







 本文围绕 UNet - 2022 展开,指出 self - attention 和卷积现存问题,提出新的权重分配机制,将动态权重引入空间和通道维度。介绍了 UNet - 2022 模型的编码器、解码器结构,以及卷积干、反卷积干的操作。还提及损失函数,通过消融实验展示了模型性能提升。
本文围绕 UNet - 2022 展开,指出 self - attention 和卷积现存问题,提出新的权重分配机制,将动态权重引入空间和通道维度。介绍了 UNet - 2022 模型的编码器、解码器结构,以及卷积干、反卷积干的操作。还提及损失函数,通过消融实验展示了模型性能提升。
UNet-2022: Exploring Dynamics in Non-isomorphic Architecture
论文地址:https://arxiv.org/pdf/2210.15566.pdf
代码地址:https://bit.ly/3ggyD5G
现存问题:
- (a)self-attention,不同的位置有不同的权重,而同一位置的所有通道共享相同的权重。分配的权重在通道维度上不是动态的,从而阻止了 self-attention 捕获不同通道之间的内部差异。
- (b)同一组卷积核权重在不同的空间位置之间共享,而动态权重则分配给不同的通道。
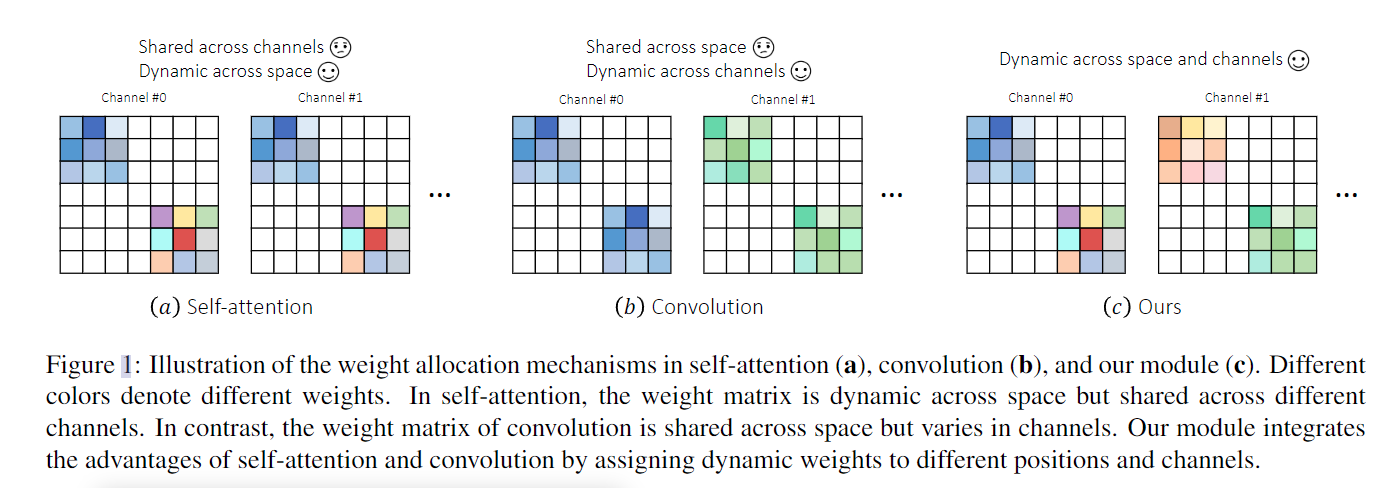
主要贡献:
- 我们提供了一个直观的解释,解释了为什么 self-attention 和卷积可以相互补充。核心区别在于权重分配机制的动态特性。自注意力解决了空间动态的重要性,但忽略了通道动态。相反,卷积将动态权重分配给不同的通道而不是空间位置。
- 我们提出了一种新的权重分配机制,将动态权重引入空间和通道维度。权重分配机制的实现非常简单,包括并行独立的自注意力和卷积模块。生成的非同构块为不同的空间位置和通道分配动态权重,使其能够捕获特征图中出现的复杂模式。
模型简介:
UNet-2022 的编码器由一个卷积主干和三个阶段组成,每个阶段涉及三个并行的非同构 (PI) 块。对称地,解码器还包括三个阶段和一个反卷积主干。在每个下采样/上采样步骤中,我们增加/减少通道数并相应地减少/增加特征图的空间分辨率。跳过连接用于弥合低级细节和高级语义之间的差距。
图 2b 描述了并行非同构块的内部结构细节。我们使用深度卷积(DwConv)来减少参数的数量。自注意力和深度卷积并行化以分别探索空间和通道维度的动态,然后将其输出相加并传递到全连接 (FC) 层。在卷积干中,我们堆叠多个卷积层以提取高分辨率特征图。类似的操作也适用于反卷积茎,其中多个反卷积层被堆叠以产生最终的分割掩码。
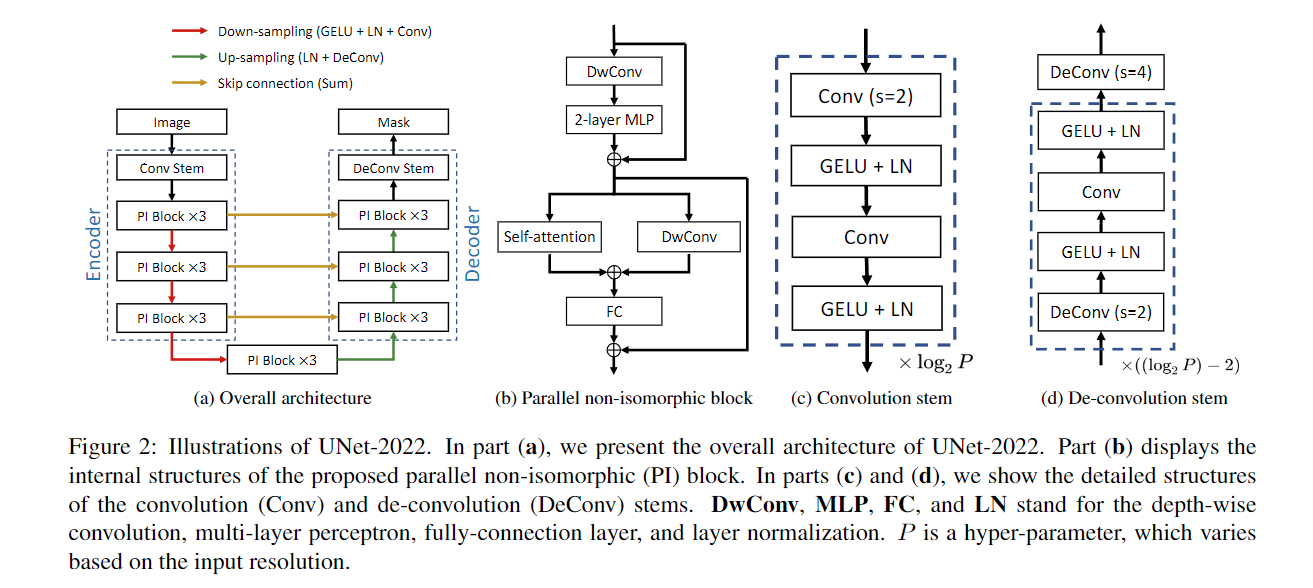
Parallel non-isomorphic block:
如前所述,self-attention 和卷积强调不同维度的动态,使它们相互补充。受这一发现的启发,我们建议通过对自注意力和卷积的直接并行化将它们的优势整合到非同构块中。
其具体做法见图2(b)
Convolution stem
卷积干由许多堆叠的块(虚线框中的层)组成。每个块由两个卷积层组成,步幅分别为 2 和 1。每个卷积层后面跟着一个 GELU 和一个归一化层。每当特征图的空间分辨率降低一半时,我们相应地将其通道数加倍。其具体做法见图2(c)
为了适应高分辨率的图像,我们在卷积干中堆叠更多的块,以降低内存成本并提高计算效率。具体来说,块的数量,即 log2 P ,取决于我们手动设置的补丁大小 P。例如,对于中小输入分辨率,我们将 P 设置为 4,例如 224×224 和 320×320。当输入分辨率较高时,我们将 P 增加到 8,例如 512 × 512。
De-convolution stem
与卷积主干类似,反卷积主干的架构也因输入图像的分辨率而异。对于小(224 × 224)和中等(320 × 320)输入大小,反卷积茎仅由一个反卷积层组成,其内核大小为4,步幅为4。至于高分辨率输入(即,512×512),我们采用了与卷积茎相似的策略,即增加上采样块的数量(参见图 2d)。在实践中,反卷积茎涉及具有反卷积层的块,以实现对特征图进行上采样以产生最终掩模预测的目标。具体来说,反卷积块的数量为 (log2 P ) − 2,对于小 (P =4) 和中等 (P =4) 分辨率为 0,对于高分辨率输入 (P =8) 为 1 , 分别。
损失函数:
crossentropy loss and dice loss
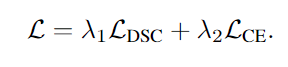
λ
1
、
λ
2
\lambda_1、\lambda_2
λ1、λ2分别为1.2和0.8
实验结果:

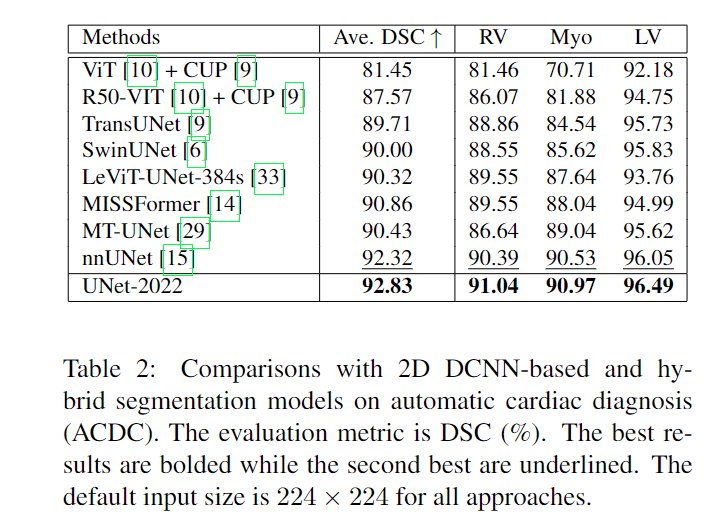

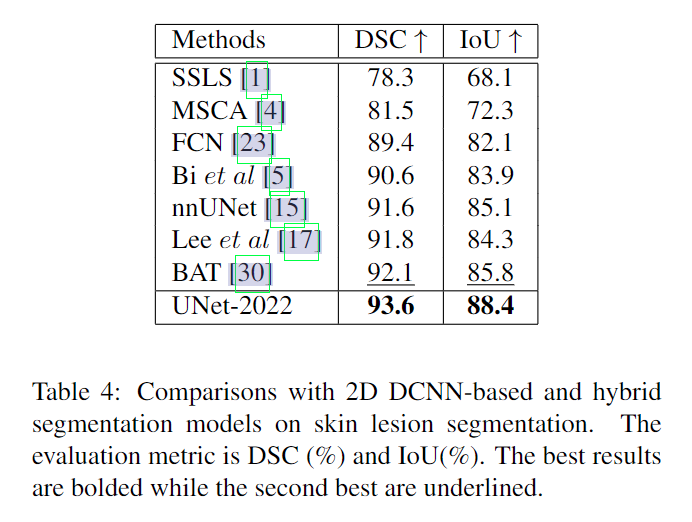
消融实验:
在本节中,我们首先通过将其与 Swin Transformer (ST) 块和 ConvNeXt (CNX) 块进行比较来研究提出的 PI 块的影响。然后,我们进一步研究了 PI 块中 self-attention 和 DwConv 层的影响。接下来,我们展示了基于 ImageNet 的预训练相对于从头开始训练的性能提升。最后,我们提出了一种新的后处理策略,我们发现它在经验上提供了稳定的任务性能改进。
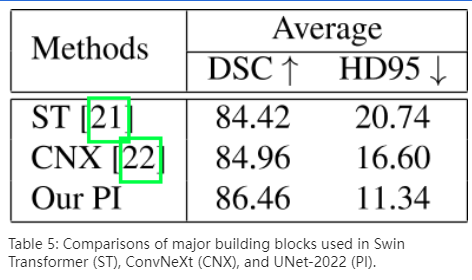
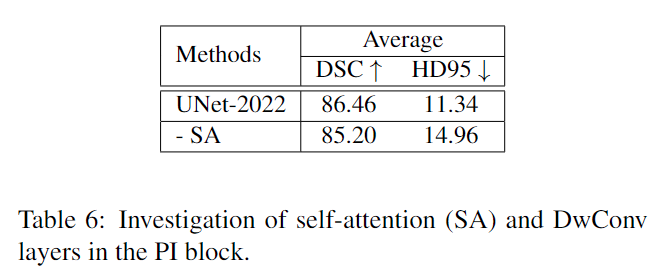
首先,我们从 PI 块中移除自注意力层。结果,生成的构建块无法探索不同空间位置的动态,因为它们只包含卷积操作。这种失败可以通过表 6 第二行中可观察到的任务性能下降来验证。
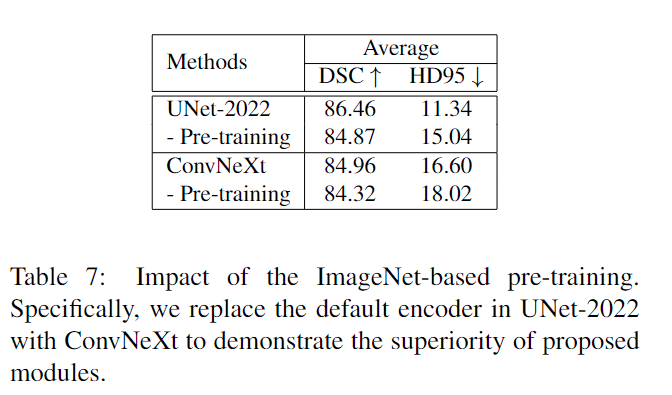
引入预训练可将平均 DSC 提高 1.5%,并将 HD95 提高近 5mm。
全文仅为个人理解, 如有错误欢迎指正!

















 2619
2619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









