







最通俗易懂理解论文《Real-time Personalization using Embeddings for Search Ranking at Airbnb》 KDD年度最佳论文
题目
在Airbnb使用嵌入进行搜索排名的实时个性化
绪论
介绍了目前上搜索和推荐在各行各业都非常的火热,但考虑到各行各业在排名、个性化和推荐的内容上的巨大差异,目前还没有一个通用的方案来解决所有领域的推荐问题。
而本文提出为airbnb这个全球的订房软件开发的部署列表和用户嵌入技术可以提高99%的推荐效果,并且已经在测试系统中完成测试。
介绍
介绍了最近几年机器学习运用到搜索排名中越来越多,因为机器学习需要大量的数据,而目前的技术可以搜集到大量的数据。
举例每个平台业务的不同带来的搜索算法不同,如有些网站提升算法性能是为了提升网站的点击率,有些网站是为了优化客户的最大转换率,比如购买商品的网站,还有一些网站是为了提升买家和卖家双向的交易体验。示例的行业有住宿(Airbnb),乘车共享(Uber、Lyft)等。
在Airbnb订房中,要优化的目标是用户输入位置和旅行日期后,算法能够提供给客户一个吸引客户的房源。所以本文提出了使用修改版的Lambda Rank模型实现搜索优化
客户在预定前会经过多次的搜索操作,我们在规定时间内给客户一个唯一的会话id(session),来记录用户的操作动作。同时我们也可以使用负面的信号,比如展示一些搜索量比较少的房源,这项举措能够提升Airbub中99%的业务预定量。
除了记录用户的点击操作之外,我们还将用户的所属的类别来嵌入带向量空间列表中。这样就能计算到正在搜索的用户的用户类别和需要排序的候选列表的列表类型嵌入之间的相似性。
本文的贡献
1 实时个性化——以用户最后一次操作来离线计算用户最感兴趣的项目,然后部署到生产系统中,实现实时的推荐。
2 使用一致性的搜索策略——用户通常只会在一个地区进行订房,所以在抽取负样本的时候,减少了负样本的抽取,更好的捕捉她在市场上的相似性。
3 实时变化全局背景——因为用户的搜索会一直进行,所以我们一个会将窗口进行移动,来调整用户的中心,并会考虑上下文对话全局的背景。
4 用户类别的嵌入——因为用户的点击操作可能比较稀疏,所以将用户的类别也作为特征嵌入到训练的过程中。
5 明确否定的拒绝——当客户明显发出拒绝的信号,我们将拒绝类别嵌入到训练的过程中。
本文已经在8亿次的搜索点击训练中进行了各项的嵌入,并且嵌入各项指标之后,点击率显著的提升20%。
为了长期的兴趣个性化,我们使用了5000万用户预定的列表序列来训练用户类别和列表类别。用户的类别和列表列别都嵌入到同一向量空间中进行学习,所以本文也计算了用户列表和列表类别之间的相似性,并且已经被成功的推出了。
相关工作
目前nlp领域的嵌入也非常火热,我们可以将一些内容嵌入到句子之中。如word2vec
方法论
介绍了本文的两种嵌入方式,分别针对短期实时个性话嵌入和用于长期的用户类别和列表类型嵌入。
1 列表嵌入
N个用户会获得一组S个点击会话,然后每个会话都是一个连续的序列,当点击时间间隔操作30s,会重新开启一个会话。
然后通过最大化目标函数在skipgram模型上学习
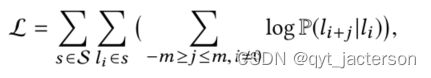
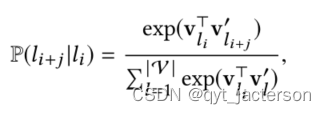
其中vl和v′l是列表l的输入和输出向量表示,超参数m定义为单击列表的相关前向和后向上下文(邻域)的长度,v是定义为数据集中唯一列表id的集合的词汇表。从上面两式我们可以看出,所提出的方法对列表点击序列的时间上下文进行建模,其中具有相似上下文的列表(即,在搜索会话中具有相似的相邻列表)将具有相似的表示。
上面第一条公式计算梯度所需的时间中目标函数的L与词汇表大小|V|成比例,这对于大型词汇表,例如数百万个列出ID,是不可行的任务。作为替代方案,我们使用了中提出的负采样方法,这显著降低了计算复杂性。负抽样可按如下公式表示。我们从整个词汇表V中生成点击列表l及其上下文c的正样本(l,c)的集合Dp(即,同一用户在长度为m的窗口内点击列表l前后对其他列表的点击),以及点击列表和n个随机抽样列表的负样本(l、c)的集Dn
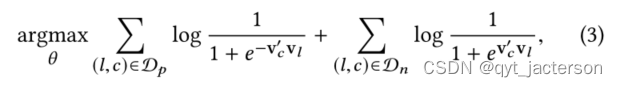
修改的skipgram模型图
其中要学习的参数θ为vl和vc,l,c∈ V、 优化是通过随机梯度上升完成的。
将预定成功的列表作为全局环境
预定的列表是很用的一个参数项,所以加入到目标函数中去
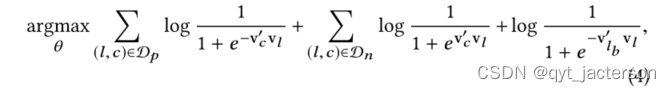
其中v‘lb是预订列表lb的嵌入。对于探索会话,更新仍然通过优化目标(3)进行。
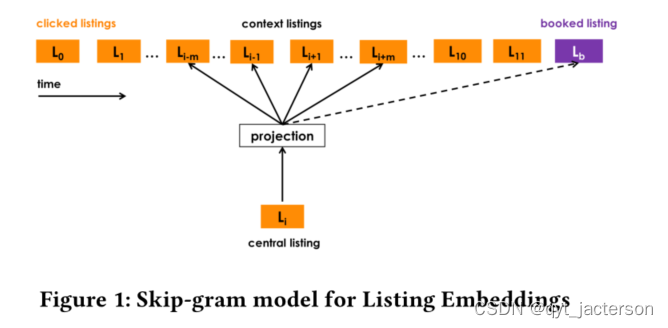
图1显示了如何使用2n+1大小的滑动窗口从预订的会话学习列表嵌入的图形表示,该窗口从第一次单击的列表滑动到预订的列表。在每一步,中心列表vl的嵌入都会被更新,以便它预测来自Dp的上下文列表vc和已预订列表vlb的嵌入。随着窗口滑动,一些列表落在上下文集合内外,而已预订列表始终作为全局上下文(虚线)保留在其中。
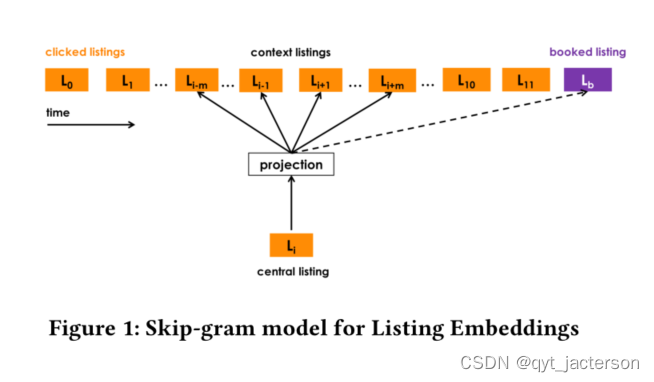
适应一致搜索的训练。在线旅游预订网站的用户通常只在一个市场内搜索,即他们想要停留的地点。因此,Dp很可能包含来自同一市场的上市公司。另一方面,由于负面的随机抽样,Dn很可能包含与Dp中的上市公司不同的大部分上市公司。在每一步中,对于给定的中心上市公司l,正面背景主要由来自与l相同市场的上市公司组成,而负面背景主要由与l不同的上市公司构成。为了解决这个问题,文中建议添加一组随机否定Dmn。
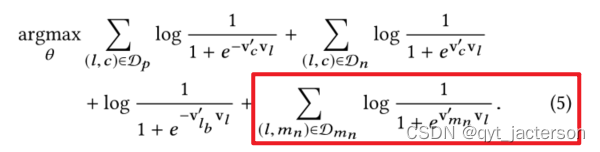
其中要学习的参数θ为vl和vc,l,c∈ V
一些没有点击过的房源进行训练
每天都有新房源由房东创建,并在Airbnb上提供。此时,这些列表没有嵌入,因为它们不存在于点击会话S训练数据中。为了为新列表创建嵌入,我们建议利用其他列表的现有嵌入。
在创建列表时,主机需要提供有关列表的信息,例如位置、价格、列表类型等。我们使用所提供的列表元数据来查找3个地理位置最近的列表(半径10英里内),这些列表具有嵌入,与新列表(例如,私人房间)的列表类型相同,并且与新列表属于相同的价格区间(例如,20美元− $25每晚)。接下来,我们使用识别的列表的3个嵌入来计算平均向量,以形成新的列表嵌入。使用这种技术,我们能够覆盖98%以上的新房源。

检查列表的评估指标
检查列表嵌入。为了评估嵌入捕获了哪些列表特征,我们检查了在8亿次点击会话中使用(5)训练的d=32维嵌入。首先,通过对学习的嵌入执行k均值聚类,我们评估地理相似性是否被编码。图2显示了加利福尼亚州的100个集群,它证实了来自类似位置的列表是聚集在一起的。我们发现集群对于重新评估我们对旅游市场的定义非常有用。接下来,我们评估了不同上市类型的洛杉矶上市公司(表1)和不同价格范围的上市公司(图2)之间的平均余弦相似度。从这些表中可以看出,与不同类型和价格范围的上市公司之间的相似性相比,相同类型和价格区间的上市公司的余弦相似性要高得多。因此,我们可以得出结论,这两个列表特征在学习的嵌入中也得到了很好的编码。
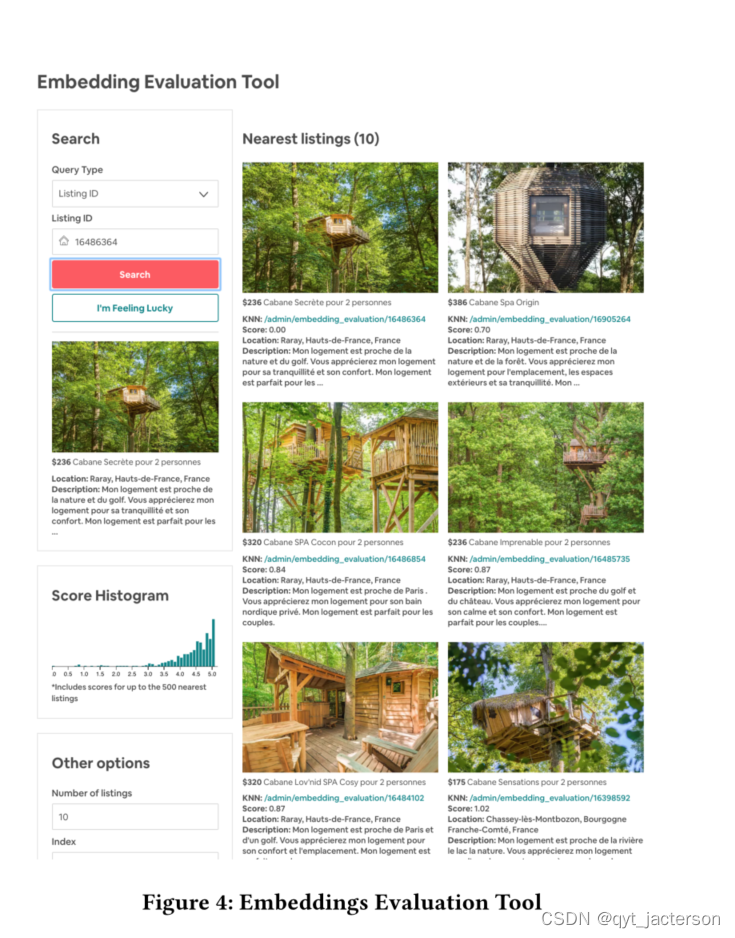
虽然一些上市特征(如价格)不需要学习,因为它们可以从上市元数据中提取,但其他类型的上市特征(例如架构、风格和感觉)则更难以上市特征的形式提取。为了评估这些特征是否被嵌入捕获,我们可以检查列表嵌入空间中唯一架构列表的k近邻。图3显示了一个这样的例子,对于左侧的独特体系结构列表,最相似的列表具有相同的样式和体系结构。为了能够在列表嵌入空间中进行快速而简单的探索,我们开发了一个内部相似性探索工具,如图4所示。
该工具的演示视频,可在线访问https://youtu.be/1kJSAG91TrI,显示了更多嵌入能够找到相同独特建筑的类似列表的例子,包括游艇、树屋、城堡、小木屋、海滨公寓等。
结论
在Airbnb的搜索排名中提出了一种新的实时个性化方法。该方法基于用户点击和预订会话中的上下文共现来学习住宅列表和用户的低维表示。为了更好地利用可用的搜索上下文,我们将全局上下文和显式否定信号等概念纳入训练过程。我们在“相似列表推荐和搜索排名”中评估了所提出的方法。在对实时搜索流量进行成功测试后,两个嵌入应用程序都部署到了生产环境中。(总结效果非常好)















 632
632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









