







 本文介绍了在深度学习中,针对不同场景选择ZeRO-3、模型并行和流水线并行的优势。ZeRO-3适合参数量大但计算量均衡的情况,通过参数分片和显存优化提高训练效率。模型并行适用于计算量大但参数量少的模型,通过层级分工和负载平衡提升计算效率。流水线并行则在计算量大且需要高效利用多GPU资源时发挥作用,通过流水线处理实现多批次并行,提高训练速度。
本文介绍了在深度学习中,针对不同场景选择ZeRO-3、模型并行和流水线并行的优势。ZeRO-3适合参数量大但计算量均衡的情况,通过参数分片和显存优化提高训练效率。模型并行适用于计算量大但参数量少的模型,通过层级分工和负载平衡提升计算效率。流水线并行则在计算量大且需要高效利用多GPU资源时发挥作用,通过流水线处理实现多批次并行,提高训练速度。
目录
1. ZeRO-3 (Zero Redundancy Optimizer-3)
1. ZeRO-3 (Zero Redundancy Optimizer-3)
适用场景:
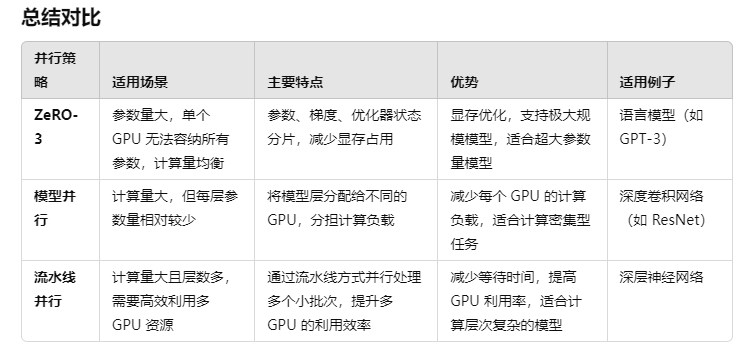
- 参数量非常大,以至于单个 GPU 无法容纳所有模型参数、优化器状态和梯度,计算量相对均衡的情况下。
主要特点:
- 参数、梯度和优化器状态分片:ZeRO-3 将模型的参数、梯度和优化器状态分散存储在多个 GPU 上,而不是在每个 GPU 上存储完整副本。
- 显存优化:通过将模型的各个部分分散到不同的 GPU 上,大大减少了每个 GPU 的显存需求,使得可以在较小显存的 GPU 上训练更大的模型。
- 支持大规模模型训练:在分布式训练中,即便是具有数十亿、数百亿或更大参数的模型,也可以通过 ZeRO-3 在多 GPU 环境下有效地训练。
优势:
- 极大降低了每个 GPU 所需的显存。
- 能够训练比显存容量大很多的模型,同时保持计算效率。
- 可与数据并行、模型并行等其他分布式训练方式组合使用。
适用场景举例:
- 语言模型:如 GPT-3 这样的超大规模模型,具有数十亿至百亿的参数,每个参数需要被存储和更新。单个 GPU 的显存无法同时容纳如此多的参数和梯度,ZeRO-3 可将这些分散到多个 GPU 上进行训练。
2. 模型并行
适用场景:
- 计算量非常大,但模型每一层的参数量相对较少的情况。
主要特点:
- 层级分工:将模型的不同层分配到不同的 GPU 上运行,确保每个 GPU 仅处理自己负责的模型部分。
- 计算负载分担:通过将计算任务在多个 GPU 之间进行分担,显著减少了每个 GPU 上的计算负载,使得每个 GPU 的算力都得到充分利用。
- 跨 GPU 通信:层之间的计算可能需要进行大量的跨 GPU 通信,影响到整体的训练速度,因此通常适用于跨层通信较少的模型。
优势:
- 分担计算量,使得计算效率得到提升。
- 避免在 GPU 之间传递过多数据,减少了通信开销。
- 能够处理计算密集型的模型训练任务。
适用场景举例:
- 深度卷积神经网络:例如 ResNet 等模型,卷积层的计算量非常大,但每层的参数量相对较少。通过将不同层分配到不同的 GPU 上,计算负载得到分担。
3. 流水线并行
适用场景:
- 计算量大,需要高效利用多个 GPU 资源的情况,通常是当模型层数较多时。
主要特点:
- 流水线处理:模型的不同部分(例如一部分层)分配给不同的 GPU,输入数据则通过流水线的方式逐层处理,每一批次的不同数据可以在不同的 GPU 上同时进行计算。
- 高效利用多 GPU 资源:通过流水线处理,不同的 GPU 可以同时处理同一个批次的不同部分数据或不同批次的数据,以此提高计算效率。
- 减少空闲时间:流水线并行的关键是减少每个 GPU 的等待时间,最大限度地利用每个设备的计算资源。
优势:
- 高效利用多 GPU 资源:通过并行处理,流水线并行可以极大地提高多 GPU 的利用率。
- 提升训练速度:多个小批次数据同时通过不同的 GPU 加速整体训练过程,适合层数较多的大型模型。
- 灵活性高:适合计算量较大且层次划分较明确的模型,可以轻松与数据并行或其他形式的并行计算方式结合。
适用场景举例:
- 深层神经网络(DNN):例如具有大量全连接层、卷积层的深度神经网络,通过流水线并行可以将前几层分配给一个 GPU,后几层分配给另一个 GPU,实现数据的流水线式处理。
最佳实践建议:
- ZeRO-3:适用于大参数量模型,但计算量相对均衡时,例如训练超大规模语言模型时,显存优化尤为重要。
- 模型并行:适用于计算量大、跨层通信少的任务,如深度卷积网络,每一层的计算密集但参数相对较少。
- 流水线并行:适用于层数多、需要高效利用 GPU 资源的场景,如深度学习中的神经网络,在复杂模型的训练中显著提高效率。
这三种并行训练策略可以单独使用或结合使用,以适应不同的训练需求。


















 589
589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











