







LLM 检索增强生成技术:RAG
文章目录
受限于训练数据的时效性和局限性,当涉及实时新闻或特定专业领域内知识时,大语言模型的生成结果可能会产生误导性的“幻觉”。在现实世界的应用中,数据需要不断更新以反映最新的发展,生成的内容必须是透明可追溯的,以便控制成本并保护数据隐私。
因此,简单依赖这些 “黑盒” 模型是不够的,我们需要更精细的解决方案来满足这些复杂的需求。
1. 什么是RAG
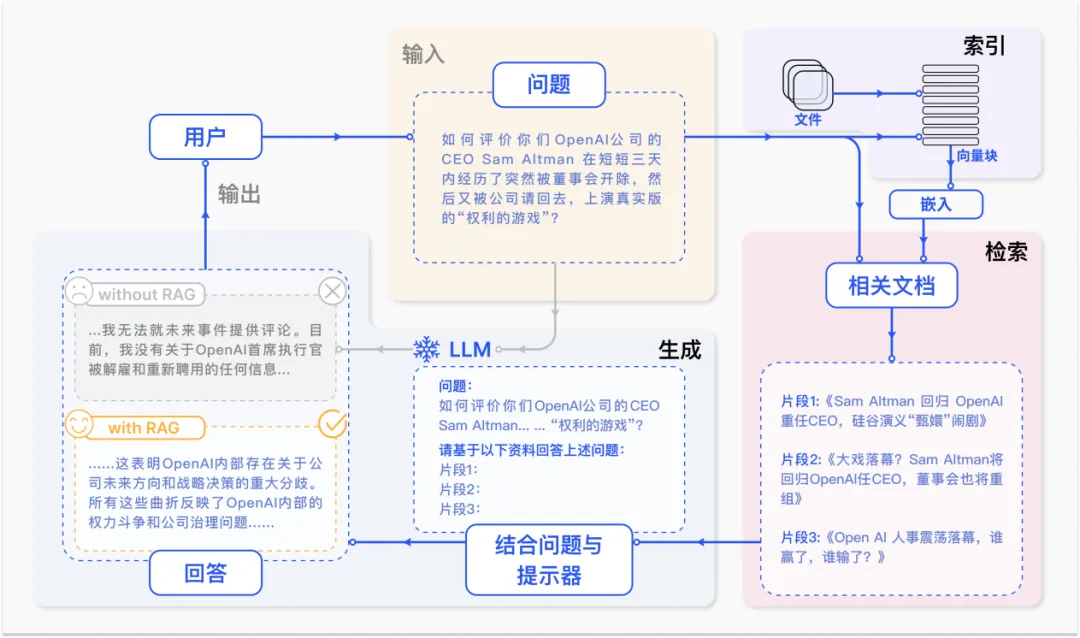
在上述场景下,检索增强生成(Retrieval-Augmented Generation, RAG) 技术应运而生。该技术旨在通过信息检索系统从外部知识库中获取相关信息,为大语言模型提供时效性强、领域相关的外部知识,以减少大语言模型生成内容中的错误。一个典型的 RAG 案例如图所示。如果我们向 LLM 询问 OpenAI CEO Sam Atlman 在短短几天内突然解雇随后又被复职的事情。由于受到预训练数据的限制,缺乏对最近事件的知识,ChatGPT 则表示无法回答。RAG 则通过从外部知识库检索最新的文档摘录来解决这一差距。在这个例子中,它获取了一系列与询问相关的新闻文章。这些文章,连同最初的问题,随后被合并成一个丰富的提示,使 LLM 能够综合出一个有根据的回应。
RAG技术的优缺点:
- 优点:RAG 有效地缓解了幻觉问题,提高了知识更新的速度,并增强了内容生成的可追溯性,使得大型语言模型在实际应用中变得更加实用和可信。
- 不足:真实的应用场景下,检索返回的结果可能受限于检索质量、呈现格式、输入长度等问题,从而导致大语言模型不能很好地利用这些信息。
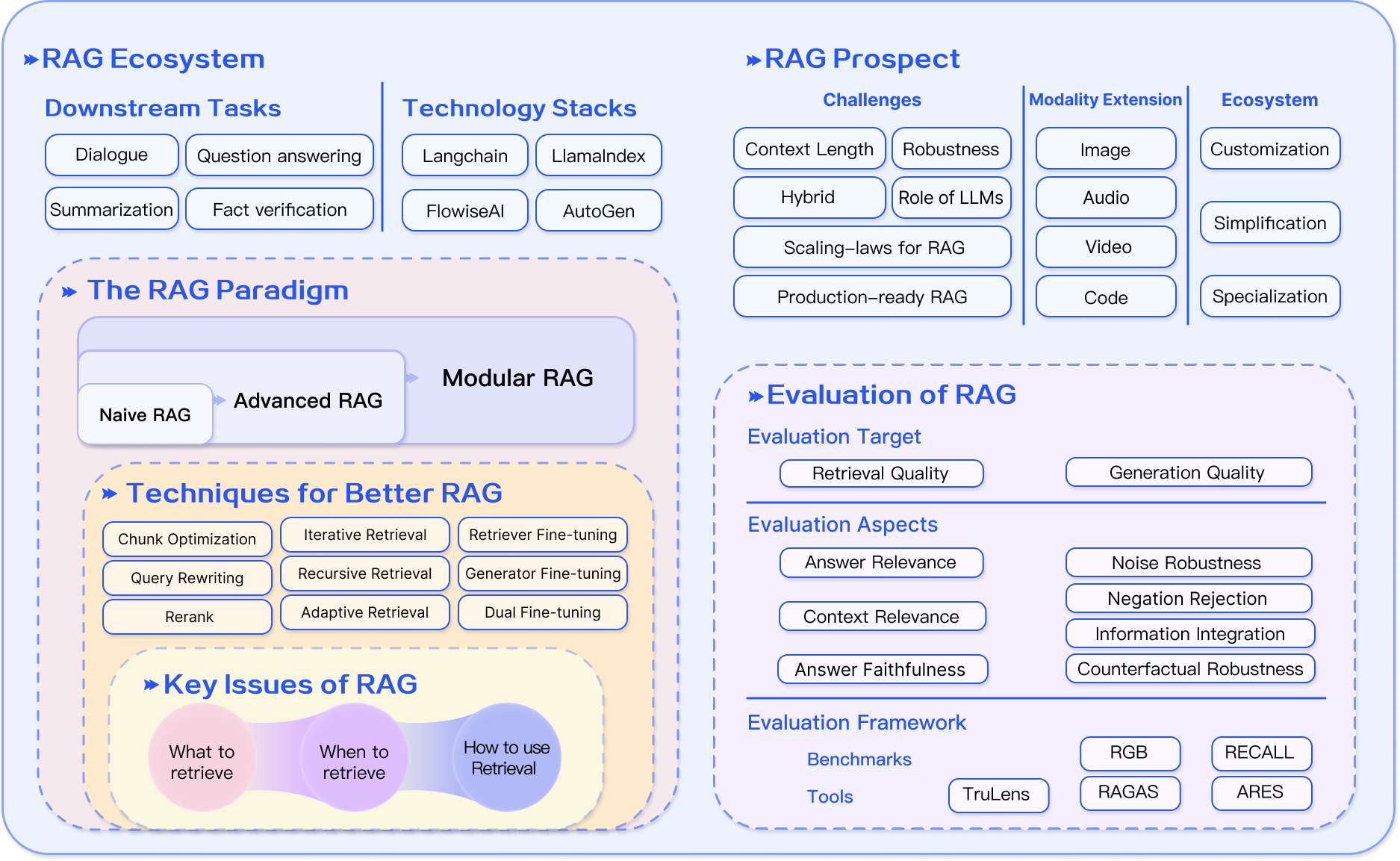
2. RAG技术发展
RAG 概念由 Lewis 于 2020 年提出,此后发展迅速,其研究历程经历了不同的阶段。最初,研究旨在通过在预训练阶段为语言模型注入额外知识来增强语言模型。ChatGPT 的推出引发了人们对利用大型模型进行深入语境理解的兴趣,加速了 RAG在推理阶段的发展。随着研究人员对大型语言模型 (LLM) 功能的深入研究,重点转向增强其可控性和推理能力,以满足日益增长的需求。GPT-4 的出现标志着一个重要的里程碑,它以一种新颖的方式彻底改变了 RAG,将 RAG 与微调技术相结合,同时继续改进预训练策略。
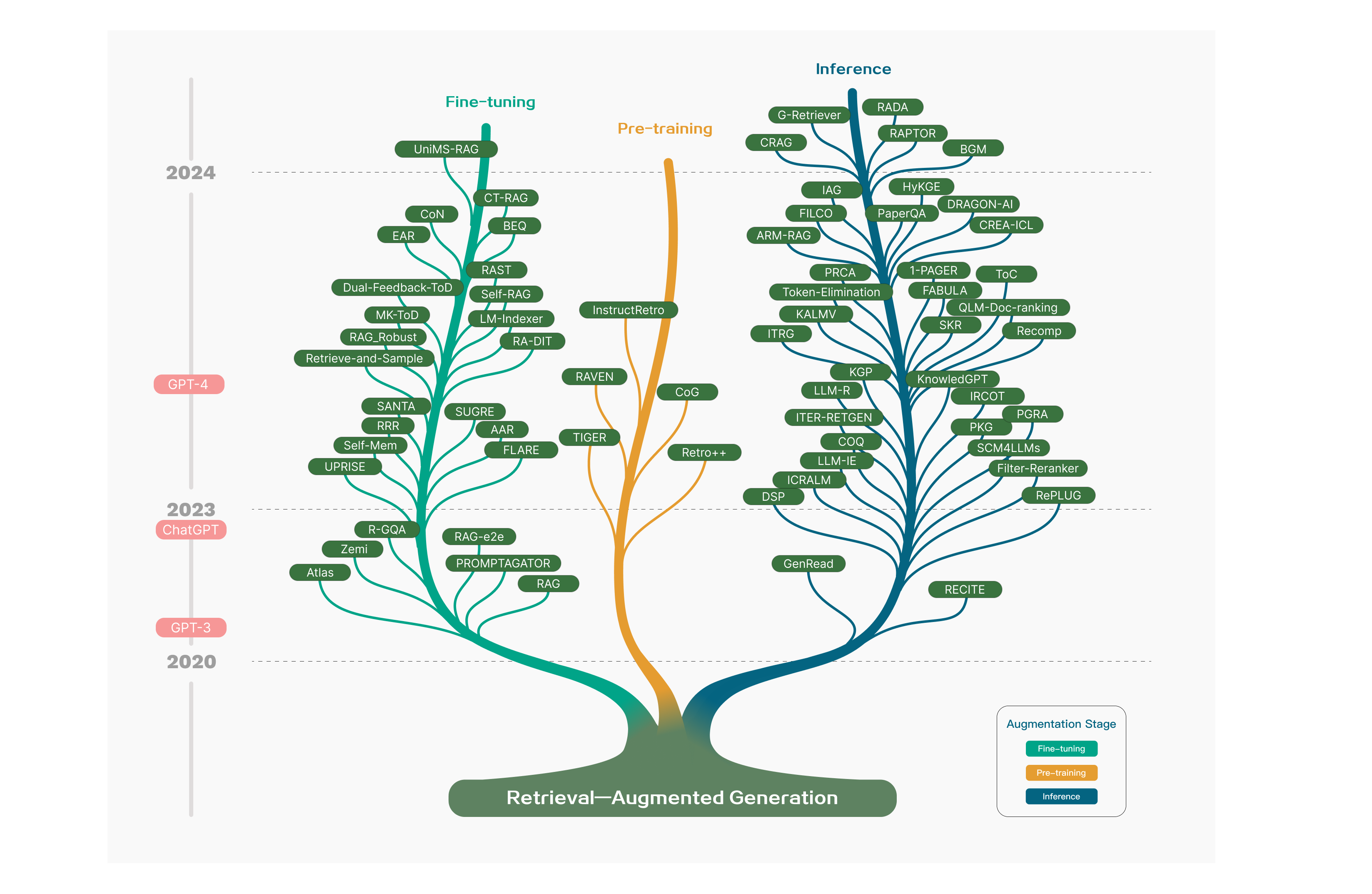
在RAG的技术发展中,从技术范式的角度将其演进概括为以下几个阶段:
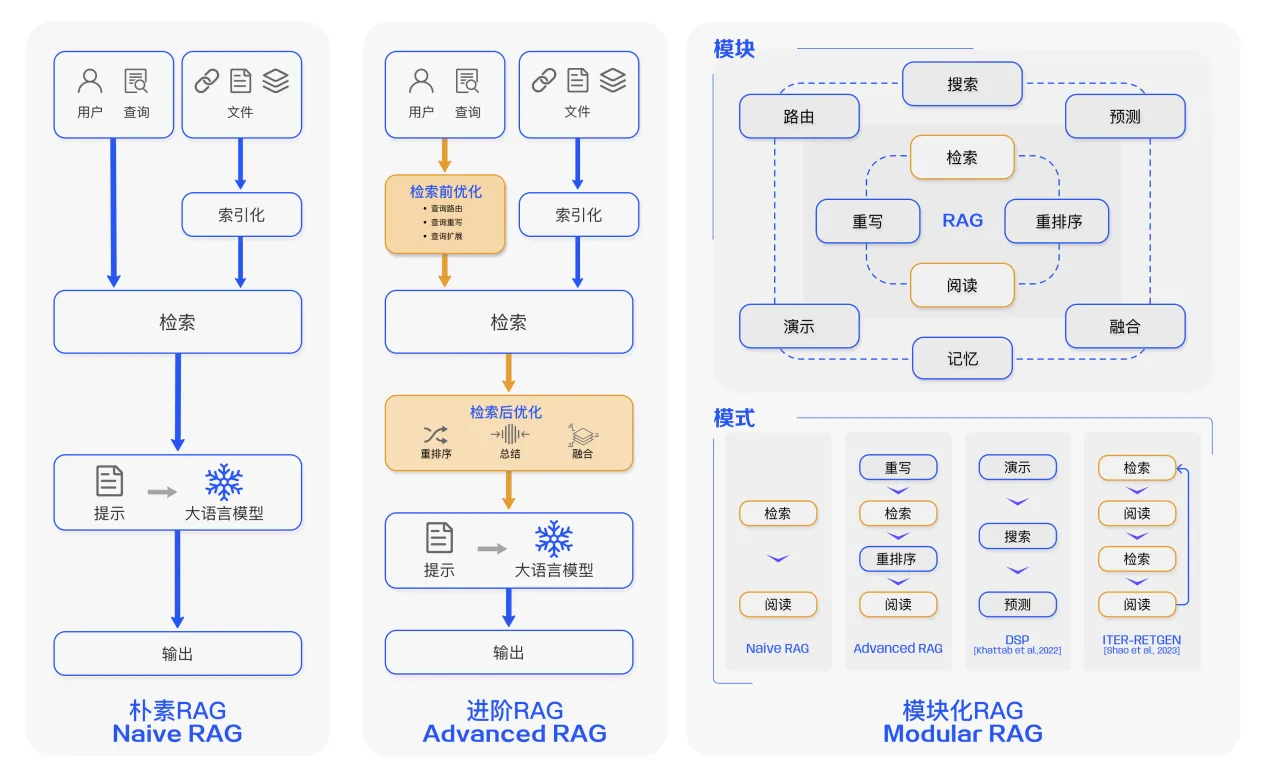
在 RAG 的技术发展过程中,从技术范式角度,将其总结成如下几个阶段:
1.朴素(Naive RAG)
主要包括包括三个基本步骤:
- 索引 — 将文档库分割成较短的 Chunk,并通过编码器构建向量索引。
- 检索 — 根据问题和 chunks 的相似度检索相关文档片段。
- 生成 — 以检索到的上下文为条件,生成问题的回答。
2.进阶的 RAG(Advanced RAG)
Naive RAG 在检索质量、响应生成质量以及增强过程中存在多个挑战。
Advanced RAG 范式随后被提出,并在数据索引、检索前和检索后都进行了额外处理。
通过更精细的数据清洗、设计文档结构和添加元数据等方法提升文本的一致性、准确性和检索效率。
在检索前阶段则可以使用问题的重写、路由和扩充等方式对齐问题和文档块之间的语义差异。
在检索后阶段则可以通过将检索出来的文档库进行重排序避免 “Lost in the Middle ” 现象的发生。或是通过上下文筛选与压缩的方式缩短窗口长度。
3.模块化 RAG(Modular RAG)
随着 RAG 技术的进一步发展和演变,新的技术突破了传统的 Naive RAG 检索 — 生成框架,基于此提出模块化 RAG 的概念。
在结构上它更加自由的和灵活,引入了更多的具体功能模块,例如查询搜索引擎、融合多个回答。
技术上将检索与微调、强化学习等技术融合。流程上也对 RAG 模块之间进行设计和编排,出现了多种的 RAG 模式。然而,模块化 RAG 并不是突然出现的,三个范式之间是继承与发展的关系。
Advanced RAG 是 Modular RAG 的一种特例形式,而 Naive RAG 则是 Advanced RAG 的一种特例。
模块化 RAG 框架:
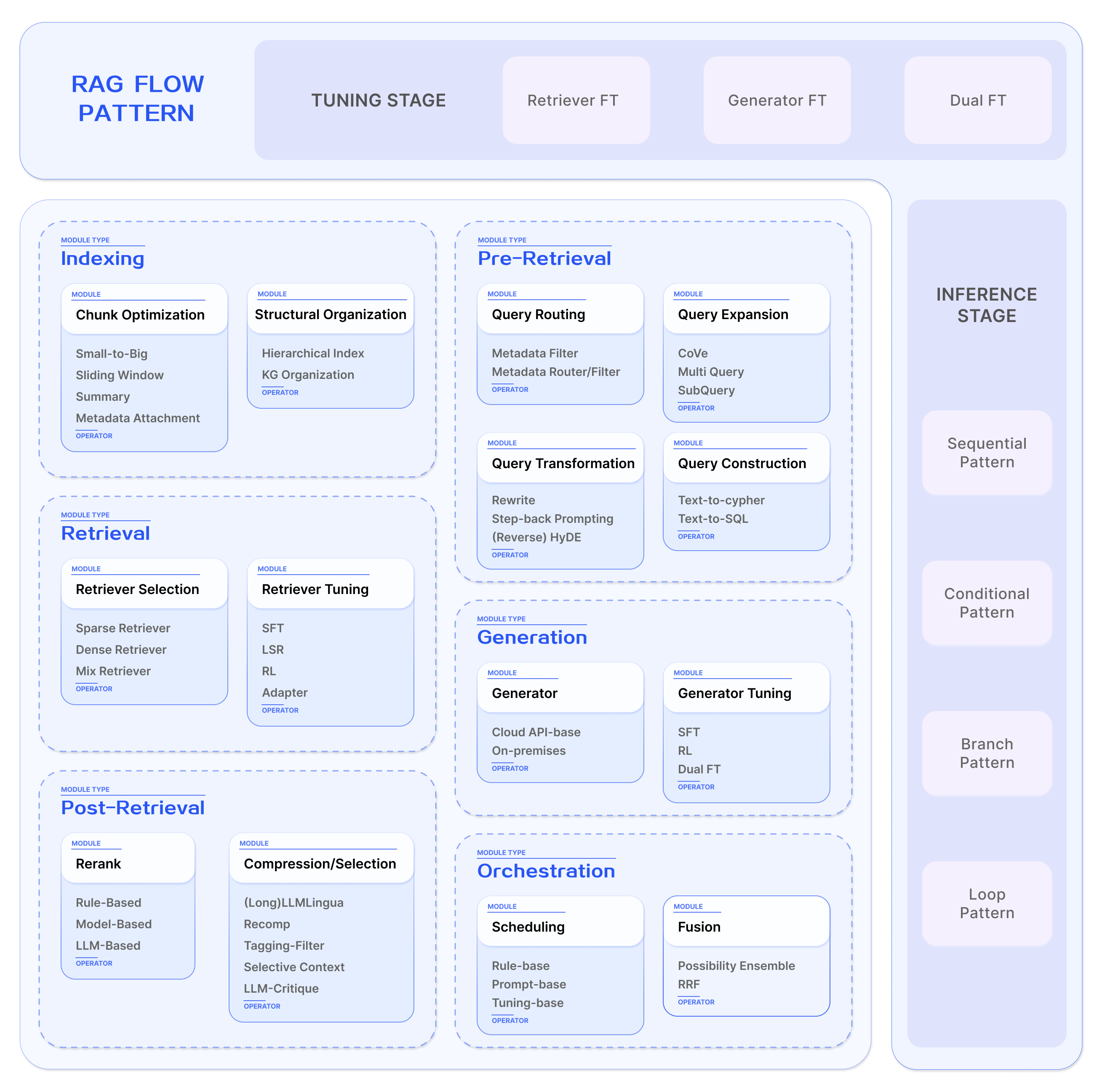
模块化 RAG 技术地图 :

3. 如何进行增强?
为了构建良好的 RAG 系统,对应于三要素(检索、增强、生成),其中增强部分是关键,需要考虑三个关键问题:
- 要检索什么?
- 啥时候取回?
- 如何使用检索到的内容?
从以上三个问题出发,我们组织如下增强:
- 增强阶段。检索增强可以在 预训练、微调和推理 阶段进行,这决定了外部知识的参数化程度,并对应所需的不同计算资源。
- 增强源。增强可以利用各种形式的数据,包括非结构化数据,如文本段落、短语或单个单词。也可以使用结构化数据,如索引文档、三元组数据或子图。另一种方法是不依赖外部信息源,而是充分利用 LLM 的内在功能,从LLM本身生成的内容中进行检索。
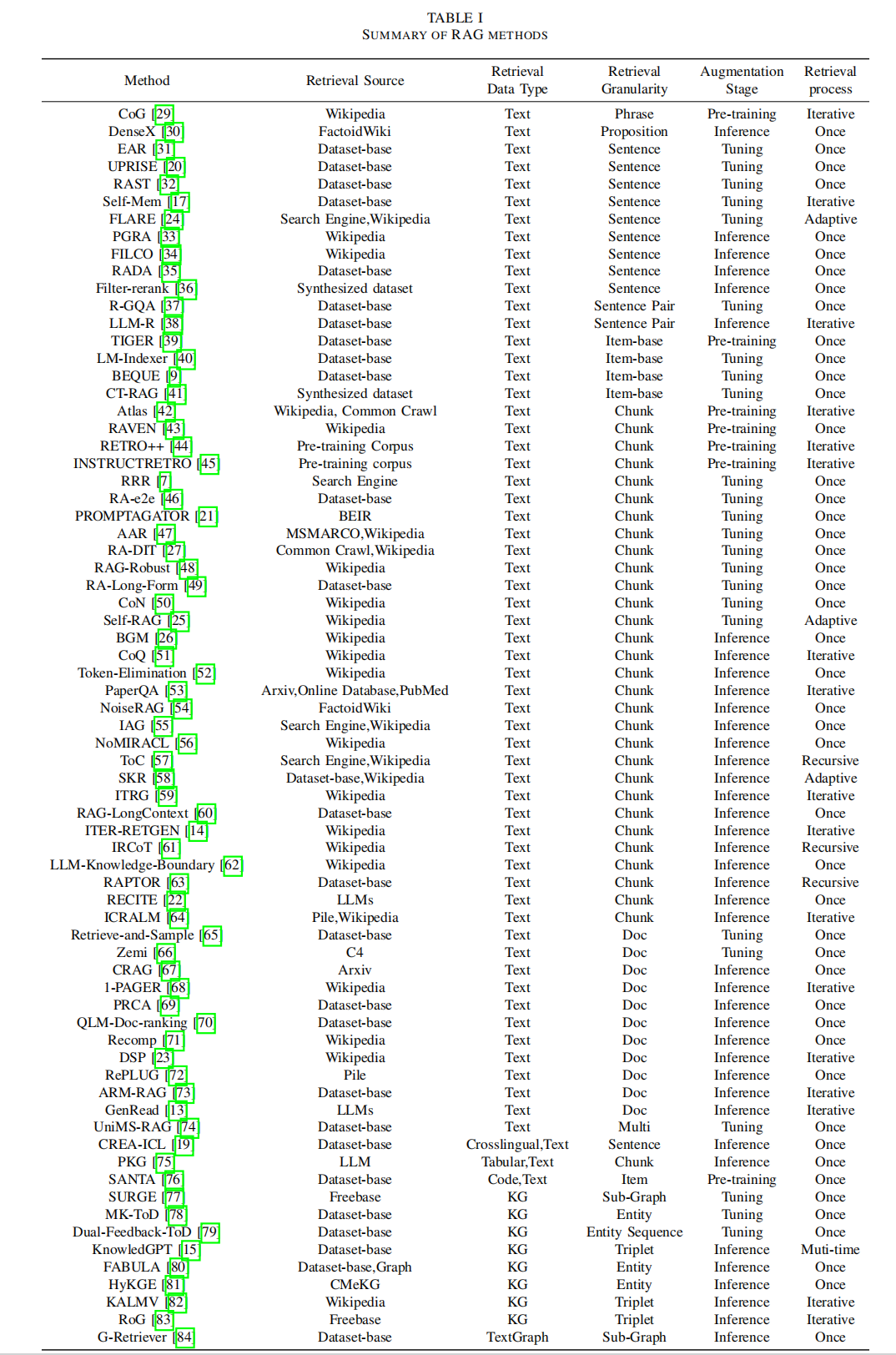
- 增强过程。最初的检索是一个一次过程,但在RAG的发展过程中,逐渐出现了迭代检索、递归检索和自适应检索方法,其中LLM自行决定检索的时间。

4. RAG 还是 Fine-tuning ?
除了RAG之外,LLM的主要优化策略还包括Prompt Engineering和Fine-tuning(FT),它们各有特色,根据对外部知识的依赖和对模型调整的要求,各自有适合的场景。
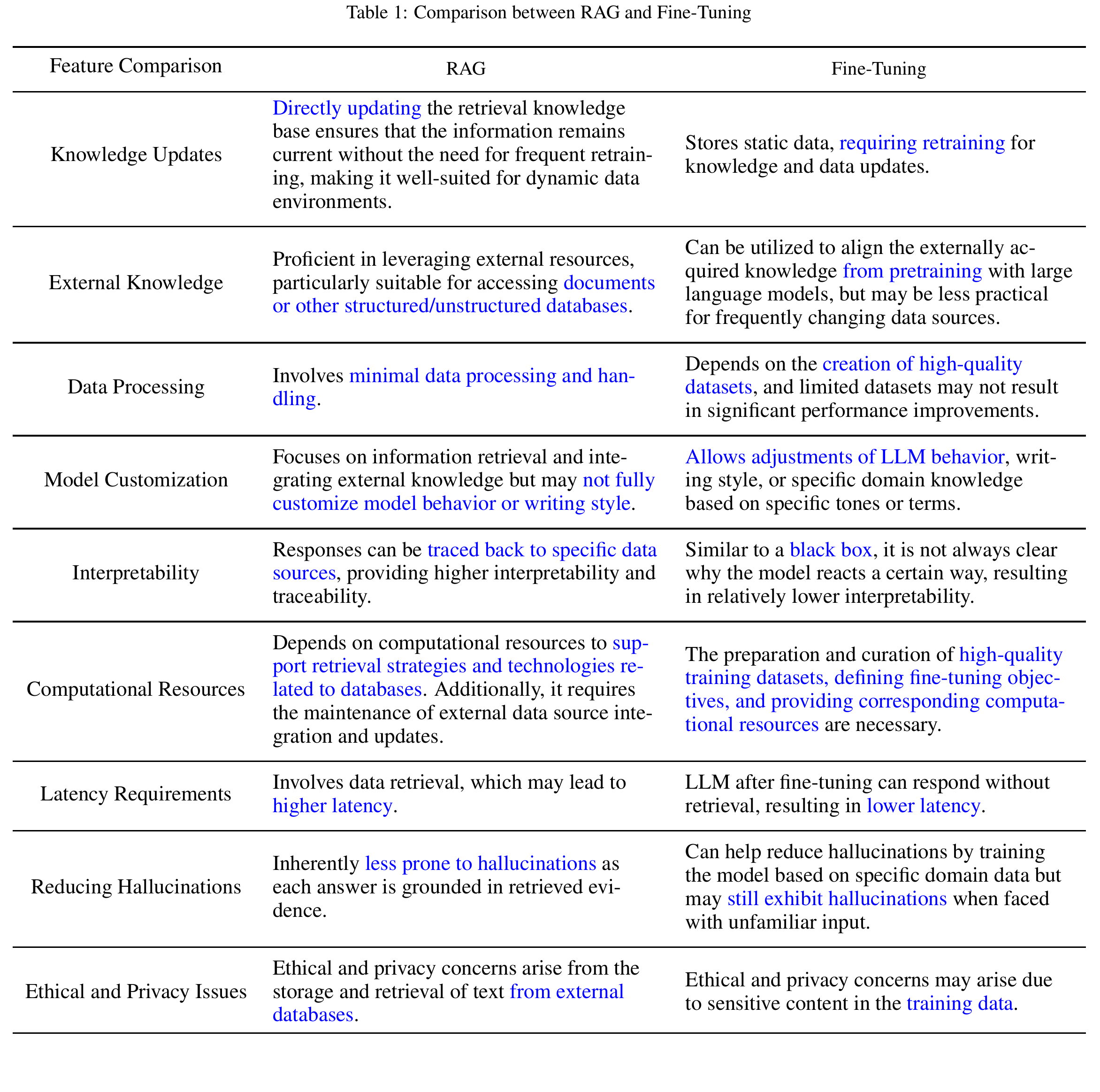
RAG 就像是给模型一本定制信息检索的教科书,非常适合特定查询。而 FT 就像是一个学生随着时间的推移内化知识,更适合模仿特定的结构、风格或格式。FT 可以通过增强基础模型的知识、调整输出和教授复杂的指令来提高模型的性能和效率。但它并不擅长整合新知识或快速迭代新用例。RAG 和 FT 并不互相排斥;它们是互补的,一起使用它们可能会产生最佳效果。
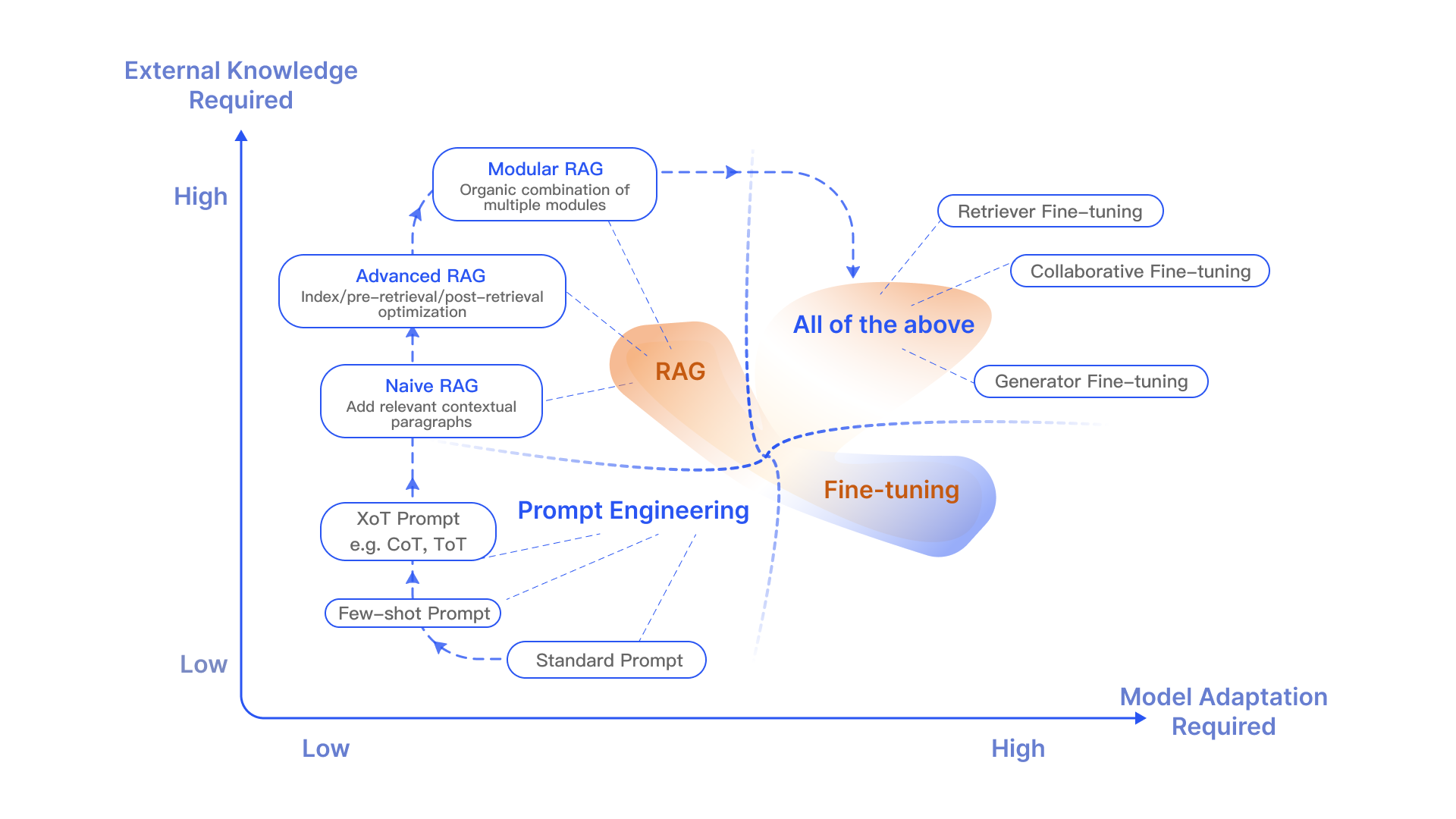
RAG 与微调象限图
5. 如何评估 RAG?
下游任务和数据集:

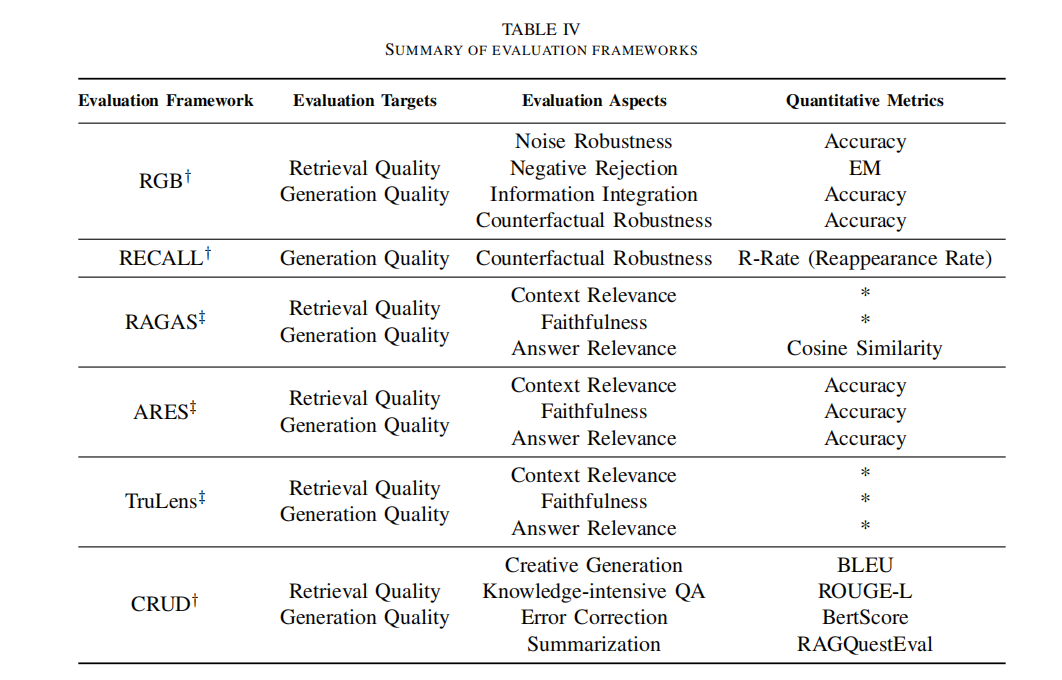
RAG 的评估方法多种多样,主要包括上下文相关性、答案逼真度和答案相关性三个质量分数,以及抗噪性、拒绝能力、信息整合性和反事实鲁棒性四个关键能力。这些评估维度结合了传统的量化指标和针对 RAG 特性的专门评估标准,尽管这些标准尚未标准化。
在评估框架方面,有RGB、RECALL等基准测试,以及RAGAS、ARES、TruLens等自动化评估工具,可以全面衡量RAG模型的性能。

6. 前景
RAG的发展正在蓬勃兴起,有几个问题值得进一步研究。我们可以从三个方面进行展望:
6.1 现有的挑战
旨在进一步应对RAG当前面临的挑战;
- **上下文长度。**检索内容太多,超出窗口限制怎么办?如果LLM的上下文窗口不再受限制,RAG应该如何改进?
- 鲁棒性。如何处理检索到的错误内容?如何过滤和验证检索到的内容?如何增强模型对中毒和噪音的抵抗力?
- 协调与微调。如何同时发挥RAG与FT的作用,如何协调、组织,是串联、交替、还是端到端?
- 缩放定律:RAG 模型是否满足缩放定律?RAG 是否会或在什么情况下 RAG 可能会经历逆缩放定律现象?
- LLM 的作用。LLM 可用于检索(用 LLM 的生成或搜索 LLM 的记忆代替搜索),用于生成,用于评估。如何进一步挖掘 LLM 在 RAG 中的潜力?
- **已投入生产。**如何降低超大规模语料库的检索延迟?如何确保检索到的内容不会被 LLM 泄露
6.2 多模态拓展
如何将 RAG 不断发展的技术和概念扩展到其他数据模态,如图像、音频、视频或代码?一方面,这可以增强单一模态内的任务,另一方面,它可以通过 RAG 的思想融合多模态。
6.3 RAG 的生态系统
RAG的应用不再局限于问答系统,其影响正在拓展到更多的领域,现在,推荐系统、信息抽取、报告生成等各种任务都开始受益于RAG技术的应用。
与此同时,RAG 技术栈也正在迎来爆发式增长,除了Langchain、LlamaIndex等知名工具之外,市场上也出现了更多针对性的 RAG 工具,比如:针对特定用例定制的工具,满足更针对性的场景需求;使用上更加简化的工具,进一步降低使用门槛;以及功能上更加专业化,逐步面向生产环境的工具。
7. Reference:
https://github.com/Tongji-KGLLM/RAG-Survey?tab=readme-ov-file

















 1899
1899

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









