






梯度提升迭代树(GBDT)直观理解
GBDT的底层必须是决策树,不支持其他算法。而且都是回归树,哪怕做分类也是回归树,所以GBDT的回归能力好,Adaboost的分类能力好。GBDT中不像Aeqboost中修改样本权重和模型权重去,而是根据梯度减少误差。

比如我们预测年龄,直接拿到样本的特征输入到第一个模型中,得到的预测可能是20(每个模型前面有惩罚系数不会一上来就预测的很准,防止过拟合),然后计算真实值和预测值的差值来作为实际值输入到下一个模型中,依此往后进行,最后把所有预测值加起来就是结果
BGDT由三部分组成,决策树,梯度,衰减系数
和随机森林比较:
底层都只能是决策树。但是随机森林是抽取m个样本n个特征构建树,树与树之间是没有关系的。而GBDT是用之前子树的残差构建下一颗树,预测的时候也会按照顺序加起来。
GBDT原理
给定输入量x和输出量y,目标是找一个函数使得损失函数最小
损失函数

一般我们使用的都是最小二乘损失函数。
所以我们就是寻找最小的损失函数对应得F(x)

而F(x)是由M个子学习器加权累加得和。这里的V是一个超参数也就是说不是模型训练的是手动给的。注意和Adaboost中α的区别,这里的V是衰减系数。
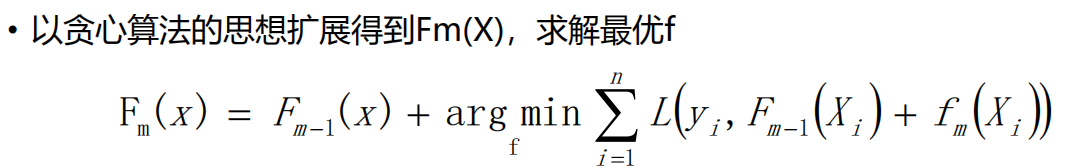
可以理解为,当前一轮得函数等于,前几轮得函数加上 使得输入得y值和(前几轮函数+本轮函数)的差值最小的函数。这样求得的就是m次模型的累加。但是这样求还是不好求
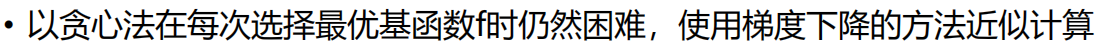
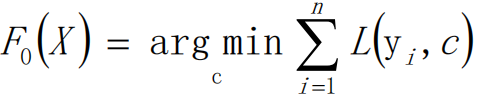
F0 hi第一次迭代,c是均值(比如给定样本的年龄,我们求一下均值来作为预测值),求一个损失函数最小的F0。我们给L函数求导
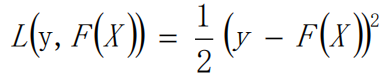
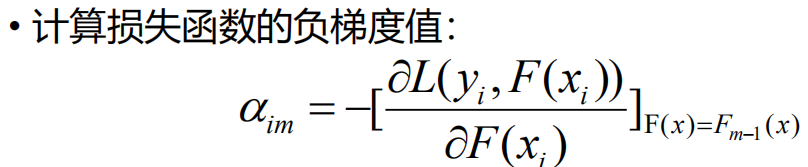
这里求导是对F(x)这个函数来求导,也就是在函数空间求导,如上图。图中我们要从F(x)中找一个f(x)来拟合α,这里的α指的是梯度,前面加了负号也就是残差了。L函数求导的结果就是(f(x)-y),也就是预测值减去实际值也就是我们能前面图中的残差。

计算的残差和x做一个组合,然后用x构建一棵树来拟合残差得到m颗树。
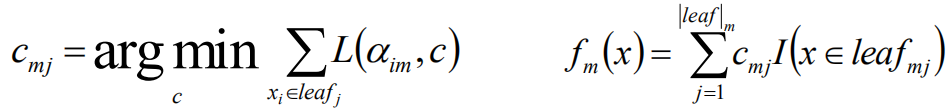
cmj代表的就是第m轮中第j个叶子节点的预测值(平均值),当第j个叶子节点的预测值和实际值相差最小的时候的第j个叶子的预测值
fm(x)表示对m轮的树的所有叶子节点的预测值求和
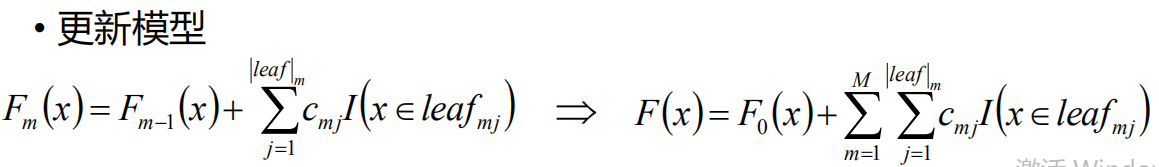
遍历当前树所有叶子节点的预测值的累加和,加之前的树就是模型。对最终模型做个转化就是,遍历所有树的所有的叶子节点加起来(每个样本必定会落到一个叶子节点,所以所有树的所有节点相加就是最终预测结果)
代码
algo = GradientBoostingRegressor()
#
"""
loss='ls', 定义损失函数 默认为最小二乘损失函数
learning_rate=0.1, 模型损失函数 默认是0.1
n_estimators=100, 子模型的数量
subsample=1.0, 模仿随机森林进行子模型样本随机抽样
criterion='friedman_mse', 分类节点时候采取的标准
min_samples_split=2, 构建决策树过程中,分裂节点最少需要的样本数
min_samples_leaf=1, 底层构建决策树过程中叶子最少需要的样本的树
min_weight_fraction_leaf=0., 剪枝参数
max_depth=3, 剪枝参数
min_impurity_decrease=0., 剪枝参数
min_impurity_split=None, 剪枝参数
"""















 762
762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









