







IDEA 作为Java开发工具的后起之秀,几乎以碾压之势把其他对手甩在了身后,主要原因还是归功于:好用;虽然有点重,但依旧瑕不掩瑜,内置了非常多的功能,大大提高了日常的开发效率,下面汇总了常用的30个使用小技巧,学会之后,让你的撸码效率直接起飞...
查看代码历史版本
调整idea的虚拟内存:
idea设置成eclipse的快捷键
设置提示词忽略大小写
关闭代码检查
设置文档注释模板
显示方法分隔符
设置多行tab
快速匹配方法的大括号位置
代码结尾补全
模糊搜索方法
预览某个类的代码
查看方法在哪里被调用
代码模板(代码快捷键)
自动导包、自动移除没用的包
codota插件:可以优先显示使用频率较高的类、方法
快速查看类、字段的注释
括号颜色区分
微服务项目中 将不同项目添加到同一个启动窗口
idea全局设置 (打开新窗口的设置)
java mapper层代码文件和mapper.xml文件相互跳转
设置idea背景图片
maven tree (查看maven jar包依赖关系)
快捷键切换回上一个点击开的tab
idea自带的ssh连接工具
代码调用链路图插件
获取当前线程dump
idea同个项目不同端口多开
注意:不同idea版本菜单、目录可能有细微差别,自己稍加分析都能找到
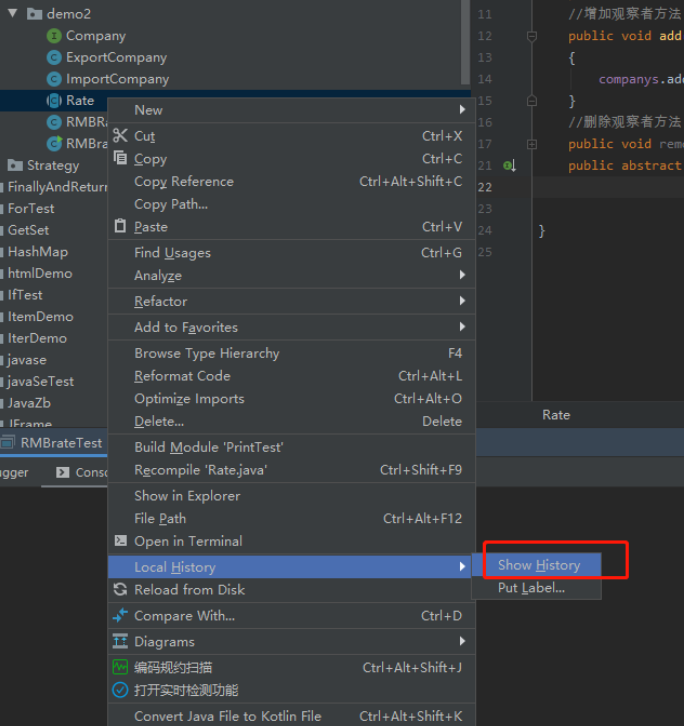
1.查看代码历史版本
鼠标在需要查看的java类 右键 找到Local History >> Show History 点开即可看到历史版本,常用于自己忘记代码改了哪些内容 或需要恢复至某个版本 (注意 只能看近期修改 太久了也是看不到的)
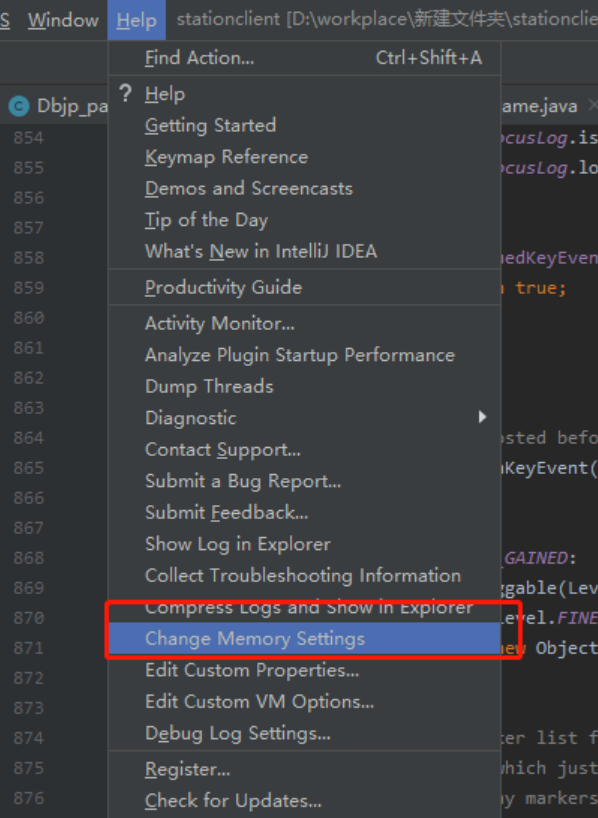
2.调整idea的虚拟内存
尽管本质都是去改变 .vmoptions配置文件,但推荐使用Change Memory Settings去调整,选择Edit Custom VM Options 或者在本地磁盘目录更改,通过某些方法破解的idea 很可能造成idea打不开的情况
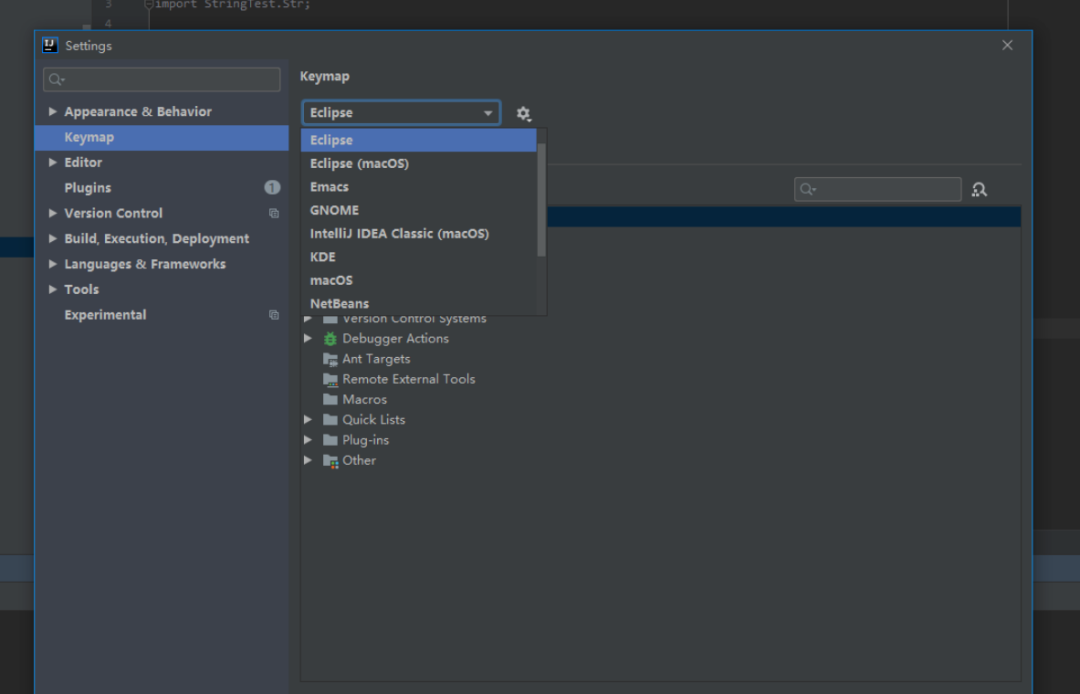
3.idea设置成eclipse的快捷键
这对eclipse转idea的开发人员来说 非常友好,这样不需要记两套快捷键
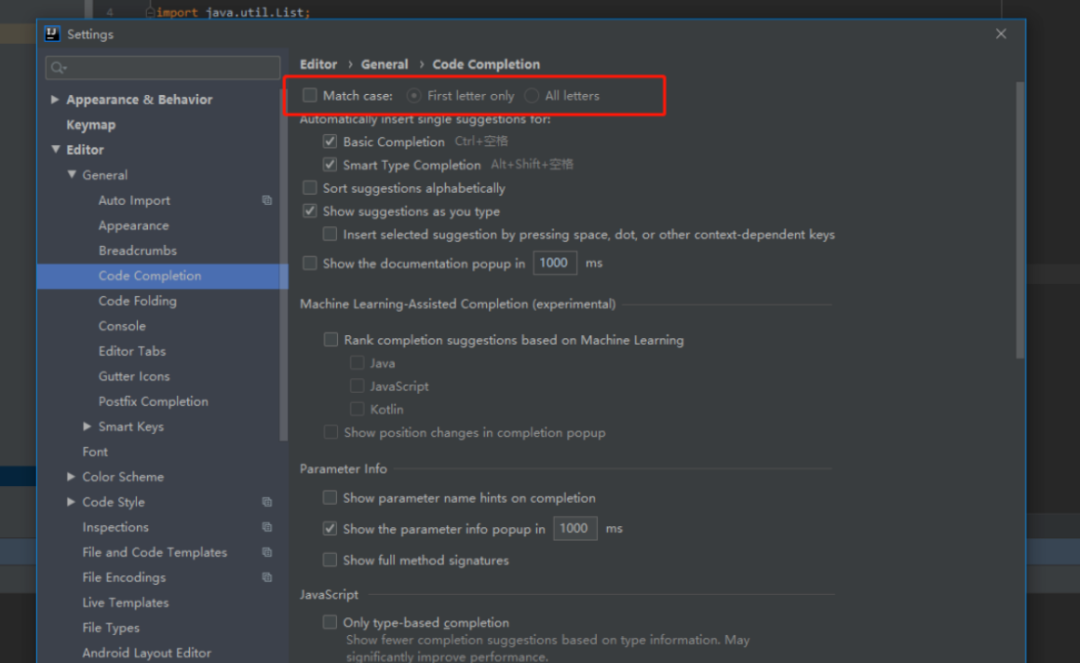
4.设置提示词忽略大小写
把这个勾去掉,(有的idea版本是选择选项 选择none即可),例如String 输入string 、String 都可以提示
5.关闭代码检查
与eclipse类似,idea也可以自己关闭代码检查 减少资源使用,但不推荐全部关闭,(是大佬当我没说),把我们项目中不会使用到的关闭就好了
6.设置文档注释模板
文档注释快捷键及模板
https://blog.csdn.net/qq_36268103/article/details/108027486
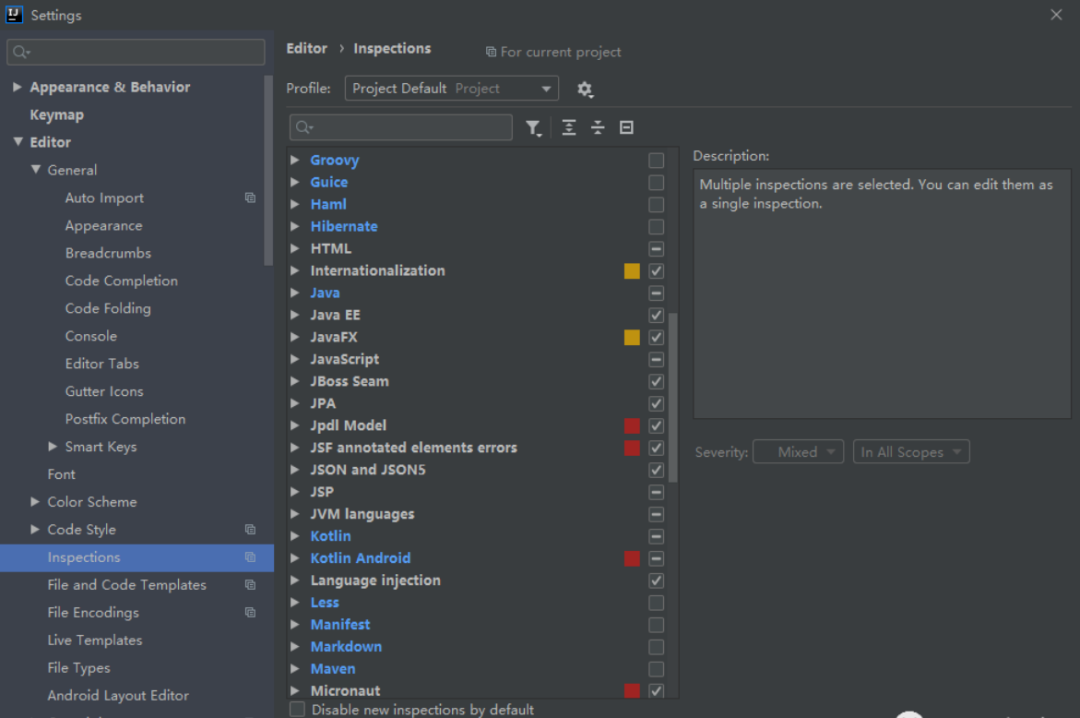
7.显示方法分隔符
方便查看方法与方法之间的间隔,在代码不规范的项目中 很好用!
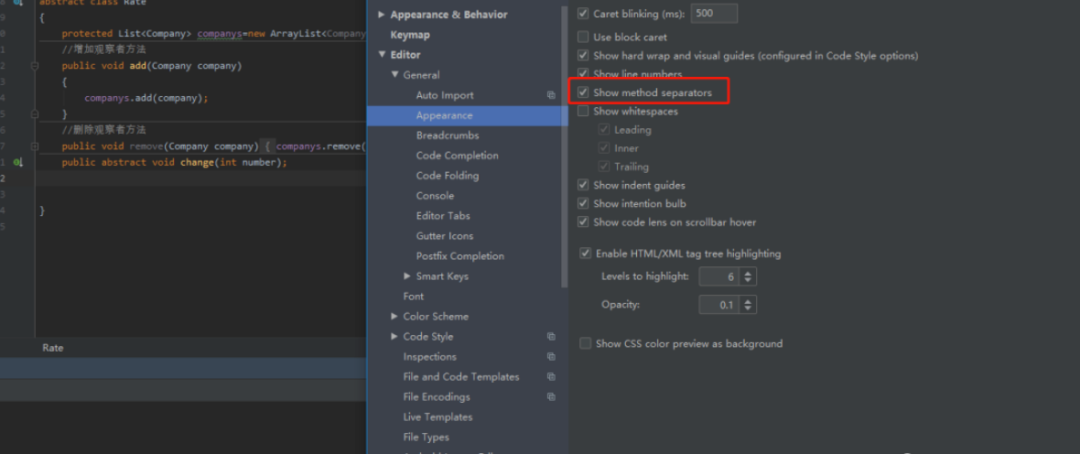
8.设置多行tab
idea默认是选择显示单行的,我们把这个去掉,就可以显示多行tab了,在打开tab过多时的场景非常方便!
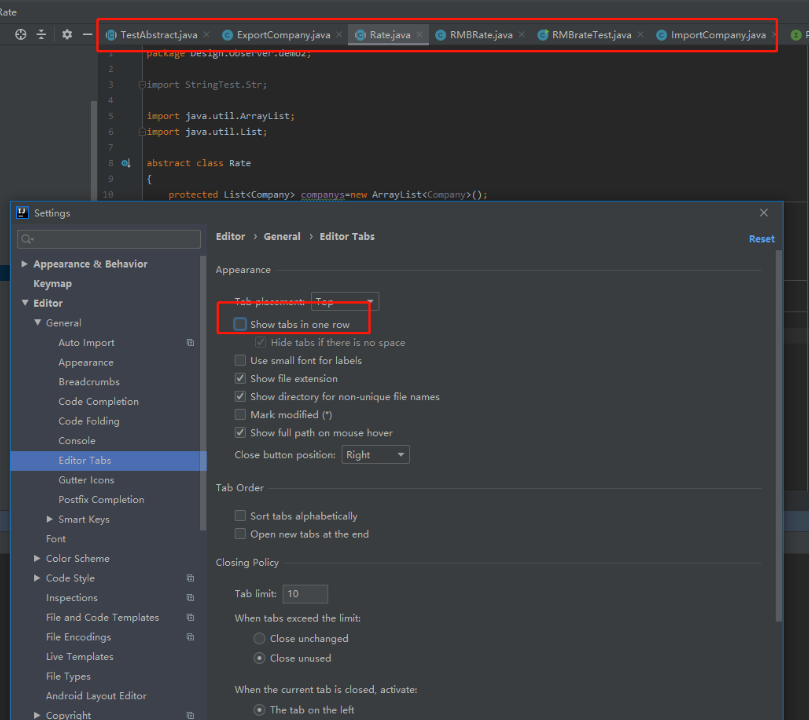

8.1 tab过多会自动关闭
settings - editor - General - Editor tabs - tab limit 数值设大就好了
9.快速匹配方法的大括号位置
ctrl+[ ctrl+] 可以快速跳转到方法大括号的起止位置,配合方法分隔符使用,不怕找不到方法在哪儿分割了
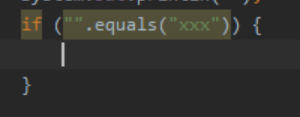
10.代码结尾补全
例如一行代码补全分号,或者是if(xxx) 补全大括号,按ctrl+shift+enter 无需切换鼠标光标,大幅度提升了编码效率
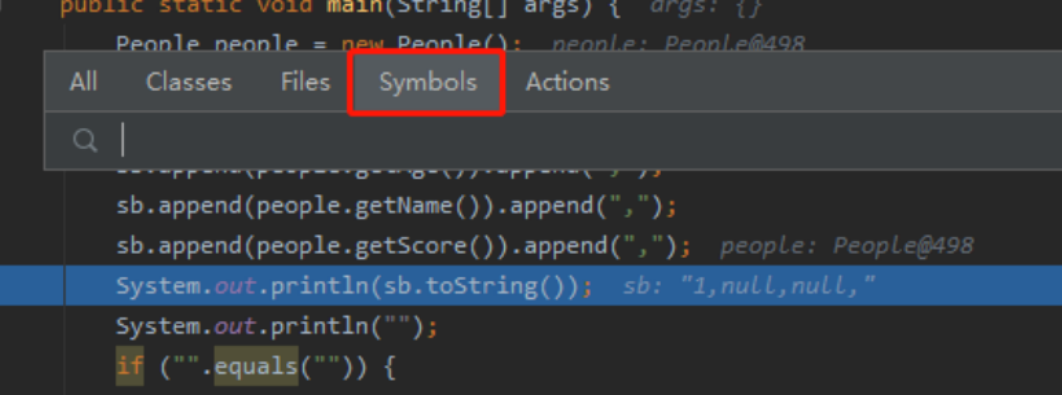
11.模糊搜索方法
例如People类里面的test方法,按ctrl+shift+alt+n 输入Peo.te 就可以查到该方法了,如果觉得这个快捷键难记 也可以按ctrl+shift+r (查找某个文件名的快捷键 下图中的Files),再手动选择Symbols
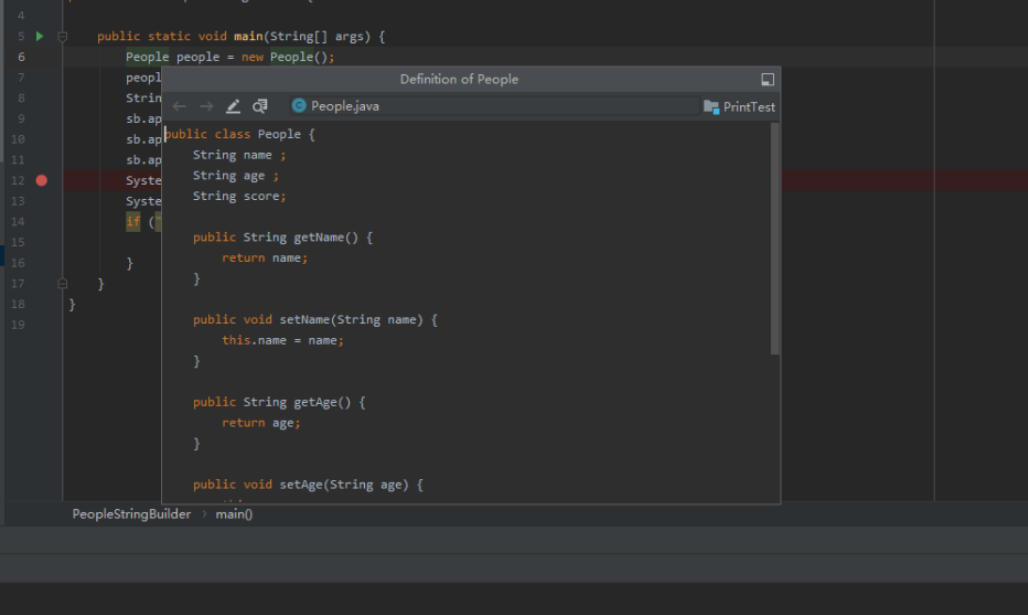
12.预览某个类的代码
例如People类里面的test方法,按ctrl+shift+a
例如我们在test类中,有句代码:People p = new People(); 我们想稍微查看一下People这个类,但是tab已经够多了,ctrl+alt+b会打开新的标签,标签多了就混乱了,尤其一堆命名类似的tab,这时候我们可以按ctrl+shift+i 实现预览功能,不占tab
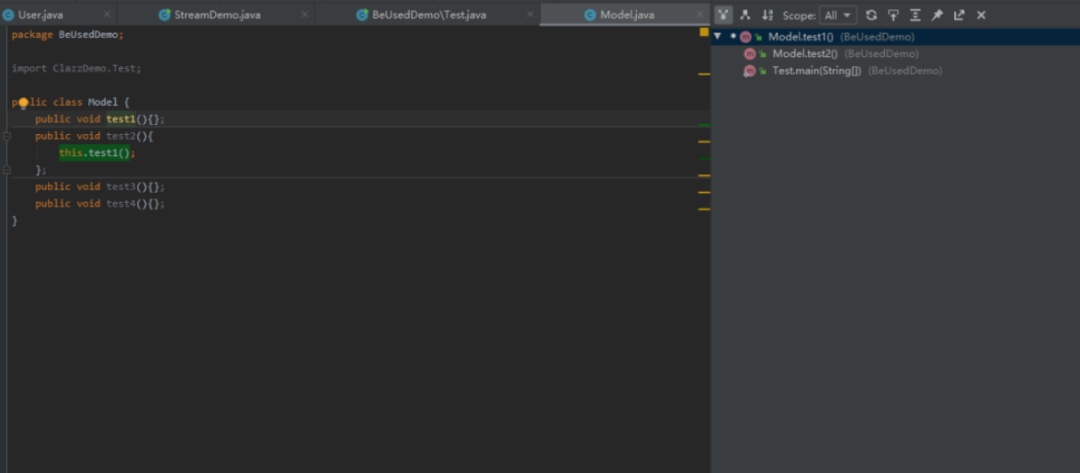
13.查看方法在哪里被调用
ctrl+alt+h 可以清楚看到方法在哪些地方被调用;在知道这个快捷键之前,都是ctrl+h(idea默认 ctrl+shift+f)搜索,肉眼找的…
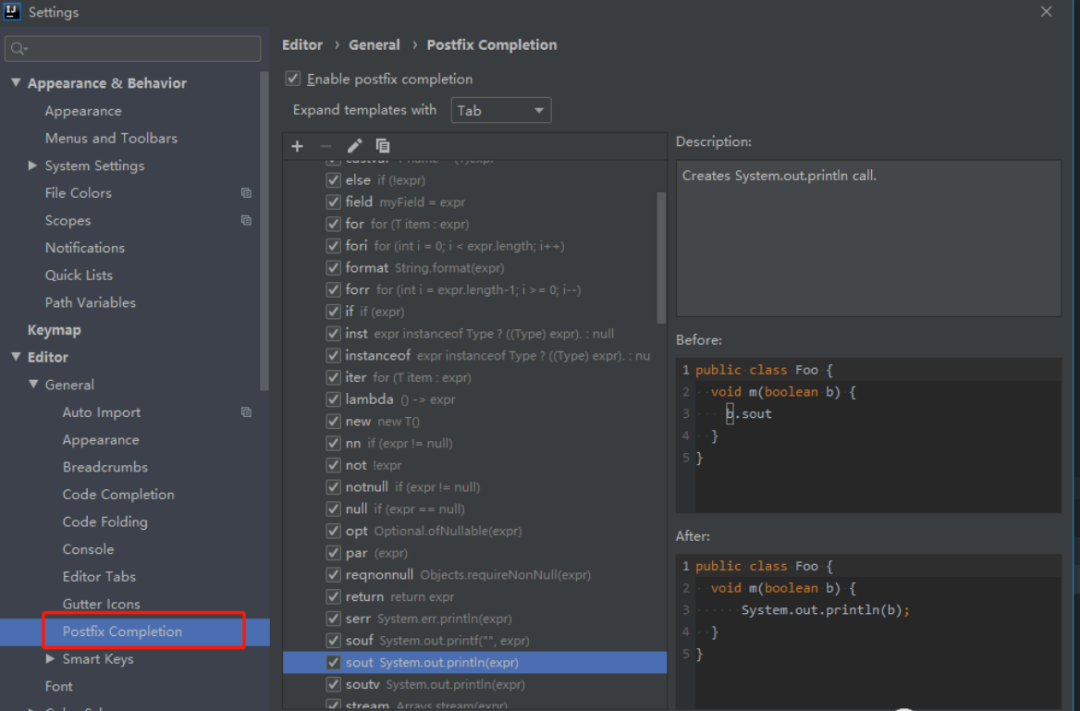
14.代码模板(代码快捷键)
例如 : eclipse 中的syso是打印控制台输出 ,但是idea默认是sout , 如果非要改成syso 可以在Postfix Completion里面设置,类似的 fori等都是在里面设置
15.自动导包、自动移除没用的包
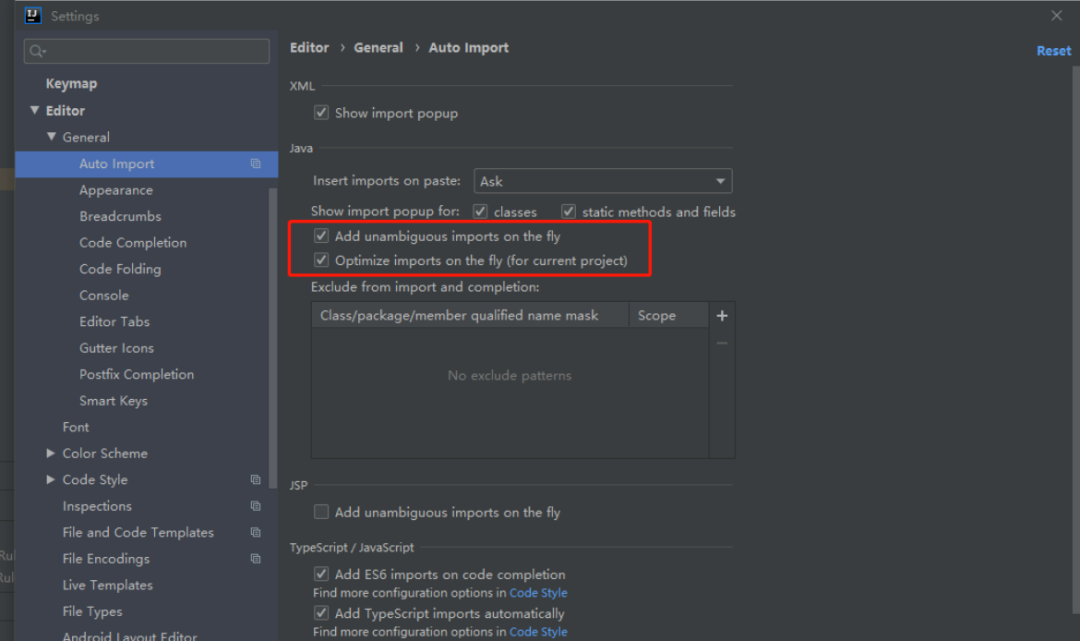
15.1 手动导包 :alt+enter 手动移除未使用包: crtl+alt+o
16.codota插件:可以优先显示使用频率较高的类、方法
这个根据个人是否要使用 有的时候工具只能作参考,自己记忆才能保证准确
17.快速查看类、字段的注释
这是一个很有用的小技巧 按F2可以快速查看某个类或某个字段的文档注释 ;基于这点 其它IDE应该也是可以快速查看文档注释内容 不仅仅是idea特性,这也是为什么阿里编码规范里面会明确声明实体类字段需要用文档注释 而不能使用双斜杠// 注释 ,还记得刚看到这个规范的时候 很不理解 特地去百度 看到有人说就是个习惯问题 很显然不能说服人,直到发现F2可以快速查看之后 恍然大悟!
18.括号颜色区分
Rainbow Brackets 插件 成对的括号用相同的颜色表示出来了

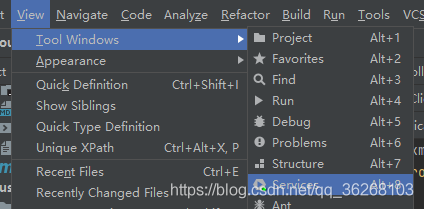
19.微服务项目中将不同项目添加到同一个启动窗口
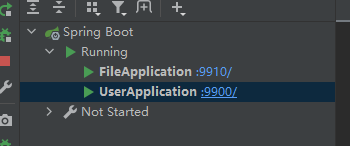
步骤:View ——>Tool Windows ——> services ——>add services
20.idea全局设置(打开新窗口设置)
例如我们打开新窗口时,maven配置会恢复 这时就需要对打开新窗口的设置进行修改 达到一个全局的目的。
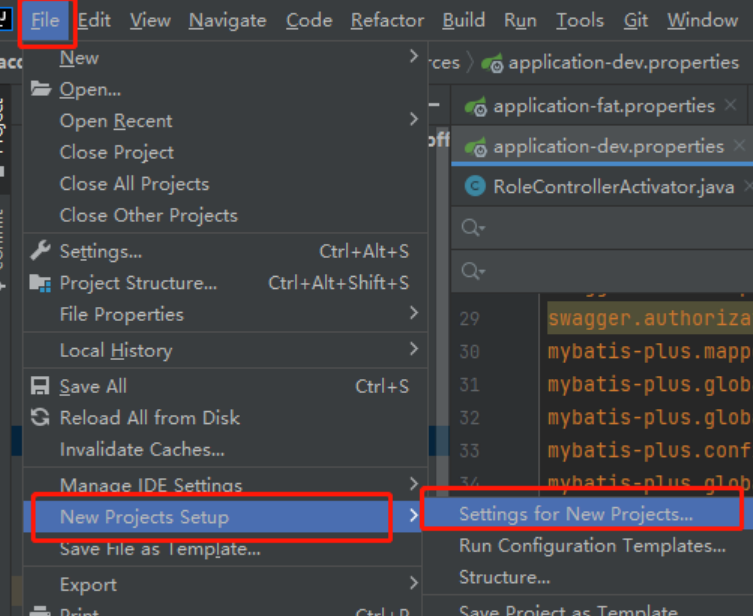
在低版本idea中 也是在File下 例如idea2018是叫other settings
21.java mapper层代码文件和mapper.xml文件相互跳转
Free MyBatis plugin 插件
点击绿色箭头可以直接跳转 非常方便
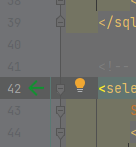
22.设置idea背景图片
BackgroundImage插件
设置喜欢的图片作为背景图
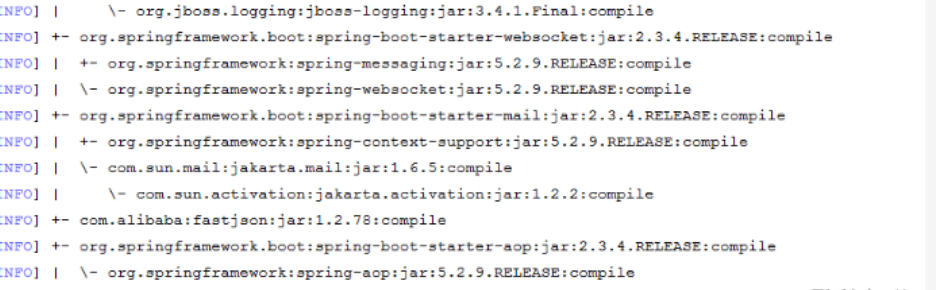
23.maven tree(查看maven jar包依赖关系)
如果是使用 mvn dependency:tree 命令 , 结果是下图这样 很不方便查看
我们可以在idea右上角点击这个ShowDependencies按钮 以图片形式展示出来 图片按住ctrl和鼠标滑轮 可以放大,这个在排除依赖冲突 查看jar包来源时 非常好用
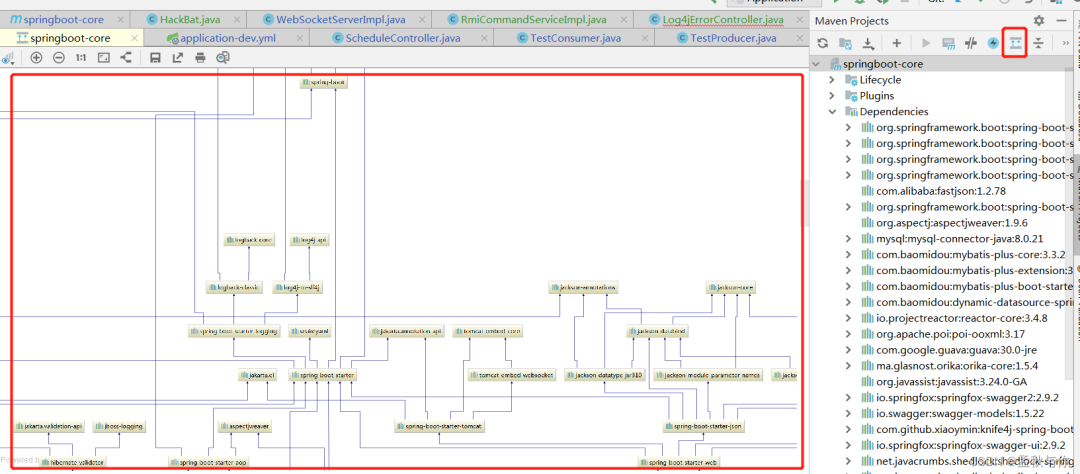
有的时候 可能莫名其妙看不到这个图标 ,我们可以点一下设置
把这个勾上,它就能显示了,等显示后,再把这个勾去掉
24.快捷键切换回上一个点开的tab
当我们打开了多个tab的时候 , 想要快速回到上一个点击的tab中 有的时候肉眼很难找
我们可以用快捷键 alt + ← 键 (eclipse版快捷键 idea默认快捷键需要自测) ,有的时候我们在后面tab编辑了内容 按一次可能不够 需要再多按几次 ,相应的 alt + → 切换到下一个点击的tab
常见应用场景:debug发生类跳转时 、利用快捷键在其它类中创建方法时
即使两个tab不相邻 也可以切换回去

25.idea自带的ssh连接工具
类似的idea还有自带的数据库连接工具 但是视图界面并不如Navicat 所以很多人都不选择用
第一步:配置账号密码
第二步:开启ssh会话
26.代码调用链路图插件
SequenceDiagram 插件
这其实是本文第13点的上位替代方案,idea自带的快捷键查看代码调用,只是以菜单形式展示,不太直观,如果是自己写的代码或比较规范的代码,那用自带的也就无所谓,如果是比较复杂的源码或不规范的代码,那使用 SequenceDiagram 会直观特别多。
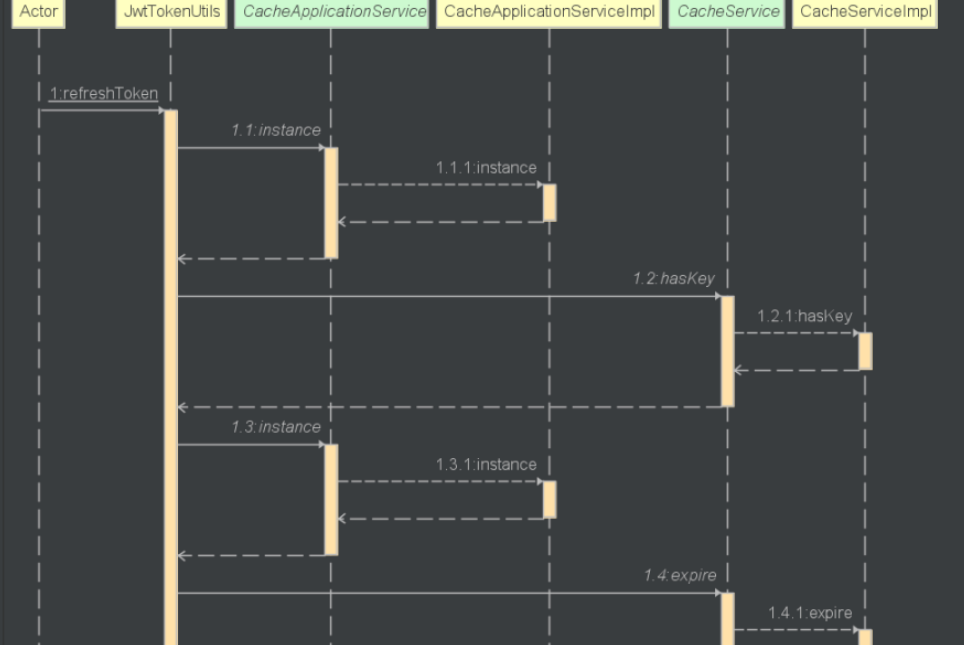
在要查看的java文件鼠标右键,点击 Sequence Diagram

效果示例:
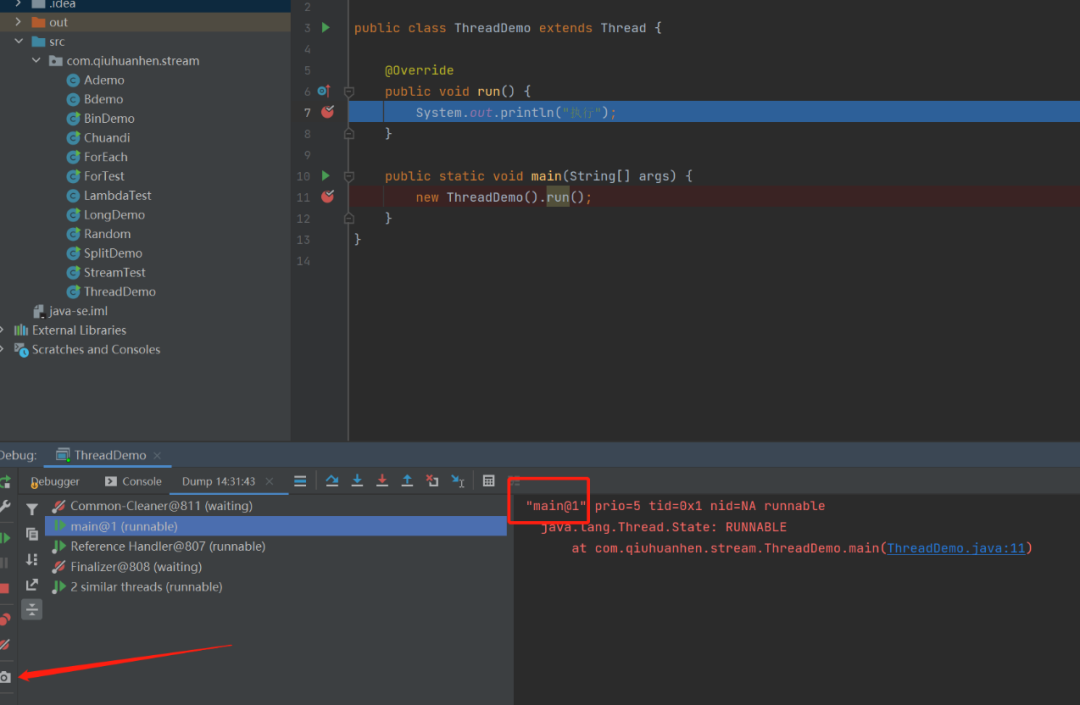
27.获取当前线程dump
在断点调试的时候,我们可以通过点击下图红色箭头指向的相机图标,获取当前线程的dump信息。
这个功能有什么用呢?我们可以通过线程名,分析当前是哪个线程执行的,在多线程环境下对代码运行分析起到辅助作用。
比如下图1, run()方法是通过main主线程执行的,只是方法调用,并没有启动多线程(这是我们熟知结论的实践证明)
当我们把run方法改成start()方法时,可以看到是线程thread0执行的。
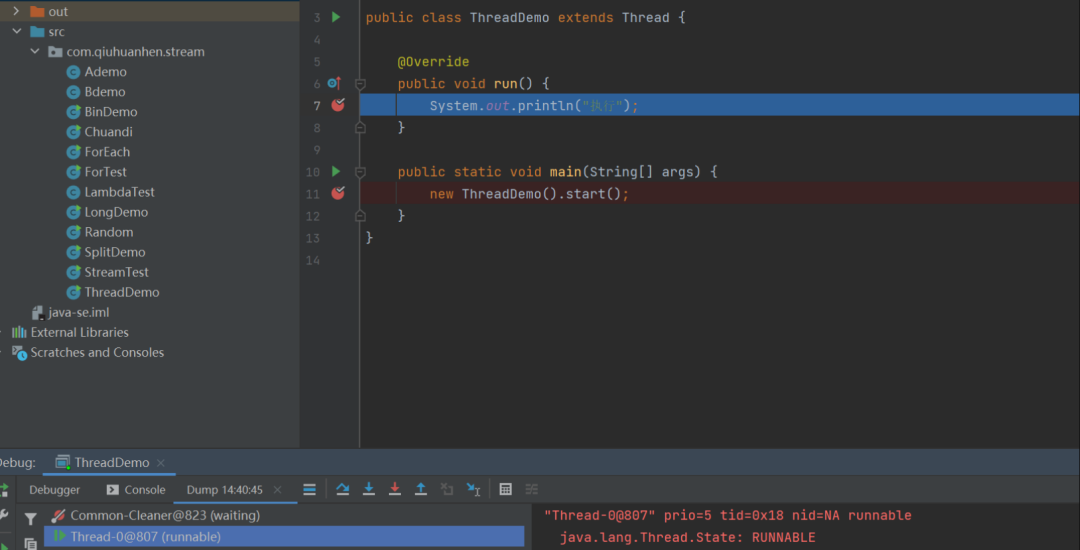
28.idea同个项目不同端口多开
这是个非常实用的功能,可以模拟集群 测试负载均衡。
此外 在开发阶段也是非常好用,开发过程中,让别人直接连自己本地测试 是不是非常方便?
那自己又想打断点调试 会影响别人 怎么办呢 ?这个时候多开的作用就体现出来了!
网上很多方法提到勾选 Allow parallel run (不同版本idea 名称不一样) ,我也亲眼见过有老师是可以多开启动的, 但我本地启动发现每次都会同时同端口启动多个,不知道是版本问题还是操作问题,这里我用的是另一种有效的方法:
在 VM options 加上
# 8993是区别于 application.yml 配置中 port 的另一个端口,达到不同端口多开的效果-Dserver.port=8993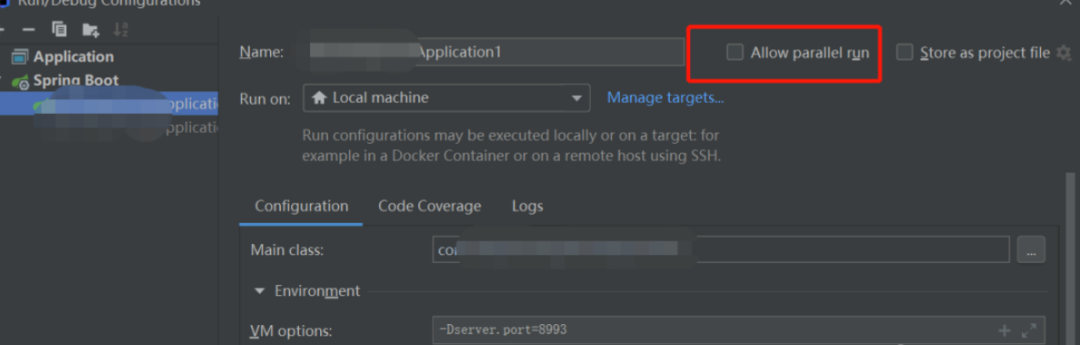


















 853
853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











