float> x; std::vector<float> y; std::vector<float> z; }; MyVec a; void func() { for (std::size_t i = 0; i < a.x.size(); i++) { a.x[i] *= a.y[i]; } }
数学运算
-
数学优化:除法变乘法
相当于变成了 a * 0.5f,因为乘法更快。
float func(float a) { return a / 2; }_Z4funcf: .LFB0: .cfi_startproc # main.cpp:2: return a / 2; mulss .LC0(%rip), %xmm0 #, tmp84 # main.cpp:3: } ret .cfi_endproc -
编译器放弃的优化:分离公共除数
void func(float *a, float b) { for (int i = 0; i < 1024; i++) { a[i] /= b; } }为什么放弃优化?因为编译器害怕 b = 0
_Z4funcPff: .LFB0: .cfi_startproc leaq 4096(%rdi), %rax #, _5 shufps $0, %xmm0, %xmm0 # vect_cst__6 .p2align 4,,10 .p2align 3 .L2: # main.cpp:3: a[i] /= b; movups (%rdi), %xmm1 # MEM <vector(4) float> [(float *)_2], vect__5.7 addq $16, %rdi #, ivtmp.15 divps %xmm0, %xmm1 # vect_cst__6, vect__5.7 movups %xmm1, -16(%rdi) # vect__5.7, MEM <vector(4) float> [(float *)_2] cmpq %rdi, %rax # ivtmp.15, _5 jne .L2 #, # main.cpp:5: } ret .cfi_endproc -
解决方案1:手动优化
乘法比除法更快!提前计算好 b 的倒数避免重复求除法。
void func(float *a, float b) { float inv_b = 1 / b; for (int i = 0; i < 1024; i++) { a[i] *= inv_b; } } -
解决方案2:
-ffast-math-ffast-math 选项让 GCC 更大胆地尝试浮点运算的优化,有时能带来 2 倍左右的提升。作为代价,他对 NaN 和无穷大的处理,可能会和 IEEE 标准(腐朽的)规定的不一致。
如果你能保证,程序中永远不会出现 NaN 和无穷大,那么可以放心打开 -ffast-math。
gcc -ffast-math -O3 -fopenmp -fomit-frame-pointer -fverbose-asm -S main.cpp -o /tmp/main.S_Z4funcPff: .LFB0: .cfi_startproc movss .LC0(%rip), %xmm1 #, tmp91 leaq 4096(%rdi), %rax #, _5 divss %xmm0, %xmm1 # tmp96, reciptmp_17 shufps $0, %xmm1, %xmm1 # vect_cst__6 .p2align 4,,10 .p2align 3 .L2: # main.cpp:3: a[i] /= b; movups (%rdi), %xmm0 # MEM <vector(4) float> [(float *)_2], vect__5.7 addq $16, %rdi #, ivtmp.15 mulps %xmm1, %xmm0 # vect_cst__6, vect__5.7 movups %xmm0, -16(%rdi) # vect__5.7, MEM <vector(4) float> [(float *)_2] cmpq %rdi, %rax # ivtmp.15, _5 jne .L2 #, # main.cpp:5: } ret .cfi_endproc -
数学函数请加 std:: 前缀
- sqrt 只接受 double
- sqrtf 只接受 float
- std::sqrt 重载了 double 和 float(推荐)
- abs 只接受 int
- fabs 只接受 double
- fabsf 只接受 float
- std::abs 重载了 int, double, float(推荐)
- 总之,请勿用全局的数学函数,他们是 C 语言的遗产。始终用 std::sin, std::pow 等。
-
gcc -ffast-math -O3的强大功能#include <cmath> void func(float *a) { for (int i = 0; i < 1024; i++) { a[i] = std::sqrt(a[i]); } }开启前矢量化失败:
_Z4funcPf: .LFB984: .cfi_startproc pushq %rbx # .cfi_def_cfa_offset 16 .cfi_offset 3, -16 pxor %xmm1, %xmm1 # tmp89 leaq 4096(%rdi), %rbx #, _24 subq $16, %rsp #, .cfi_def_cfa_offset 32 .p2align 4,,10 .p2align 3 .L6: # main.cpp:5: a[i] = std::sqrt(a[i]); movss (%rdi), %xmm0 # MEM[(float *)_13], _4 ucomiss %xmm0, %xmm1 # _4, tmp89 ja .L8 #, # /usr/local/gcc-12/include/c++/12.2.0/cmath:464: { return __builtin_sqrtf(__x); } sqrtss %xmm0, %xmm0 # _4, _11 # main.cpp:4: for (int i = 0; i < 1024; i++) { addq $4, %rdi #, ivtmp.13 # main.cpp:5: a[i] = std::sqrt(a[i]); movss %xmm0, -4(%rdi) # _11, MEM[(float *)_13] # main.cpp:4: for (int i = 0; i < 1024; i++) { cmpq %rbx, %rdi # _24, ivtmp.13 jne .L6 #, .L1: # main.cpp:7: } addq $16, %rsp #, .cfi_remember_state .cfi_def_cfa_offset 16 popq %rbx # .cfi_def_cfa_offset 8 ret .L8: .cfi_restore_state movq %rdi, 8(%rsp) # ivtmp.13, %sfp # /usr/local/gcc-12/include/c++/12.2.0/cmath:464: { return __builtin_sqrtf(__x); } call sqrtf # # main.cpp:5: a[i] = std::sqrt(a[i]); movq 8(%rsp), %rdi # %sfp, ivtmp.13 # main.cpp:4: for (int i = 0; i < 1024; i++) { pxor %xmm1, %xmm1 # tmp89 # main.cpp:5: a[i] = std::sqrt(a[i]); movss %xmm0, (%rdi) # tmp91, MEM[(float *)_13] # main.cpp:4: for (int i = 0; i < 1024; i++) { addq $4, %rdi #, ivtmp.13 cmpq %rbx, %rdi # _24, ivtmp.13 jne .L6 #, jmp .L1 # .cfi_endproc开启后矢量化成功:
_Z4funcPf: .LFB984: .cfi_startproc movss .LC1(%rip), %xmm5 #, tmp100 movss .LC3(%rip), %xmm4 #, tmp101 leaq 4096(%rdi), %rax #, _11 # /usr/local/gcc-12/include/c++/12.2.0/cmath:464: { return __builtin_sqrtf(__x); } pxor %xmm3, %xmm3 # tmp94 shufps $0, %xmm5, %xmm5 # tmp100 shufps $0, %xmm4, %xmm4 # tmp101 .p2align 4,,10 .p2align 3 .L2: # main.cpp:5: a[i] = std::sqrt(a[i]); movups (%rdi), %xmm1 # MEM <vector(4) float> [(float *)_2], vect__4.7 # /usr/local/gcc-12/include/c++/12.2.0/cmath:464: { return __builtin_sqrtf(__x); } movaps %xmm3, %xmm2 # tmp94, tmp95 addq $16, %rdi #, ivtmp.16 rsqrtps %xmm1, %xmm0 # vect__4.7, tmp89 cmpneqps %xmm1, %xmm2 #, vect__4.7, tmp95 andps %xmm2, %xmm0 # tmp95, tmp89 mulps %xmm0, %xmm1 # tmp89, tmp90 mulps %xmm1, %xmm0 # tmp90, tmp91 mulps %xmm4, %xmm1 # tmp101, tmp93 addps %xmm5, %xmm0 # tmp100, tmp92 mulps %xmm1, %xmm0 # tmp93, vect__9.8 # main.cpp:5: a[i] = std::sqrt(a[i]); movups %xmm0, -16(%rdi) # vect__9.8, MEM <vector(4) float> [(float *)_2] cmpq %rdi, %rax # ivtmp.16, _11 jne .L2 #, # main.cpp:7: } ret .cfi_endproc -
嵌套循环:直接累加,有指针别名问题
#include <cmath> void func(float *a, float *b, float *c) { for (int i = 0; i < 1024; i++) { for (int j = 0; j < 1024; j++) { c[i] += a[i] * b[j]; } } }编译器担心 c 和 a 可能会指向同一个地址,而连续判断三个指针是否有重合又过于复杂,无耻地放弃了矢量化!
-
解决方案1:先读到局部变量,累加完毕后,再写入
编译器认为不存在指针别名的问题,矢量化成功!
#include <cmath> void func(float *a, float *b, float *c) { for (int i = 0; i < 1024; i++) { float tmp = c[i]; for (int j = 0; j < 1024; j++) { tmp += a[i] * b[j]; } c[i] = tmp; } } -
解决方案2:先累加到初始为 0 的局部变量,再累加到 c
也能矢量化成功!该解决方案比起前一种,由于加法顺序原因,算出来的浮点精度更高。
#include <cmath> void func(float *a, float *b, float *c) { for (int i = 0; i < 1024; i++) { float tmp = 0; for (int j = 0; j < 1024; j++) { tmp += a[i] * b[j]; } c[i] += tmp; } }
总结
-
优化手法总结
- 函数尽量写在同一个文件内
- 避免在 for 循环内调用外部函数
- 非 const 指针加上 __restrict 修饰
- 试着用 SOA 取代 AOS
- 对齐到 16 或 64 字节
- 简单的代码,不要复杂化
- 试试看 #pragma omp simd
- 循环中不变的常量挪到外面来
- 对小循环体用 #pragma unroll
- -ffast-math 和 -march=native
-
CMake 中开启 -O3
set(CMAKE_BUILD_TYPE Release) -
CMake 中开启 -fopenmp
find_package(OpenMP REQUIRED) target_link_libraries(testbench PUBLIC OpenMP::OpenMP_CXX) -
CMake 中开启
-ffast-math和-march=nativetarget_compile_options(testbench PUBLIC -ffast-math -march=native)















 224
224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









