










机器学习翻译任务中的constrain decoding 实现流程
前言
在翻译任务中(从一种格式的语言翻译到另一种格式的语言,并不局限于国家自然语言的互相转换,从自然语言翻译到程序代码也算一种,比如Text2SQL任务),通常会涉及到格式化语言的输出,这时候需要constrain decoding算法来避免模型输出词汇/语法错误的sequence,按照我们给出的一系列准则,使模型输出我们希望的结果。
本文主要介绍项目中本人调研并使用过的constrain decoding算法,介绍其实现流程以及优缺点,为后来者提供参考和借鉴。
一、(Vectorized) Lexically constrained decoding with dynamic beam allocation
官方Readme文档参考链接戳这里。
这一方法目前已经集成到了fairseq源码中,可以直接调用,它的使用原理很简单,给定一组候选词汇list, 模型generate时必将输出包含list里所有内容的sequence。如果传入ordered参数,意味着模型在最后输出的sequence里出现的候选词的顺序和list给出的顺序是一致的,在Readme里体现为:
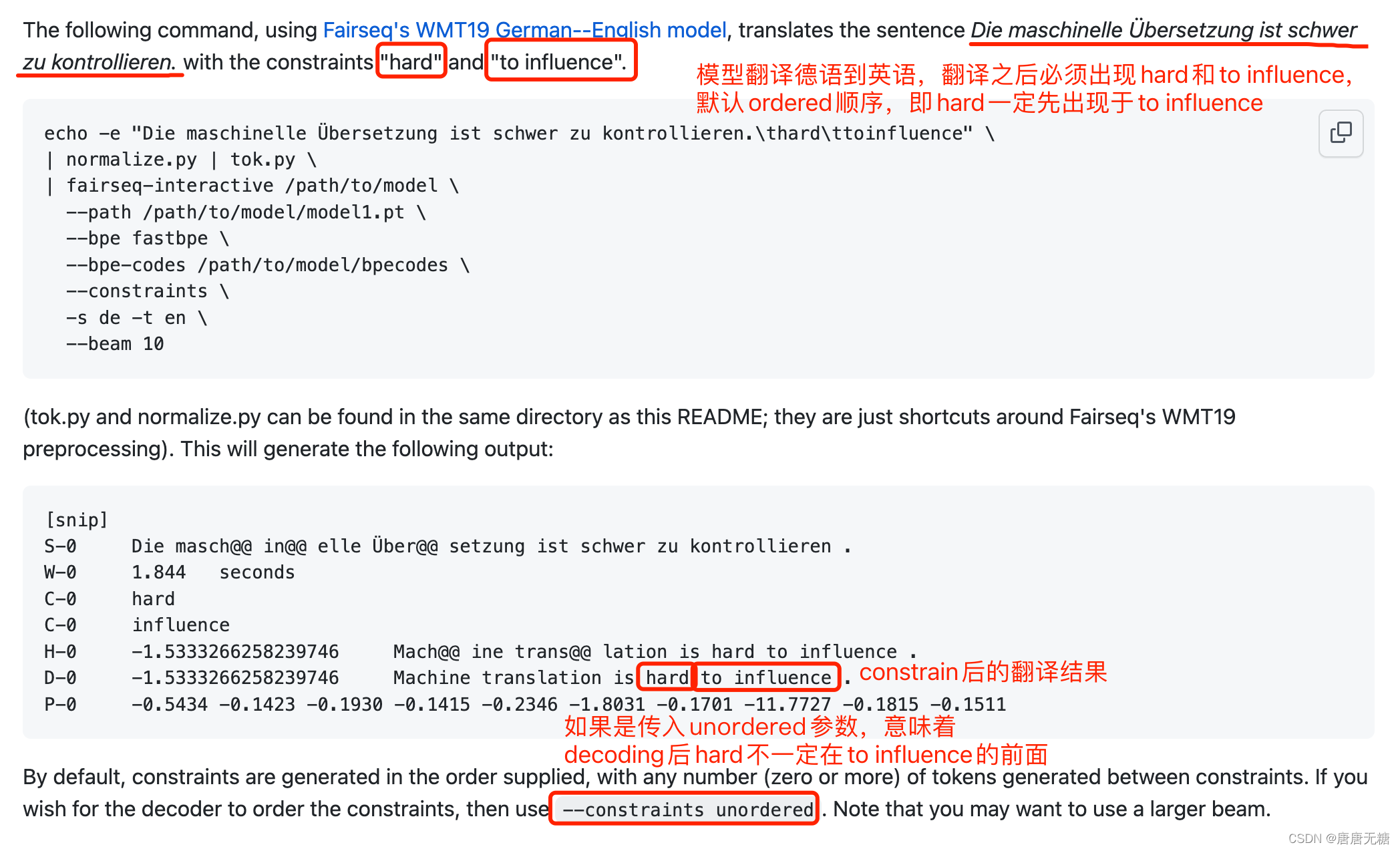
但是MD文档里只介绍了fairseq-interactive的使用方法,并没有给出python代码的调用接口,在此给出相关实现方式供参考:
from fairseq.models.bart import BARTModel
from fairseq.token_generation_constraints import pack_constraints
checkpoint_dir="xxxx/xxxx/xxxx" #模型和词典的存放目录
model = BARTModel.from_pretrained(model_name_or_path=checkpoint_dir, checkpoint_file="checkpoint_best.pt").eval()
model.cuda()
constrain_words = ["aaa","bbb","ccc",...]
result = model.translate(
sentences=sequences,
beam=5,
constraints = "unordered",
inference_step_args = {
"constraints":pack_constraints([
[model.encode("{}".format(w))[1:-1] for w in constrain_words] #这里的[1:-1]主要针对BART预加载模型的处理,去掉<s>和</s>起止符号,也就是只有token本身需要encode进去,其他的预加载模型需要根据其特点灵活处理
])
}
)
二、GENRE constrain decoding
官方文档链接戳这里。
⚠️ 首先需要注意fairseq版本需要用他给出的:
https://github.com/facebookresearch/GENRE/tree/main/examples_genre
git clone --branch fixing_prefix_allowed_tokens_fn https://github.com/nicola-decao/fairseq
cd fairseq
pip install --editable ./
他在constrain decoding时的主要思路是,在模型做generate的每一个step时,根据需求传入可选的token list,当前step可选的token list主要取决于之前生成的prev output tokens,也就是下面的参数sent,根据我们提供的候选词list,构造前缀字典树Trie。
每一次step选择合法的候选词的关键函数是prefix_allowed_tokens_fn(batch_id, sent),我们需要根据具体的需求修改内部逻辑。
其主要在apply_mask中调用:
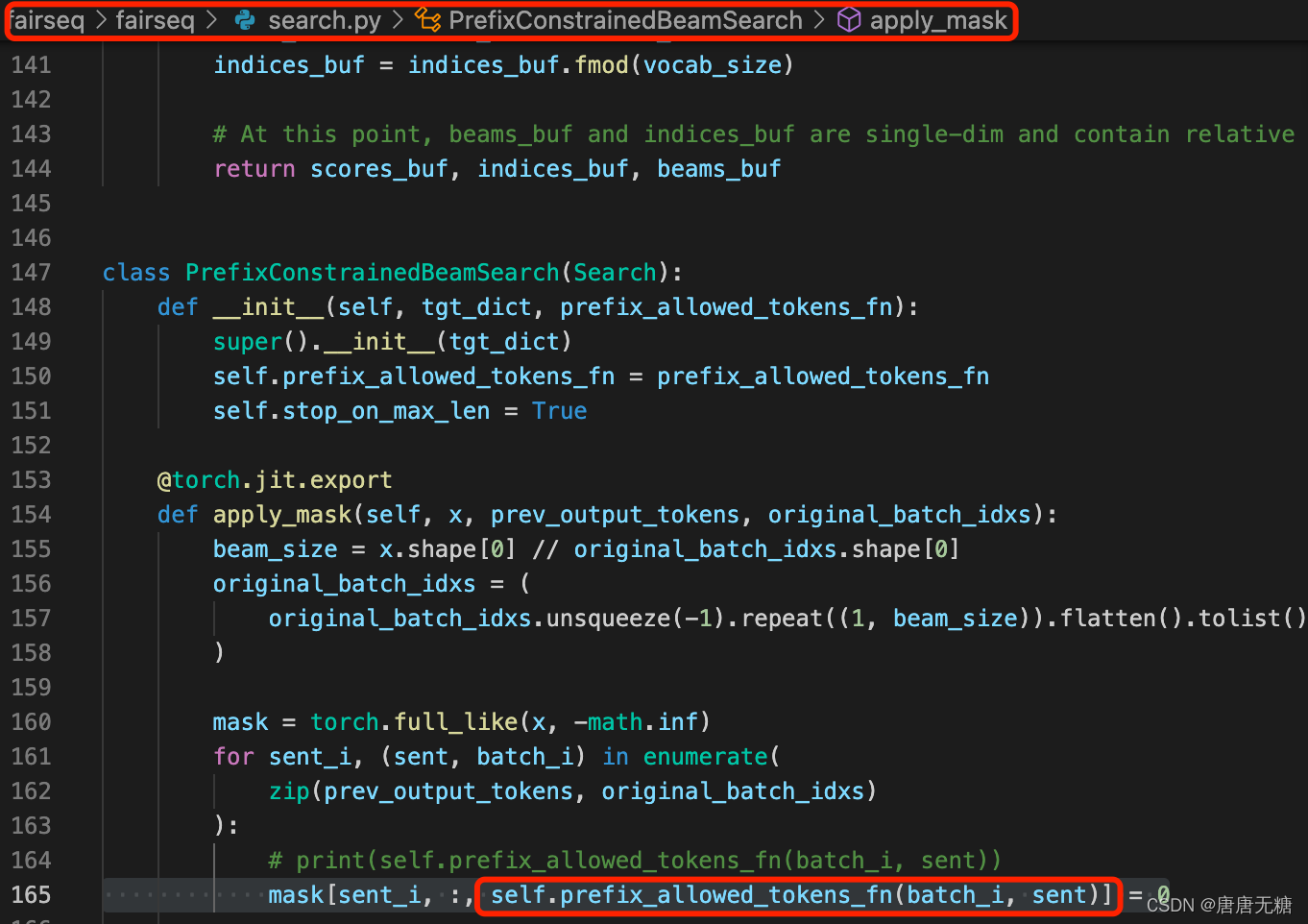
我们需要根据提供的候选词构造出它所需要的前缀树Trie,参考代码:
from genre.trie import Trie
from genre.entity_linking import get_end_to_end_prefix_allowed_tokens_fn_fairseq
from genre.fairseq_model import GENRE
model = GENRE.from_pretrained(model_name_or_path=checkpoint_dir, checkpoint_file=ckpt_file).eval()
model.cuda(f'cuda:{0}')
sentences = ['Hello world']
constrain_words = ["aaa","bbb","ccc",...]
example_trie=Trie([
model.encode("{}".format(w))[:].tolist() for w in constrain_words
])
prefix_allowed_tokens_fn = get_end_to_end_prefix_allowed_tokens_fn_fairseq(
model,
sentences,
mention_trie=example_trie,
)
results = model.translate(
sentences=sentences,
beam=5,
prefix_allowed_tokens_fn=prefix_allowed_tokens_fn
)
如有疑问可在公众号后台留言,期待您的关注!回复【关键词】可免费领取本人上传至CSDN的所有资料~



















 1201
1201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









