







Remembering history with convolutional LSTM for anomaly detection
Abstract
作者利用CNN来编码外观利用ConvLSTM通过记忆过去帧来编码运动信息再结合自编码器来学习正常样本的外观和运动模式。
相比基于三维卷积自动编码器的异常检测(作者此处指3D卷积,认为16年Hasan那篇使用的是3d卷积,但Hasan使用的应该是二维卷积),作者的主要贡献在于提出了一个ConvLSTM自编码器框架,可以更好地分别对正常事件的外观变化和运动变化进行编码
通过实验证明了方法的有效性
Conclusion
通过使用利用CNN对每一帧进行编码,可以很好地对每一帧的内容进行表征,并利用ConvLSTM对运动信息进行表征。同时,ConvLSTM保留了空间信息,有助于重建当前帧和以前帧。在一个合成的的Moving-MNIST数据集上的实验表明,ConvLSTM-AE对外观和运动的变化具有鲁棒性。在所有真实数据集上的实验进一步表明,作者的模型大大优于卷积自动编码器。
ps:对运动信息提取的探索,卷积LSTM的又一次使用尝试,模型结构相比于16年那篇是新的。
Introduction
异常检测可以归结为以下两个子问题:i)如何表征外观和运动;Ii)如何建模外观或运动的变化。作者表示现有的许多动作识别工作表明,三维卷积不足以用于运动特征的描述(此处应是想与hasan做对比)
作者的工作总结如下:i)提出了一个ConvLSTM-AE框架,对外观和外观(运动)的变化进行编码,用于异常检测;ii)在合成移动MNIST数据集上的实验表明,提出的ConvLSTM-AE可以很容易地检测到由运动或外观引起的异常。在真实数据集上的实验进一步验证了该异常检测框架的有效性。
Related work
提到hasan那篇文章,预测视频中所有片段的异常。为了获得帧级的异常预测,需要对多个视频片段进行异常检测,并对每一帧进行异常程度插值,这一过程耗时较长。(此处提到了原文没提到的异常分数计算方法?)
Method
模型结构
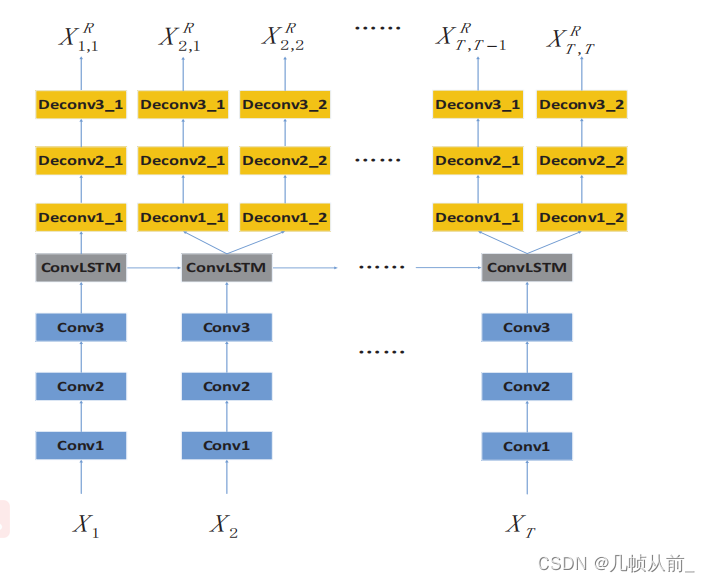
结构如上图首先使用CNN对每一帧的内容进行编码,然后将每一帧的编码特征输入到一个ConvLSTM中,由ConvLSTM记忆所有的历史帧。利用ConvLSTM的输出重建当前帧和前一帧。重构前一帧的目的是保证ConvLSTM能够记住历史帧中的信息。对于异常事件,随着外观或运动的变化,历史信息无法帮助重建当前帧。那么重建误差就会很高。因此,可以根据重构误差来判断是否发生异常。
目标函数(重构当前输入帧和过去一帧):
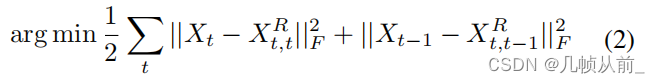
当t=1时,只重构当前帧。
首先,将3个卷积层分别叠加128、256、512个特征图。这些卷积层对应的内核大小分别是7×7、5×5和3×3。对于所有卷积层,stride设置为2。然后将ConvNet的输出输入到ConvLSTM-AE中,ConvLSTM-AE的输出大小与其输入相同。在ConvLSTM-AE中,初始输出和初始内存对应的h0和c0设为0。对于基于DeconvNet的解码模块,我们翻转了ConvNet的架构,即从下到上对应层的特征数分别为256、128、1,内核大小为7×7,5×5和3×3 , stride设为2。零填充用于所有卷积和反卷积层。
###异常检测
一旦模型经过训练,理论上,模型可以用于检测任意帧的测试视频的异常检测。然而,模型是用包含T帧的视频片段进行训练的。即使在测试阶段,模型仍然记住了前一帧中的信息,这可能对应于异常事件。因此,为了提高检测精度,作者每次只对包含连续
T
′
帧
T'帧
T′帧的视频片段进行异常预测。换句话说,作者强制网络在每T帧中忘记所有的历史信息,以提高异常检测的精度。
当前输入为
I
t
I_t
It,对应的重构错误计算为:
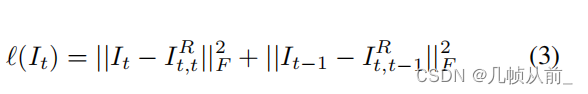
归一化分数:
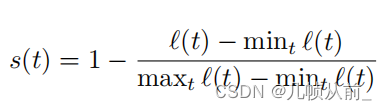
这里s(t)可以用来确定异常事件何时发生。对于普通时刻,s(t)对应一个更大的值。而对于异常事件,s(t)对应一个较小的值。
实验
使用了hasan等人的数据增强策略,学习率0.01,AdaGrad优化器,batch为4,Xavier初始化。ReLU激活。输入大小为225X225.
设定输入长度T为10,
T
′
T'
T′越大意味着记忆的信息越多。对于变化频繁的场景,我们可以使用小
T
′
T'
T′来证更高的精度。更具体地说,对于Ped1,Ped2,Avenue,
T
′
T'
T′固定为10。对于地铁入口和地铁出口,
T
′
T'
T′被设置为测试视频的长度,这意味着不需要刷新记忆,因为在地铁数据集中,几乎所有帧都对应于相同的背景。
Moving-MNIST Dataset测试
为了评估方法对分别由外观或运动引起的异常性能,在一个合成的Moving-MNIST数据集上部署实验。
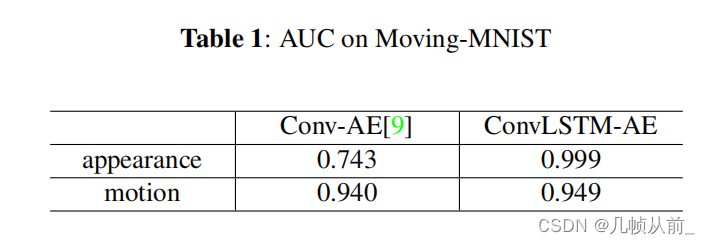
作者解释对于运动convAE已经很高了所以作者方法提升不明显,而外观作者方法提升很大
异常数据集测试
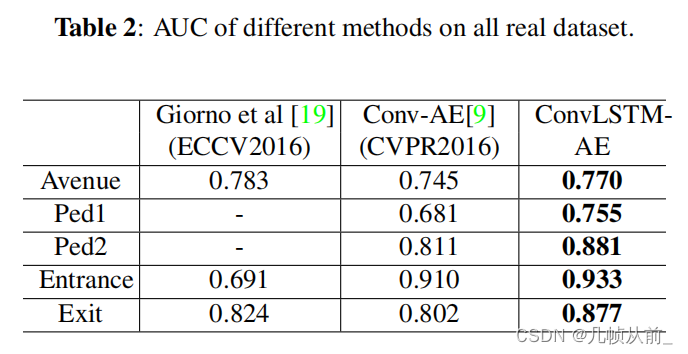
此处作者给出的ConvAE的结果是作者根据该论文作者提供的代码跑出的结果,与原论文有较大差距
作者最终帧级别 AUC:
ped1(0.755)
ped2(0.881)
Avenue(0.770)
Discussion
- 主要想利用LSTM提取运动信息,其他时序模型的尝试?
- LSTM作用是利用历史信息,这样当重构的时候会利用到过去的帧,将序列的帧联系起来了,但是是否是针对运动信息?学习到的可能是提取运动信息的能力,那么对于正常事件和异常事件区分度在哪?作者说在测试阶段仍会记忆异常事件的上下帧信息所以要每T忘记所有历史,所以对于正常和异常事件区分度在哪?如果是只针对正常运动提取则可具有区分度,这与自编码器存在相似问题即是否存在区分度。
- 如何在提取特征的同时使得正异常具有区分性。
- 本文利用了动作识别论文Long Term Recurrent Convolutional Networks for Visual Recognition and Description同样的结构只是在lstm输出上加入了解码结构。














 813
813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









