






Boosting的思想
每一步都产生一个弱分类器,并且加权累计形成总的模型。如果每一步产生的弱分类器是依据梯度的,那么就称之为梯度提升(GBDT)

首先基于M个样本训练一个弱学习器,根据这个弱学习器对M个样本做修改,然后训练得到一个弱学习器2,依次下去,把各个弱学习器做一个权重的融合。融合的是各个模型结果的融合不是参数的融合
Adaboost
Adaboost是一种迭代算法,每一次在数据集上迭代迭代会产生一个弱学习器,然后对样本进行预测,根据对样本的准确性来确定样本的权重,预测的越错误的权重越大,预测对的降低权重。直至错误率足够低或者到达一定迭代次数。
Adaboost将弱分类器线性组合为强分类器。同时给分类误差较大的基分类器较小的权重,给分类误差小的较大权重
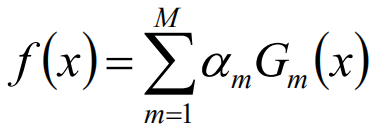
回归
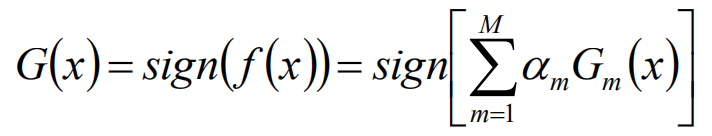

分类
sign函数得作用就是,当是小于0的时候认为是-1,大于0的时候认为是1.
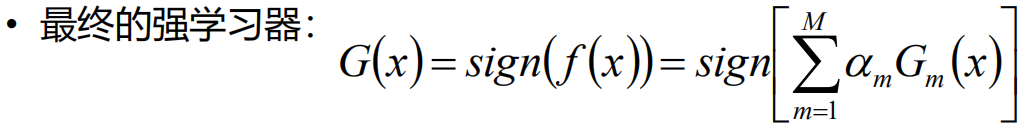

I函数表示内部为True的时候返回1,为False返回0。G(xi)代表预测值,当预测值和实际值不符的时候就返回1,相等就返回0。然后遍历每个样本,得到的结果再做一个累加,这样得到的就是错误的个数,除以样本数就是错误率。所以说损失函数是以错误率为标准的。
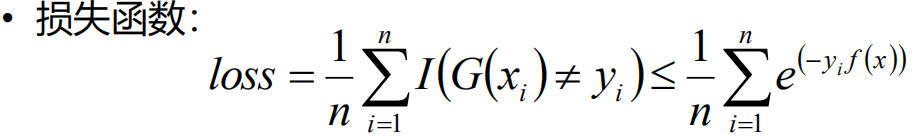

这里要把损失函数上限求出来的原因就是原先的是一个阶梯状的不可导,转化后的是可导的
Adaboost算法构建过程
 2 我们训练的是样本权重也就是w,第一轮初始化的样本权重都是1/n,
2 我们训练的是样本权重也就是w,第一轮初始化的样本权重都是1/n,
3 训练得到基分类器,在G函数中得到1 -1的预测
4 在这里假设使用的决策树做的基模型。在3中已经训练完了,我们可以对模型计算一个误差率。在第4步中,用每个错误的样本乘以它的权重,然后累加的到这轮模型中的总误差。这里注意误差要小于0.5,即使是弱分类器也要大于我们的随机猜想。
5 根据误差来计算本轮的模型权重。把括号中分解为1/e-1(这里用e代替图中字母)。当e小于等于1/2的时候,1/e大于等于2,再减一也就是大于等于1。也就是我们的模型权重保证是大于0的了,并且e越小我们的1/e就越大,模型的权重也就越大。
在第一轮中主要是讲解了模型的权重如何通过错误率来计算出来,以及错误率如何计算出来,还有样本的权重没有说明如何计算。我们来看第二轮。
·这是第二轮构建过程


6 Wm,i 就是上一轮的样本权重, yGm(xi)有两种情况,当预测对的时候是1,预测错的时候为-1,然后只讨论预测错的情况,就是这里等于-1,6中就可以简写成e^α
(在第一轮的时候已经证码这个α一定是正数),根据图像可以看出来e^α一定是大于1的,反之时小于1的。这样就对样本做了一个权重的分配。
7 这里的Z只是做一个加权处理
8 然后再训练本轮的学习器
9 合并为总的分类似
Adaboost(接着上一个Adaboost看)
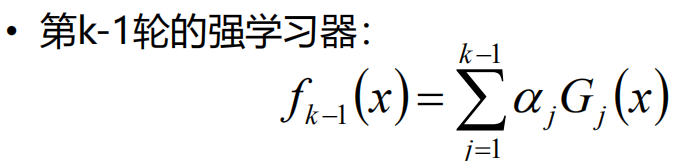
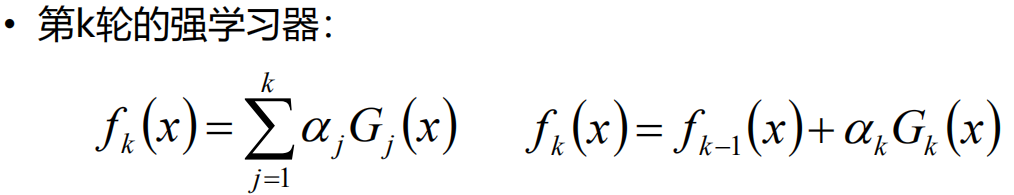
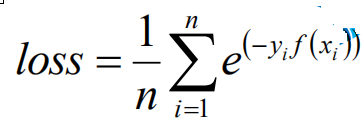
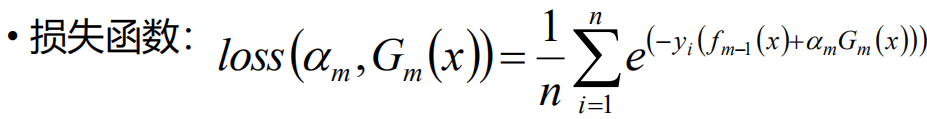
我们把第k轮的学习器带入Loss损失函数中,就可以得到第四个图中的损失函数。但是在这个时候我们的前面m-1轮的f(x)都已经计算出来了就是一个常数,所以就是对αGm(x) 求一个最小值,这样就把求全局的最有函数变成了求当前一步的最优函数。


这里就是做一个简单的化简。但是e^-yf(x)是固定值,给它做上图处理。

在当前这一轮中可能优很多划分的方式,选择让Gm最小的也就是误差率最小的。

这里后面再写。
Adaboost对异常数据比较敏感可能会获得较高的权重影响模型效果















 320
320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









