







- 无监督学习
监督学习解决的是“分类”和“回归”问题,而无监督学习解决的主要是“聚类(Clustering),降维”问题。
这是几种常见的主要用于无监督学习的算法。
K均值(K-Means)算法;
自编码器(Auto-Encoder);
主成分分析(Principal Component Analysis)。 - SVM
计算分类面方程
方程:
x 1 ∗ w 1 + x 2 ∗ w 2 + b = 0 x_1*w_1 +x_2*w_2+b=0 x1∗w1+x2∗w2+b=0
约束条件:
m i n 1 / 2 ( w 1 2 + w 2 2 ) min 1/2 (w_1^2+w_2^2) min1/2(w12+w22)
st y i ( w i ∗ x i + b ) > = 1 y_i(w_i*x_i + b) >= 1 yi(wi∗xi+b)>=1
例题 - 判别模型和生成模型
判别式模型(Discriminative Model)是直接对条件概率p(y|x;θ)建模。
常见的判别式模型有 线性回归模型、线性判别分析、支持向量机SVM、神经网络等。
生成式模型(Generative Model)则会对x和y的联合分布p(x,y)建模,然后通过贝叶斯公式来求得p(yi|x),然后选取使得p(yi|x)最大的yi,
常见的生成式模型有 隐马尔可夫模型HMM、朴素贝叶斯模型、高斯混合模型GMM、LDA等 - adaboost
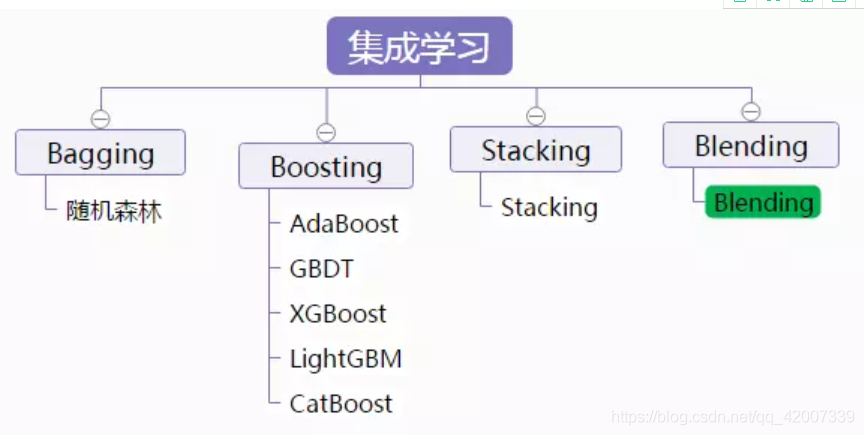
在前一轮识别过程中识别错误的样本会在下一轮中提升权重,而那些识别正确的样本会降低权重。 - EM
EM 算法通过逐步提高极大似然的下限,以此求出极大似然函数对参数的估计,为无监督算法 - 数据挖掘方法
主要有决策树 、神经网络 、回归 、聚类 、关联规则 、贝叶斯分类 - HK算法和感知器算法
HK算法思想很朴实,就是在最小均方误差准则下求得权矢量.
他相对于感知器算法的优点在于,他适用于线性可分和非线性可分得情况,对于线性可分的情况,给出最优权矢量,对于非线性可分得情况,能够判别出来,以退出迭代过程.















08-19
 854
854
854
03-17
1147
1147
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









