






集成学习思想

我们如论如何调参数(网格交叉验证)也不能得到满意的模型,可能是模型本身的限制,这时候我们可以用集成学习的思想来做。注意多个学习器组合的时候要选用同一类,比如同是分类器并且一般是弱学习器
集成思想的关键在于保留了每个学习器的特性。集成不稳定的算法也会有较大提升。比如说树结构中如果构造的过深会造成过拟合,把一些异常点也学进去,但是在集成学习中每个学习器是用总样本的部分样本(对样本进行抽样)可以抗噪
常见的集成学习思想:
Bagging
Boosting
Stacking
弱分类器之间存在差异,导致其中可能会有错误的。但是多个弱分类器融合和会得到更合理的分类边界。(在分类中是否也会对分类概率进行抵消还是进行多数表决后面理解再补充)
当数据集过大的时候我们可以对数据集做一个划分,可以重叠的划分
数据集过小的时候可以进行有放回的抽样,来训练多个学习器提高准确率。
当数据划分边界是类似于圆的,线性很难拟合。集成学习可以将多个线性进行融合,从而去拟合分割边界。
对于多个异构数据,我们可以训练多个模型进行融合。(比如来自不同数据源又不能合并为一个数据集的数据)
Bagging的思想
在原始的数据集上进行有放回的抽样(抽到的数据是允许重复的),并且抽出来的样本数和原始样本数是一样多的。在模型训练的时候将重复数据去除(这时候和原始数据是不一样多的)。这里注意,因为是有放回的抽样,所以一定会有数据抽不到((n-1/n)^n大约是33%)
子学习器在预测的时候会进行多数投票(多数投票选择不出来的时候可以进行加权的多数投票就比如KNN中的加权,这里的权重系数就是子学习器的分数)或者求均值
Bagging中一个特殊的算法就是随机森林,用的就是决策树

Bagging中封装好的算法——随机森林 Random Forest
随机森林中除了对样本进行随机取样,对特征也是随机选取(可以防止过拟合,比如决策树中选择所有特征,有多个异常样本的同一个特征有异常取值,且属于一个分类,这样最优划分有可能就会根据这个特征把异常样本划分到一起)。从随机选择的特征中找到最优的划分特征构建树(全部特征选取的是全局最优,随机特征是选择局部最优,单个学习器的效果会下降,但是效果会高于0.5,也就是保证是一个弱学习器。然后多个集合效果就会好起来)。然后重复前面的步骤得到m颗树。然后通过决策树来投票选择出属于哪一类,投票的时候会考虑到权重系数也就是决策树的分数
随机森林的变种
Extra Tree:子模型不是决策树的随机森林
Extra Tree每个子决策树中采用原始的数据进行训练,随机森林是抽样的。随机森林中子模型考虑的特征不一样,之间的联系就不大。如果使用相同的数据训练子模型得到的就是相同的模型,所以Extra Tree在选择特征就不会基于基尼或者信息增益来选择而是随机,这样子模型也相当于从不同特征来考虑样本集的划分。所以个人觉得效果不太好,除非随机森林局部最优都过拟合再尝试Extra Tree。
Totally Random Trees Embedding(TRTE):合并多个多个随机树,非监督数据转化方式。
TRTE主要要用升维度将样本从低纬度映射到高纬度。提升到高维之后,这样比较有利于算法去将数据边界切开(可以联想后面深度学习的线性分割锥面的例子)
他的构建过程类似于RF构建T个决策树来拟合数据,像KD-Tree一样使用方差来选择特征划分,但是中间的随机过程还是保留的。所以这T颗决策树还是不同的,样本和特征都不同。当这T颗树构建完成,每个样本所在的叶子节点也就确定下来了,然后转化为向量。
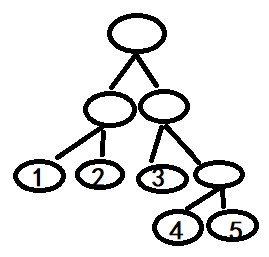
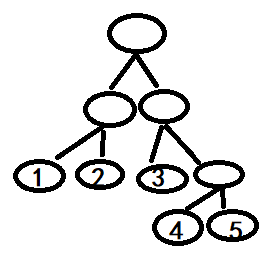
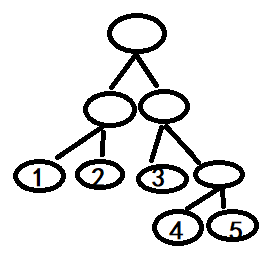
例如当一个样本x 进入模型,在第一棵树,根据特征划分落入3号叶子节点,第二棵树落入1节点,第三颗树落入5节点.这里每棵树的训练样本不同选择的特征不同所以样本进入才会出现落入不同节点。在这三颗树里面,每一个叶子节点就可以认为是一类样本。这样x的特征就转换为0,0,1,0,0,1,0,0,0,0,0,0,0,0,1
Isolation Forest: 异常点检测
本质是一个分类算法,将样本分为异常和正常两类。
在随机采样的过程中只需要很少的数据,选择完数据,根据特征划分的时候会随机选择特征再随机选择阈值进行划分(连续性数据),然后构建一个深度比较小的树。
随机森林的总结
- 各个子模型之间是没有关系的,所以可以并行训练,在大规模数据集上有速度优势
- 随机选择特征进行划分,所以样本维度比较高的时候,效果也比较不错
- 底层是决策树,所以可以给出各个特征的重要程度,可以用于特征选择
- 随机抽样,泛化能力强
- 对于特征确缺失不敏感
属性比较多的特征对决策树有比较大的影响,从而影响随机森林的效果。
代码
随机森林
# 4. 决策树算法模型的构建
"""
# 随机森林中,子模型决策树的数目。默认为10
n_estimators=10,
# 同决策树算法
criterion="gini",
# 同决策树算法
max_depth=None,
# 同决策树算法
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.,
# 同决策树算法
max_features="auto",
max_leaf_nodes=None,
min_impurity_split=1e-7,
# 给定是否采用有放回的方式产生子数据集,默认为True表示采用。
bootstrap=True,
oob_score=False,
n_jobs=1,
random_state=None,
verbose=0,
warm_start=False,
class_weight=None
"""
algo = RandomTreesEmbedding(n_estimators=3, max_depth=3, random_state=28)
print("特征的重要程度:{}".format(len(algo.feature_importances_)))
# 8. 随机森林可视化输出
print("随机森林中的子模型列表:{}".format(len(algo.estimators_)))
# 2. 方式二:直接使用pydotplus插件直接生成pdf文件进行保存
from sklearn import tree
import pydotplus
#
# feature_names=None, class_names=None 分别给定特征属性和目标属性的name信息
for i in range(len(algo.estimators_)):
dt = algo.estimators_[i]
dot_data = tree.export_graphviz(decision_tree=dt, out_file=None,
feature_names=['sepal length', 'sepal width', 'petal length', 'petal width'],
class_names=['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'], filled=True)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_png("iris{}.png".format(i))
graph.write_pdf("iris{}.pdf".format(i))
Bagging
# 7. 方式二:使用Boosting的算法
"""
base_estimator=None, # 给定基础的模型对象,也就是子模型
n_estimators=10, # 给定子模型的数目
max_samples=1.0, # 给定子模型训练的时候,使用多少个样本训练,这个是总样本的百分比
max_features=1.0, # 给定子模型训练的时候,使用样本的多少个特征属性来训练,这个是总样本的百分比
bootstrap=True,# 给定子模型训练的时候,每个子训练集的产生样本数据是否基于重采样,默认为True,表示是
bootstrap_features=False,# 给定子模型训练的时候,每个子训练集的产生用于训练的特征属性是否基于重采样,默认为False,表示不是
oob_score=False,
warm_start=False,
n_jobs=1,
random_state=None,
verbose=0
"""
br = BaggingRegressor(base_estimator=LinearRegression(), n_estimators=10, max_samples=0.9, max_features=0.7)
Totally Random Trees Embedding(TRTE)
algo = RandomTreesEmbedding(n_estimators=3, max_depth=3, random_state=28)
# 5. 算法模型的训练
algo.fit(x_train, y_train)
# 6. 直接获取扩展结果
x_train2 = algo.transform(x_train)
x_test2 = algo.transform(x_test)
print("扩展前大小:{}, 扩展后大小:{}".format(x_train.shape, x_train2.shape))
print("扩展前大小:{}, 扩展后大小:{}".format(x_test.shape, x_test2.shape))















 646
646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









