







目录
一、前言
学习Transformer之前我们先看一下作者论文中的模型,如下图所示:

本章内容主要是自己学习笔记,在学习过程中总结和整理,希望对各位有所帮助。
本章学习从基础模型 Transformer 拆解,分析整个 Transformer 架构用到哪些模块,再把整个 Transformer 拼接起来。同时,图中的位置编码、矩形 和 Nx又是什么?这些模块又如何搭建起来呢?当真的有一个任务,又如何使用和完成的?例如在翻译任务中 Transformer 是如何完成的?
了解清楚 Transsformer 整个架构以后,就可以对照着实现代码了,即Transsformer架构是如何进行实现构建的。在学习Transformer 时候, Transformer 的最基础内容是注意力机制。
那么注意力机制是什么呢?注意力在模型使用过程(构建过程)中是如何起作用的?
Transformer 中出现的几种注意力:交叉注意(CrossAttation)、自注意力、多头自注意力、掩码注意力等。
二、Transformer 注意力
1. 注意力
对于人类我们的眼睛鼻子耳朵等获取周围的很多信息,对围事物的分配关注度(关注的多少)都是不同的,例如我们在逛夜市时候会接收很多东西,但分配的关注度不同,感兴趣的关注度会高一点,不感兴趣的关注度会低一点。
对于模型是同样的道理,开始接收很多信息,但每个信息的关注度是不同的。例如有100个词组成的一句话,我们对这句话中的100个词关注度不同。例如今天我们下班后去吃海鲜,我们关注度高的是'吃'和'海鲜',其他词关注度比较低。模型是同样道理(所以模型就是一个有限的资源,要分配给当前所有输入不同的关注程度)。
下面给出一幅图和一个图表数据,先简单看一下。后面有解释说明。

图1

图2
结合图2看图1,观察图1第一时间识别出的物体,就是关注度比较高的。假如我们在图中看到的内容从关注度高低来说分别是:人、太阳、石头、天空、地平线,给关注度打分分别是 60 60 20 30 10 。我们给出一个条件,从动物开始观察,此时再次观察图1,会对人、太阳、石头、天空、地平线的关注度分数会发生变化,假如是90 10 5 5 3。
小结:按照给出的条件,回过头来再观察图片,脑海中首次观察的事物关注度分数会发生变化。
问题:在这个过程中注意力是哪些,哪些又参与了运算,怎么计算出来的。
上述描述过程中,根据动物观察就是注意力条件 记为Q(Query),往往给出的条件都是观察这幅图的非常重要因素。
在这个条件Q的基础上进行观察,得到的新注意力的分配结果即新注意力分数,这个新注意力分数我们记为 α(实际上是权重,为方便大家理解,使用整数代替)。
新的注意力分数是依据给出的条件 Q 和 自然情况下对不同事物的关注度情况(如第一次观察分数)得到,而自然情况下对不同事物的关注度情况也是得的新注意力分数的关键,我们记为K。
因此新注意力的分数和条件Q及自然情况分数K有关,可以写成 α=QK。
我们一般观察到的事物如人、太阳、石头、天空、地平线都会用一个词向量表示,一般记为V。
接下来需要将注意力大小即α分配到不同的事物上,即分配到不同的词向量上。那么他们的和 α1*v1 + α2v2 + α3*v3 + α4*v4 + α5*v5 就是我们按照给定条件 Q,对自然情况下观察到的事物 V 在分配的注意力 α 情况下的结果。
2. QKV计算过程
通过上面例子,我们知道了注意力及注意力计算的过程(注意:注意力计算过程不是唯一的,为方便大家理解Transformer的注意力,也为保持和Transformer中注意力计算过程一致,我们就用上面方式作为注意力计算过程),同时也得到四个概念Q、K、V、α。接下来我们对Q、K、V分别解释说明。
Transformer原本就是用来做文本训练使用。我们把上面的人、太阳、石头、天空、地平线当做是一个文本中的一段话经过分词后得到的词语。
2.1V的计算
接下来我们需要将人、太阳、石头、天空、地平线这几个词通过独热编码或者Word2vec的转换为词向量。假如人、太阳、石头、天空、地平线的词向量分别是:
| 人 | x1= [0.3,0.8,0.5,0.3,0.4] |
| 太阳 | x2= [0.2,0.7,0.7,0.2,0.6] |
| 石头 | x3= [0.4,0.7,0.6,0.4,0.5] |
| 天空 | x4= [0.5,0.8,0.6,0.3,0.3] |
| 地平线 | x5= [0.3,0.7,0.5,0.2,0.4] |
此时给出一个全连接层,假设全连接层是10个值【3,2,2,1,3,5,6,4,9,3】,使用卷积神经网络,将词向量 x1= [0.3,0.8,0.5,0.3,0.4] 作为一个输入,那么有五个神经元,五个神经元经过隐层后与【3,2,2,1,3,5,6,4,9,3】中的每个数分别计算一次,每次得到一个结果,最总得到10个结果假设是 [6,4,5,3,2,1,3,5,3,2],这个值就是v1。用同样的方式,我们可以计算得到 v2、v3、v4、v5。

2.2 K的计算
再给出一个新的全连接层,假设全连接层是10个值【5,3,2,2,4,1,3,4,6,7】,使用卷积神经网络,将词向量 x1= [0.3,0.8,0.5,0.3,0.4] 作为一个输入,那么有五个神经元,五个神经元经过隐层后与【5,3,2,2,4,1,3,4,6,7】中的每个数分别计算一次,每次得到一个结果,最总得到10个结果假设是 [2,1,3,5,4,5,3,3,2,4],这个值就是k1。用同样的方式,我们可以计算得到 k2、k3、k4、k5。
同样我们假设给出注意力观察的条件是‘动物’这个词,经过独热编码或者Word2vec的转换为词向量假设是:
| 动物 | d= [0.5,0.7,0.4,0.6,0.3] |
2.3 Q的计算
注意力条件Q ,给出一个新的全连接层,假设全连接层是10个值【2,4,1,3,6,7,5,3,2,4】,使用卷积神经网络,将词向量 d= [0.5,0.7,0.4,0.6,0.3] 作为一个输入,那么有五个神经元,五个神经元经过隐层后与【2,4,1,3,6,7,5,3,2,4】中的每个数分别计算一次,每次得到一个结果,最总得到10个结果假设是 [6,5,3,5,2,4,5,3,6,1],这个值就是k1 即注意力条件Q。
3. 注意力计算
注意:在实际计算过程中,qkv和α都是小数,此处我们都用整数表示,是为了方便大家理解。
根据前面的公式 α=QK,我们可以计算出 α,假设
Q=[6,5,3,5,2,4,5,3,6,1],
k=[
[2,1,3,5,4,4,3,4,2,1]
[1,1,2,3,6,1,2,5,3,1]
[1,3,5,3,2,5,2,7,5,4]
[3,2,3,4,5,2,1,3,7,3]
[5,1,4,5,4,1,3,7,1,6]
]
则 α=QK =[165 92 140 102 132]
此时需要分配给v1、v2、v3、v4、v5的注意力权重分别是165 92 140 102 132。
三、Transformer 模块分解
为方便大家理解Transformer模型,我们按照序号 1、2、4、5、6、7、8、9的顺序进行讲解。

1. 交叉注意力
序号1:表示的是交叉注意力机制。即kv和q来自不同的地方。其中kv就是左侧根据人、太阳、石头、天空、地平线的词向量经过转换一次过来的,q 是由右侧根据条件'动物'词向量经过转换得来。因此kv和q分别是从左右侧得到,这种方式就是交叉注意力。需要注意的是这里的注意力条件q是可以不断变换的,如条件可以是动物、天气等,不同的条件q不同。
2. 自意力
序号2:表示的是自注意力,即就是qkv来自于同一个地方。qkv都是由人、太阳、石头、天空、地平线的词向量经过转换而来。
3. 多头自注意力
序号3:在原论文中,每个q、k、v长度都是512,q、k、v都分成8份,每份长度64, 此时有了8组qkv,每组qkv再进行计算,此时就是相当于有了8个头,这种方式就是多头自注意力。
4. 输入编码与位置编码
序号4和序号5:表示的是文本对应的词向量编码和位置编码。例如文本“我们今天下班吃海鲜”,经过分词后得到“我们”、“今天”、“下班”、“吃”、“海鲜”,这些分词的位置信息分别记作 1、2、3、4、5 ,将得到后的分词和位置信息,分别使用独热编码或者Word2vec的转换为词向量和位置信息向量。将位置编码加入到词向量中做为输入的X,再用X分别生成qkv进行下一步计算。
5. Add与正则化
序号6:表示Resnet思想,即至少比上次差。在深度的网络学习中,参数求导需要梯度下降,为了抵消掉深度网络中梯度消失和梯度爆炸,引入的了Resnet思想,即至少比上次差。使用Add是将原来的输入即X + 经过多头注意力计算后的结果![]() 。
。
序号7:表示正则化。在深度的网络学习中数据可能会越学越大,太大了容易跑偏,容易出现梯度爆炸,因此需要进行纠偏一下,纠正到一个指定的范围内,一般是【0,1】区间。
6. 前馈神经网络
序号8:表示的就是前馈神经网络,就是全连接。
7. 层数
序号6:表示虚线内的模块有N层,即执行N次类似的计算过程。
8. 掩码注意力
在深度学习中,我们可能需要处理不同长度的句子。然而,由于神经网络中的矩阵操作需要固定大小的输入,因此我们需要将句子变成相同的长度,所以需要通过添加填充数据来使所有句子的长度相同。但是,我们并不希望模型对填充的数据进行建模,因为这可能会导致错误的结果。
为了解决这个问题,我们可以使用注意力掩码机制。具体来说,我们可以找到一个与QKᵀ矩阵具有相同维度的掩码M,并在要掩码的列(即填充令牌的列)上使用-∞。这样,当我们将M添加到QKᵀ矩阵时,该列的所有值都将变为-∞。然后,当我们对结果矩阵应用softmax函数时,填充令牌列的所有值都将变为0,从而不会影响权重矩阵中其他值的权重。
举个例子:这里只是为了方便大家理解,实际上会更复杂。
例如要预测一个句子的回答,如:“今天天气如何”。模型假如回答是:It will rain in the afternoon。那么这个回答是如何生成的呢?假设模型要生成一句长度为6的句子,那么它先创建一个6*6的矩阵,默认值都是-inf即-∞,表示不可见。这个矩阵就是掩码M,如下:
[
[ -inf, -inf, -inf, -inf, -inf ]
[ -inf, -inf, -inf, -inf, -inf ]
[ -inf, -inf, -inf, -inf, -inf ]
[ -inf, -inf, -inf, -inf, -inf ]
[ -inf, -inf, -inf, -inf, -inf ]
[ -inf, -inf, -inf, -inf, -inf ]
]
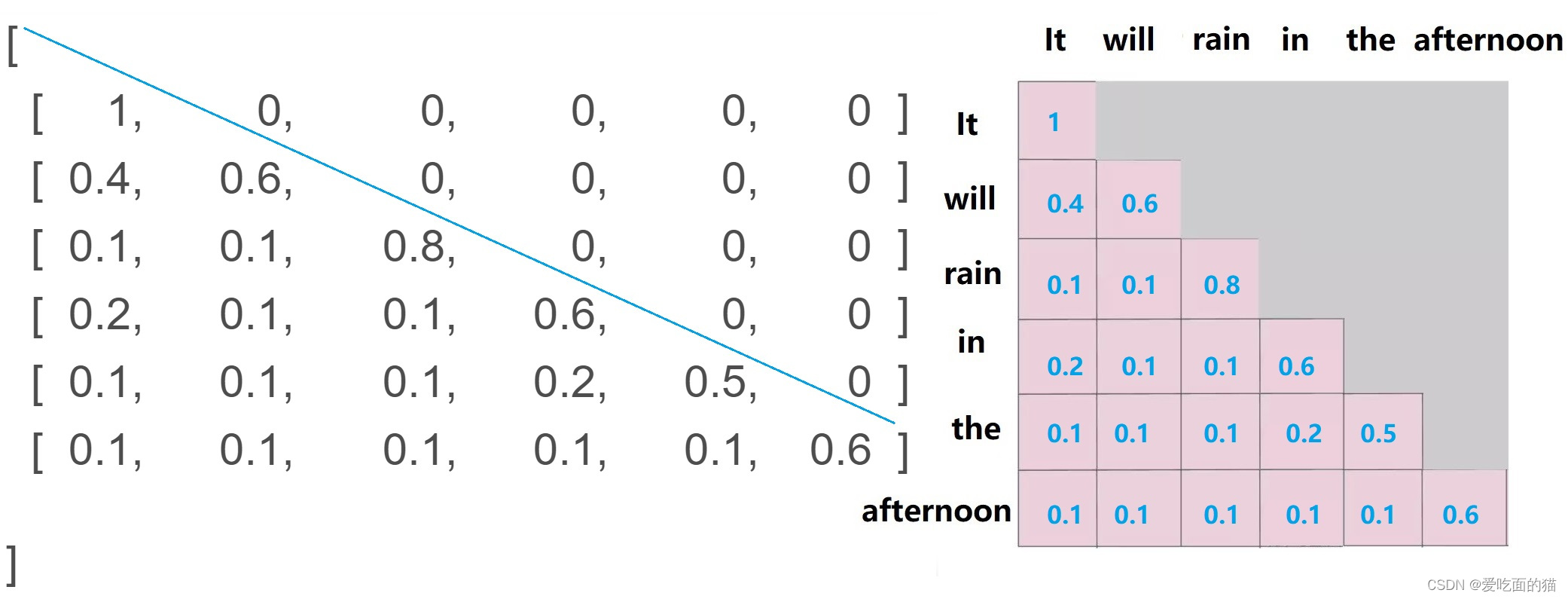
模型首先根据前文的语境,给预测出一个单词 It,但需要给出的长度是6,此时只有一个单词,因此 第一个单词“It”和自身attention,其他的5个位置没有内容,使用-inf掩盖。将之前的语境和It作为输入,预测出下一个单词是will,will会和It进行attention,同时也会和自己attention。依次类推,直到预测出 afternoon,它会和前面所有的单词进行attention再和自己attention。如下图所示:

最终经过 softmax 之后,横轴结果合为 1。负无穷结果为0。如下图所示;
9.总结
通过前面讲解,将上图左侧称作是编码器,右侧是解码器。
编码器作用是:将输入的句子进行分词后进行词嵌入,同时将每个词的位置信息编码加入,进行自注意力分配,生成Q、K、V,再通过多头注意力机制得到新的结果,将新的结果和原有的结果相加再进行归一化,通过全连接生成新的结果,生成的新的结果和前面归一化后的结果再次相加进行归一化。这个结果作为下次输入的数据。这个过程执行N次,即图中菜单N+。将执行N次的结果最终生成K和V传给右侧的界面器使用。
编码器作用是:根据条件(一般是上下文语境)生成词向量加入位置编码,进行自注意力分配,生成Q、K、V,再通过多头注意力机制得到新的结果,将新的结果和原有的结果相加再进行归一化,归一化的结果做Q,和左侧的K、V作为输入,再通过多头注意力机制得到新的结果,将新的结果和原有的结果相加再进行归一化,通过全连接生成新的结果,生成的新的结果和前面归一化后的结果再次相加进行归一化。将得到的结果通过线性和softmax生成预测内容。将语境和预测内容再次作为输入的条件循环执行上面步骤。
四、编码实现

1、实现思路
定义 注意力类 SelfAttention(紫色部分:注意力、多头注意力、掩码注意力)
定义 TransformerBlock(暗红色框:SelfAttention+求和+归一化+全连接)
定义Encoder(橙色框:TransformerBlock叠加N次 + 输入+位置编码)
定义DecoderBlock(黄色框:TransformerBlock+多头注意力机制+求和+归一化+全连接)
定义Decoder(红色框)
定义Transformer(由Encoder和Decoder组成)
2、编码实现
import torch
from torch import nn
'''
就是找到 QKV ,让Q和K相乘得到的结果再和V相乘。
'''
# 定义一个名为SelfAttention的类,继承自torch.nn.Module,这是PyTorch中定义神经网络模块的基类
class SelfAttention(torch.nn.Module):
def __init__(self, embed_size, heads):
# 调用父类(torch.nn.Module)的初始化方法
super(SelfAttention, self).__init__()
# 嵌入大小(即输入特征的维度)
self.embed_size = embed_size
# 注意力头的数量
self.heads = heads
# 每个头的嵌入大小,通过嵌入大小除以头数计算得到
self.head_dim = embed_size // heads
# 确保嵌入大小可以被头数整除
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
# 定义三个线性层,分别用于处理值(values)、键(keys)和查询(queries),每个线性层都将输入映射到与头大小相同的维度
self.values = torch.nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = torch.nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = torch.nn.Linear(self.head_dim, self.head_dim, bias=False)
# 一个线性层,用于将多头注意力的输出映射回原始的嵌入大小
self.fc_out = torch.nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask):
# 获取查询的批次大小
N = query.shape[0]
# 获QKV的长度
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
# 将嵌入(QKV)按照头数进行拆分
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
query = query.reshape(N, query_len, self.heads, self.head_dim)
# 对拆分后的QKV进行线性变换
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(query)
# 使用torch.einsum计算QK的点积(即能量值),这里使用了爱因斯坦求和约定
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
# 如果提供了mask,则将mask中值为0的位置对应的能量值替换为一个非常小的数(接近于负无穷),这样在softmax后这些位置的值会接近于0
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
# 对能量值应用softmax函数,得到注意力权重,并除以嵌入大小的平方根进行缩放(这是Transformer中的一个常见技巧,用于防止梯度消失或爆炸)
attention = torch.softmax(energy / (self.embed_size ** (1 / 2)), dim=3)
# 使用torch.einsum和注意力权重计算加权和,得到输出的嵌入
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(N, query_len, self.heads * self.head_dim)
# 将多头注意力的输出映射回原始的嵌入大小
out = self.fc_out(out)
# 返回输出嵌入
return out
# 定义一个名为TransformerBlock的类,继承自PyTorch的nn.Module,用于构建Transformer模型的一个基本块
class TransformerBlock(nn.Module):
# 初始化函数,设置TransformerBlock所需的各种参数和层
def __init__(self, embed_size, heads, dropout, forward_expansion):
# 调用父类(nn.Module)的初始化方法
super(TransformerBlock, self).__init__()
# 创建一个SelfAttention对象,用于实现多头自注意力机制
self.attention = SelfAttention(embed_size, heads)
# 创建第一个LayerNorm层,用于对注意力层的输出进行归一化
self.norm1 = nn.LayerNorm(embed_size)
# 创建第二个LayerNorm层,用于对前馈神经网络层的输出进行归一化
self.norm2 = nn.LayerNorm(embed_size)
# 创建一个前馈神经网络,包括一个线性层、ReLU激活函数和一个线性层
# 前馈神经网络用于对注意力层的输出进行进一步的转换
self.feed_forward = nn.Sequential(
# 第一个线性层,将嵌入大小扩展到forward_expansion倍
nn.Linear(embed_size, forward_expansion * embed_size),
# ReLU激活函数
nn.ReLU(),
# 第二个线性层,将扩展后的嵌入大小缩回到原始的嵌入大小
nn.Linear(forward_expansion * embed_size, embed_size)
)
# 创建一个Dropout层,用于在训练过程中随机将部分神经元的输出置零,以防止过拟合
self.dropout = nn.Dropout(dropout)
# 前向传播函数,定义了数据通过该模块时的计算流程
def forward(self, value, key, query, mask):
# 通过SelfAttention层计算注意力权重并生成加权和
attention = self.attention(value, key, query, mask)
# 对注意力层的输出进行归一化,并添加残差连接(原始查询与归一化后的输出相加)
# 然后应用dropout层以防止过拟合
x = self.dropout(self.norm1(attention + query))
# 将归一化并添加了残差连接的输出传递给前馈神经网络
forward = self.feed_forward(x)
# 对前馈神经网络的输出进行归一化,并再次添加残差连接(x与归一化后的输出相加)
# 然后应用dropout层以防止过拟合
out = self.dropout(self.norm2(forward + x))
# 返回最终的输出
return out
# 定义一个名为Encoder的类,继承自PyTorch的nn.Module,用于构建Transformer编码器
class Encoder(nn.Module):
# 初始化函数,设置Encoder所需的参数和层
def __init__(self,
src_vocab_size, # 源语言词汇表大小
embed_size, # 嵌入向量的维度
num_layers, # Transformer层的数量
heads, # 多头注意力机制中头的数量
device, # 设备,用于指定模型是在CPU还是GPU上运行
forward_expansion, # 前馈神经网络中第一个线性层的扩展倍数
dropout, # Dropout的概率
max_length # 输入序列的最大长度
):
super(Encoder, self).__init__() # 调用父类(nn.Module)的初始化方法
# 存储嵌入向量的维度
self.embed_size = embed_size
# 存储运行模型的设备(CPU或GPU)
self.device = device
# 创建一个词嵌入层,将输入的单词索引转换为嵌入向量
self.word_embedding = nn.Embedding(src_vocab_size, embed_size)
# 创建一个位置嵌入层,用于给序列中的每个位置一个独特的嵌入向量
self.position_embedding = nn.Embedding(max_length, embed_size)
# 创建一个TransformerBlock的列表,表示编码器中的多个Transformer层
self.layers = nn.ModuleList(
[
# 创建一个TransformerBlock实例,并添加到列表中
TransformerBlock(
embed_size,
heads,
dropout=dropout,
forward_expansion=forward_expansion
)
# 循环创建num_layers个TransformerBlock实例
for _ in range(num_layers)
]
)
# 创建一个Dropout层,用于在训练过程中随机将部分神经元的输出置零
self.dropout = nn.Dropout(dropout)
# 前向传播函数,定义了数据通过编码器时的计算流程
def forward(self, x, mask):
# 获取输入序列的批量大小和长度
N, seq_length = x.shape
# 创建一个从0到seq_length-1的tensor,表示序列中每个位置的位置索引
# 并通过expand操作将其扩展为与输入x形状相同的tensor
positions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)
# 将词嵌入和位置嵌入相加,得到融合了位置信息的嵌入向量
# 并应用dropout层以防止过拟合
out = self.dropout(self.word_embedding(x) + self.position_embedding(positions))
# 遍历Transformer层列表,将上一层的输出作为下一层的输入
# 并传入相同的value、key、query和mask
for layer in self.layers:
out = layer(out, out, out, mask)
# 返回编码器的最终输出
return out
# 定义一个名为DecoderBlock的类,继承自PyTorch的nn.Module,用于构建Transformer解码器的一个块
class DecoderBlock(nn.Module):
# 初始化函数,设置DecoderBlock所需的参数和层
def __init__(self, embed_size, heads, forward_expansion, dropout, device):
super(DecoderBlock, self).__init__() # 调用父类(nn.Module)的初始化方法
# 创建一个自注意力层,用于解码器中的自注意力机制
self.attention = SelfAttention(embed_size, heads) # 这里假设SelfAttention是另一个定义好的类
# 创建一个层归一化层,用于对注意力输出和原始输入进行归一化
self.norm = nn.LayerNorm(embed_size)
# 创建一个TransformerBlock实例,用于处理编码器的输出和解码器的自注意力输出
self.transformer_block = TransformerBlock(embed_size, heads, dropout, forward_expansion)
# 创建一个Dropout层,用于在训练过程中随机将部分神经元的输出置零
self.dropout = nn.Dropout(dropout)
# 前向传播函数,定义了数据通过DecoderBlock时的计算流程
def forward(self, x, value, key, src_mask, trg_mask):
# 计算自注意力,其中x是解码器当前位置的查询向量
attention = self.attention(x, x, x, trg_mask) # trg_mask是目标序列的掩码
# 将自注意力的输出与原始输入x相加,并应用层归一化和dropout
query = self.dropout(self.norm(attention + x)) # query是结合了自注意力信息的解码器当前位置的向量
# 使用TransformerBlock处理编码器的输出(value, key)和解码器的自注意力输出(query)
# 其中src_mask是源序列的掩码
out = self.transformer_block(value, key, query, src_mask)
# 返回TransformerBlock的输出
return out
# 定义一个名为Decoder的类,继承自PyTorch的nn.Module,表示Transformer解码器
class Decoder(nn.Module):
# 初始化函数,设置Decoder所需的参数和层
def __init__(self,
trg_vocab_size, # 目标词汇表大小
embed_size, # 嵌入层的大小
num_layers, # 解码器层数
heads, # 多头注意力中的头数
forward_expansion, # 前馈神经网络中的扩展因子
dropout, # dropout比例
device, # 设备(CPU或GPU)
max_length): # 输入序列的最大长度(用于位置嵌入)
super(Decoder, self).__init__() # 调用父类(nn.Module)的初始化方法
self.device = device # 存储设备信息
# 定义单词嵌入层,将单词索引映射为嵌入向量
self.word_embedding = nn.Embedding(trg_vocab_size, embed_size)
# 定义位置嵌入层,用于为序列中的每个位置提供唯一的嵌入向量
self.position_embedding = nn.Embedding(max_length, embed_size)
# 使用nn.ModuleList创建一个DecoderBlock的列表,每个DecoderBlock表示解码器的一层
self.layers = nn.ModuleList(
[DecoderBlock(embed_size, heads, forward_expansion, dropout, device)
for _ in range(num_layers)]
)
# 定义全连接层,用于将解码器的输出映射到目标词汇表大小
self.fc_out = nn.Linear(embed_size, trg_vocab_size)
# 创建一个dropout层,用于在训练过程中随机将部分神经元的输出置零
self.dropout = nn.Dropout(dropout)
# 前向传播函数,定义了数据通过Decoder时的计算流程
def forward(self, x, enc_out, src_mask, trg_mask):
# x: 形状为(N, seq_length)的目标序列的单词索引
# enc_out: 编码器的输出
# src_mask: 源序列的掩码
# trg_mask: 目标序列的掩码
N, seq_length = x.shape # 获取批量大小和序列长度
# 创建一个位置张量,形状为(N, seq_length),用于索引位置嵌入
positions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)
# 将单词嵌入和位置嵌入相加,并应用dropout
x = self.dropout((self.word_embedding(x) + self.position_embedding(positions)))
# 遍历解码器的每一层,将输入x、编码器的输出enc_out以及掩码传入
for layer in self.layers:
x = layer(x, enc_out, enc_out, src_mask, trg_mask)
# 将解码器的最终输出通过全连接层映射到目标词汇表大小
out = self.fc_out(x)
# 返回输出
return out
# 定义一个名为Transformer的类,继承自PyTorch的nn.Module,表示一个完整的Transformer模型
class Transformer(nn.Module):
def __init__(self,
src_vocab_size, # 源语言词汇表大小
trg_vocab_size, # 目标语言词汇表大小
src_pad_idx, # 源语言填充索引
trg_pad_idx, # 目标语言填充索引
embed_size=256, # 嵌入层的大小,默认为256
num_layers=6, # 编码器和解码器的层数,默认为6
forward_expansion=4, # 前馈神经网络中的扩展因子,默认为4
heads=8, # 多头注意力中的头数,默认为8
dropout=0, # dropout比例,默认为0
device="cuda", # 设备(CPU或GPU),默认为"cuda"
max_length=100 # 输入序列的最大长度,默认为100
):
super(Transformer, self).__init__() # 调用父类(nn.Module)的初始化方法
# 初始化编码器部分
self.encoder = Encoder(
src_vocab_size, # 源语言词汇表大小
embed_size, # 嵌入层大小
num_layers, # 编码器层数
heads, # 多头注意力头数
device, # 设备
forward_expansion, # 前馈神经网络扩展因子
dropout, # dropout比例
max_length # 最大长度
)
# 初始化解码器部分
self.decoder = Decoder(
trg_vocab_size, # 目标语言词汇表大小
embed_size, # 嵌入层大小
num_layers, # 解码器层数
heads, # 多头注意力头数
forward_expansion, # 前馈神经网络扩展因子
dropout, # dropout比例
device, # 设备
max_length # 最大长度
)
# 存储源语言和目标语言的填充索引
self.src_pad_idx = src_pad_idx
self.trg_pad_idx = trg_pad_idx
# 存储设备信息
self.device = device
# 创建一个源序列的掩码,用于忽略填充的token
def make_src_mask(self, src):
src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2)
# (N, 1, 1, src_len) 创建一个布尔掩码,用于指示非填充token的位置
return src_mask.to(self.device) # 将掩码移动到指定的设备上
# 创建一个目标序列的掩码,用于自回归解码(即预测下一个token时只能看到之前的token)
def make_trg_mask(self, trg):
N, trg_len = trg.shape # 获取批量大小和目标序列长度
trg_mask = torch.tril(torch.ones((trg_len, trg_len))).expand(
N, 1, trg_len, trg_len
)
# 创建一个下三角矩阵,然后将其扩展到(N, 1, trg_len, trg_len)的形状
return trg_mask.to(self.device) # 将掩码移动到指定的设备上
# 前向传播函数,定义了数据通过Transformer时的计算流程
def forward(self, src, trg):
# 创建源序列的掩码
src_mask = self.make_src_mask(src)
# 创建目标序列的掩码
trg_mask = self.make_trg_mask(trg)
# 通过编码器得到源序列的编码表示
enc_src = self.encoder(src, src_mask)
# 将目标序列、源序列的编码表示、源序列掩码和目标序列掩码传入解码器
out = self.decoder(trg, enc_src, src_mask, trg_mask)
# 返回解码器的输出
return out
未完 待续(工作空闲继续)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









