






 本文介绍了一种名为VideoBERT的模型,它将BERT的强大能力应用于视频领域,学习视频与语言的联合表示。该模型能够在没有监督的情况下理解视频内容,并在视频字幕任务上取得了优秀的表现。实验表明,大规模训练集有助于提升模型性能。
本文介绍了一种名为VideoBERT的模型,它将BERT的强大能力应用于视频领域,学习视频与语言的联合表示。该模型能够在没有监督的情况下理解视频内容,并在视频字幕任务上取得了优秀的表现。实验表明,大规模训练集有助于提升模型性能。

1.相关工作
有监督的学习:一些最成功的视频表示学习方法利用了大量的标记数据集-来训练卷积神经网络进行视频分类。但是收集有标签的数据十分困难,此外,这些方法被设计用来表示短视频剪辑,通常只有几秒钟长。我们工作的主要不同之处在于,我们关注的是视频中事件的长期演变,我们不使用手动提供的标签。
无监督学习:有些使用单一的静态随机变量,然后使用RNN“解码”成序列,要么使用VAE型损失,要么使用GAN型损失。最近的研究使用了时间随机变量,如SV2P模型和SVGLP模型。还有各种基于GAN的方法,如SAVP方法和MoCoGAN方法。我们不同于这项工作,因为我们使用BERT模型,没有任何显式随机潜变量。
自然语言模型:我们建立在最近的nlp社区,有大规模的语言模型,如ELMO,BERT,在很多任务当中都有了state_of_art的结果。都在词的级别,以及句子的级别。然后Bert被扩展到了预训练当中。本文主要在于语言学和视觉领域。
图片和视频:目前有大量的针对图片捕捉的工作。形似于P(y|x),y is video captioning(视频字幕),x is image。应用了很多的方法,对于字幕的形成,有的是人工的分割,有的是基于估计的分割。我们使用P(x,y)的模型应用于视频字幕。并且实现了state_of_art的效果。
教学视频:不同的论文训练模型去分析教学视频,比如图中的烹饪。本文不使用任何的标签,并且学习大规模的可生成模型,基于词和视觉标识。
2.Models
这里简单总结一些bert模型,同时描述一下如何,将其扩展到对应的视频语言数据。
2.1 bert
主要使用了:“masked language model”来训练这些实体。使x = {x1,x2,x3 .. xL} 成为具体的token序列。我们能够定义联合概率分布为
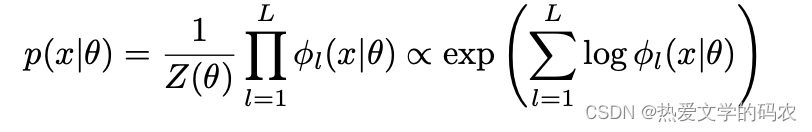
公式解释:φl(x) 是第L个位函数,参数θ, and Z 是 配分函数
为了捕捉位置信息,我们可以用每个单词在句子中的位置来“标记”它。BERT模型学习每个单词标记的嵌入,以及这些标记的嵌入,然后对嵌入向量求和,得到每个标记的连续表示。
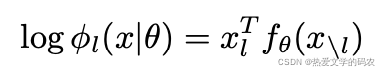
其中xl是一个one_hot向量对于第l个token。 f(x\l)是一个多层双向transfer 模型。L*D1个tensor,包含D1深度的embedding 对应于x\l,返回L*
D2个tensor,D2是每个transfer节点的输出。模型训练最大化似然函数为:
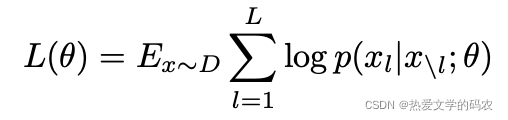
我们能够推测优化logloss(由softmax从f函数预测得到的)通过将两个句子串联起来,BERT可以扩展到两个句子的建模。
同时我们也关注句子间的关系。比如是连续的还是随机的句子通过CLS实现。同时我们可以加入一个sep来做分隔两个句子。最后一个隐藏层用来预测分类任务的标签。除了用[SEP]标记来区分句子之外,BERT还可以根据标记所来自的句子来标记每个标记。对应的联合模型可以写成p(x, y, c),其中x是第一个句子,y是第二个句子,c ={0,1}是一个标签,表示这些句子在源文档中是独立的还是连续的。
2.2. The VideoBERT model
为了应用bert到视频中,我们决定做最小的改变,并将原始的视觉数据转换成离散的标记序列。为此,我们提出通过应用分层矢量量化的特征来生成一个“视觉单词”序列,从视频使用一个预先训练的模型。除了简单之外,这种方法还鼓励模型专注于视频中的高级语义和长期时间动态。可以将从视频中使用ASR衍生出来的语言句子与视觉句子结合起来。[CLS] orange chicken with [MASK] sauce [>] v01 [MASK] v08 v72 [SEP], where v01 and v08 are visual tokens, and [>] is a special token we introduce to combine text and video sentences. 虽然这个完形填空任务很自然地扩展到一系列的语言和视觉标记,但应用下一个句子预测任务,如BERT使用的,就不那么简单了。
我们提出了一种语言-视觉对齐任务,在该任务中,我们使用[CLS]标记的最终隐藏状态来预测语言句子是否与视觉句子在时间上对齐。
为了实现。我们首先随机结合了相邻的句子到单个句子中。为了允许模型能够学到词义相符(及时两个暂时不相邻),其次,因为状态的转换即使相同的行为也会十分不同根据不同的视频,由此,我们选择了1到5个视频tokens的随机二次抽样。这个不仅帮助模型更鲁棒了(因为更能适应视频速度的变化)而且还允许模型在更大的时间范围内捕捉时间动态,并学习更长期的状态转换。我们将对视频和文本结合的其他方式的研究留到未来的工作中。
总的来说,我们有三种与不同的输入数据模式相对应的训练制度:纯文本、纯视频和视频文本。对于纯文本和纯视频,标准掩模完成目标用于训练模型。对于文本-视频,我们使用上述的语言-视觉对齐分类目标。总体培训目标是个人目标的加权和。文本目标迫使VideoBERT在语言建模方面做得很好;视频目标迫使它学习一种“视频语言模型”,它可以用于学习动态和学习。
3.实验与分析
3.1. Dataset
深度学习模型,在语言和视觉方面都是主流,在不断增加的数据集的情况下,表现出了显著的进步。例如,“大”BERT模型(我们使用的)是根据BooksCorpus(800万字)和英语Wikipedia (2500万字)的连接进行预先训练的。不幸的是,这样的数据集相对较小,所以我们转向YouTube收集大规模的视频数据集进行训练。 为了从视频中获取文本,我们利用YouTube Data API提供的YouTube自动语音识别(ASR)工具包来检索带有时间戳的语音信息。API返回单词序列和预测的语言类型。在312K的视频中,180K有API可以检索到的ASR,其中预计有120K是英文的。在我们的实验中,虽然我们将所有视频用于视频目标,但我们只使用来自英语ASR的文本用于VideoBERT的文本和视频-文本目标。
我们在Kinet- ics数据集上预训练S3D网络,该数据集涵盖了YouTube视频的广泛动作范围,并作为每个单独剪辑的通用表示。
我们使用分层k- means来标记视觉特征。我们通过直观地检查聚类的一致性和代表性,来调整层次结构层次d的数量和每个层次k的聚类数量。我们设d=4, k = 12,总共得到20736个集群。图4说明了这个“矢量量化”过程的结果。 对于每个ASR单词序列,我们使用现成的基于lstm的语言模型,通过添加标点符号,将单词流分解成句子。对于每个句子,我们遵循来自BERT的标准文本预处理步骤和标记化
3.2 模型预训练
作者为YouCook II的验证集收集了63个最常见对象的bounding box。然而,对于行动并没有基本的真理,许多其他的普通物体也没有被贴上标签。 表1显示了VideoBERT及其消融的top-1和top-5精度。为了验证VideoBERT确实使用了视频输入,我们首先删除VideoBERT的视频输入,然后只使用该语言。
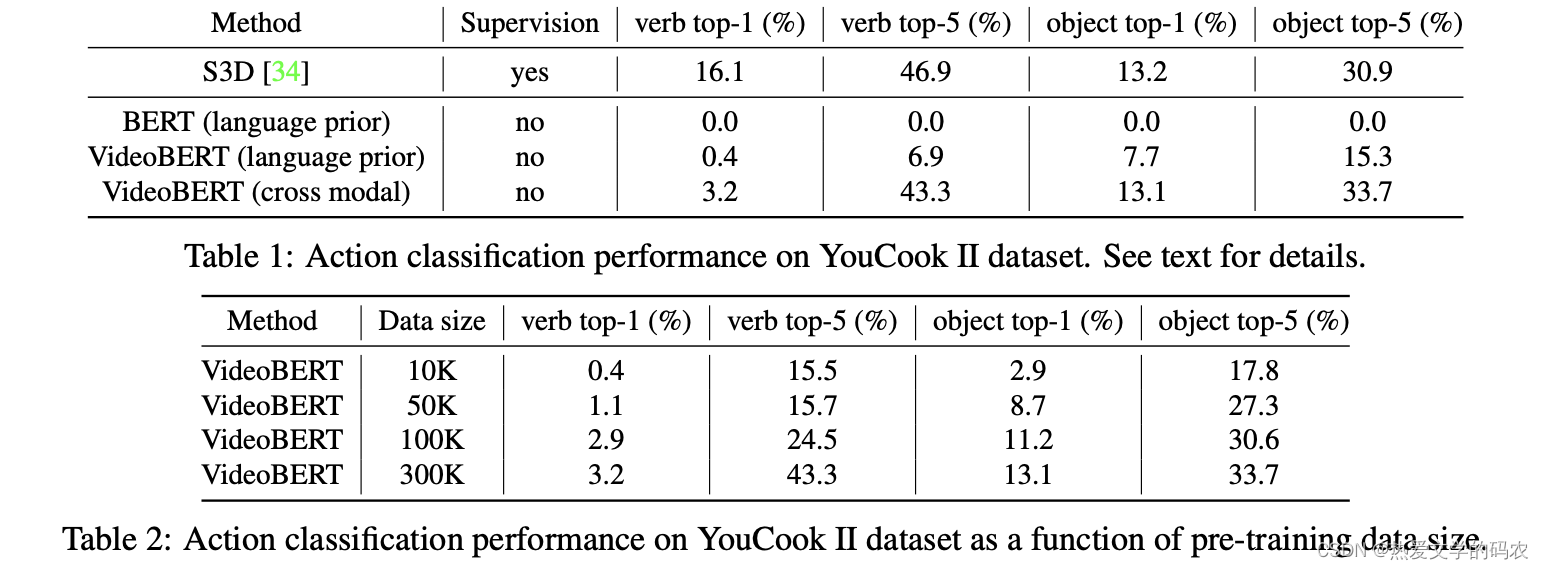
正如预期的那样,VideoBERT的语言先验适应于烹饪句子,并且优于传统的BERT模型。
3.3. 大型训练集的好处
我们还研究了预训练数据集大小的影响。在本实验中,我们从预训练集中选取10K、50K和100K的随机视频子集,并使用与上面相同的设置,对于相同的epoch数目,进行预训练的VideoBERT。表2显示了性能。我们可以看到,准确性随着数据量的增加而单调增长,没有显示出饱和的迹象。这表明VideoBERT可以从更大的训练前数据集中获益。
3.4 字幕的迁移学习
我们进一步证明了VideoBERT作为特征提取器的有效性。为了提取只给出视频输入的特征,我们再次使用一个简单的填空任务,将视频标记附加到模板句子中。我们提取视频token的特征,以及屏蔽掉的文本令牌,取其平均值并将两者连接在一起,以供下游任务中的监督模型使用。
我们评估在视频字幕上提取的特征,其中ground truth视频分割被用来训练一个监督模型,将视频片段映射到字幕。我们使用与他们相同的模型,即transfer编码器-解码器,但我们用上面描述的VideoBERT派生的特性替换编码器的输入。我们还将VideoBERT特性与平均池化的S3D特性连接起来;作为基准,我们也考虑使用S3D功能而不使用VideoBERT。我们设置transfer块层的数量为2,即隐藏单元。我们注意到,预测的单词序列很少完全等于ground truth,这解释了为什么表3中的度量(测量n-gram重叠)的绝对值都很低。然而,从语义上讲,结果似乎是合理的。
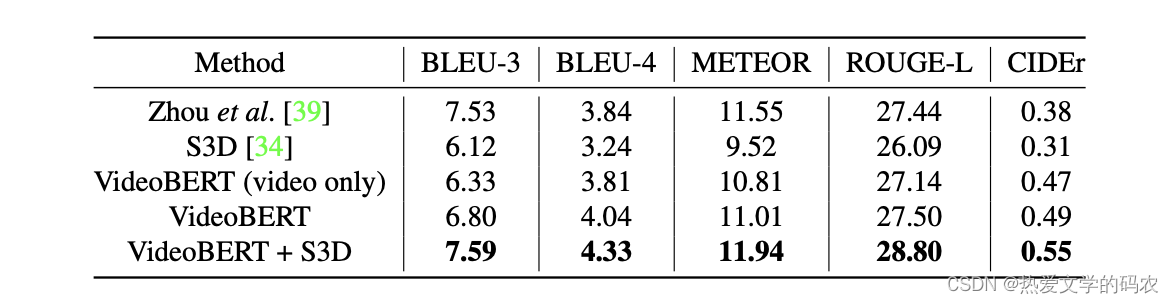
可以看到效果超过了一般的baseline
4.讨论和结论
本文将功能强大的BERT模型用于学习视频的视觉语言联合表示。我们的实验结果表明,我们能够学习高级语义表示,并且我们在YouCook II数据集上的视频字幕的性能优于目前最先进的视频字幕。我们还证明了该模型可以直接用于开放词汇分类,并且其性能随训练集的大小单调增长。这项工作是学习这种联合表征方向的第一步。对于许多应用程序,包括烹饪,重要的是使用空间细粒度的可视化表示,而不是仅仅在框架或剪辑级别工作,这样我们可以区分单个对象和它们的属性。我们设想要么使用预先训练的对象检测和语义分割模型,要么使用未经监督的技术来获得更广泛的覆盖。我们还希望在多个时间尺度上明确地为视觉模式建模,而不是像我们目前的方法那样,跳过框架,构建单一的词汇表。除了改进模型,我们计划评估我们的方法在其他视频理解任务,和其他主要做的做饭。(例如,我们可以使用最近发布的COIN数据集,其中包含手动标记的教学视频)我们相信,通过视频和语言进行大规模表征学习的前景非常光明。

















 1048
1048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









