






第1章 绪论
1.1引言
机器学习:研究如何通过计算手段,利用经验来改善系统自身的性能
研究的主要内容:学习算法——关于在计算机上从数据中产生模型的算法
模型——全局性结果 模式——局部性结果
1.2基本术语
数据集dataset:一组数据的集合
示例instance、样本sample:数据集中关于对象的一条描述
属性attribute、特征feature:反映对象的性质
属性值attribute value:属性的取值
属性空间attribute space、样本空间sample space、输入空间:属性张成的空间,每一点与一类对象相对应
特征向量feature vector:属性空间中的一点,一类对象
维数dimensionality:样本属性的个数
学习learning、训练training:从数据中学得模型的过程
训练样本training sample:用于训练的样本
训练集training set:用于训练的数据集,希望训练集能很好地反应样本空间的特性
假设hypothesis、学习器learner:学习获得的模型(学习算法在给定数据集和参数空间上的实例化)
真相、真实ground-truth:学习获得的模型对应的数据集的潜在的规律
样例example:拥有标记信息的样本(有时将样本和标记当作整体看,叫做样本)
标记空间label space、输出空间:所有标记的集合
分类classification:预测值为离散值的预测过程
回归regression:预测值为连续值的预测过程
二分类binary classification:只涉及两个类别的分类吗,一个类别是正类positive class,一个是反类
negative class(负类)
多分类任务multi-class classification:涉及多个类别的分类
测试testing:学的模型之后,使用其进行预测的过程
测试样本testing sample、测试示例testing instance:被预测的样本
聚类clustering:将数据分成若干组,每组称为一个簇cluster(这些不同的组可能对应一些潜在的概念化分,聚类过程有助于我们了解数据内在的规律,更深入分析数据)
监督学习supervised learning、有导师学习:训练数据拥有标记(分类、回归)
无监督学习unsupervised learning、无导师学习:训练数据没有标记(聚类)
泛化generalization:模型适应于新样本(未见样本unseen instance)的能力,泛化能力越强,模型越能更好地适用于整个样本空间
独立同分布independent and identically distributed:通常假设样本空间中全体样本服从一个未知的分布distribution,我们获得的样本都是独立地从这个分布上采样获得的,一般样本越多,我们得到的关于未知分布的信息越多,越有可能训练得到泛化能力强的模型
1.3假设空间
科学推理两大手段:归纳(induction)、演绎(deduction),归纳是从特殊到一般的泛化generalization过程,演绎是从一般到特殊的特化过程specialization。从样本中学习模型,是一个归纳过程,因此亦成为归纳学习induction learning。
广义归纳学习:从样例中学习
狭义归纳学习:从数据集中学得概念,因此被称为概念学习、概念形成(学得泛化性能好而且语义明确的概念很难,应用较少)
学习可以看作是在所有假设hypothesis空间中进行搜索的过程
现实生活中的假设空间一般很大,而学习过程在有限的训练集上进行,因此可能很多假设与训练集一致,即存在着一个与训练集一致的假设集合,也称为版本空间version space。
1.4归纳偏好
归纳偏好inductive:机器学习算法在学习过程中对某种类型假设的偏好
特征选择feature selection:基于训练集选择对学习算法有益的相关特征
任何一个有效的机器学习算法必有其归纳偏好,否则它将被假设空间中看似在训练集上等效的假设所迷惑。
奥卡姆剃刀Occam‘s razor:如果多个假设与观察一致,选取最简单的一个。
归纳偏好与问题是否匹配,一般直接决定了算法是否能取得好的性能
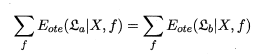
“没有免费的午餐”定理:如果在一些问题上,算法a比算法b好,那么必定存在另一些问题,b比a好。(假设所有问题出现机会相同,同等重要)
脱离具体问题,空谈“什么算法更好”毫无意义
1.5发展历程
推理期(逻辑推理家、通用问题求解)-》知识期(专家系统)-》学习期
习题
1.1
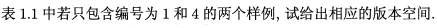

从一般到特殊进行搜索:
1.(色泽=青绿,根蒂=*,敲声=*)
2.(色泽=*,根蒂=蜷缩,敲声=*)
3.(色泽=*,根蒂=*,敲声=浊响)
4.(色泽=青绿,根蒂=蜷缩,敲声=*)
5.(色泽=青绿,根蒂=*,敲声=浊响)
6.(色泽=*,根蒂=蜷缩,敲声=浊响)
7.(色泽=青绿,根蒂=蜷缩,敲声=浊响)
1.2

合取式:
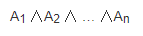
析合范式:
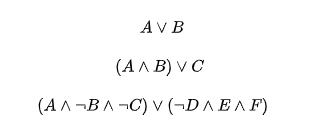
由表一知,色泽属性有三种属性值:青绿、乌黑、*;根蒂属性有四种属性值:蜷缩、硬挺、稍蜷、*;敲声属性有四种属性值:浊响、清脆、沉闷、*。
在假设空间中,从一般到特殊进行搜索,具有3个通配符的合取式有1种,具有2个通配符的合取式有2+3+3=8种,具有一个通配符的合取式有3*3+2*3+2*3=21种,没有通配符的叶子合取式有2*3*3=18种,由于样本中存在正例,所以不考虑空集,合取式一共有1+8+21+18=48种。
不考虑冗余的情况下,含有k个合取式的析合范式有
C
48
k
C_{48}^{k}
C48k种情况,最多含有k个合取式的析合范式有
∑
n
=
1
k
C
48
n
\sum_{n=1}^kC_{48}^{n}
∑n=1kC48n种情况。考虑冗余的情况比较复杂,由于假设空间很大,所以需要借助计算机进行求解。参考连接
1.3

归纳偏好:认为与样本数据一致性越高的模型越好
1.4

假设目标函数
f
f
f均匀分布,则对于一个样本
x
x
x,有一半的
f
f
f的预测结果与
h
h
h不同。对于一个二分类问题而言,
f
f
f的个数一共有
2
∣
χ
∣
2^{|\chi|}
2∣χ∣.
对于性能度量函数
ℓ
\ell
ℓ,自变量
h
(
x
)
h(x)
h(x)和
f
(
x
)
f(x)
f(x)只有
h
(
x
)
=
f
(
x
)
h(x)=f(x)
h(x)=f(x)和
h
(
x
)
≠
f
(
x
)
h(x) \neq f(x)
h(x)=f(x)两种情况,所以
l
l
l不妨可以看作只有两种固定取值
A
A
A和
B
B
B。
∑
f
E
o
t
e
(
ε
a
∣
X
,
f
)
=
∑
f
∑
h
∑
x
∈
χ
−
X
P
(
x
)
ℓ
(
h
(
x
)
,
f
(
x
)
)
P
(
h
∣
X
,
ε
a
)
=
∑
x
∈
χ
−
X
P
(
x
)
∑
h
P
(
h
∣
X
,
ε
a
)
∑
f
ℓ
(
h
(
x
)
,
f
(
x
)
)
=
∑
x
∈
χ
−
X
P
(
x
)
∑
h
P
(
h
∣
X
,
ε
a
)
∗
(
0.5
∗
2
∣
χ
∣
∗
ℓ
(
h
(
x
)
≠
f
(
x
)
)
+
0.5
∗
2
∣
χ
∣
∗
ℓ
(
h
(
x
)
=
f
(
x
)
)
)
=
∑
x
∈
χ
−
X
P
(
x
)
∑
h
P
(
h
∣
X
,
ε
a
)
(
0.5
∗
2
∣
χ
∣
A
+
0.5
∗
2
∣
χ
∣
∗
B
)
=
2
∣
χ
∣
−
1
(
A
+
B
)
∑
x
∈
χ
−
X
P
(
x
)
∑
h
P
(
h
∣
X
,
ε
a
)
=
2
∣
χ
∣
−
1
(
A
+
B
)
∑
x
∈
χ
−
X
P
(
x
)
∗
1
\sum_{f}E_{ote}(\varepsilon_a|X,f)=\sum_{f}\sum_{h}\sum_{x \in \chi -X}P(x)\ell(h(x),f(x))P(h|X,\varepsilon_a) \\=\sum_{x \in \chi -X}P(x)\sum_{h}P(h|X,\varepsilon_a) \sum_{f}\ell(h(x),f(x)) \\=\sum_{x \in \chi -X}P(x)\sum_{h}P(h|X,\varepsilon_a)* \\(0.5*2^{|\chi|}*\ell(h(x)\neq f(x))+0.5*2^{|\chi|}*\ell(h(x)=f(x))) \\=\sum_{x \in \chi -X}P(x)\sum_{h}P(h|X,\varepsilon_a)(0.5*2^{|\chi|}A+0.5*2^{|\chi|}*B) \\=2^{|\chi|-1}(A+B)\sum_{x \in \chi -X}P(x)\sum_{h}P(h|X,\varepsilon_a) \\=2^{|\chi|-1}(A+B)\sum_{x \in \chi -X}P(x)*1
f∑Eote(εa∣X,f)=f∑h∑x∈χ−X∑P(x)ℓ(h(x),f(x))P(h∣X,εa)=x∈χ−X∑P(x)h∑P(h∣X,εa)f∑ℓ(h(x),f(x))=x∈χ−X∑P(x)h∑P(h∣X,εa)∗(0.5∗2∣χ∣∗ℓ(h(x)=f(x))+0.5∗2∣χ∣∗ℓ(h(x)=f(x)))=x∈χ−X∑P(x)h∑P(h∣X,εa)(0.5∗2∣χ∣A+0.5∗2∣χ∣∗B)=2∣χ∣−1(A+B)x∈χ−X∑P(x)h∑P(h∣X,εa)=2∣χ∣−1(A+B)x∈χ−X∑P(x)∗1
可以看到,对于任意性能度量函数,一个算法的总误差与算法无关,因此对于任意算法总误差都相同,即NFL得证。
1.5


1.在向搜索引擎提交信息的阶段,能够从提交文本中进行信息提取,进行语义分析。
2.在搜索引擎进行信息匹配的阶段,能够提高问题与各个信息的匹配程度。
3.在向用户展示搜索结果的阶段,能够根据用户对结果感兴趣的程度进行排序。
参考:https://zhuanlan.zhihu.com/p/44279394















 9831
9831











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









