







文章目录
一 、hadoop简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。【来源:百度百科】
二、hadoop安装部署
1.下载
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz ##官网也可以下在,这个地址下载速度快。
由于hadoop是java编写的,所以需要jdk
2.解压,写入环境变量
[root@node1 java]# useradd hadoop
[root@node1 java]# su - hadoop
[hadoop@node1 ~]$ ls
hadoop-3.2.1.tar.gz jdk-8u171-linux-x64.rpm
[hadoop@node1 ~]$ tar zxf hadoop-3.2.1.tar.gz #解压
[hadoop@node1 ~]$ ln -s hadoop-3.2.1 hadoop #将解压后的hadoop-3.2.1做个软链接
[hadoop@node1 ~]$ ll hadoop
lrwxrwxrwx 1 hadoop hadoop 12 Mar 22 10:46 hadoop -> hadoop-3.2.1
切换到root用户安装jdk
[root@node1 ~]# rpm -ivh jdk-8u171-linux-x64.rpm
[root@node1 ~]# rpm -ql jdk-8u171-linux-x64 #查看一下jdk的安装目录,后面要写进环境变量里
查看后安装目录在:/usr/java/jdk1.8.0_171-amd64
[hadoop@node1 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@node1 hadoop]$ vim hadoop-env.sh
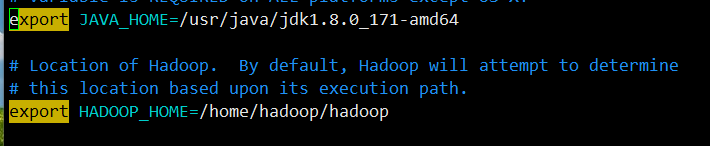
三、不完全分布式
1. Standalone Operation
[hadoop@node1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@node1 hadoop]$ mkdir input/ #建立input目录
[hadoop@node1 hadoop]$ cp etc/hadoop/*.xml input
[hadoop@node1 hadoop]$ cd input/
[hadoop@node1 input]$ ls
capacity-scheduler.xml hadoop-policy.xml httpfs-site.xml kms-site.xml yarn-site.xml
core-site.xml hdfs-site.xml kms-acls.xml mapred-site.xml
[hadoop@node1 hadoop]$ ls
bin etc include input lib libexec LICENSE.txt NOTICE.txt output README.txt sbin share
[hadoop@node1 hadoop]$ ls output/
part-r-00000 _SUCCESS
[hadoop@node1 hadoop]$ cat output/*
1 dfsadmin
2.Pseudo-Distributed Operation伪分布式
用单个节点模仿分布式的环境
[hadoop@node1 hadoop]$ vim etc/hadoop/core-site.xml #核心配置文件,写hdfs的master
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://172.25.7.131:9000</value>
</property>
</configuration>
[hadoop@node1 hadoop]$ cat etc/hadoop/workers #定义的是slave,master会自动连接works里的机器
localhost
[hadoop@node1 hadoop]$ vim etc/hadoop/hdfs-site.xml #hdfs副本数,默认为3,这里是单节点,改为1
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
免密:
[hadoop@node1 hadoop]$ ssh-keygen
[hadoop@node1 hadoop]$ ssh 172.25.7.131 #连接的时候输入个yes,再次连接即可直接连接
格式化node节点
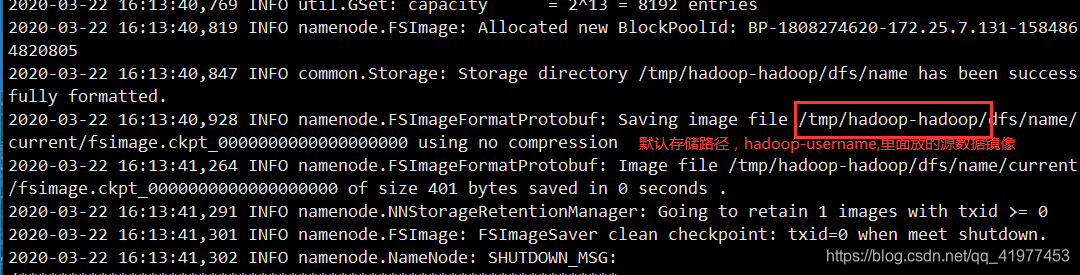
[hadoop@node1 hadoop]$ bin/hdfs namenode -format

开启master和slave
[hadoop@node1 hadoop]$ sbin/start-dfs.sh #因为是单节点,所以开启都在node1。master为namenode,简称nn,datanode是salve,简称dn
Starting namenodes on [node1]
node1: Warning: Permanently added 'node1' (ECDSA) to the list of known hosts.
Starting datanodes
Starting secondary namenodes [node1]
hadoop默认9870是web浏览器端口
[hadoop@node1 hadoop]$ bin/hdfs dfs -mkdir -p /user/hadoop
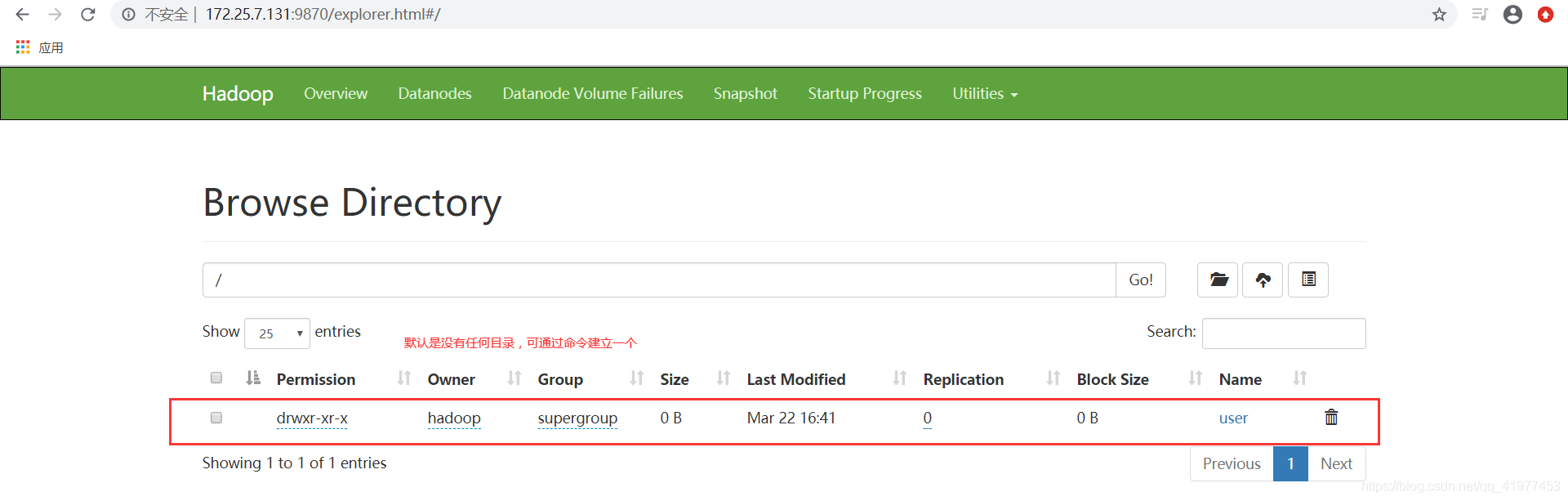
刚建立的目录,啥都没有
[hadoop@node1 hadoop]$ bin/hdfs dfs -put input/ #上传文件
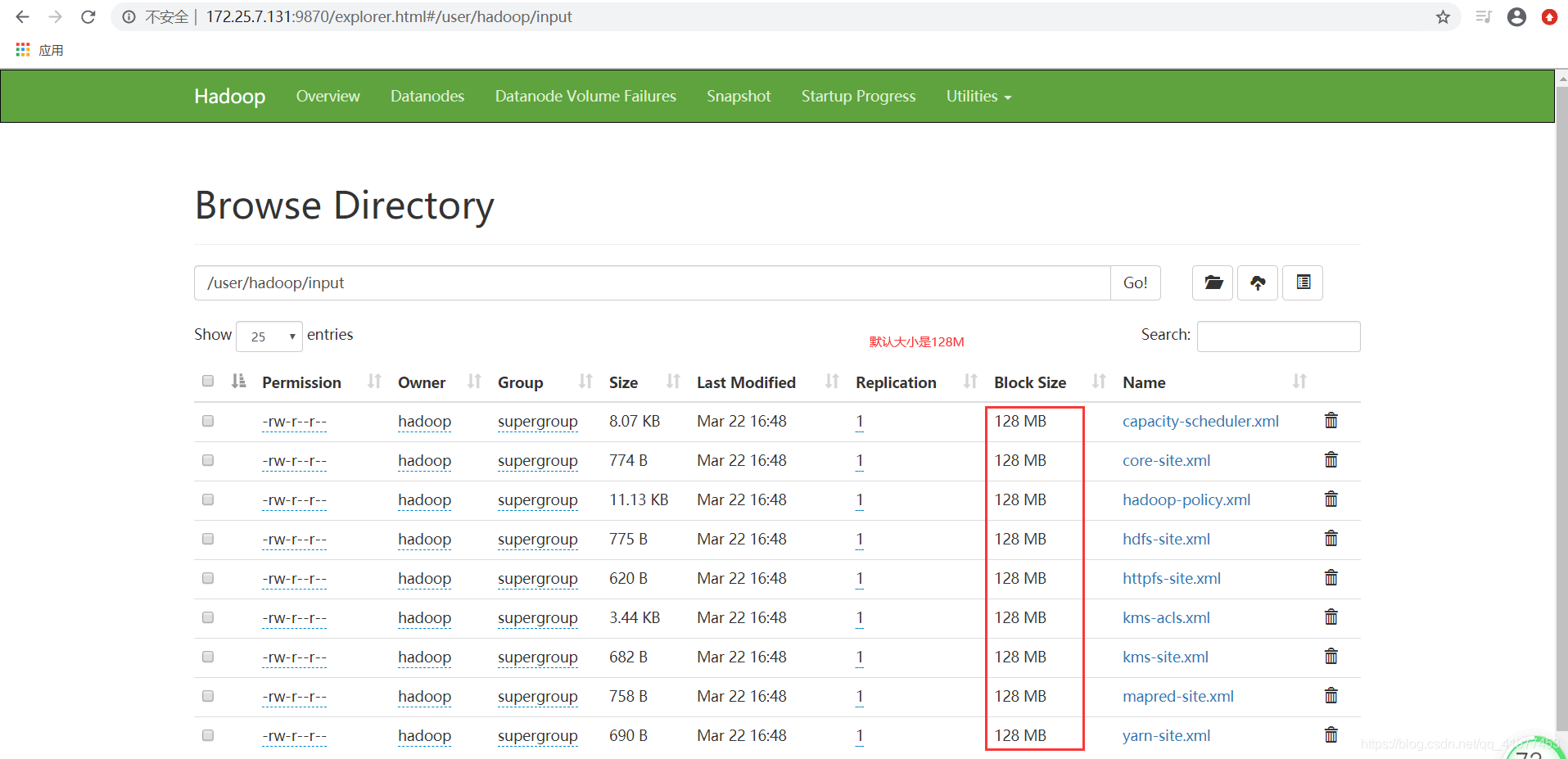
再上传一个文件:
[hadoop@node1 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount input output
浏览器中查看:
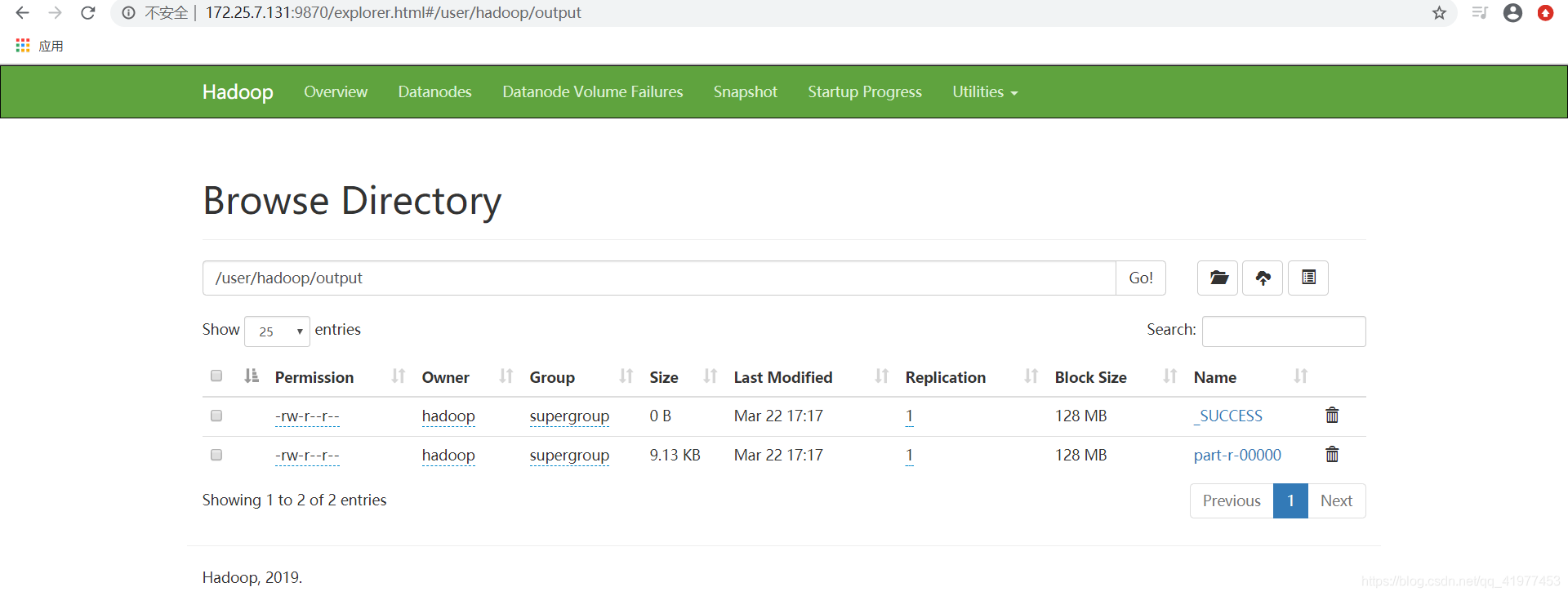
命令行查看上传的文件:
[hadoop@node1 hadoop]$ bin/hdfs dfs -ls output/
Found 2 items
-rw-r--r-- 1 hadoop supergroup 0 2020-03-22 17:17 output/_SUCCESS
-rw-r--r-- 1 hadoop supergroup 9351 2020-03-22 17:17 output/part-r-00000
[hadoop@node1 hadoop]$ bin/hdfs dfs -cat output/*
命令cat查看的部分数据
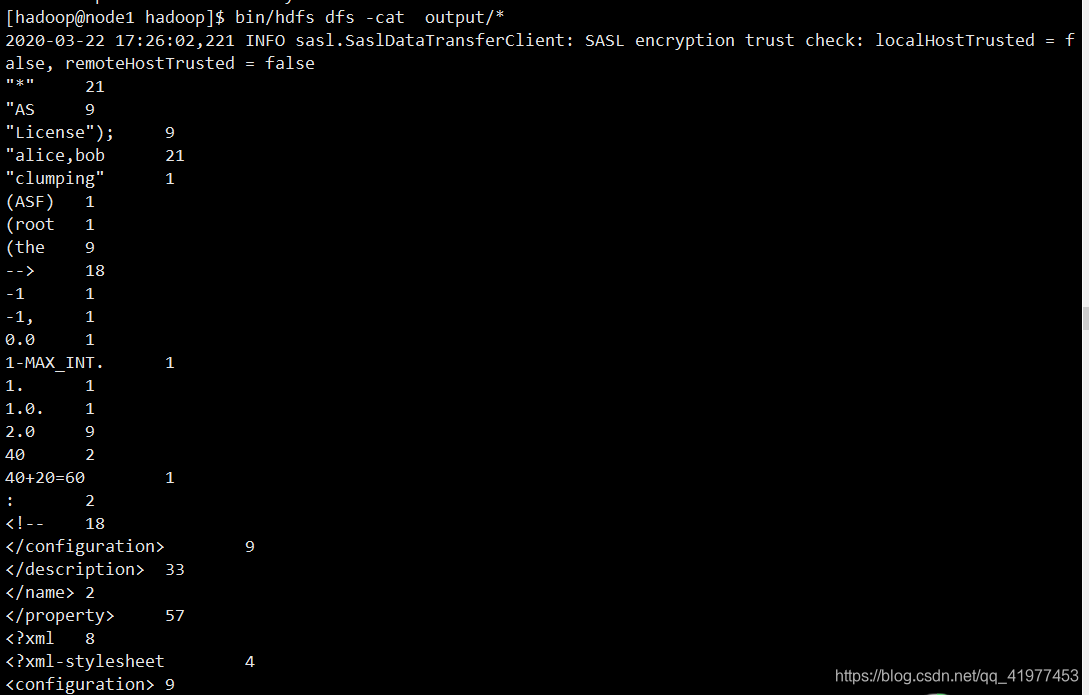
读的不是本地的output,所以本地的output删除了也可以在浏览器中查看。分布式的机制的输入熟出读的是分布式文件系统
[hadoop@node1 hadoop]$ rm -rf output/
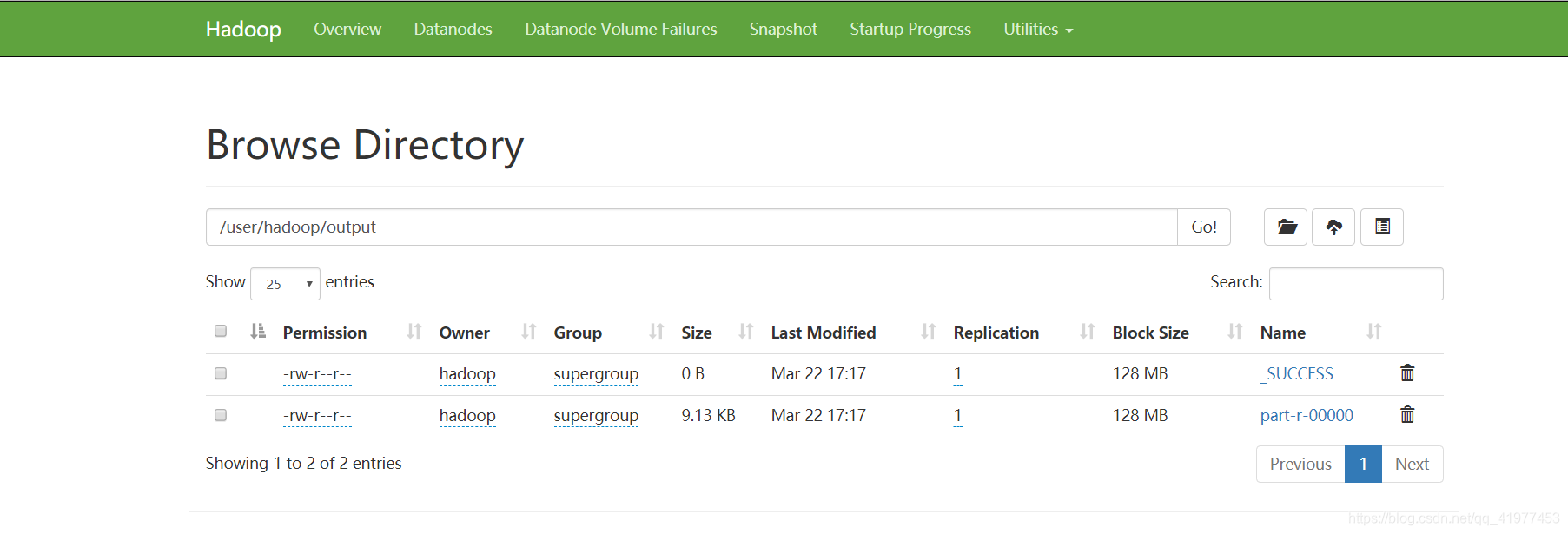
删了可以再从文件系统下载回来
[hadoop@node1 hadoop]$ bin/hdfs dfs -get output
[hadoop@node1 hadoop]$ cat output/* #这样也能查看
四、完全分布式
1.搭建
要求所有节点时间都同步,生产环境中最好使用时间同步服务器
先将node1的不完全分布式停掉:[hadoop@node1 hadoop]$ sbin/stop-dfs.sh
并且删除掉/tmp下的所有内容:[hadoop@node1 hadoop]$ rm -rf /tmp/*
实验环境:
| node1:172.25.7.131 | master |
|---|---|
| node2:172.25.7.132 | slave |
| node3:172.25.7.133 | slave |
[hadoop@node1 hadoop]$ vim etc/hadoop/hdfs-site.xml
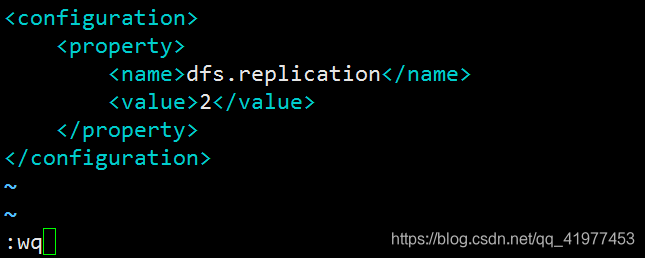
[hadoop@node1 hadoop]$ vim etc/hadoop/workers
[hadoop@node1 hadoop]$ bin/hdfs namenode -format #重新格式化
1.所有节点要存储同步,安装nfs-utils
[root@node1 ~]# yum install -y nfs-utils
[root@node2 ~]# yum install -y nfs-utils
[root@node3 ~]# yum install -y nfs-utils
并且,在node2和node3安装jdk,否则最后在master启动的时候会报错。
2.在各节点建立用户hadoop,并且id要一致

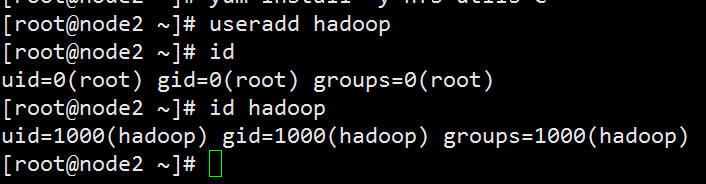

3.把hadoop目录共享出去
[root@node1 ~]# vim /etc/exports
/home/hadoop *(rw,anonuid=1000,anongid=1000)
4.开启nfs服务
[root@node1 ~]# systemctl start nfs
[root@node1 ~]# showmount -e #查看共享目录
Export list for node1:
/home/hadoop *
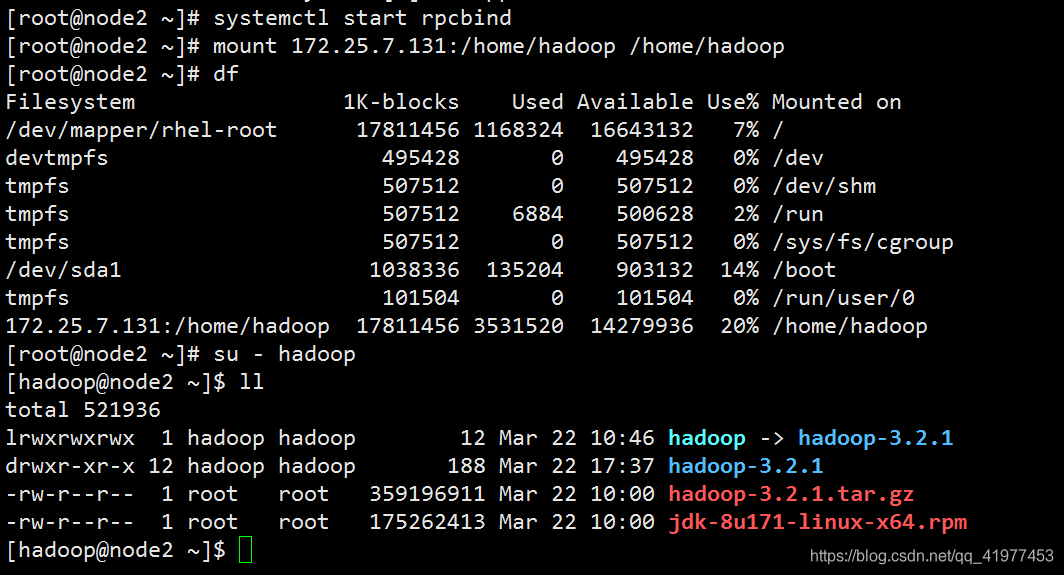
[root@node2 ~]# systemctl start rpcbind
[root@node2 ~]# mount 172.25.7.131:/home/hadoop /home/hadoop
[root@node2 ~]# su - hadoop
[hadoop@node2 ~]$ ll
total 521936
lrwxrwxrwx 1 hadoop hadoop 12 Mar 22 10:46 hadoop -> hadoop-3.2.1
drwxr-xr-x 12 hadoop hadoop 188 Mar 22 17:37 hadoop-3.2.1
-rw-r--r-- 1 root root 359196911 Mar 22 10:00 hadoop-3.2.1.tar.gz
-rw-r--r-- 1 root root 175262413 Mar 22 10:00 jdk-8u171-linux-x64.rpm
[root@node3 ~]# systemctl start rpcbind.service
[hadoop@node3 ~]$ mount 172.25.7.131:/home/hadoop /home/hadoop
[root@node3 ~]# su - hadoop
[hadoop@node3 ~]$ ll
total 521936
lrwxrwxrwx 1 hadoop hadoop 12 Mar 22 10:46 hadoop -> hadoop-3.2.1
drwxr-xr-x 12 hadoop hadoop 188 Mar 22 17:37 hadoop-3.2.1
-rw-r--r-- 1 root root 359196911 Mar 22 10:00 hadoop-3.2.1.tar.gz
-rw-r--r-- 1 root root 175262413 Mar 22 10:00 jdk-8u171-linux-x64.rpm
5.免密
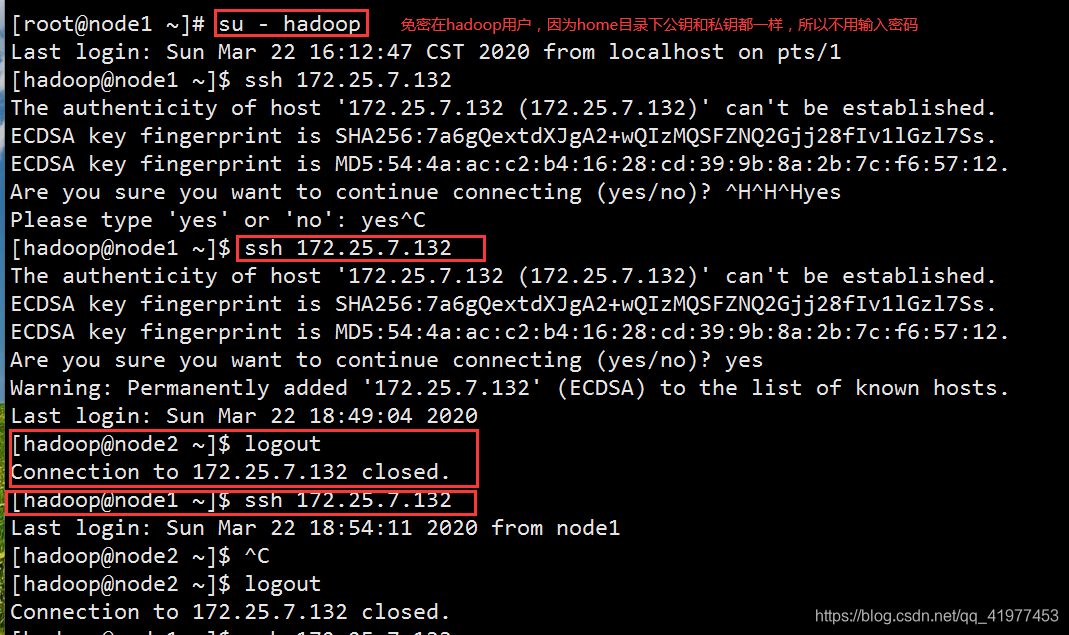
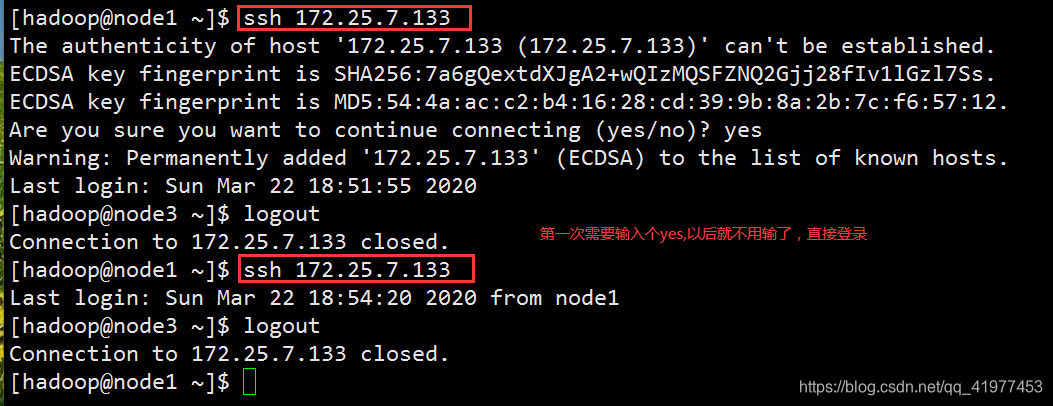
6.主节点启动,slave节点会随着主节点启动而启动
注意:
doe2和node3节点要装jdk,否则:
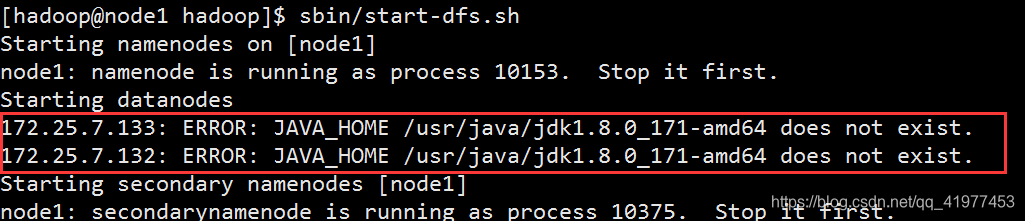
[hadoop@node1 hadoop]$ sbin/start-dfs.sh #启动
Starting namenodes on [node1]
node1: namenode is running as process 10153. Stop it first.
Starting datanodes
Starting secondary namenodes [node1]
node1: secondarynamenode is running as process 10375. Stop it first.
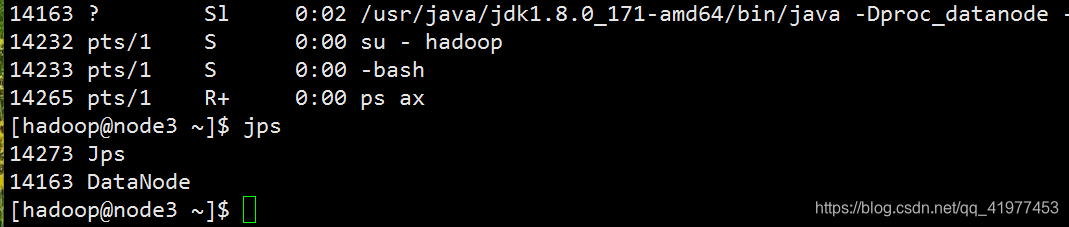
[hadoop@node1 hadoop]$ jps
11590 Jps
10375 SecondaryNameNode
10153 NameNode

2.测试
建立目录,上传数据:
[hadoop@node1 hadoop]$ bin/hdfs dfs -mkdir -p /user/hadoop
[hadoop@node1 hadoop]$ bin/hdfs dfs -put input

3. 在线扩容
再开启一台虚拟机node4
1.安装jdk,创建用户hadoop
[root@node4 ~]# rpm -ivh jdk-8u171-linux-x64.rpm
Preparing... ################################# [100%]
Updating / installing...
1:jdk1.8-2000:1.8.0_171-fcs ################################# [100%]
Unpacking JAR files...
tools.jar...
plugin.jar...
javaws.jar...
deploy.jar...
rt.jar...
jsse.jar...
charsets.jar...
localedata.jar...
[root@node4 ~]# useradd hadoop
[root@node4 ~]# id hadoop
uid=1000(hadoop) gid=1000(hadoop) groups=1000(hadoop)
2.安装nfs,开启rpcbind服务,并挂载
[root@node4 ~]# yum install -y nfs-utils
[root@node4 ~]# systemctl start rpcbind.service
[root@node4 ~]# mount 172.25.7.131:/home/hadoop/ /home/hadoop
[hadoop@node4 ~]$ ll
total 521936
lrwxrwxrwx 1 hadoop hadoop 12 Mar 22 10:46 hadoop -> hadoop-3.2.1
drwxr-xr-x 12 hadoop hadoop 188 Mar 22 17:37 hadoop-3.2.1
-rw-r--r-- 1 root root 359196911 Mar 22 10:00 hadoop-3.2.1.tar.gz
-rw-r--r-- 1 root root 175262413 Mar 22 10:00 jdk-8u171-linux-x64.rpm
3.在works写入新加的节点信息
[hadoop@node4 hadoop]$ vim etc/hadoop/workers
[hadoop@node4 hadoop]$ vim etc/hadoop/hdfs-site.xml


启动服务:
[hadoop@node4 hadoop]$ bin/hdfs --daemon start datanode
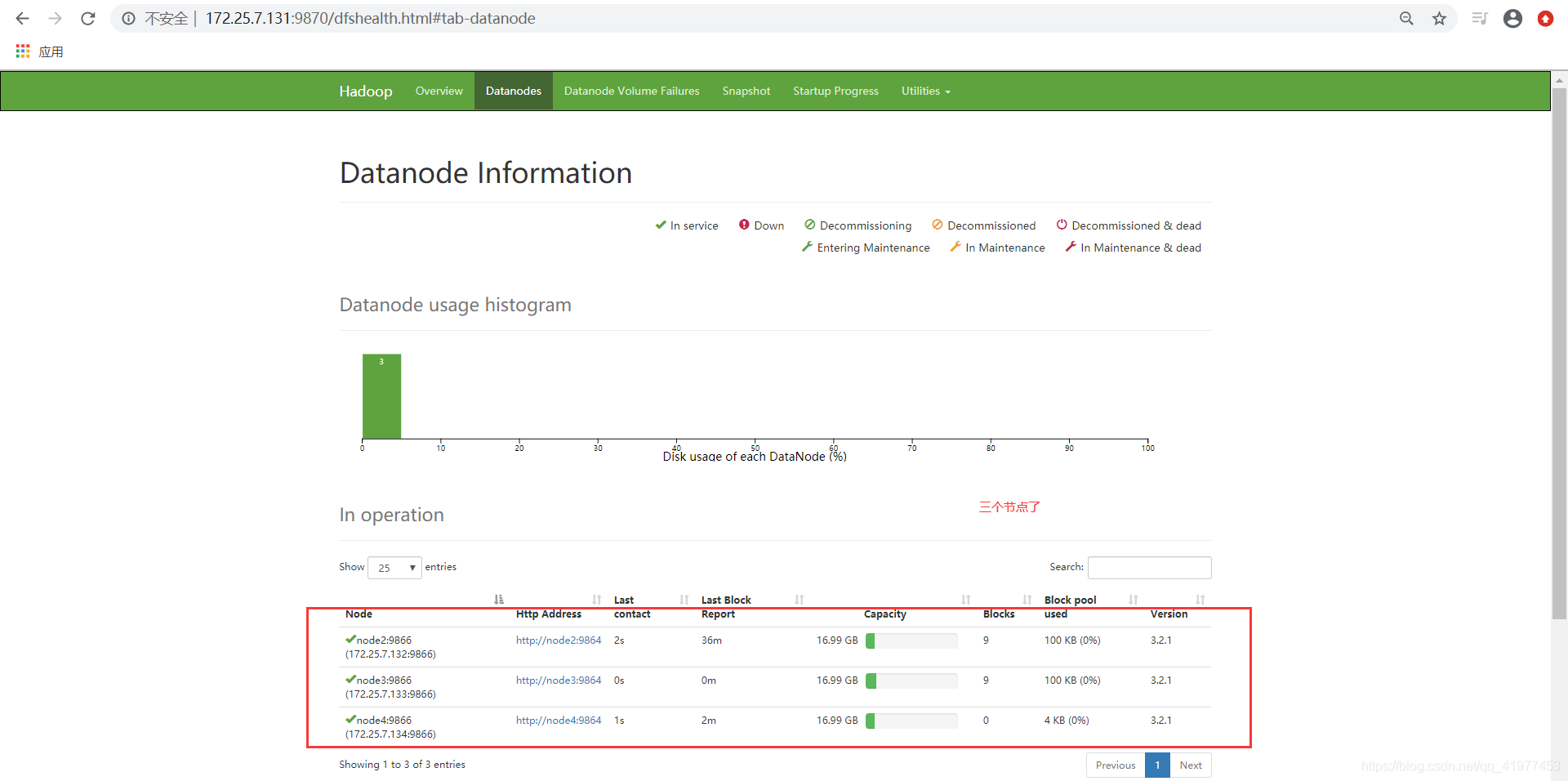
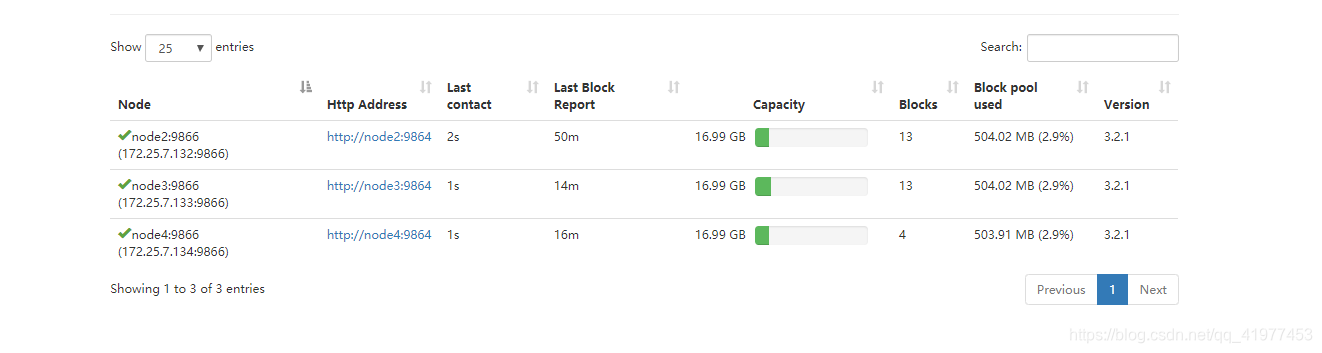
上传一个文件:
[hadoop@node1 hadoop]$ dd if=/dev/zero of=bigfile bs=1M count=500 #建立一个500M的文件
[hadoop@node1 hadoop]$ bin/hdfs dfs -put bigfile
五、工作原理
此博客推荐看看:https://cloud.tencent.com/developer/article/1481758
HDFS容错机制:
- 节点失败检测机制,DN每隔3秒向NN发送心跳信号,10分钟收不到,认为DN宕机。
- 通信故障检测机制:只要发送了数据,接收方就会返回确认码
- 数据错误监测机制:在传输数据时,同时会发送综合校验码
hdfs ==> nn(namenodes)+dn(datanodes)
mapred ==> rm(ResourceManager) +nm(NameNode)
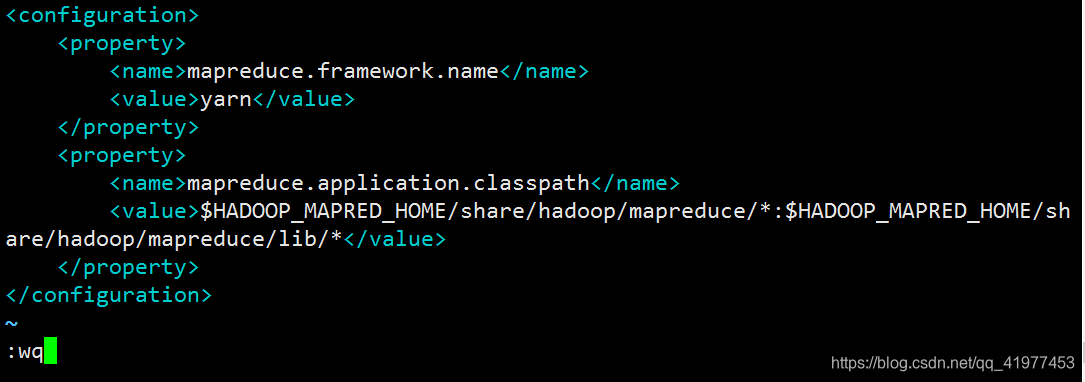
[hadoop@node1 hadoop]$ vim etc/hadoop/mapred-site.xml
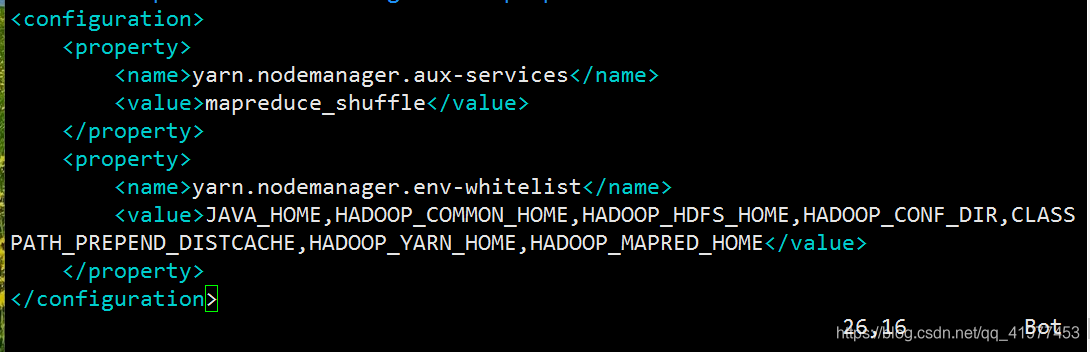
[hadoop@node1 hadoop]$ vim etc/hadoop/yarn-site.xml
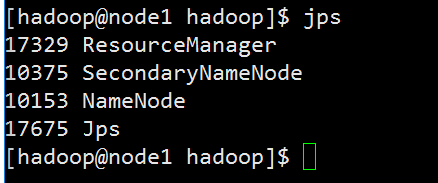
[hadoop@node1 hadoop]$ sbin/start-yarn.sh
[hadoop@node1 hadoop]$ jps
17329 ResourceManager
10375 SecondaryNameNode
10153 NameNode
17675 Jps
六、hdfs高可用
首先关闭nn和rm
[hadoop@node1 hadoop]$ sbin/stop-yarn.sh
Stopping nodemanagers
Stopping resourcemanager
[hadoop@node1 hadoop]$ jps
19766 Jps
10375 SecondaryNameNode
10153 NameNode
[hadoop@node1 hadoop]$ sbin/stop-dfs.sh
Stopping namenodes on [node1]
Stopping datanodes
Stopping secondary namenodes [node1]
删除各个节点/tmp下的内容
1.在/home/hadoop下载并解压zookeeper
增加node5节点
解压:
[hadoop@node1 ~]$ tar zxf zookeeper-3.4.9.tar.gz #解压
编写服务:
[hadoop@node1 ~]$ cd zookeeper-3.4.9/conf/
[hadoop@node1 conf]$ cp zoo_sample.cfg zoo.cfg #复制一份并改名
[hadoop@node1 conf]$ vim zoo.cfg #2888通信端口,3888选举端口
node.1=172.25.7.132:2888:3888
node.2=172.25.7.133:2888:3888
node.3=172.25.7.134:2888:3888
在节点node2,node3,node4上创建对应的id
[hadoop@node2 conf]$ mkdir /tmp/zookeeper
[hadoop@node2 conf]$ echo 1 > /tmp/zookeeper/myid
[hadoop@node3 ~]$ mkdir /tmp/zookeeper
[hadoop@node3 ~]$ echo 2 > /tmp/zookeeper/myid
[hadoop@node4 ~]$ mkdir /tmp/zookeeper
[hadoop@node4 ~]$ echo 3 > /tmp/zookeeper/myid
node2,node3,node4三个节点开启服务:
[hadoop@node2 zookeeper-3.4.9]$ bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.9/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@node3 zookeeper-3.4.9]$ bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.9/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@node4 zookeeper-3.4.9]$ bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.9/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
开启后查看状态,一般默认中间的(node3)是默认leader
[hadoop@node3 zookeeper-3.4.9]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: leader
node2和node4是follower


2.Hadoop配置
1.编辑core-site.xml文件
指定hdfs的namenode为masters(名称可自定义)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://masters</value>
</property>
</configuration>
指定zookeeper集群主机地址
<property>
<name>ha.zookeeper.quorum</name>
<value>172.25.7.132:2181,172.25.7.133:2181,172.25.7.134:2181</value>
</property>
2.编辑hdfs-site.xml文件
指定hdfs的nameservers为masters,和core-site.xml文件中的设置保持一致:
<property>
<name>dfs.nameservices</name>
<value>masters</value>
</property>
masters下面有两个namenode节点,分别是h1和h2(名称可自定义):
<property>
<name>dfs.ha.namenodes.masters</name>
<value>h1,h2</value>
</property>
指定h1节点的rpc通信地址:
<property>
<name>dfs.namenode.rpc-address.masters.h1</name>
<value>172.25.7.131:9000</value>
</property>
指定h1节点的http通信地址:
<property>
<name>dfs.namenode.http-address.masters.h1</name>
<value>172.25.7.131:9870</value>
</property>
同理,指定h2和rpc通信地址和http通信地址:
<property>
<name>dfs.namenode.rpc-address.masters.h2</name>
<value>172.25.7.135:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.masters.h2</name>
<value>172.25.7.135:9870</value>
</property>
指定
指定namenode元数据在journalnode上的存放位置:
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://172.25.7.132:8485;172.25.7.133:8485;172.25.7.134:8485/masters</value>
</property>
指定JournalNode在本地磁盘呢存放数据的位置:
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/tmp/journaldata</value>
</property>
开启node失败自动切换:
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
配置失败自动切换实现方式:
<property>
<name>dfs.client.failover.proxy.provider.masters</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
配置隔离方法机制,每个机制占用一行:
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
使用sshfence隔离机制时需要ssh免密码:
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa </value>
</property>
配置sshfence隔离机制超时时间:
3.启动hdfs集群(按顺序启动)
(1)在三个DN上一次启动zookeeper集群
/bin/zkServer.sh start #已经启动过了
(2)在三个DN上依次启动journalnode(第一次启动hdfs必须先启动journalnode)
[hadoop@node2 hadoop]$ bin/hdfs --daemon start journalnode
[hadoop@node3 hadoop]$ bin/hdfs --daemon start journalnode
[hadoop@node4 hadoop]$ bin/hdfs --daemon start journalnode
启动后会有一个日志节点,并且8485端口会打开
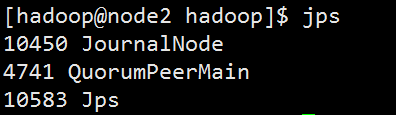
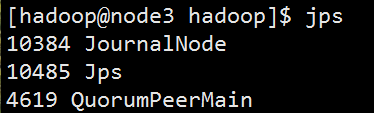
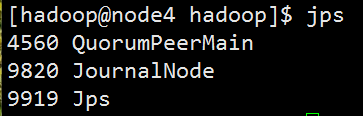
(3)格式化HDFS集群
[hadoop@node1 hadoop]$ bin/hdfs namenode -format
NameNode数据默认存放在h1,需要把数据拷贝到h2:
[hadoop@node1 hadoop]$ cd /tmp/
[hadoop@node1 tmp]$ ls
hadoop-hadoop hadoop-hadoop-namenode.pid hsperfdata_hadoop journaldata
[hadoop@node1 tmp]$ scp -r hadoop-hadoop 172.25.7.135:/tmp/

(4)格式化zookeeper(只需在h1上执行即可)
[hadoop@node1 hadoop]$ bin/hdfs zkfc -formatZK
(5)启动集群
[hadoop@node1 hadoop]$ sbin/start-dfs.sh
[hadoop@node1 hadoop]$ jps
20596 NameNode
20998 DFSZKFailoverController
21067 Jps
在其他节点上查看
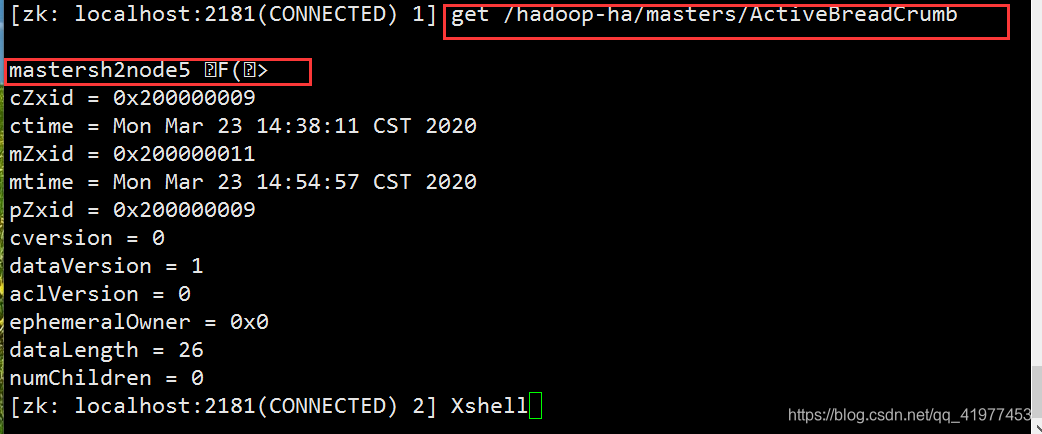
[hadoop@node2 zookeeper-3.4.9]$ bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 8] get /hadoop-ha/masters/ActiveBreadCrumb #查看谁是master
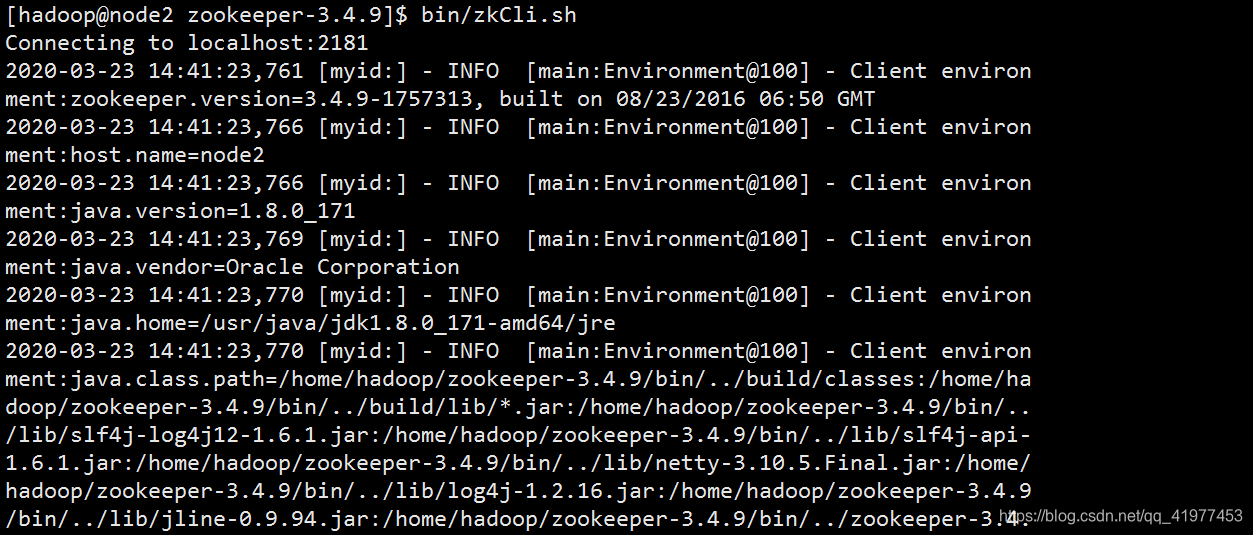

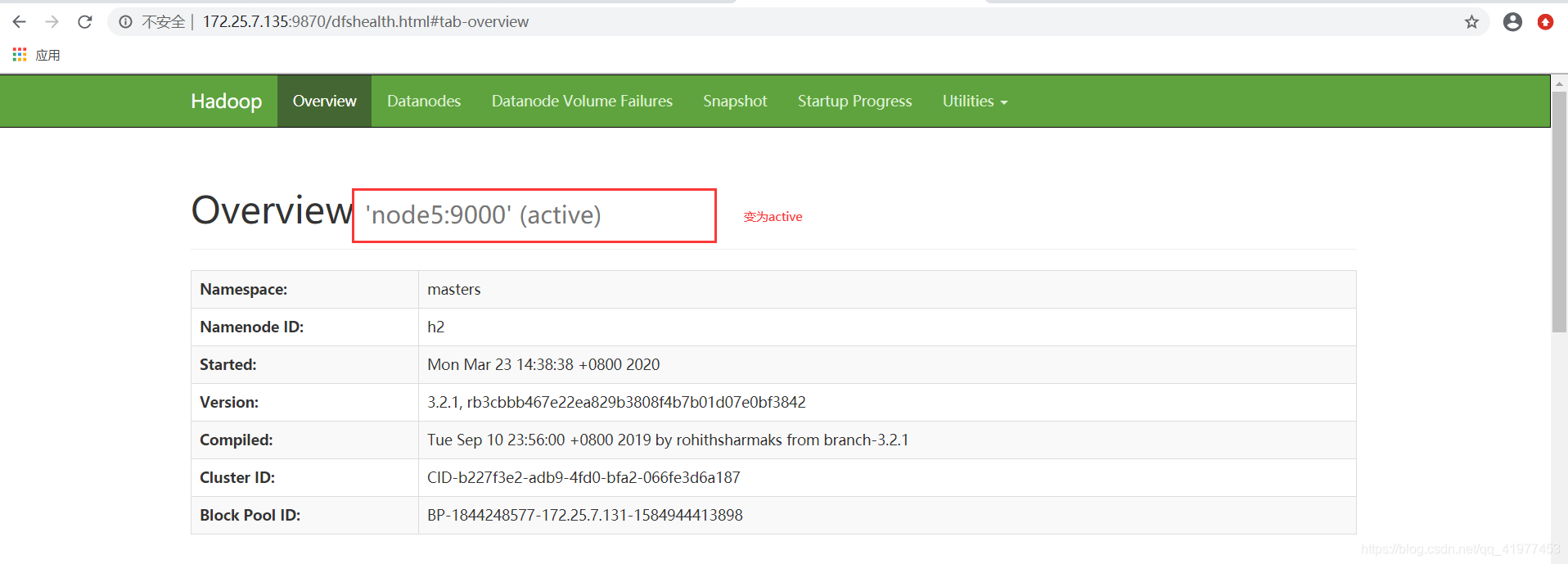
也能在浏览中web页面查看
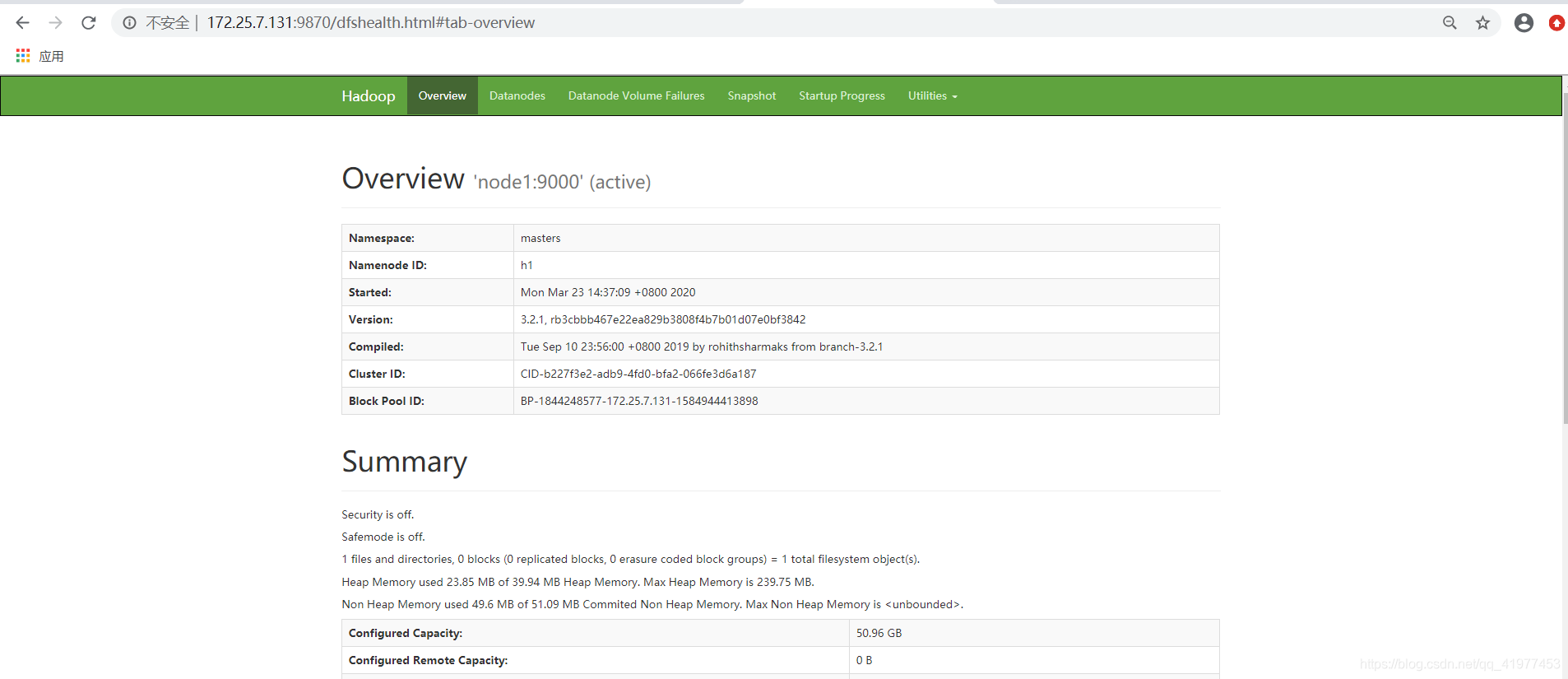
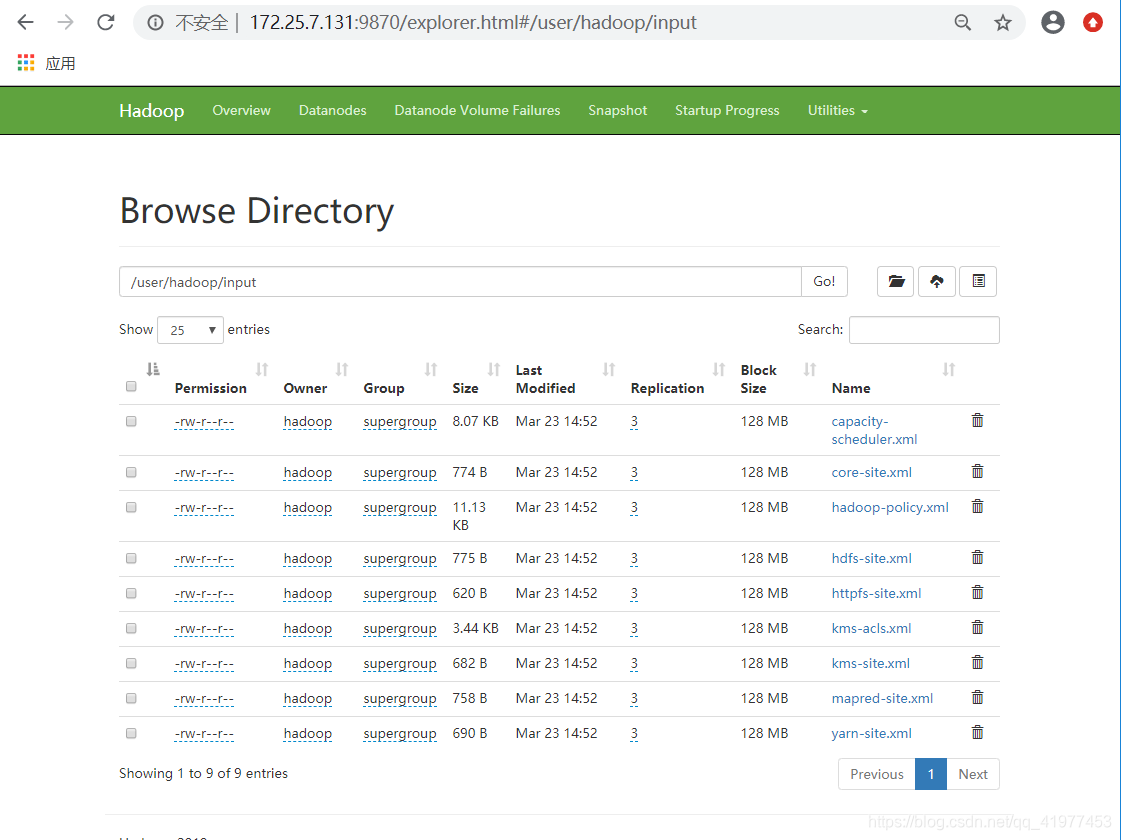
上传文件数据测试:
[hadoop@node1 hadoop]$ bin/hdfs dfs -mkdir -p /user/hadoop
[hadoop@node1 hadoop]$ bin/hdfs dfs -put input
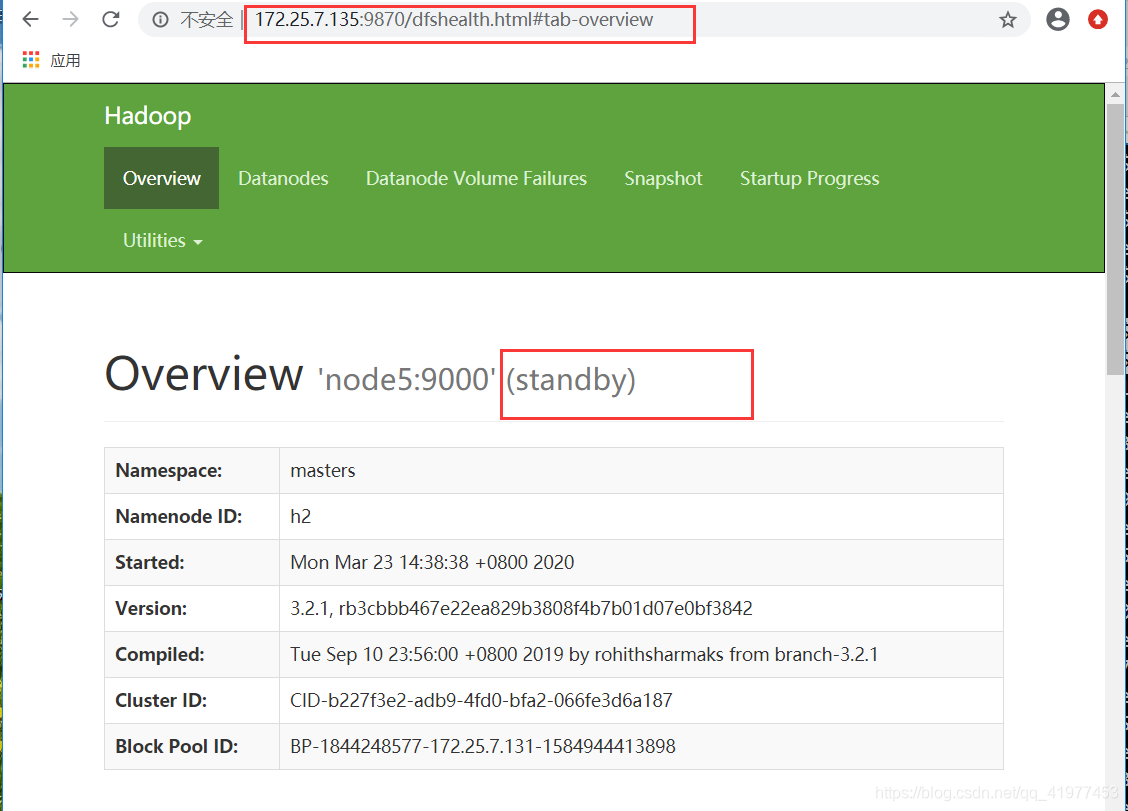
故障测试
把master的进程杀掉
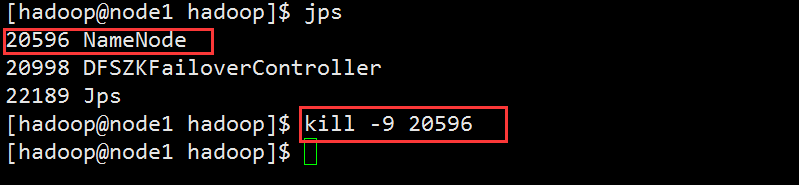
在数据节点上node2查看,node5变成了主节点。
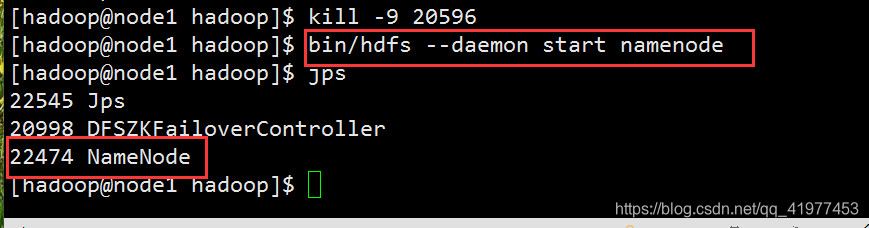
node1可再次开启:
七、yarm的高可用配置
生产环境中,RM和NM要分开,都是消耗资源的大户,此处实验机器不够,就讲RM和NM放在一起。
1.编辑mapred-site,xml文件
指定yarn为MapReduce的框架:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
2.编辑yarn-site.xml文件
配置可以在nodemanager上运行mapreduce程序:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
激活RM高可用:
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
指定RM的集群id:
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>RM_CLUSTER</value>
</property>
定义RM的节点:
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
指定RM1的地址:
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>172.25.7.131</value>
</property>
指定RM2的地址:
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>172.25.7.135</value>
</property>
激活RM自动恢复:
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
配置RM状态信息存储方式,有MemStore和ZKStore:
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
配置为zookeeper存储时,指定zookeeper集群的地址:
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>172.25.7.132:2181,172.25.7.133:2181,172.25.7.134:2181</value>
</property>
3.启动:
[hadoop@node1 hadoop]$ sbin/stop-yarn.sh
Stopping nodemanagers
Stopping resourcemanagers on [ 172.25.7.131 172.25.7.135]
[hadoop@node1 hadoop]$ sbin/start-yarn.sh
Starting resourcemanagers on [ 172.25.7.131 172.25.7.135]
Starting nodemanagers
[hadoop@node1 hadoop]$ jps
26945 ResourceManager
20998 DFSZKFailoverController
22474 NameNode
27066 Jps
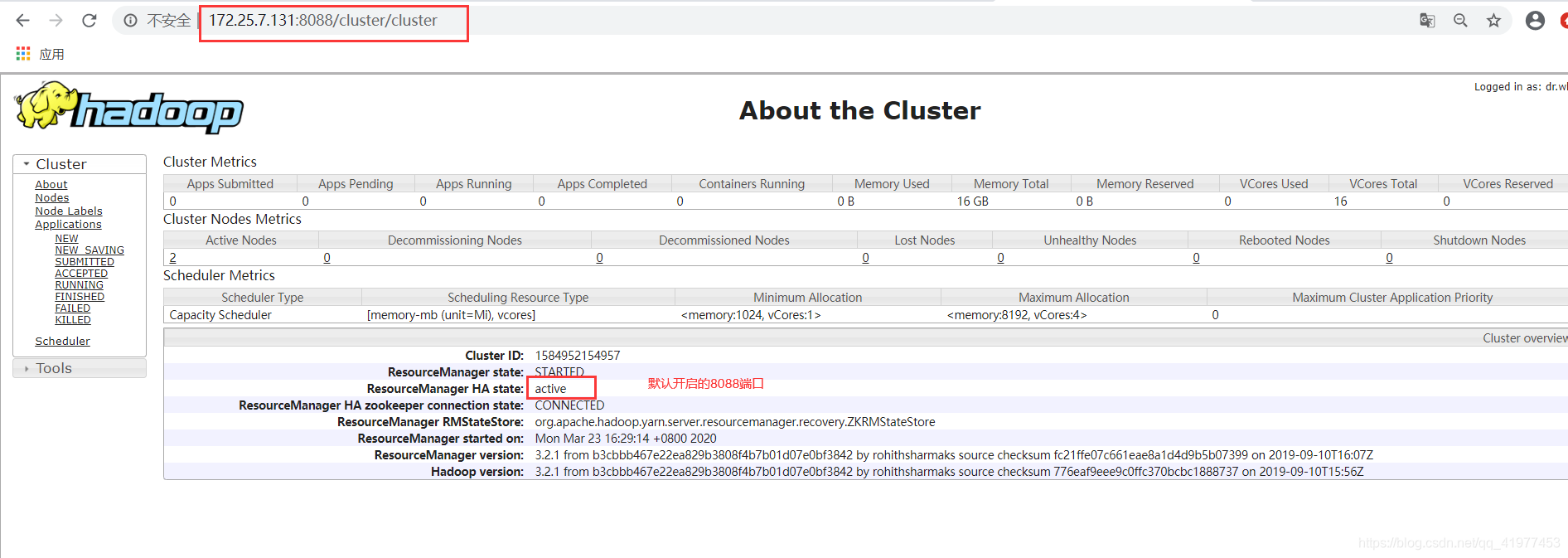
RM2需要手动开启: #老版本需要手动开启
[hadoop@node5 hadoop]$ sbin/yarn-daemon.sh start resourcemanager

模拟故障产生
[hadoop@node1 hadoop]$ jps
20998 DFSZKFailoverController
22474 NameNode
31100 ResourceManager
31820 Jps
[hadoop@node1 hadoop]$ kill 31100 #将RM 进程杀掉
[hadoop@node1 hadoop]$ jps
20998 DFSZKFailoverController
31846 Jps
22474 NameNode
浏览器172.25.7.131:8088不能访问,135可以访问,并且变成active
 node1也可以恢复运行:
node1也可以恢复运行:
[hadoop@node1 hadoop]$ bin/yarn --daemon start resourcemanager
[hadoop@node1 hadoop]$ jps
20998 DFSZKFailoverController
32295 ResourceManager
32328 Jps
22474 NameNode














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









