









摘要
近年来,集检测和识别为一体的端到端可训练场景文本检测方法取得了很大进展。然而,目前的任意形状场景文本观察器大多使用区域提案网络(RPN)来生成提案。RPN在很大程度上依赖于手动设计的锚,其提案用轴对齐的矩形表示。前者在处理具有极端纵横比或不规则形状的文本实例方面存在困难,而后者通常在密集定向文本的情况下将多个相邻实例包括在单个建议中。为了解决这些问题,我们提出了MASK TextSpotter v3,一个端到端的可训练场景文本检测器,它采用了分割建议网络(SPN)而不是RPN。我们的SPN是无锚点的,并给出了任意形状提案的准确表示。因此,它在检测极端纵横比或不规则形状的文本实例方面优于RPN。此外,SPN生成的准确建议允许使用屏蔽ROI特征来分离相邻文本实例。因此,我们的MASK TextSpotter v3可以处理长宽比极高或形状不规则的文本实例,其识别精度不会受到附近文本或背景噪音的影响。具体地说,我们在旋转的ICDAR 2013数据集上的性能比最先进的方法高21.9%(旋转健壮性),在全文本数据集上的性能高出5.9%(形状健壮性),在MSRA-TD500数据集上达到最先进的性能(纵横比健壮性)。
引言

RPN的局限性主要体现在两个方面:(1)人工预先设计的锚点是使用轴向对齐的矩形定义的,不能很容易地匹配极端纵横比的文本实例。(2)当文本实例被密集定位时,所生成的轴对齐的矩形建议可以包含多个相邻的文本实例。如图1所示,MASK TextSpotter v2[21]产生的建议彼此重叠,因此其ROI特征包括多个相邻文本实例,导致检测和识别错误。
在本文中,我们提出了一种分割建议网络(SPN),旨在解决基于RPN的方法的局限性。我们的SPN是无锚点的,并给出了提案的准确多边形表示。SPN不受预先设计的锚点的限制,可以处理长宽比极高或形状不规则的文本实例。然后,通过将我们提出的硬ROI掩蔽应用到ROI特征中,可以抑制相邻文本实例或背景噪声,从而充分利用其准确的建议。这在密集定向或形状不规则的文本的情况下是有益的,如图1所示。因此,通过将SPN引入到掩码TextSpotter v2中,提出了掩码文本聚焦v3。
方法
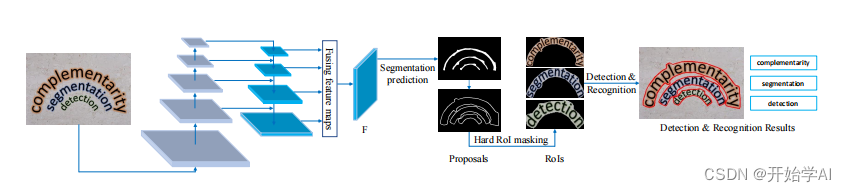
Mask TextSpotter v3结构
MASK TextSpotter v3由ResNet-50[12]主干、用于提案生成的分割提案网络(SPN)、用于提炼提案的Fast R-CNN模块[8]、用于准确检测的文本实例分割模块、用于识别的字符分割模块和空间注意模块组成。
SPN
SPN采用U-Net结构,从分割掩膜中产生候选建议,SPN是从融合特征图F中进行预测的,融合特征图F包含了各种感受野的特征图,F的尺寸为,预测文本分割图S的大小为1×H×W,其值在[0,1]的范围内。
分割标签生成
为了分离相邻文本实例,基于分段的场景文本检测器通常收缩文本区域[49,42]。灵感来自王等人[42]和DB[24],我们采用Vatti裁剪算法[39]通过裁剪d个像素来缩小文本区域。可以将偏移像素d设定为,A表示区域,L表示文本区域周长。r表示收缩比。

提议生成
给定值在[0,1]范围内的文本切分映射S,我们首先将S二进制化成二值B:
这里,i和j是分段或二进制映射的索引,并且t被设置为0.5。请注意,B的大小与S和输入图像相同。
然后,我们将二值图B中的连通区域分组。由于如上所述,文本分割标签被缩小,因此这些连通区域可以被认为是缩小的文本区域。因此,我们使用Vatti裁剪算法通过取消裁剪dˆ像素来扩展它们,其中dˆ被计算为。这里,Aˆ和ˆL是预测缩小的文本区域的面积和周长。根据收缩比r的值,rˆ设置为3.0.。如上所述,SPN产生的建议可以准确地表示为多边形,即文本区域的轮廓。因此,SPN为具有极端长宽比和密集定向/不规则形状的文本实例的文本行生成合适的建议。
硬ROI掩蔽
由于自定义ROI Align操作符仅支持轴对齐的矩形边界框,因此我们使用多边形提案的最小、轴对齐的矩形边界框来生成ROI特征,以使ROI Align操作符保持简单。
秦等人。[34]提出了一种将掩码概率图与感兴趣区域特征相乘的ROI掩蔽方法,其中掩码概率图由mask R-CNN检测模块生成。然而,掩码概率图可能是不准确的,因为它们是由RPN的建议预测的。例如, 它可以包含密集定向文本的多个相邻文本实例。在我们的例子中,精确的多边形表示是为建议设计的,因此我们可以通过我们提出的硬ROI掩蔽将建议直接应用到ROI特征上。
硬ROI掩码将二进制多边形掩码与ROI特征相乘,以抑制背景噪声或相邻文本实例,其中,多边形掩码M指示具有在多边形区中的全部1值和在多边形区之外的全部0值的轴对齐的矩形二进制图。假设R0是ROI特征,M是大小为32×32的多边形掩码,则掩码ROI特征R可以计算为R=R0∗M,其中∗表示逐元素相乘。通过用1填充多边形建议区域,同时将多边形外部的值设置为0,可以容易地生成M。我们报道了一项在SEC中对硬ROI掩蔽的消融研究。4.7,其中我们将所提出的硬ROI掩蔽与包括Qin等人的ROI掩蔽在内的其他算子进行了比较。[34][中英文对照]。
在应用硬ROI掩蔽后,掩蔽后的ROI特征中背景区域或相邻文本实例被抑制,大大降低了检测和识别模块的难度和错误。
实验


















 398
398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











