







arxiv:https://arxiv.org/pdf/1709.06531.pdf
本文贡献:
1.开发了一个端到端可训练的深度神经网络模型来进行暴力视频分类。
2.发现一个能够编码局部时空变化的递归神经网络用于检测视频中暴力的存在,能以较少的参数产生更好的表示。
3.证明了基于帧差训练的深度神经网络比基于原始帧训练的模型具有更好的性能。
4.使用三个广泛使用的暴力视频分类基准,实验验证了该方法的有效性。

红色的为卷积层、灰色的为归一化层、蓝色的为池化层、绿色的为ConvLSTM用于分类,全连接层为棕色。该网络由一系列卷积层和卷积长-短记忆(convLSTM)组成,前者用于提取鉴别特征,后者用于编码视频中存在的具有暴力场景特征的帧级变化。
ConvLSTM公式
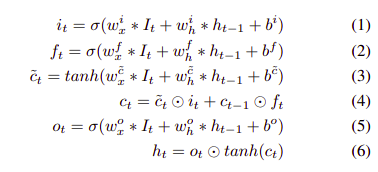
其中,*为卷积操作,⊙为逐点乘,ht为隐藏状态,ct为记忆单元,it、ft、ot均为3维的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 472
472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









